
Hôm nay:
- Naïve Bayes
- Xi có giá trị rời rạc
- Phân loại tài liệu
- Gaussian Naïve Bayes
- Xi có giá trị thực
- Phân loại hình ảnh não
Bài đọc:
Bắt buộc:
- Mitchell: “Naïve Bayes và Logistic Regression” (có trên trang web của lớp)
Tùy chọn
- Bishop 1.2.4
- Bishop 4.2
Gần đây:
- Phân loại Bayes để học P(Y|X)
- Ước tính MLE và MAP cho các tham số của P
- Độc lập có điều kiện
- Naïve Bayes → làm cho việc học Bayes trở nên thiết thực
Tiếp theo:
- Phân loại văn bản
- Naïve Bayes và các biến liên tục Xi:
- Bộ phân loại Gaussian Naïve Bayes
- Học trực tiếp P(Y|X)
- Hồi quy logistic, Chính quy hóa, tăng dần độ dốc
- Bayes Naïve hay Hồi quy logistic?
- Các phân loại tạo sinh và phân biệt
Sơ lược về Naïve Bayes
Quy tắc Bayes:
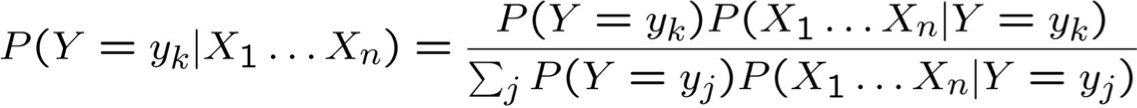
Giả định sự độc lập có điều kiện giữa Xi‘s:
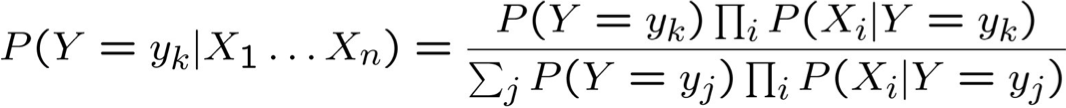
Vì vậy, quy tắc phân loại cho Xnew = < X1, …, Xn > là:
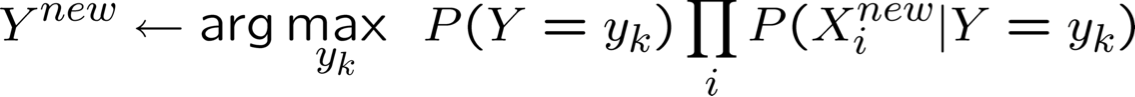
Ví dụ: Sống ở Sq Hill? P(S|G,D,B)
- S=1 nếu sống ở Squirrel Hill
- G=1 nếu mua sắm tại SH Giant Eagle
- D=1 nếu lái xe hoặc đi chung xe đến CMU
- B=1 nếu sinh nhật trước ngày 1 tháng 7


Tom: D=1, G=0, B=0
P(S=1|D=1,G=0,B=0) =
P(S=1) P(D=1|S=1) P(G=0|S=1) P(B=0|S=1)
[P(S=1) P(D=1|S=1) P(G=0|S=1) P(B=0|S=1) + P(S=0) P(D=1|S=0) P(G=0|S=0) P(B=0|S=0)]
Một cách khác để xem Naïve Bayes (Boolean Y):
Quy tắc quyết định: đại lượng này lớn hơn hay nhỏ hơn 1?
