
Bài đọc tham khảo
Hôm nay:
- Mô hình đồ họa
- Bayes Nets:
- Suy luận
- Học tập
- EM
Readings:
- Bishop chương 8
- Mitchell chương 6
Giữa học kỳ
- Trong lớp vào Thứ Hai, ngày 2 tháng 3
- Không sử dụng sách tham khảo
- Bạn có thể mang theo “bảng ghi chú” 8,5 x 11
- Bao gồm tất cả các tài liệu cho đến ngày hôm nay
- Hãy chắc chắn đến đúng giờ. Chúng tôi sẽ bắt đầu chính xác lúc 12 giờ trưa
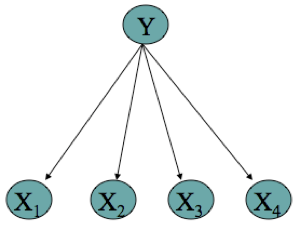
Mạng Bayesian Định nghĩa
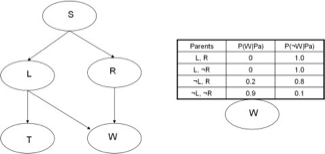
Mạng Bayes biểu thị phân phối xác suất đồng thời trên một tập hợp các biến ngẫu nhiên
Mạng Bayes là một đồ thị không tuần hoàn có hướng và một tập hợp các phân phối xác suất có điều kiện (CPD’s)
- Mỗi nút biểu thị một biến ngẫu nhiên
- Các cạnh biểu thị các phụ thuộc
- Đối với mỗi nút Xi, CPD của nó xác định P(Xi | Pa(Xi))
- Phân phối đồng thời trên tất cả các biến được định nghĩa là
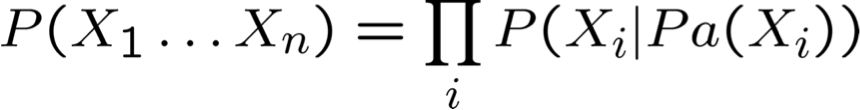
Pa(X) = cha mẹ trực tiếp của X trong biểu đồ
Những điều bạn nên biết
- Mạng Bayes là biểu diễn thuận tiện cho việc mã hóa các phụ thuộc/độc lập có điều kiện
- BN = Đồ thị cộng tham số của CPD
