
Hôm nay:
- Mô hình đồ họa
- Bayes Nets:
- EM
- Phân cụm Gaussian hỗn hợp
- Học cấu trúc Bayes Net (Chow-Liu)
Bài đọc:
- Bishop chương 8
- Mitchell chương 6
Học Bayes Nets
- Bốn loại vấn đề học
- Cấu trúc đồ thị có thể được biết/không biết
- Các giá trị biến có thể được quan sát đầy đủ/không quan sát được một phần
- Trường hợp dễ dàng: học các thông số cho cấu trúc đồ thị đã biết và dữ liệu được quan sát đầy đủ
- Trường hợp thú vị: đồ thị đã biết, dữ liệu đã biết một phần
- Trường hợp khủng khiếp: cấu trúc đồ thị chưa biết, dữ liệu không được quan sát một phần
Thuật toán EM – không chính thức
EM là một quy trình chung để học từ dữ liệu được quan sát một phần
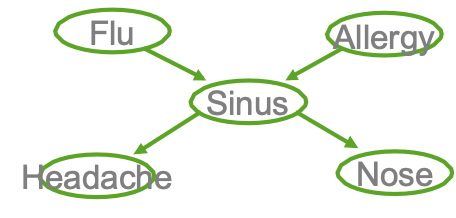
Cho các biến quan sát X, không quan sát Z (X={F,A,H,N}, Z={S})
Bắt đầu với sự lựa chọn tùy ý cho các tham số θ
Lặp lại cho đến khi hội tụ:
- Bước E: ước tính các giá trị của Z không quan sát được, sử dụng θ