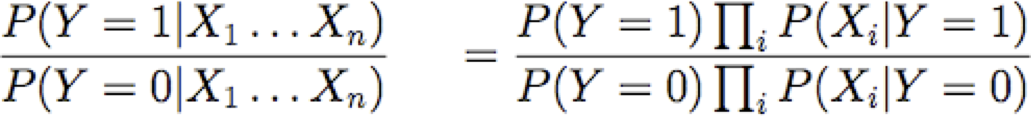
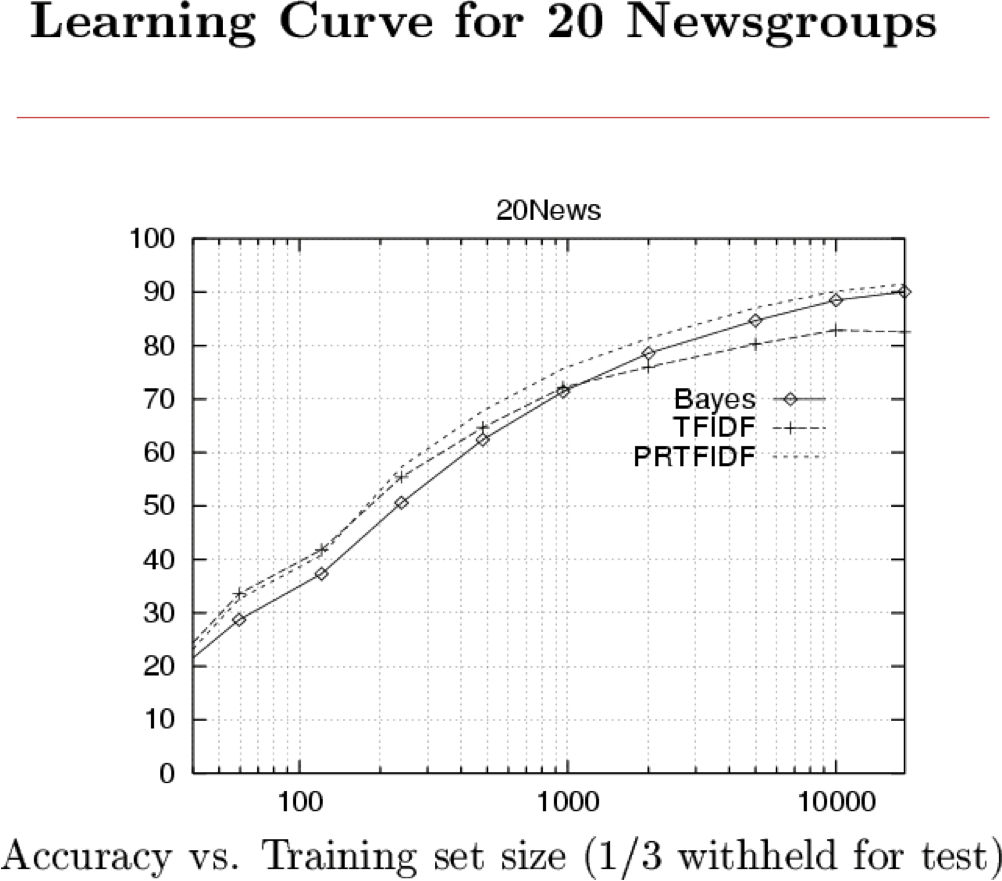
Naïve Bayes: phân loại tài liệu văn bản
- Phân loại email nào là thư rác?
- Phân loại những email hứa hẹn một tập tin đính kèm?

Làm thế nào chúng ta sẽ trình bày các tài liệu văn bản cho Naïve Bayes?
Học cách phân loại tài liệu: P(Y|X)

- Y có giá trị rời rạc.
- ví dụ: Spam hay không
- X = <X1, X2, … Xn> = tài liệu
- Xi là biến ngẫu nhiên mô tả…
Học phân loại tài liệu: P(Y|X)

- Y có giá trị rời rạc.
- ví dụ: Spam hay không
- X = <X1, X2, … Xn> = tài liệu
- Xi là một biến ngẫu nhiên mô tả…
Trả lời 1: Xi là boolean, 1 nếu từ i trong tài liệu, ngược lại 0,
ví dụ: Xpleased = 1
Vấn đề?
Học cách phân loại tài liệu: P(Y|X)

- Y có giá trị rời rạc.