- Xác định phân phối đồng thời trên các biến
- Có thể tính toán mọi thứ khác từ đó
- Mặc dù suy luận có thể khó
- Đọc các quan hệ độc lập có điều kiện từ đồ thị
- Mỗi nút độc lập có điều kiện với các nút không phải con cháu, chỉ được cho trước cha mẹ của nó
- X và Y độc lập có điều kiện cho trước Z nếu Z D-tách mọi đường dẫn nối X với Y
- Độc lập cận biên : trường hợp đặc biệt khi Z={}
Suy luận trong Bayes Nets
- Nói chung, khó kiểm soát (NP-đầy đủ)
- Đối với một số trường hợp nhất định, dễ kiểm soát
- Gán xác suất cho tập hợp các biến được quan sát đầy đủ
- Hoặc nếu chỉ một biến không được quan sát
- Hoặc cho các đồ thị được kết nối đơn lẻ (nghĩa là không có vòng lặp vô hướng)
- Lan truyền niềm tin
- Đôi khi sử dụng các phương pháp Monte Carlo
- Tạo nhiều mẫu theo phân phối Bayes Net, sau đó đếm kết quả
- Các phương pháp khác nhau cho các giải pháp gần đúng có thể xử lý được
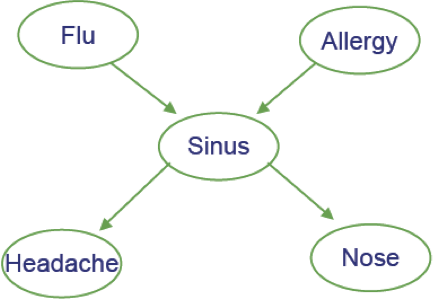
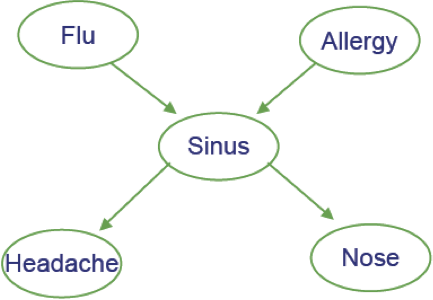
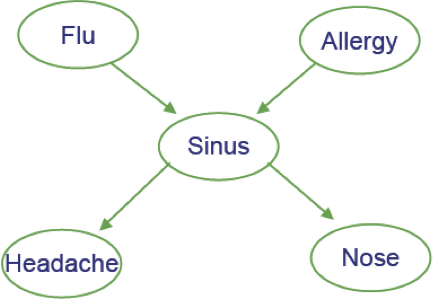
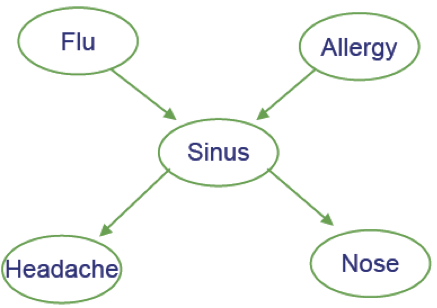
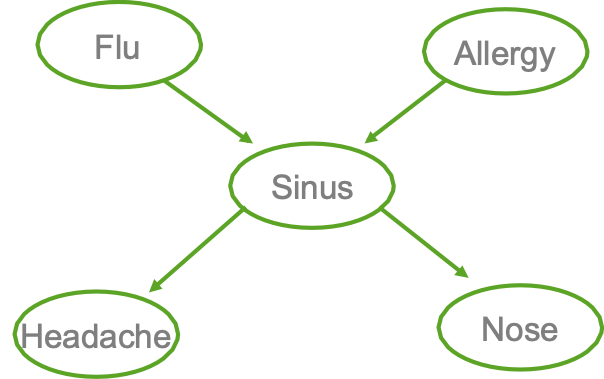
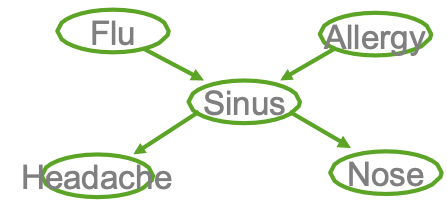
