
Bài đọc tham khảo
Mục tiêu của lý thuyết học máy
Phát triển và phân tích các mô hình để hiểu:
- chúng ta có thể hy vọng học được những loại nhiệm vụ nào và từ loại dữ liệu nào; các tài nguyên chính liên quan là gì (ví dụ: dữ liệu, thời gian chạy)
- chứng minh sự đảm bảo cho các thuật toán thành công thực tế (khi nào chúng sẽ thành công, chúng sẽ mất bao lâu?)
- phát triển các thuật toán mới có thể đáp ứng các tiêu chí mong muốn (trong các mô hình học tập mới)
Các công cụ thú vị & kết nối với các lĩnh vực khác:
- Thuật toán, Xác suất & Thống kê, Tối ưu hóa, Lý thuyết độ phức tạp, Lý thuyết thông tin, Lý thuyết trò chơi.
Lĩnh vực rất sôi động:
- Hội nghị về Lý thuyết học tập
- NIPS, ICML
Hôm nay:
Trọng tâm hôm nay: Độ phức tạp của mẫu để phân loại được giám sát (Xấp xỉ hàm)
- Lý thuyết học tập thống kê (Vapnik)
- PAC (Valiant)
- Đề xuất đọc: Mitchell: Ch. 7
- Bài tập gợi ý: 7.1, 7.2, 7.7
- Tài liệu bổ sung: giáo trình lý thuyết học tập của tôi!
Phân loại được giám sát
Quyết định email nào là thư rác và email nào quan trọng.
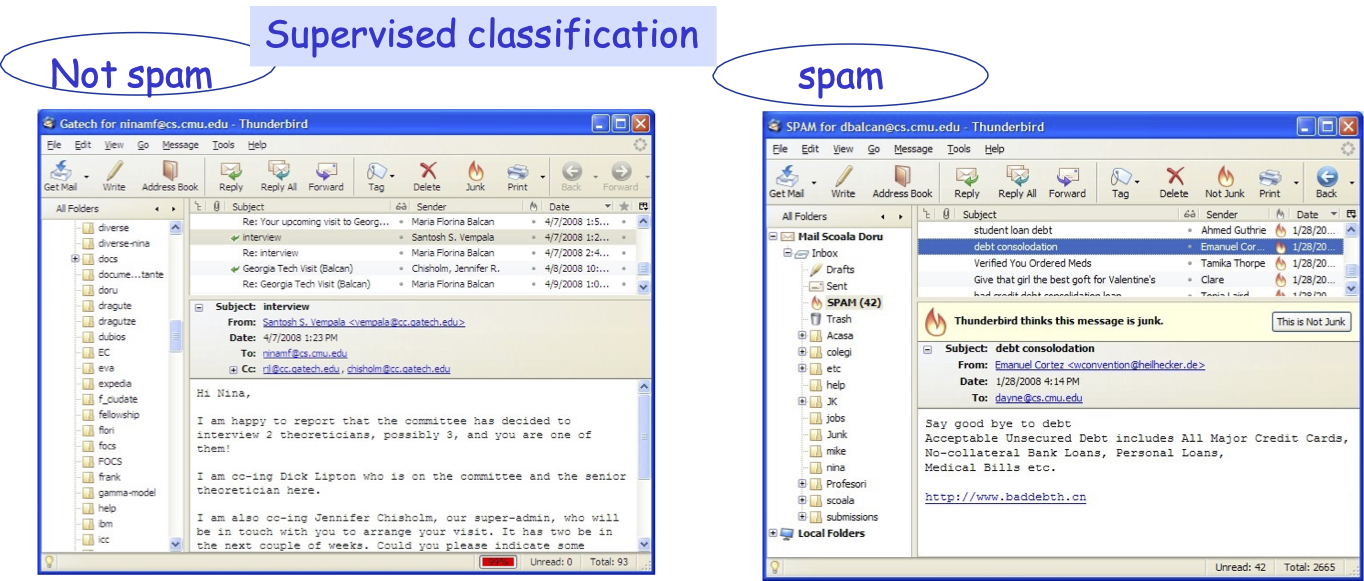
Mục tiêu: sử dụng các email đã thấy cho đến nay để tạo quy tắc dự đoán tốt cho dữ liệu trong tương lai.
Ví dụ: Phân loại được giám sát
Thể hiện từng tin nhắn theo các tính năng. (ví dụ: từ khóa, chính tả, v.v.)