- ví dụ: Spam hay không
- X = <X1, X2, … Xn> = tài liệu
- Xi là một biến ngẫu nhiên mô tả…
Trả lời 2:
- Xi đại diện cho vị trí từ thứ i trong tài liệu
- X1 = “I”, X2 = “am”, X3 = “pleased”
- và giả sử Xi là iid (indep, được phân phối giống hệt nhau)
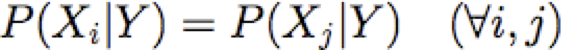
Học cách phân loại tài liệu: P(Y|X)
mô hình “Túi từ”
- Y có giá trị rời rạc. ví dụ: Spam hay không
- X = <X1, X2, … Xn> = tài liệu
- Xi là các biến ngẫu nhiên iid. Mỗi đại diện cho từ tại vị trí i của nó trong tài liệu
- Tạo tài liệu theo phân phối này = tung một con súc sắc 50.000 mặt, một lần cho mỗi vị trí từ trong tài liệu
- Số lượng quan sát được cho mỗi từ theo sau một ??? phân phối
Phân phối đa thức

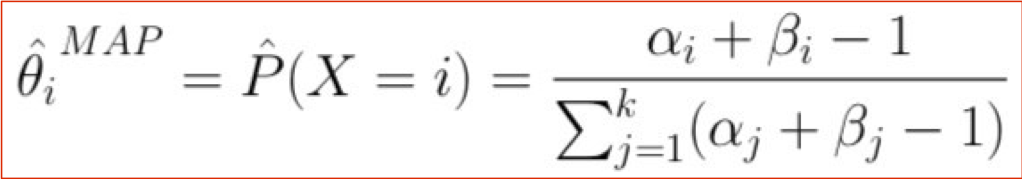
Túi từ đa thức

Ước tính MAP cho túi từ
Ước tính Map cho đa thức
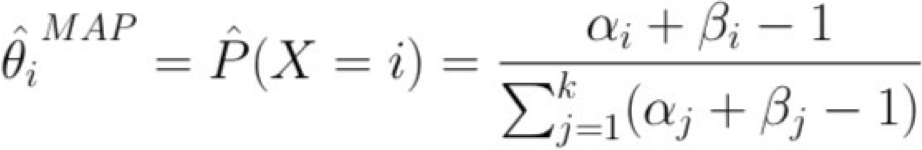
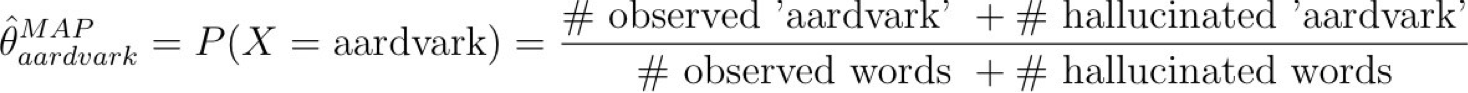
Chúng ta nên chọn những β gì?
Thuật toán Naïve Bayes – Xi rời rạc
- Huấn luyện Naïve Bayes (mẫu)
- cho từng giá trị yk
- Phân loại (Xnew)
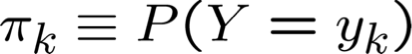
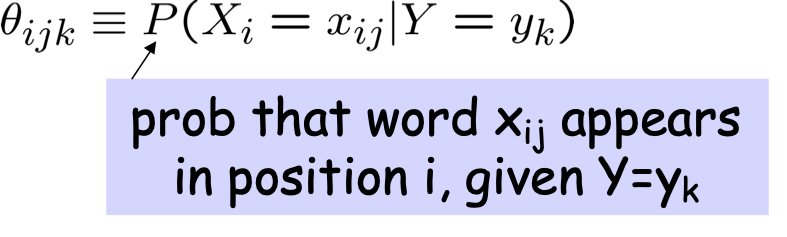
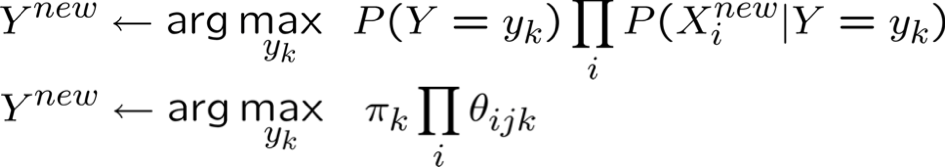
* Giả định bổ sung: xác suất từ không phụ thuộc vào vị trí

Để biết mã và dữ liệu, hãy xem www.cs.cmu.edu/~tom/mlbook.html nhấp vào “Phần mềm và Dữ liệu”
Nếu chúng ta có Xi liên tục thì sao?