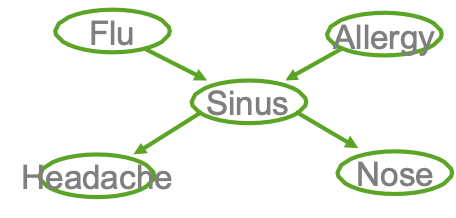
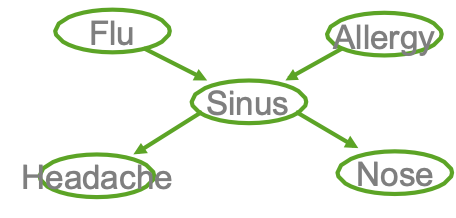
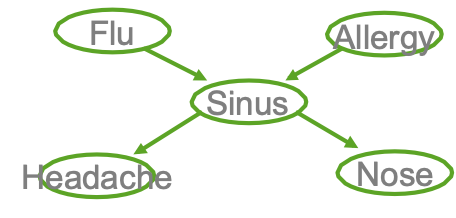
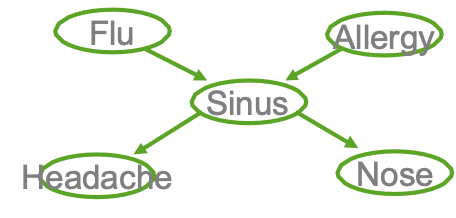
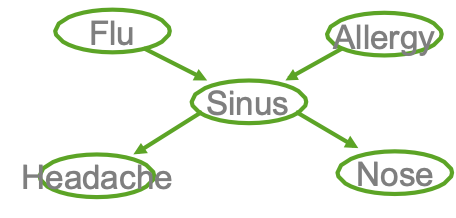
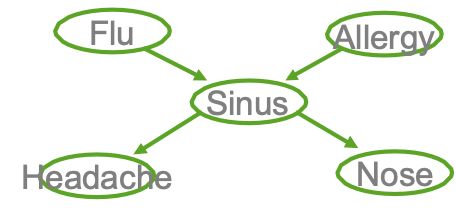
Ví dụ
- Cúm gia cầm và Allegies đều gây ra các vấn đề về xoang
- Các vấn đề về xoang gây ra Đau đầu và sổ mũi
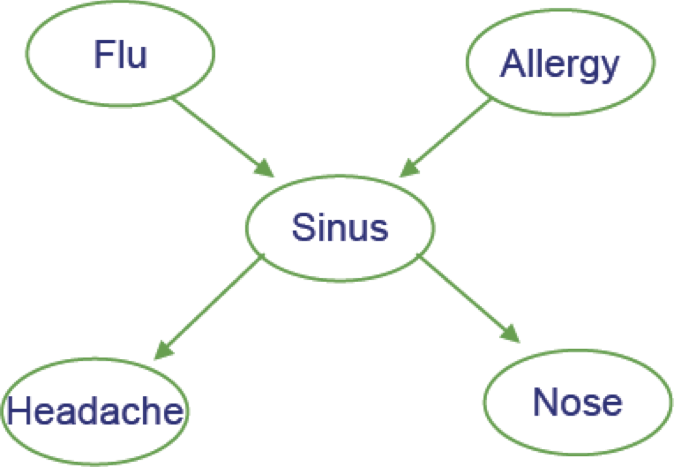
Xác suất nhiệm vụ chung: dễ dàng
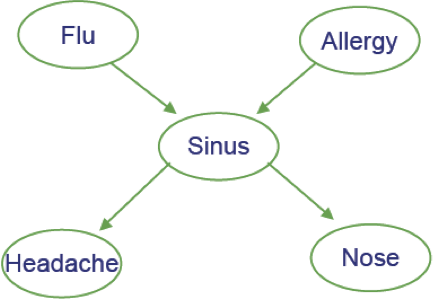
- Giả sử chúng ta quan tâm đến nhiệm vụ chung phân công <F=f,A=a,S=s,H=h,N=n>
P(f,a,s,h,n) là gì?
hãy sử dụng p(a,b) làm cách viết tắt của p(A=a, B=b)
Xác suất cận biên: không dễ
- Làm cách nào để tính P(N=n) ?
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
Tạo mẫu từ phân phối đồng thời: dễ dàng
Làm thế nào chúng ta có thể tạo mẫu ngẫu nhiên được rút ra theo P(F,A,S,H,N)?
Gợi ý: mẫu ngẫu nhiên của F theo P(F=1) = θF=1 :
- rút ra giá trị của r đều từ [0,1]
- nếu r<θ thì xuất F=1, ngược lại F=0
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
Tạo mẫu từ phân phối đồng thời: dễ dàng
Làm thế nào chúng ta có thể tạo mẫu ngẫu nhiên được rút ra theo P(F,A,S,H,N)?