- Bước M: sử dụng các giá trị được quan sát cộng với các ước tính bước E để rút ra một θ tốt hơn
Đảm bảo tìm được cực đại cục bộ.
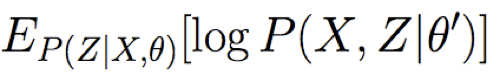
Thuật toán EM – Chính xác
EM là một quy trình chung để học từ dữ liệu được quan sát một phần
Cho các biến quan sát X, Z không quan sát (X={F,A,H,N}, Z={S}) 
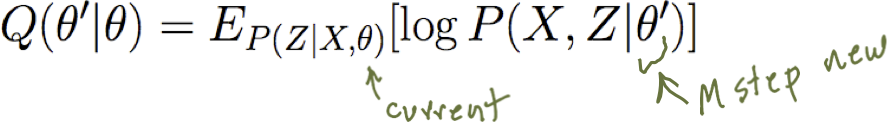
Lặp lại cho đến khi hội tụ:
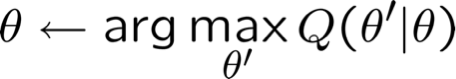
Đảm bảo để tìm cực đại cục bộ.
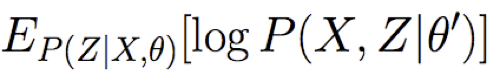
Bước E: Sử dụng X, θ, để Tính P(Z|X,θ)
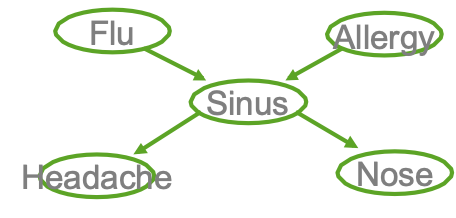
quan sát được X={F,A,H,N}, không quan sát được Z={S}
- Thế nào? Vấn đề suy luận mạng Bayes.
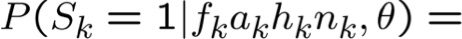
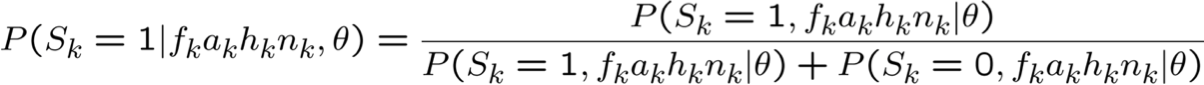
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
EM và ước tính θs|ij
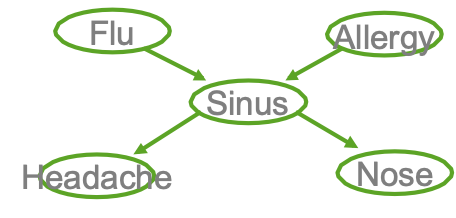
quan sát X = {F,A,H,N}, không quan sát Z={S}