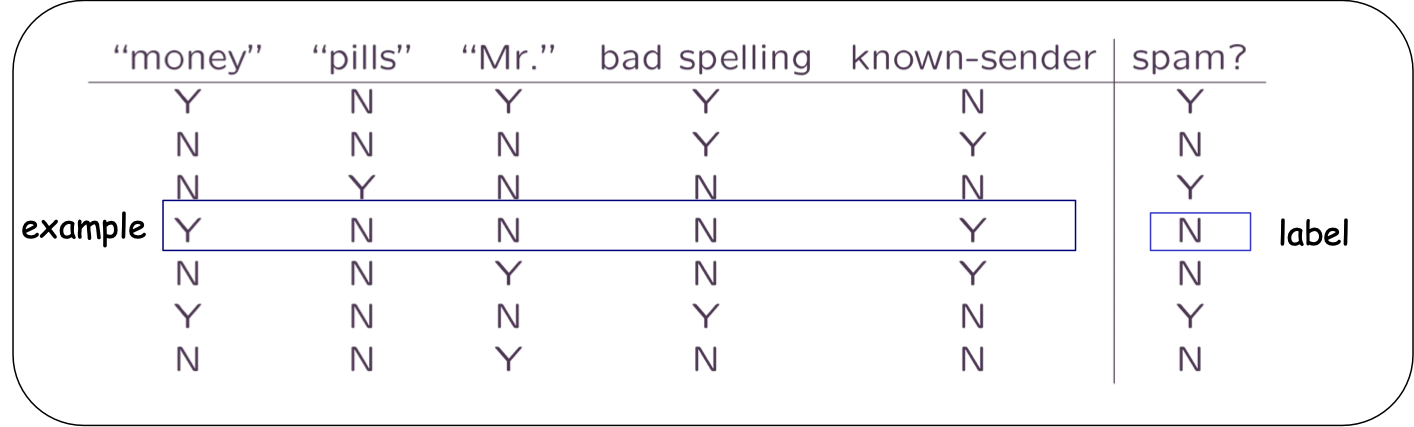
QUY TẮC hợp lý:
- Dự đoán SPAM nếu không biết VÀ (tiền HOẶC thuốc)
- Dự đoán SPAM nếu 2money + 3pills –5 đã biết > 0
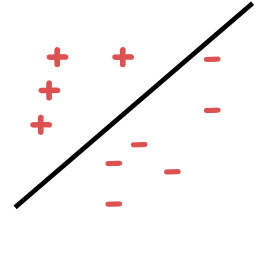
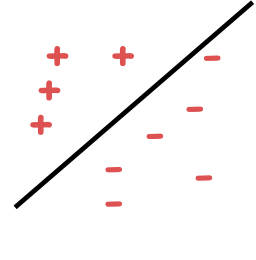
Có thể phân tách tuyến tính
Hai khía cạnh cốt lõi của học máy
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
- Ví dụ: hồi quy logistic, SVM, Adaboost, v.v.
Dữ liệu (được gắn nhãn)
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc đối với dữ liệu trong tương lai.
- Hiểu rất rõ: ràng buộc Occam, lý thuyết VC, v.v.
- Lưu ý: để nói về những điều này, chúng ta cần một mô hình chính xác.