Ví dụ: phân loại hình ảnh: Xi là pixel thứ i có giá trị thực
Nếu chúng ta có Xi liên tục thì sao?
Ví dụ: phân loại hình ảnh: Xi là pixel thứ i có giá trị thực
Naïve Bayes yêu cầu P(Xi | Y=yk), nhưng Xi là thực (liên tục)
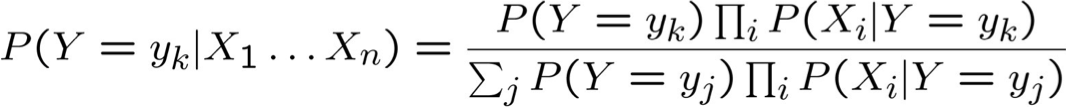
Cách tiếp cận phổ biến: giả sử P(Xi | Y=yk) tuân theo phân phối Chuẩn (Gaussian)
Nếu chúng ta có Xi liên tục thì sao?
Ví dụ: phân loại hình ảnh: Xi là pixel thứ i có giá trị thực
Naïve Bayes yêu cầu P(Xi | Y=yk), nhưng Xi là thực (liên tục)
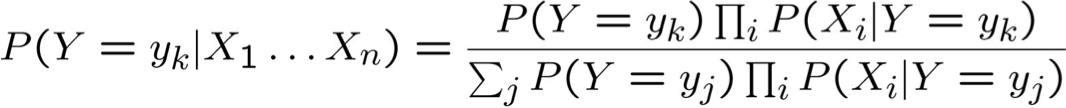
Cách tiếp cận phổ biến: giả sử P(Xi | Y=yk) tuân theo phân phối Chuẩn (Gaussian)
Phân phối Gaussian
(còn được gọi là “Chuẩn”)
p(x) là một hàm mật độ xác suất, có tích phân (không phải tổng) là 1

Nếu chúng ta có Xi liên tục thì sao?