Bước E: Tính P(Zk|Xk; θ) cho mỗi mẫu huấn luyện, k
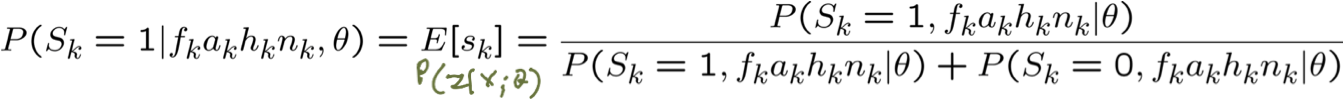
Bước M: cập nhật tất cả các tham số liên quan. Ví dụ:
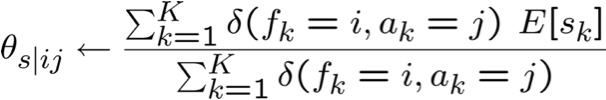
EM và ước tính θ
Tổng quát hơn,
Cho tập X được quan sát, tập Z không được quan sát của các giá trị boolean
Bước E: Tính toán cho từng mẫu đào tạo, k
- giá trị kỳ vọng của từng biến không được quan sát trong mỗi mẫu đào tạo
Bước M:
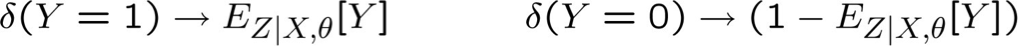
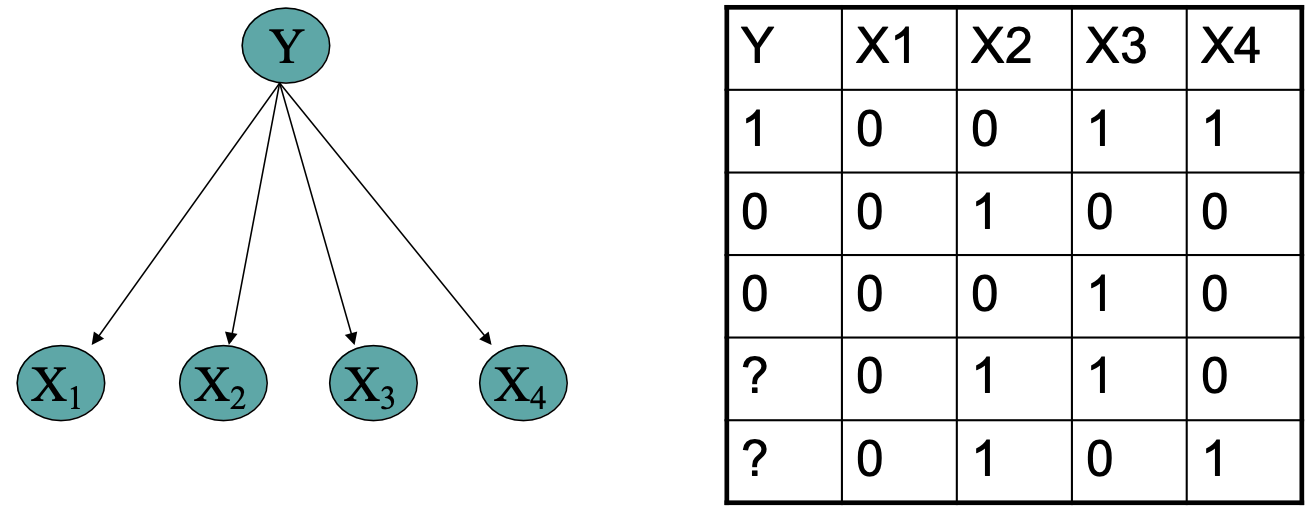
Sử dụng dữ liệu chưa được gắn nhãn để giúp đào tạo Bộ phân loại Naïve Bayes
Học P(Y|X)
EM và ước lượng θ
Cho tập quan sát X, tập Y không quan sát gồm các giá trị boolean
Bước E: Tính toán cho từng mẫu huấn luyện, k
- giá trị kỳ vọng của từng biến không quan sát Y
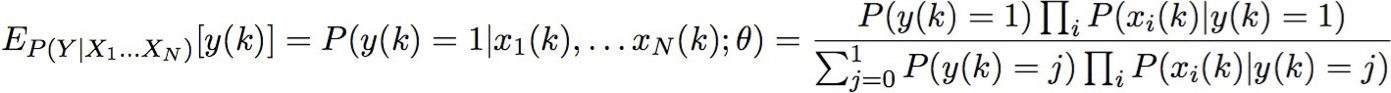
Bước M: Tính toán ước tính tương tự như MLE, nhưng thay thế từng số lượng bằng số lượng kỳ vọng của nó
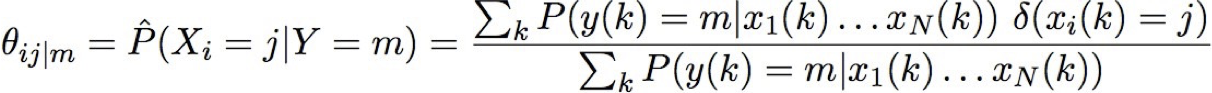