Gợi ý: mẫu ngẫu nhiên của F theo P(F=1) = θF=1 :
- rút ra giá trị của r đều từ [0,1]
- nếu r<θ thì xuất F=1, ngược lại F=0
Giải pháp:
- rút một giá trị ngẫu nhiên f cho F, sử dụng CPD của nó
- sau đó rút các giá trị cho A, cho S|A,F, cho H|S, cho N|S
Tạo một mẫu từ phân phối đồng thời: dễ dàng
Lưu ý rằng chúng ta có thể ước tính các biên như P(N=n) bằng cách tạo nhiều mẫu từ phân phối đồng thời, sau đó đếm tỷ lệ mẫu mà N=n
Tương tự, đối với bất kỳ điều gì khác, chúng ta quan tâm đến P(F=1|H=1, N=0)
→ phương pháp yếu nhưng chung để ước tính bất kỳ số hạng xác suất nào…
Suy luận trong Bayes Nets
- Nói chung, khó kiểm soát (NP-đầy đủ)
- Đối với một số trường hợp nhất định, có thể kiểm soát được
- Chỉ định xác suất cho tập hợp các biến được quan sát đầy đủ
- Hoặc nếu chỉ một biến không được quan sát
- Hoặc đối với đồ thị liên thông đơn lẻ (nghĩa là không có vòng lặp vô hướng)
- Loại bỏ biến số
- Lan truyền niềm tin
- Thường sử dụng các phương pháp Monte Carlo
- ví dụ: Tạo nhiều mẫu theo phân phối Bayes Net, sau đó đếm kết quả
- Lấy mẫu Gibbs
- Các phương pháp biến đổi cho khả năng kiểm soát giải pháp gần đúng
xem khóa học Mô hình đồ họa 10-708
Học về Bayes Nets