Gaussian Naïve Bayes (GNB): giả sử
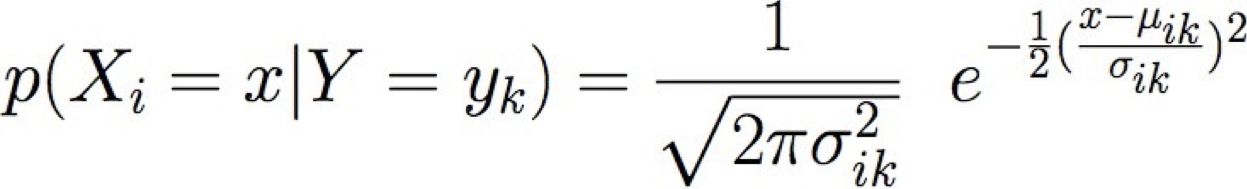
Đôi khi, giả sử phương sai
- độc lập với Y (tức là σi),
- hoặc độc lập với Xi (tức là σk)
- hoặc cả hai (tức là σ)
Thuật toán Gaussian Naïve Bayes – Xi liên tục
(nhưng Y vẫn rời rạc)
- Huấn luyện Naïve Bayes (mẫu)
- cho mỗi giá trị yk
- Phân loại (Xnew)
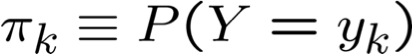
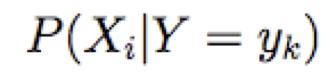
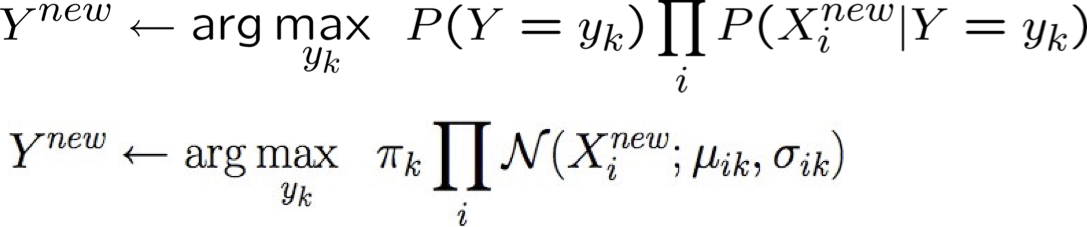
* xác suất phải có tổng bằng 1, vì vậy chỉ cần ước tính n-1 tham số…
Ước tính tham số: Y rời rạc, Xi liên tục
Ước tính khả năng tối đa:
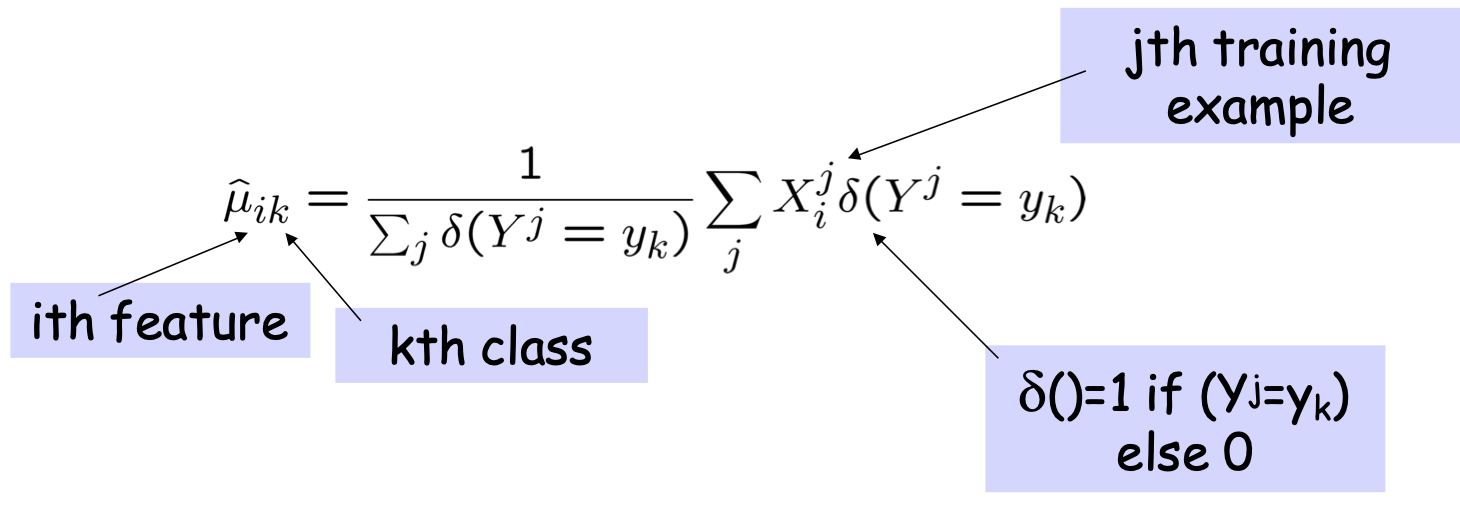
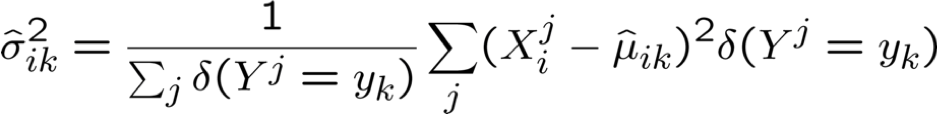
Có bao nhiêu tham số chúng ta phải ước lượng Gaussian Naïve Bayes nếu Y có k giá trị có thể, X=<X1, … Xn>?