Các mô hình PAC/SLT cho Học tập có giám sát
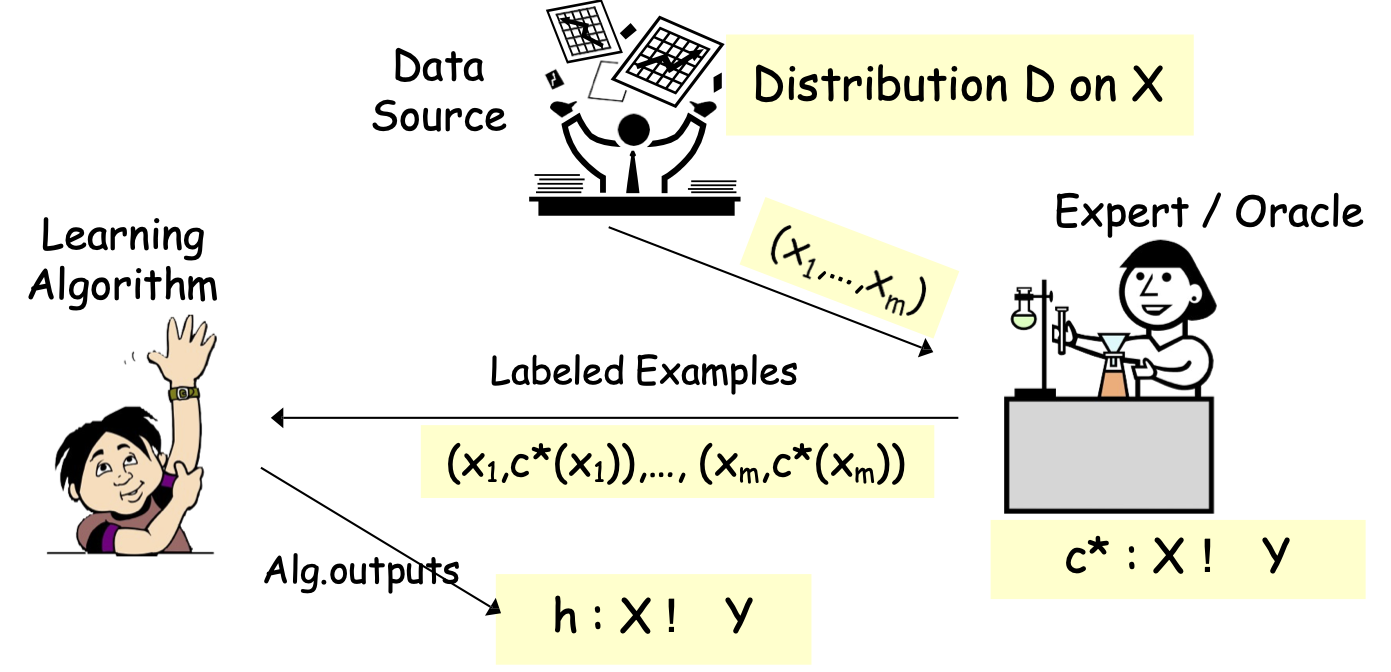
Các mô hình PAC/SLT cho Học có giám sát
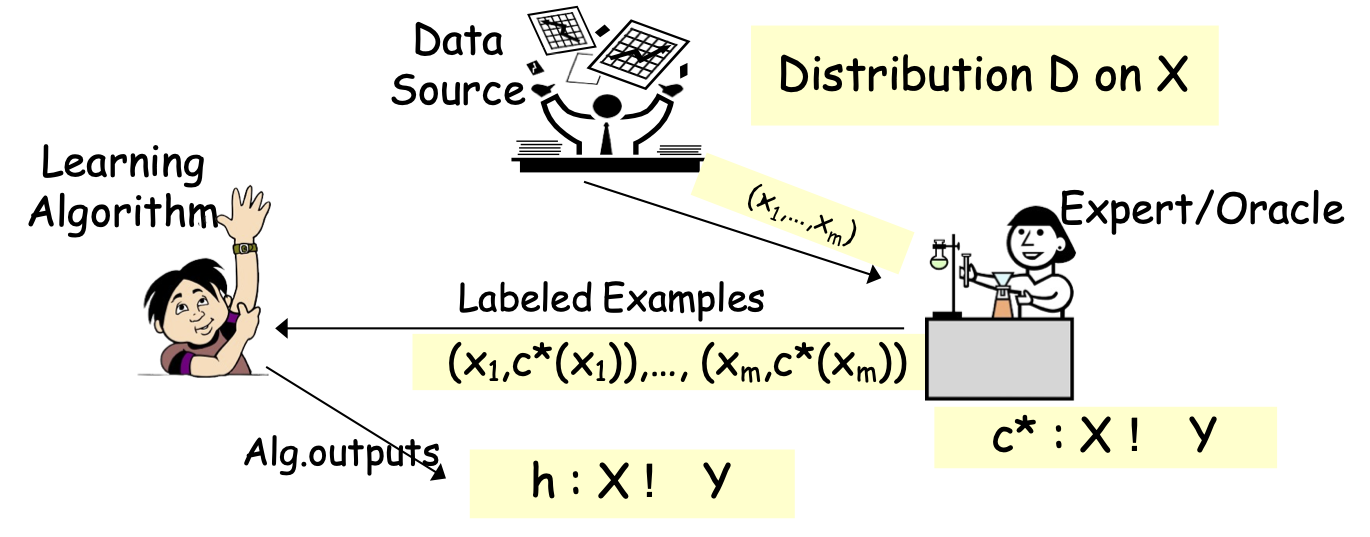
Hôm nay: Y={-1,1}
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi một cách độc lập và phân phối giống hệt nhau (i.i.d.) từ D; được gắn nhãn bởi 𝑐∗
- Tối ưu hóa trên S, tìm giả thuyết h (ví dụ: cây quyết định).