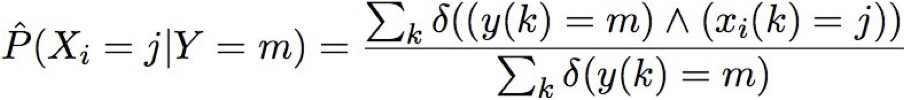
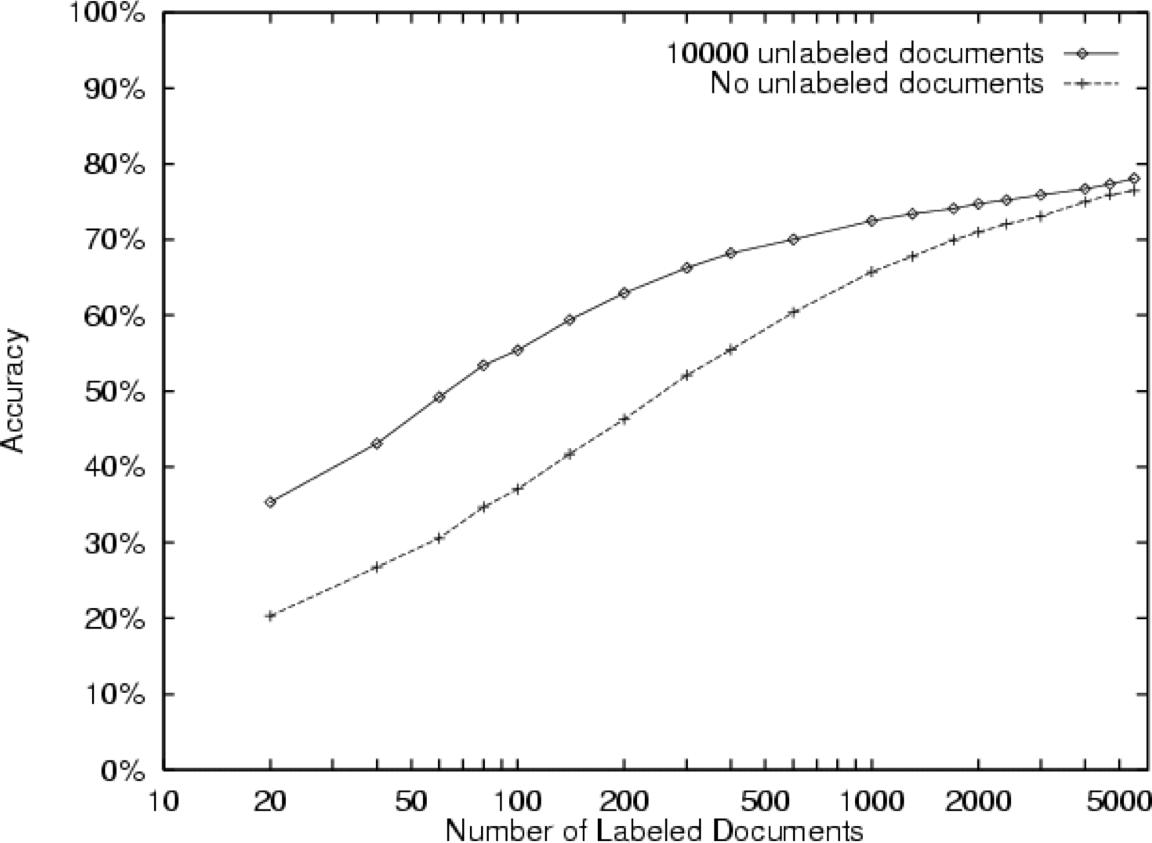
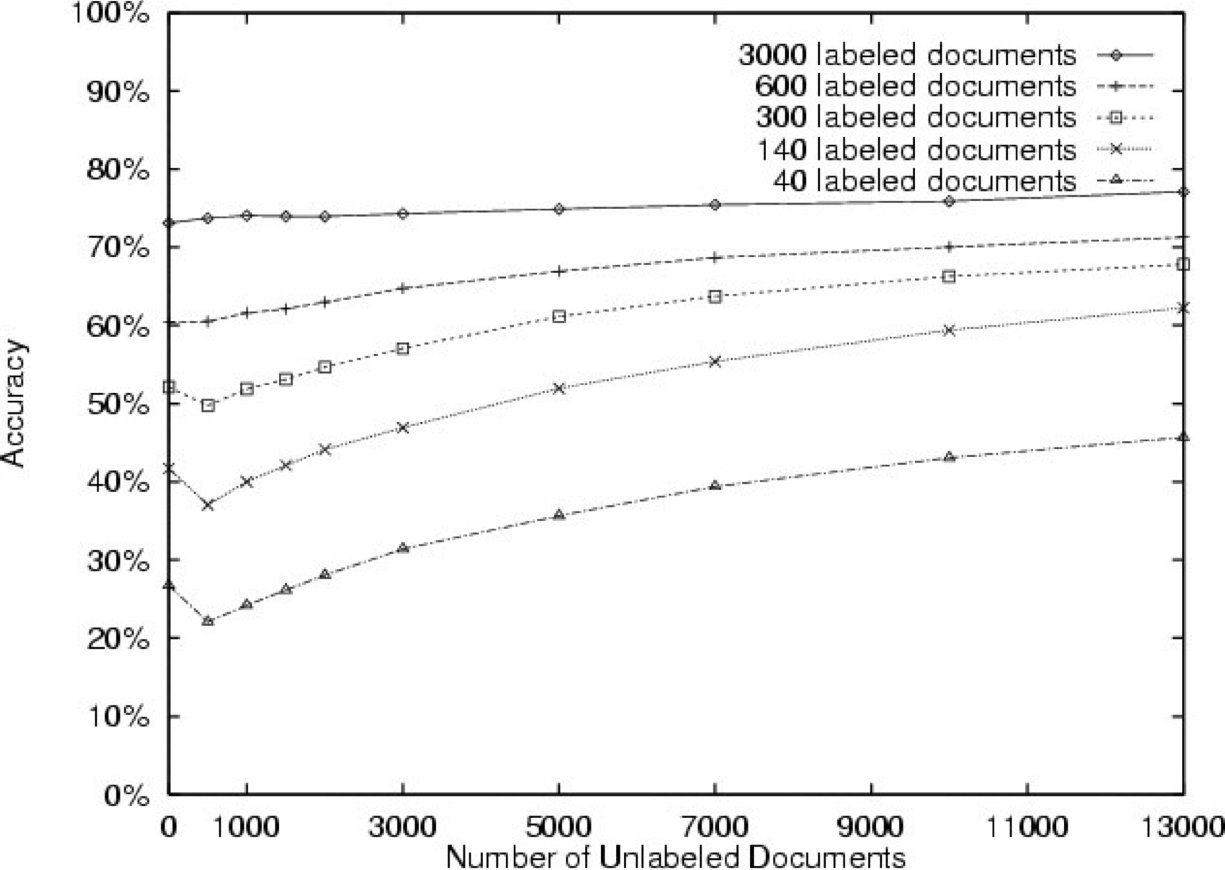
Đánh giá thử nghiệm
Từ [Nigam et al., 2000]
- Các bài đăng trong nhóm tin
- 20 nhóm tin, 1000/nhóm
- Phân loại trang web
- sinh viên, khoa, khóa học, dự án
- 4199 trang web
- Các bài báo của Reuters
- 12.902 bài báo
- 90 danh mục chủ đề
20 Nhóm tin

từ w được xếp hạng theo P(w|Y=course) / P(w|Y ≠ course)
Sử dụng một mẫu được gắn nhãn cho mỗi lớp
20 Nhóm tin
Phân cụm không giám sát
Chỉ là trường hợp đặc biệt đối với EM với các mẫu không được gắn nhãn…
Phân cụm
- Tập hợp các điểm dữ liệu đã cho, nhóm chúng lại
- Học không giám sát
- Bệnh nhân nào giống nhau? (hoặc những trận động đất, khách hàng, khuôn mặt, trang web, …)
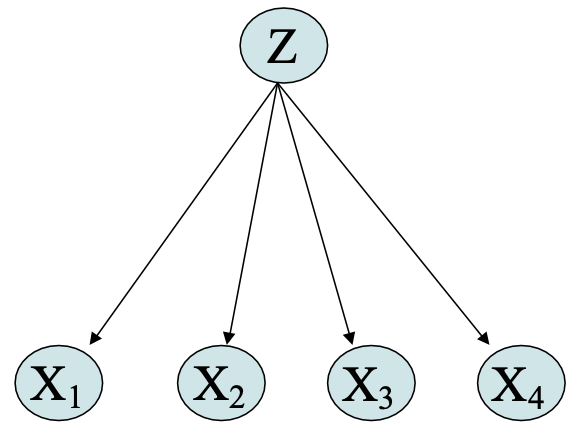
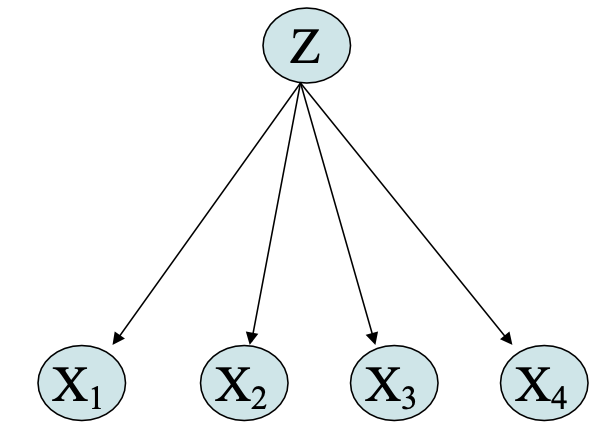
Phân phối hỗn hợp
Mô hình liên kết P(X1 . . . Xn) dưới dạng hỗn hợp của nhiều phân phối.