- Bốn loại vấn đề học tập
- Cấu trúc đồ thị có thể được biết/chưa biết
- Các giá trị biến có thể được quan sát đầy đủ/không được quan sát một phần
- Trường hợp dễ dàng: học các thông số cho cấu trúc đồ thị đã biết và dữ liệu là quan sát đầy đủ
- Trường hợp thú vị: biểu đồ đã biết, dữ liệu đã biết một phần
- Trường hợp khủng khiếp: cấu trúc biểu đồ chưa biết, dữ liệu không được quan sát một phần
Học CPT từ dữ liệu được quan sát đầy đủ
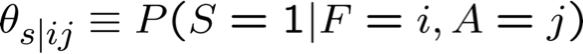
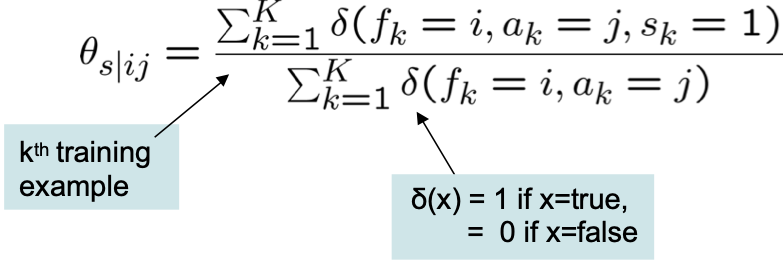
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
Ước tính θs|ij MLE từ dữ liệu được quan sát đầy đủ
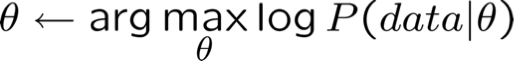
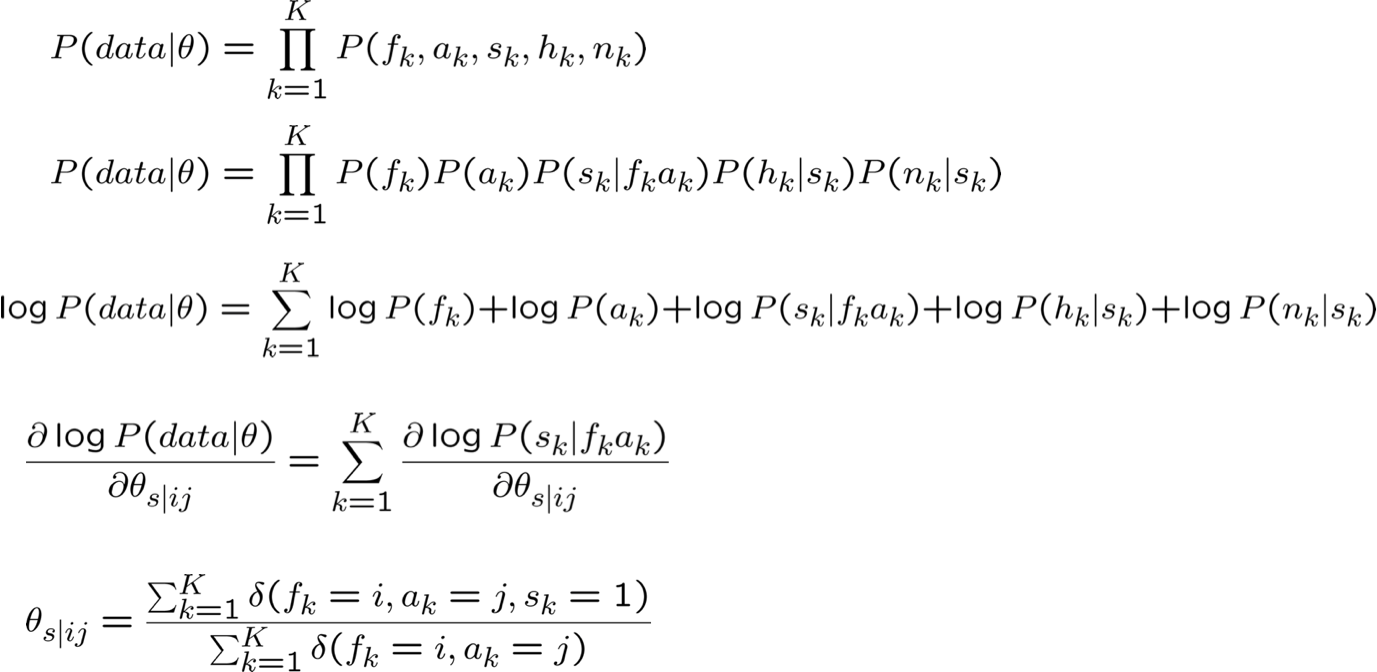
Ước tính θ từ dữ liệu được quan sát một phần
- Điều gì sẽ xảy ra nếu FAHN được quan sát, nhưng không phải S?
- Không tính được MLE
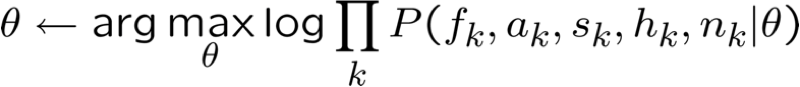
- Gọi X là tất cả các giá trị biến quan sát được (trên tất cả các mẫu)
- Gọi Z là tất cả các giá trị biến không quan sát được
- Không tính được MLE:
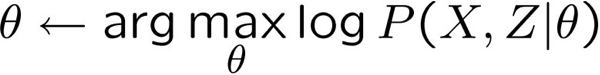
- PHẢI LÀM GÌ?
Ước tính θ từ dữ liệu được quan sát một phần
- Nếu FAHN được quan sát, nhưng không phải S thì sao?