- Mục tiêu: h có lỗi nhỏ trên D.
Các mô hình PAC/SLT cho Học có giám sát
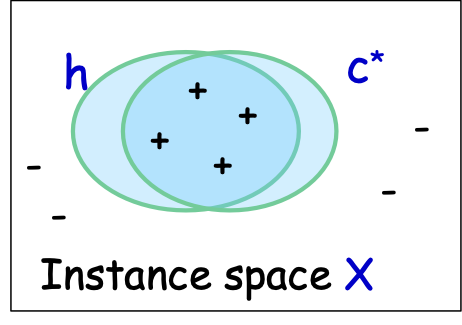
- X – không gian đối tượng hoặc tính năng; phân phối D trên X
- ví dụ: X = Rd hoặc X = {0,1}d
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- các mẫu có nhãn – được giả định là lấy i.i.d. từ một distr nào đó. D trên X và được gắn nhãn bởi một số khái niệm đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán thực hiện tối ưu hóa trên S, tìm giả thuyết ℎ.
- Mục tiêu: h có lỗi nhỏ trên D.
- 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))
 Cần một sự thiên vị: không có bữa trưa miễn phí.
Cần một sự thiên vị: không có bữa trưa miễn phí.
Xấp xỉ hàm: Bức tranh toàn cảnh

Các mô hình PAC/SLT cho Học có giám sát
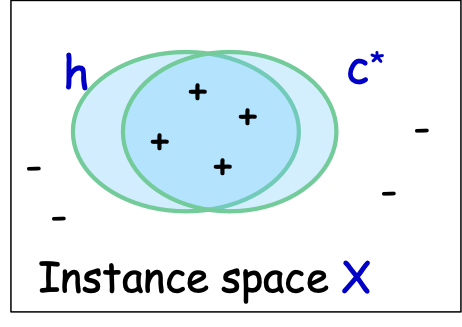
- X – không gian đối tượng hoặc đặc trưng; phân phối D trên X
- ví dụ: X = Rd hoặc X = {0,1}d
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- các mẫu được gắn nhãn – giả định là i.i.d. được rút ra từ một số distr. D trên X và được gắn nhãn bởi một số khái niệm đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán thực hiện tối ưu hóa trên S, tìm giả thuyết ℎ.
- Mục tiêu: h có lỗi nhỏ trên D.
- 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))

Sai lệch: Cố định không gian giả thuyết H.
- (có độ phức tạp không quá lớn).
Khả thi: 𝑐∗ ∈ 𝐻.
Bất khả tri: 𝑐∗ “gần với” H.
Các mô hình PAC/SLT cho Học có giám sát
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- Thực hiện tối ưu trên S, tìm giả thuyết ℎ ∈ 𝐻.