Sử dụng var Z ngẫu nhiên có giá trị rời rạc để cho biết phân phối nào đang được sử dụng cho mỗi lần rút ngẫu nhiên
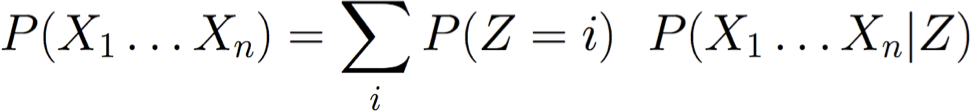
Hỗn hợp Gaussian:
- Giả sử mỗi điểm dữ liệu X=<X1, … Xn> được tạo bởi một trong số nhiều Gaussian, như sau:
1. chọn ngẫu nhiên Gaussian i, theo P(Z=i)
2. tạo ngẫu nhiên một điểm dữ liệu <x1,x2 .. xn> theo N(µi, Σi)
Hỗn hợp Gaussian
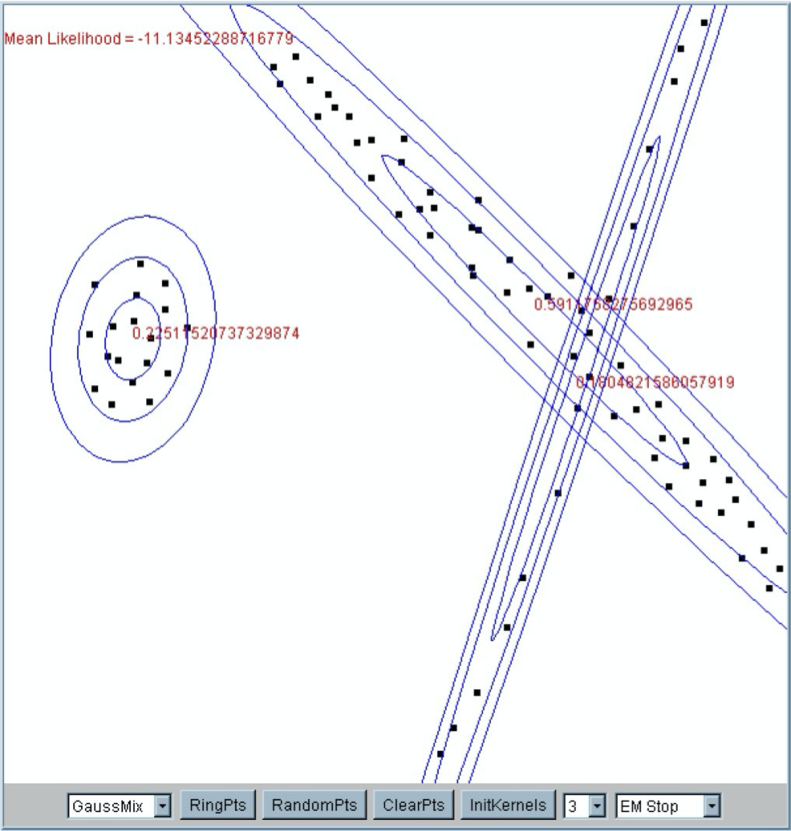
EM cho phân cụm Gaussian hỗn hợp
Hãy đơn giản hóa để làm điều này dễ dàng hơn:
- giả sử X=<X1 … Xn>, và Xi độc lập có điều kiện với Z đã cho.
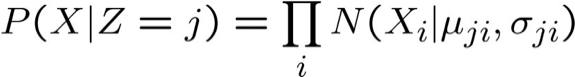
- giả sử chỉ có 2 cụm (giá trị của Z), và
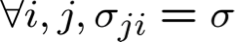
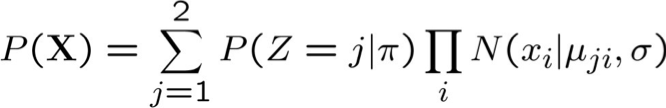
- Giả sử σ đã biết, π1 … πK, µ1i …µKi chưa biết
Quan sát: X=<X1 … Xn>, Không quan sát: Z
EM
Cho các biến quan sát X, không quan sát Z
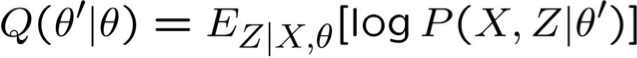
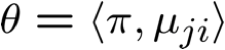
Lặp lại cho đến khi hội tụ:
- Bước E: Tính P(Z(n)|X(n),θ) cho mỗi mẫu X(n). Sử dụng điều này để xây dựng
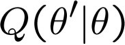
- Bước M: Thay thế θ hiện tại bằng
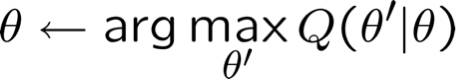
EM – Bước E
Tính P(Z(n)|X(n),θ) cho mỗi mẫu được quan sát X(n)
X(n)=<x1(n), x2(n), … xT(n)>.