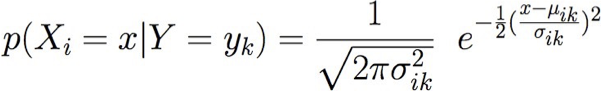
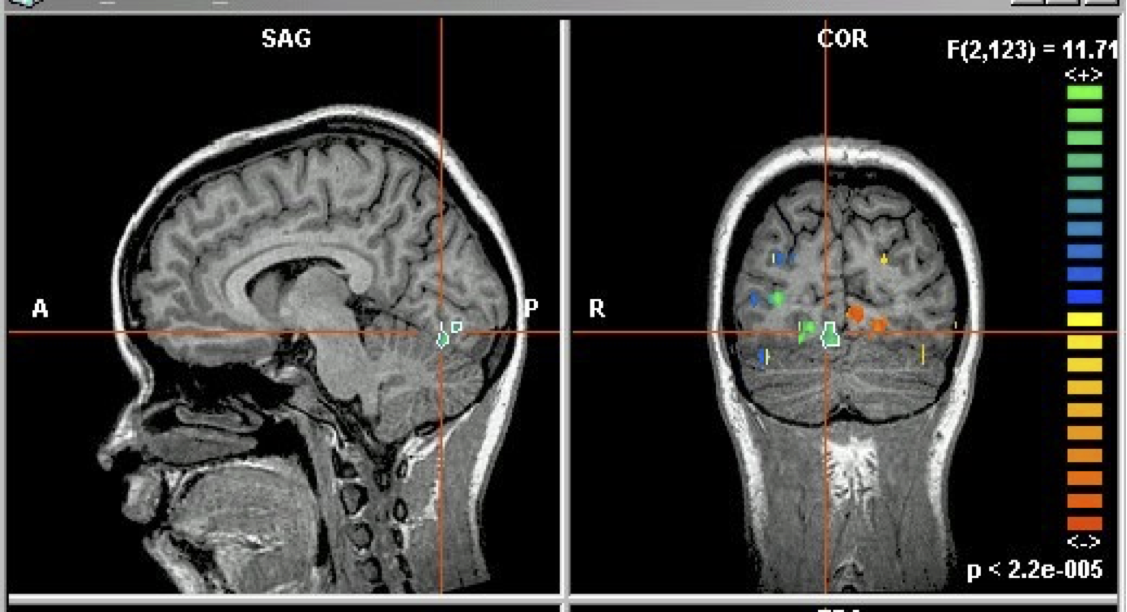
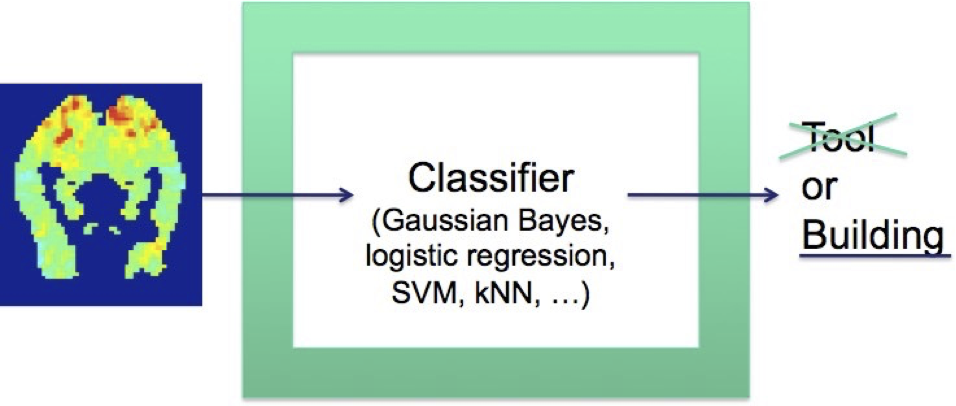
Ví dụ GNB: Phân loại trạng thái nhận thức của một người, dựa trên hình ảnh não bộ
- đọc một câu hay xem một bức tranh?
- đọc từ mô tả “Công cụ” hoặc “Tòa nhà”?
- trả lời câu hỏi, hoặc bối rối?