- Mục tiêu: h có lỗi nhỏ trên D.
- Lỗi thực tế: 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))
- Tần suất ℎ(𝑥) ≠ 𝑐∗(𝑥) đối với các phiên bản trong tương lai được rút ngẫu nhiên từ D
- Lỗi thực tế: 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))
- Nhưng, chỉ có thể đo lường:
- Lỗi huấn luyện: 𝑒𝑟𝑟𝑆 (ℎ) = 1⁄𝑚 ∑𝑖 𝐼(ℎ(𝑥𝑖) ≠ 𝑐∗(𝑥𝑖))
- Tần suất ℎ(𝑥) ≠ 𝑐∗(𝑥) đối với các phiên bản huấn luyện
- Lỗi huấn luyện: 𝑒𝑟𝑟𝑆 (ℎ) = 1⁄𝑚 ∑𝑖 𝐼(ℎ(𝑥𝑖) ≠ 𝑐∗(𝑥𝑖))
Độ phức tạp của mẫu: bị ràng buộc 𝑒𝑟𝑟𝐷 (ℎ) tính theo 𝑒𝑟𝑟𝑆 (ℎ)
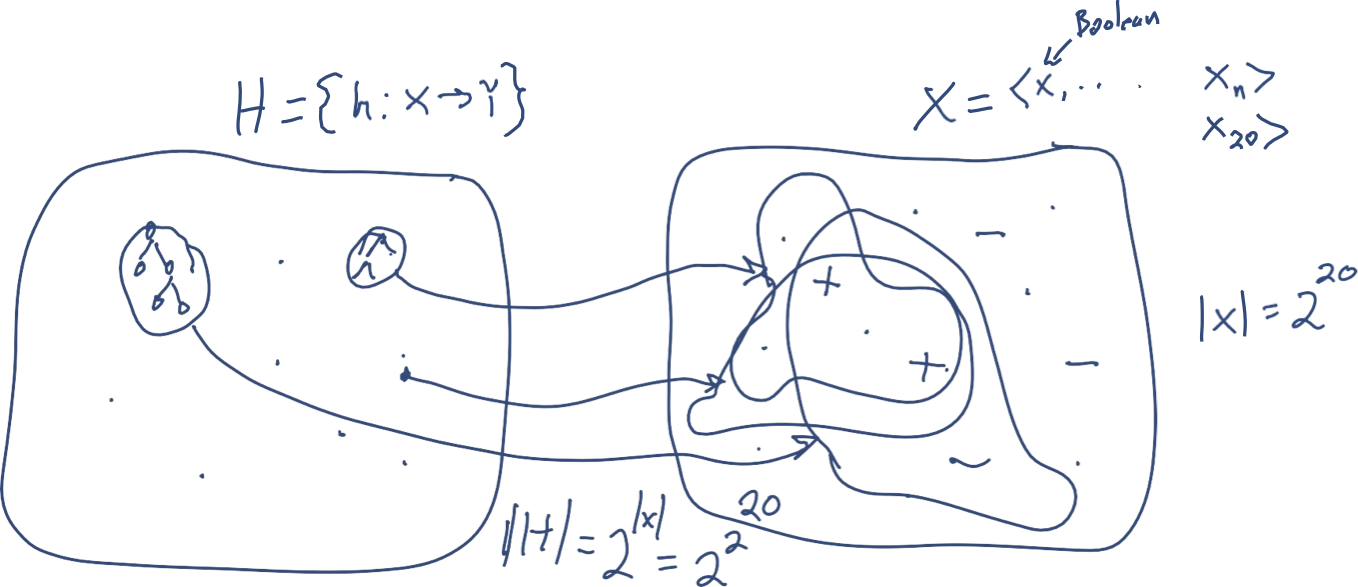
Độ phức tạp của mẫu đối với học có giám sát
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với mẫu (nếu một mẫu tồn tại).
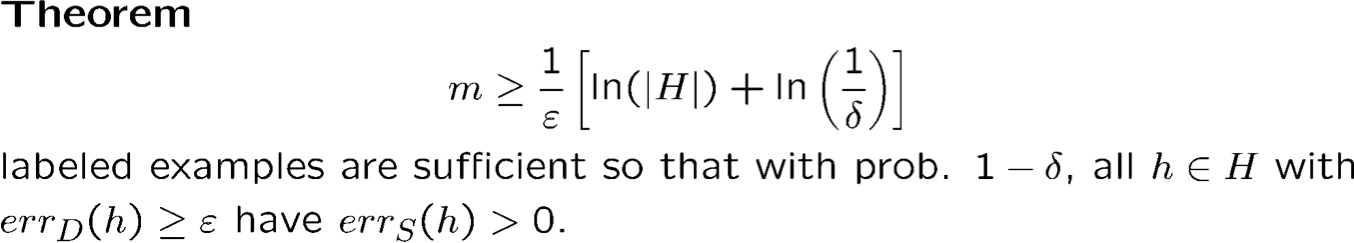
Ngược lại: nếu mục tiêu ở H và chúng ta có một thuật toán có thể tìm fns nhất quán, thì chúng ta chỉ cần nhiều mẫu để nhận lỗi tổng quát hóa ≤ 𝜖 với xác suất ≥ 1 − 𝛿
Độ phức tạp mẫu cho học có giám sát
Người học nhất quán
- Dữ liệu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H nhất quán với mẫu (nếu tồn tại).

Có giới hạn tuyến tính nghịch trong 𝜖
Chỉ có giới hạn logarit trong |H|
- 𝜖 được gọi là tham số lỗi
- D có thể đặt trọng số thấp trên các phần nhất định của không gian
- 𝛿 được gọi là tham số tin cậy
- có một khả năng nhỏ là các mẫu chúng ta nhận được không đại diện cho phân phối
Độ phức tạp của mẫu đối với học tập có giám sát
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với mẫu (nếu tồn tại).