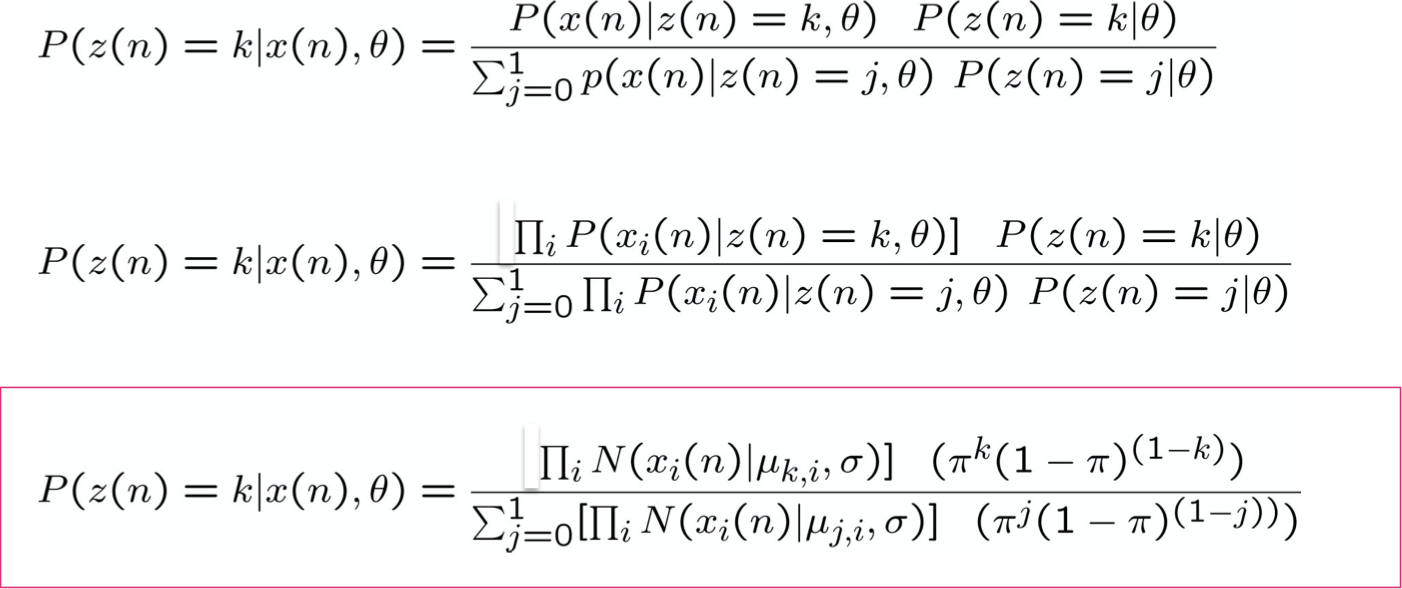
EM – Bước M
Trước tiên hãy xem xét cập nhật cho π

π’ không ảnh hưởng
z=1 cho mẫu thứ n
EM – Bước M
Bây giờ hãy xem xét cập nhật cho µji

µji‘ không có ảnh hưởng
So sánh ở trên với MLE nếu Z có thể quan sát được:
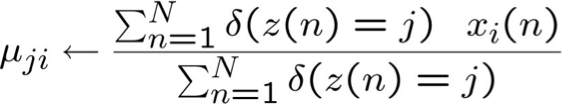
EM – đặt nó cùng nhau
Cho các biến quan sát X, Z không quan sát
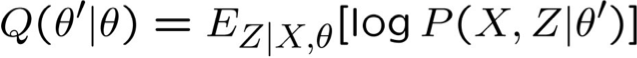
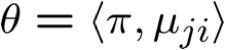
Lặp lại cho đến khi hội tụ:
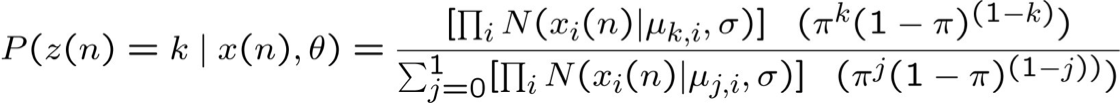
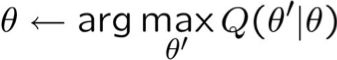
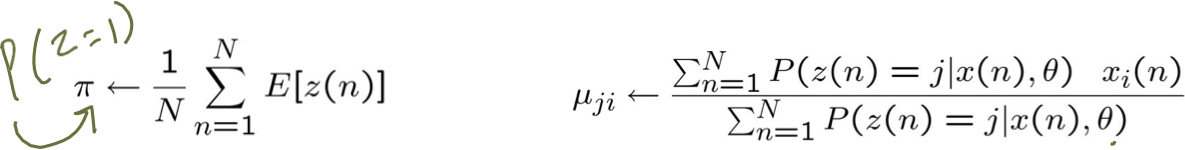
Applet Gaussian hỗn hợp
Truy cập: http://www.socr.ucla.edu/htmls/SOCR_Charts.html, sau đó vào Go to “Line Charts” → SOCR EM Mixture Chart
- thử với 2 thành phần hỗn hợp Gaussian (“kernels”)
- thử nó với 4
Những điều bạn nên biết về EM
- Đối với việc học từ dữ liệu không được quan sát một phần
- MLE của θ =
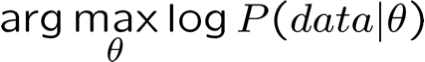
- Ước tính EM: θ =
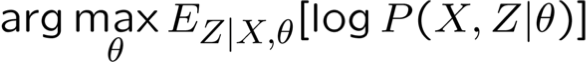
- Trong đó X được quan sát một phần của dữ liệu, Z không được quan sát
- Trường hợp tốt là mạng Bayes các vars boolean:
- Bước M giống như MLE, với các giá trị không được quan sát được thay thế bằng các giá trị kỳ vọng của chúng, với các giá trị được quan sát khác
- EM để huấn luyện mạng Bayes
- Cũng có thể phát triển phiên bản MAP của EM
- Cũng có thể rút ra thuật toán EM của riêng bạn cho vấn đề của riêng bạn
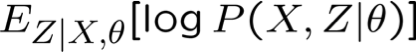
Học Cấu trúc mạng Bayes
Làm thế nào chúng ta có thể học cấu trúc đồ thị Bayes Net?