Kích hoạt trung bình trên tất cả các ví dụ đào tạo cho Y=“bottle”
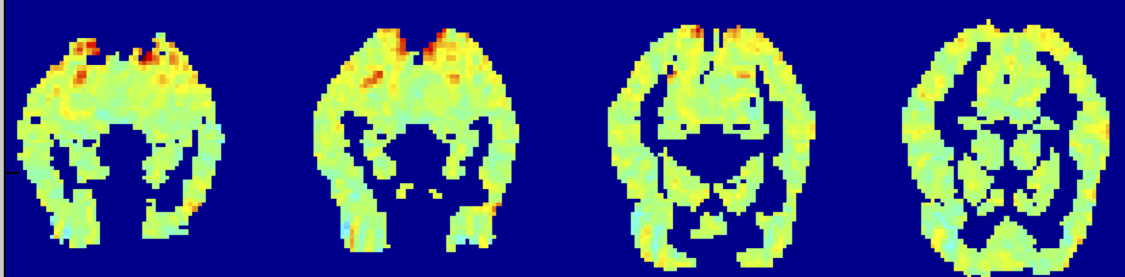
Y là trạng thái tinh thần (đọc là “ngôi nhà” hoặc “cái chai”)
Xi là các hoạt động của điểm ảnh ba chiều,
đây là biểu đồ của µ’s xác định P(Xi | Y=“bottle”)
Kích hoạt fMRI
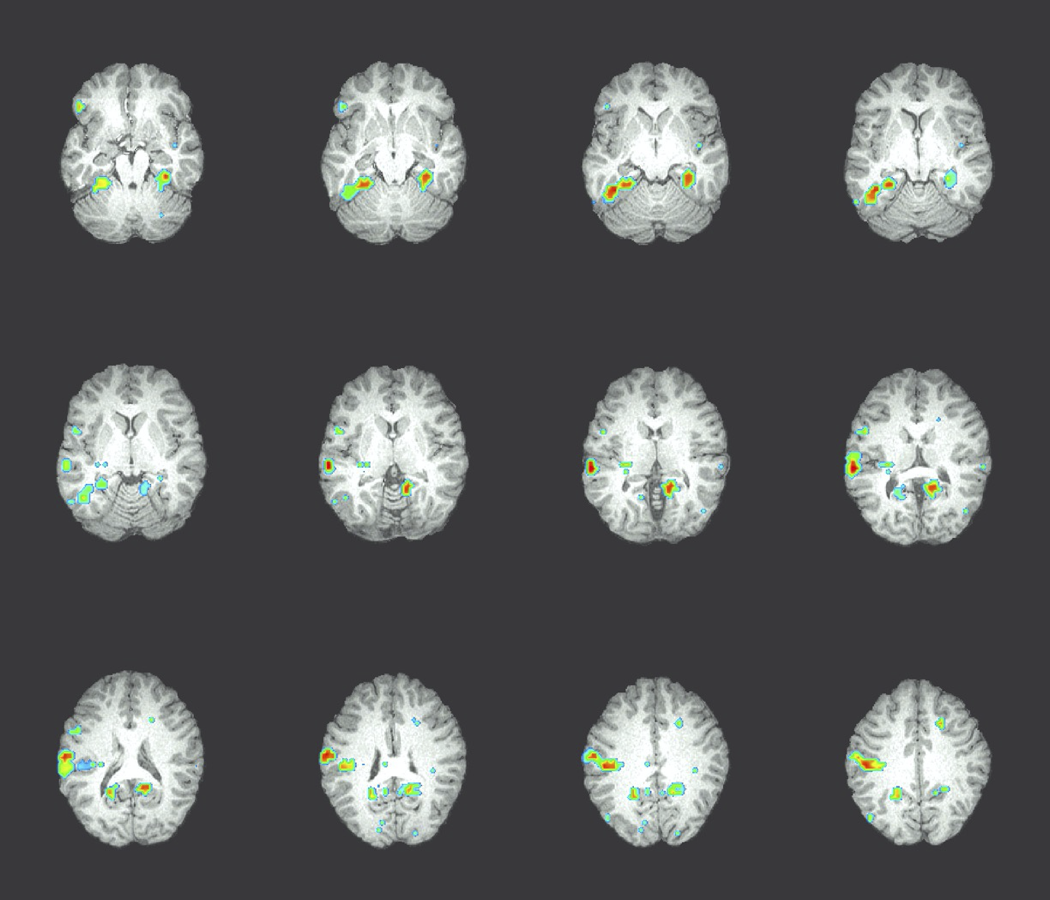
Nhiệm vụ phân loại: là người đang xem “công cụ” hoặc “tòa nhà”?
Thông tin được mã hóa ở đâu trong não?