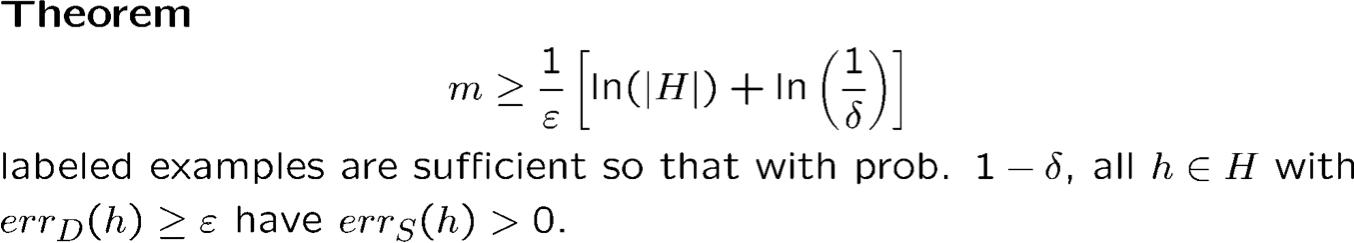
Ví dụ:
H là lớp liên từ trên X = {0,1}n. |H| = 3n
Ví dụ: h = x1 x3x5 hoặc h = x1 x2x4𝑥9
Khi đó 𝑚 ≥ 1⁄𝜖[𝑛 ln 3 + ln(1⁄𝛿)] đủ
𝑛 = 10, 𝜖 = 0.1, 𝛿 = 0.01 thì 𝑚 ≥ 156 đủ
Độ phức tạp mẫu cho Học có giám sát
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với mẫu (nếu tồn tại).
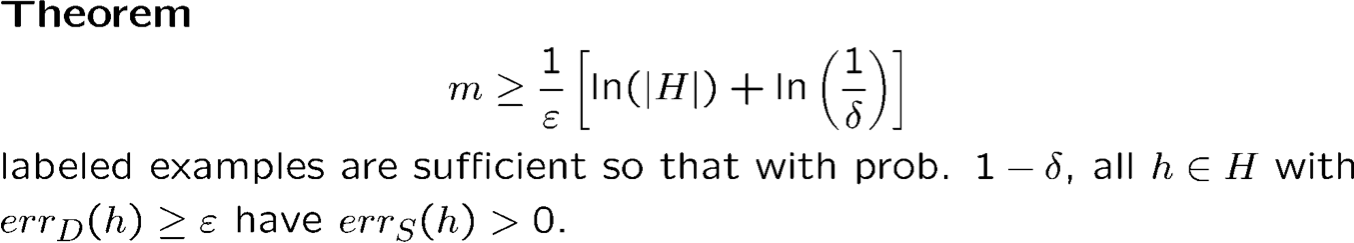
Ví dụ:
H là lớp liên từ trên X = {0,1}n.
Câu hỏi HWK phụ: chỉ ra rằng bất kỳ phép kết hợp nào cũng có thể được biểu diễn bằng một cây quyết định nhỏ; cũng bởi một dải phân cách tuyến tính.
Độ phức tạp của mẫu đối với học có giám sát
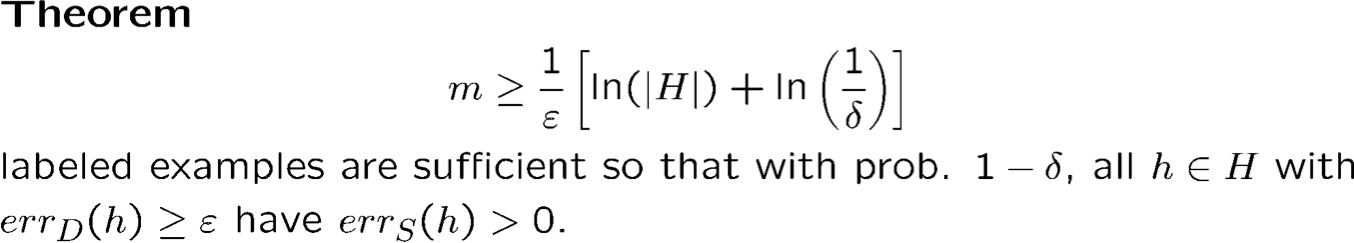
Proof
Giả sử k giả thuyết xấu h1, h2, … , hk với errD (hi) ≥ ϵ
- Cố định hi. Xác suất hi phù hợp với mẫu đào tạo đầu tiên là ≤ 1−ϵ.
- Xác suất hi nhất quán với m mẫu huấn luyện đầu tiên là ≤ (1 − ϵ)m.
- Xác suất. rằng ít nhất một ℎ𝑖 nhất quán với m mẫu huấn luyện đầu tiên là ≤ k(1−ϵ)m ≤ |H| (1 − ϵ)m.