Trong trường hợp chung, bài toán mở
- có thể yêu cầu nhiều dữ liệu (nếu không sẽ có nguy cơ quá khớp cao)
- có thể sử dụng các phương pháp Bayes để hạn chế tìm kiếm
Một kết quả chính:
- Thuật toán Chow-Liu: tìm mạng cấu trúc cây “tốt nhất”
- Cái gì tốt nhất?
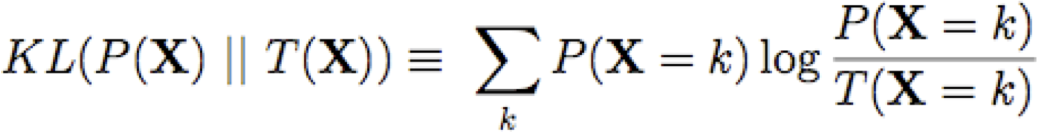
Thuật toán Chow-Liu
Kết quả chính: Để giảm thiểu KL(P || T), chỉ cần tìm mạng cây T tối đa hóa tổng thông tin lẫn nhau trên các cạnh của nó
Thông tin lẫn nhau cho một cạnh giữa biến A và B:
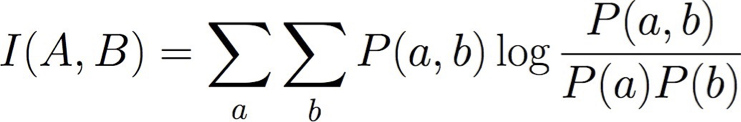
Điều này hoạt động vì đối với các mạng cây có nút 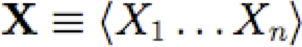
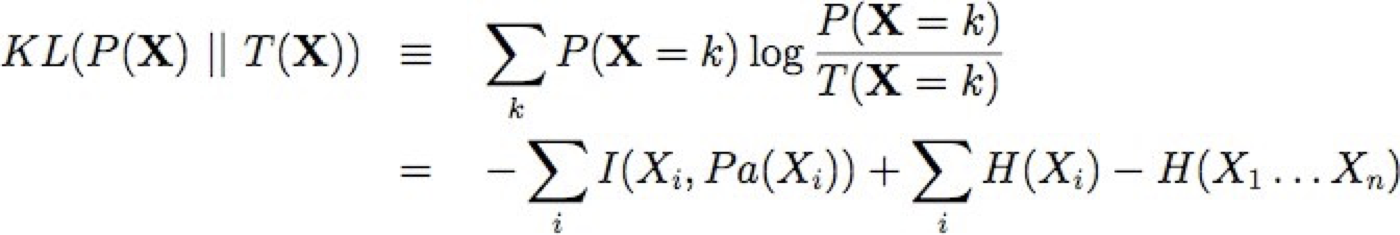
Thuật toán Chow-Liu
- đối với mỗi cặp biến A,B, sử dụng dữ liệu để ước tính P(A,B), P(A), P(B)
- đối với mỗi cặp biến A, B, tính toán thông tin lẫn nhau
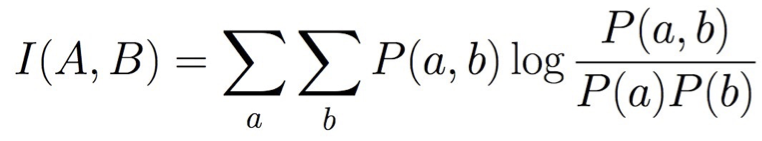
- tính toán cây bao trùm tối đa trên tập hợp các biến, sử dụng trọng số cạnh I(A,B)