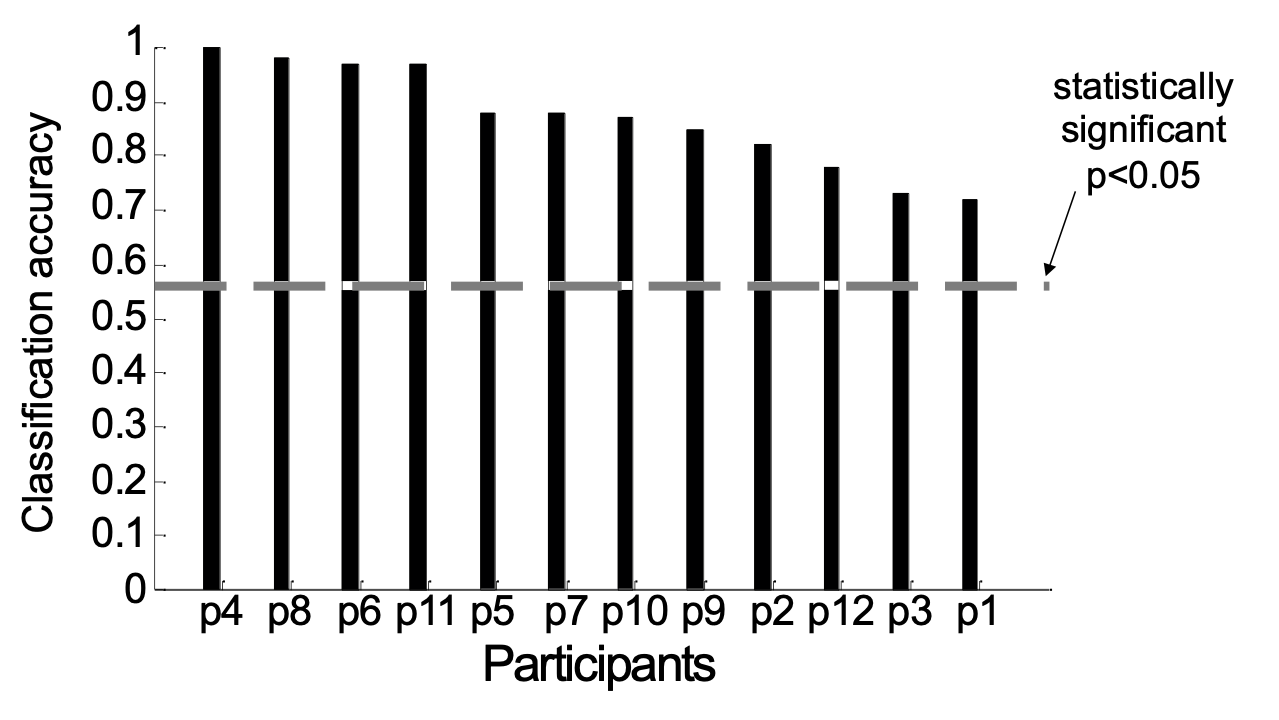
Độ chính xác của bộ phân loại 27-voxel lập phương có tâm tại mỗi điểm ảnh ba chiều quan trọng [0,7–0,8]

Naïve Bayes: Những điều bạn nên biết
- Thiết kế bộ phân loại dựa trên quy tắc Bayes
- Tính độc lập có điều kiện
- Nó là gì
- Tại sao nó lại quan trọng
- Giả định Naïve Bayes và hệ quả của nó
- Tham số nào (và bao nhiêu) phải được ước tính theo các mô hình tổng quát khác nhau (các dạng khác nhau cho P(X|Y) )
- và tại sao điều này lại quan trọng
- Tham số nào (và bao nhiêu) phải được ước tính theo các mô hình tổng quát khác nhau (các dạng khác nhau cho P(X|Y) )
- Cách đào tạo bộ phân loại Naïve Bayes
- ước tính MLE và MAP
- với đầu vào rời rạc và/hoặc liên tục Xi
Các câu hỏi cần suy nghĩ:
- Bạn có thể sử dụng Naïve Bayes để kết hợp Xi rời rạc và giá trị thực không?
- Làm thế nào chúng ta có thể dễ dàng mô hình hóa chỉ 2 trong số n thuộc tính là phụ thuộc?
- Bề mặt quyết định của bộ phân loại Naïve Bayes trông như thế nào?
- Bạn sẽ chọn một tập con của Xi như thế nào?