- Tính giá trị của m sao cho |H| (1 − ϵ)m ≤ δ
- Sử dụng thực tế là 1 − x ≤ e−x, đủ để đặt |H| e−ϵm ≤ δ
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp có thể thực hiện được

Xác suất trên các mẫu khác nhau của m mẫu huấn luyện
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp có thể thực hiện được
1) PAC: Bao nhiêu mẫu đủ để đảm bảo lỗi nhỏ whp.
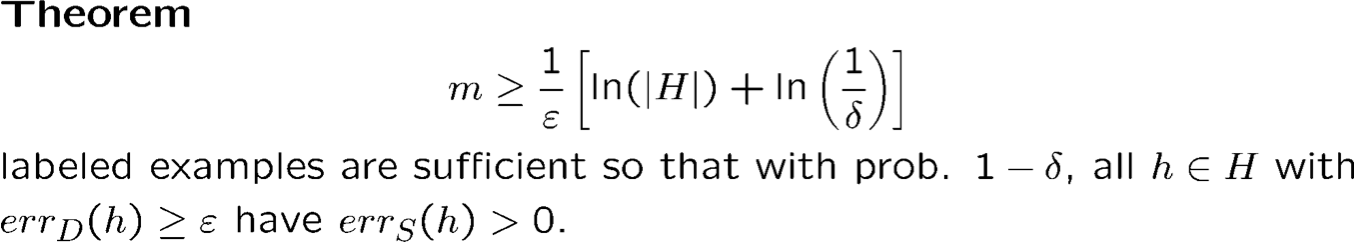
2) Cách học thống kê:
Với xác suất ít nhất là 1 − 𝛿, với mọi h ∈ H s.t. errS (h) = 0, chúng ta có
errD (h) ≤ 1⁄m (ln |H| + ln(1⁄𝛿)).
Học có giám sát: Mô hình PAC (Valiant)
- X – không gian thể hiện, ví dụ: X = {0,1}n hoặc X = Rn
- Sl={(xi, yi)} – các mẫu có nhãn được rút ra i.i.d. từ một số distr. D trên X và được gắn nhãn bởi một số khái niệm đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán A PAC-học lớp khái niệm H nếu đối với bất kỳ c* đích nào trong H, bất kỳ phân phối nào. D trên X, bất kỳ ϵ, δ > 0:
- A sử dụng nhiều nhất poly(n,1/ϵ,1/δ,size(c*)) mẫu và thời gian chạy.
- Với xác suất. 1-δ, A tạo ra h trong H chứa lỗi ở mức ≤ ϵ.
Hội tụ đồng nhất
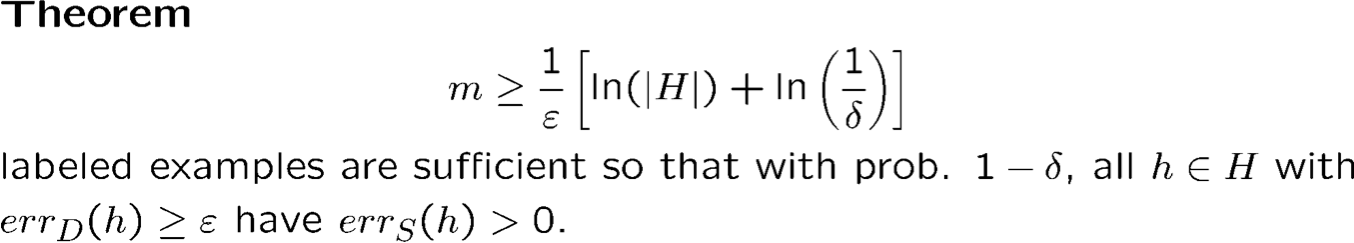
- Kết quả cơ bản này chỉ giới hạn khả năng một giả thuyết tồi có vẻ hoàn hảo trên dữ liệu. Nếu không có h∈H hoàn hảo (trường hợp bất khả tri) thì sao?
- Chúng ta có thể nói gì nếu c∗ ∉ H?
- Chúng ta có thể nói rằng whp tất cả h∈H thỏa mãn |errD(h) – errS(h)| ≤ ϵ?
- Gọi là “sự hội tụ đều”.
- Thúc đẩy tối ưu hóa trên S, ngay cả khi chúng ta không thể tìm thấy một hàm số hoàn hảo.