- (cho N biến, điều này chỉ tốn thời gian O(N2))
- thêm mũi tên vào các cạnh để tạo thành đồ thị không tuần hoàn có hướng
- học CPD cho đồ thị này
Ví dụ về thuật toán Chow-Liu, Thuật toán tham lam để tìm Cây bao trùm tối đa
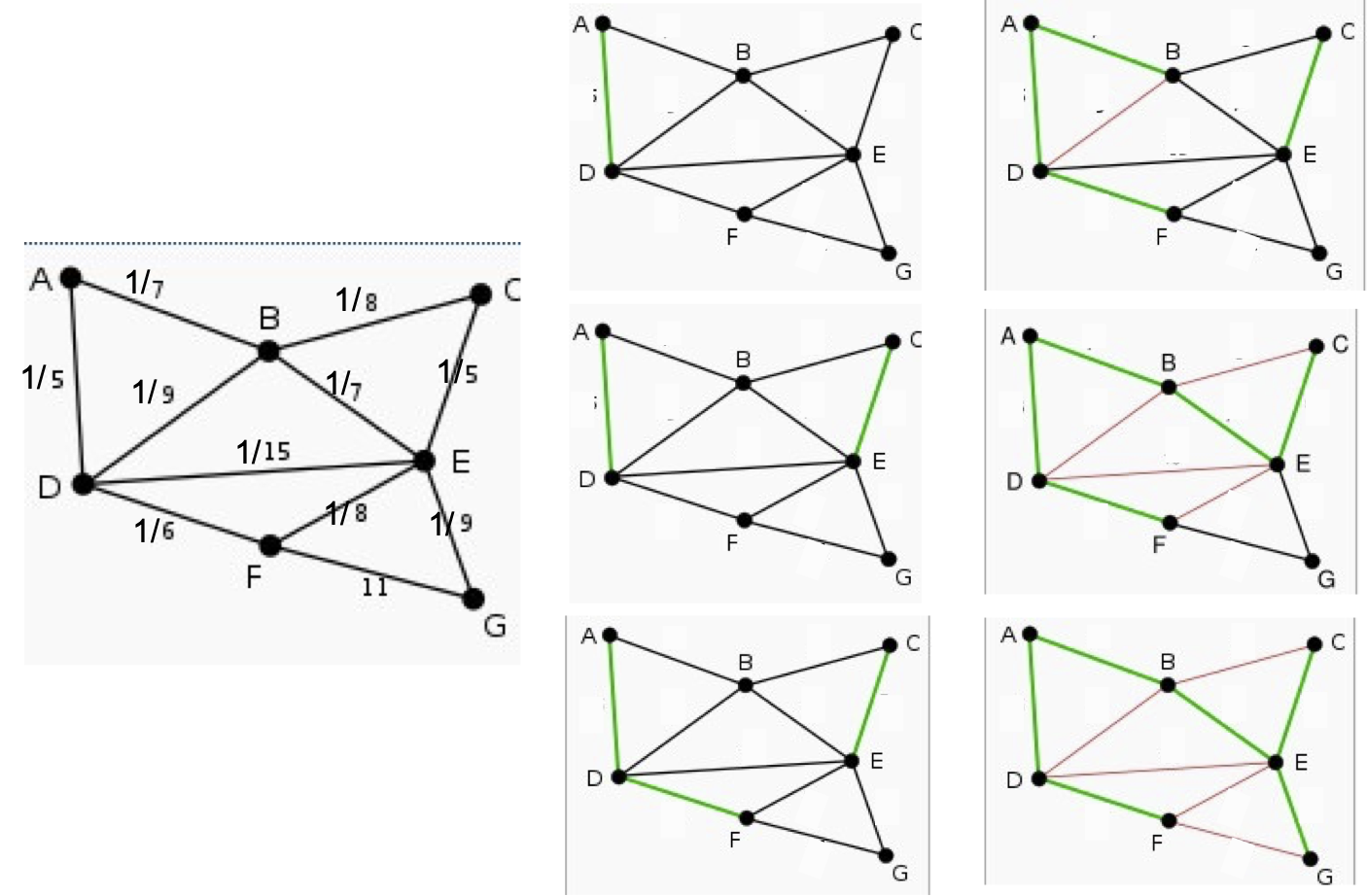
[nhờ sự giúp đỡ A. Singh, C. Guestrin]
Bayes Nets – Những điều bạn Nên biết
- Biểu diễn
- Mạng Bayes biểu thị phân phối đồng thời dưới dạng DAG + Phân phối có điều kiện
- Phân tách D cho phép chúng ta giải mã các giả định độc lập có điều kiện
- Suy luận
- NP-hard nói chung
- Đối với một số biểu đồ, suy luận dạng đóng là khả thi
- Các phương pháp gần đúng cũng vậy, ví dụ: phương pháp Monte Carlo, …
- Học tập
- Dễ dàng đối với biểu đồ đã biết, dữ liệu được quan sát đầy đủ (MLE’s, MAP est.)
- EM đối với dữ liệu được quan sát một phần, biểu đồ đã biết
- Học cấu trúc biểu đồ: Chow-Liu đối với mạng cấu trúc cây
- Khó nhất khi biểu đồ chưa biết, dữ liệu được quan sát không đầy đủ