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp có thể thực hiện được
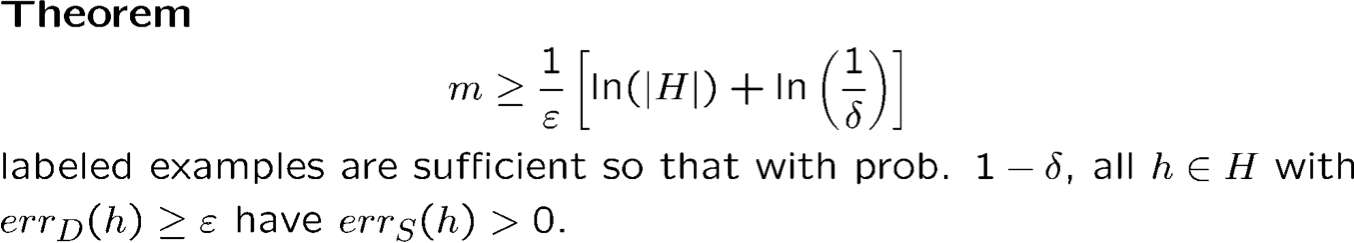
Trường hợp bất khả tri
Nếu không có h hoàn hảo thì sao?
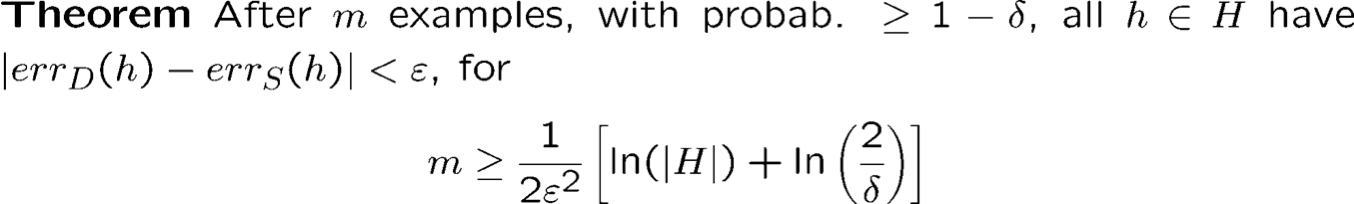
Để chứng minh các giới hạn như thế này, cần một số bất đẳng thức đuôi tốt.
Giới hạn Hoeffding
Xem xét đồng xu thiên vị p lật m lần.
Gọi N là # mặt ngửa được quan sát. Cho ε∈ [0,1].
Giới hạn Hoeffding:
- Pr[N/m > p + ε] ≤ e-2mε2, và
- Pr[N/m < p – ε] ≤ e-2mε2.
Hàm mũ giảm dần
- Bất đẳng thức đuôi: khối lượng xác suất bị ràng buộc ở đuôi phân phối (mức độ tập trung của một biến ngẫu nhiên xung quanh kỳ vọng của nó).
Độ phức tạp của mẫu: Giả thuyết hữu hạn Không gian
Trường hợp bất khả tri
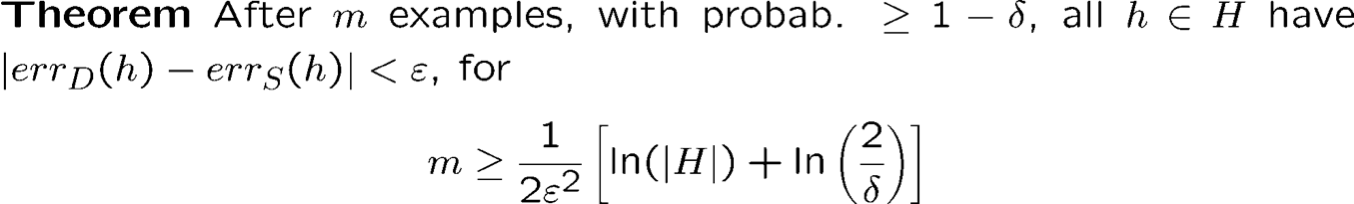
- Bằng chứng: Chỉ cần áp dụng Hoeffding.
- Cơ hội thất bại nhiều nhất là 2|H|e-2|S|ε2.
- Đặt thành 𝛿. Giải quyết.
- Vì vậy, whp, tốt nhất trên mẫu là ε-tốt nhất so với D.
- Lưu ý: giới hạn này tệ hơn giới hạn trước (1/ε đã trở thành 1/ε2), bởi vì chúng ta đang yêu cầu một thứ gì đó mạnh hơn.
- Cũng có thể có giới hạn “giữa” hai cái này.