- Không tính được MLE
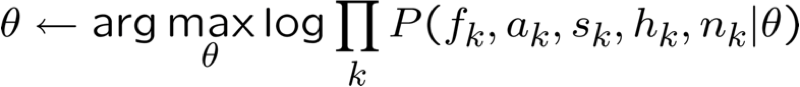
- Gọi X là tất cả các giá trị biến quan sát được (trên tất cả các mẫu)
- Gọi Z là tất cả các giá trị biến không quan sát được
- Không tính được MLE:
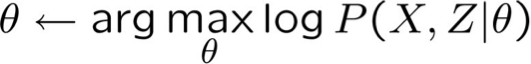
- EM tìm* ước lượng:
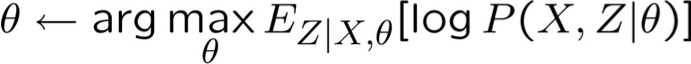
* EM đảm bảo tìm được mức tối đa cục bộ
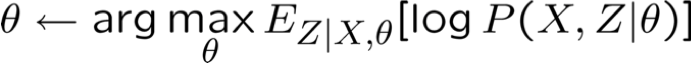
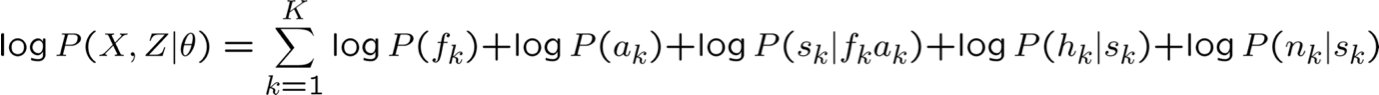
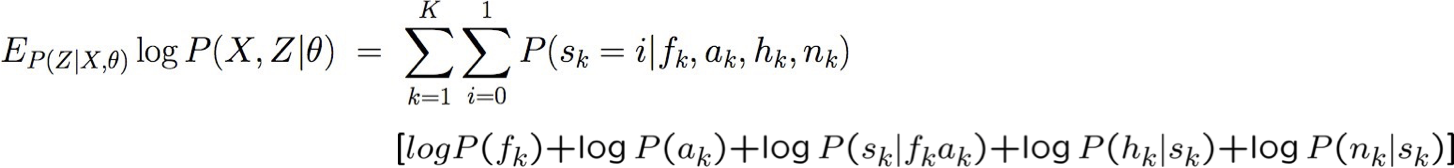
Thuật toán EM – không chính thức
EM là một quy trình chung để học hỏi từ dữ liệu được quan sát một phần
Cho các biến quan sát X, không quan sát Z (X={F,A,H,N}, Z={S})
Bắt đầu với sự lựa chọn tùy ý cho các tham số θ
Lặp lại cho đến khi hội tụ:
- Bước E: ước tính các giá trị của Z không quan sát được, sử dụng θ
- Bước M: sử dụng các giá trị được quan sát cộng với các ước tính bước E để rút ra một θ tốt hơn
Đảm bảo tìm được cực đại cục bộ.
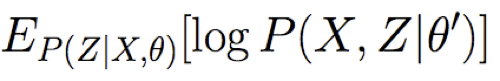
Thuật toán EM – Chính xác
EM là một quy trình chung để học từ dữ liệu được quan sát một phần
Cho các biến quan sát X, Z không quan sát (X={F,A,H,N}, Z={S}) 
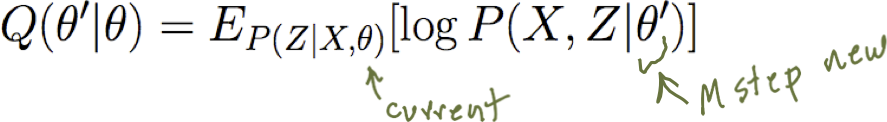
Lặp lại cho đến khi hội tụ:
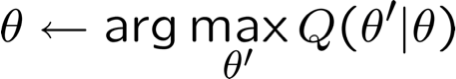
Đảm bảo để tìm cực đại cục bộ.
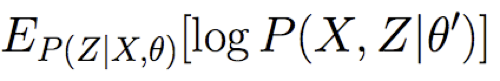
Bước E: Sử dụng X, θ, để Tính P(Z|X,θ)
quan sát được X={F,A,H,N}, không quan sát được Z={S}
- Thế nào? Vấn đề suy luận mạng Bayes.
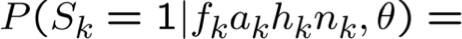
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
Bước E: Sử dụng X, θ, để Tính P(Z|X,θ)
quan sát được X={F,A,H,N}, không quan sát được Z={S}
- Bằng cách nào? Vấn đề suy luận mạng Bayes.
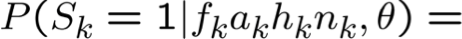
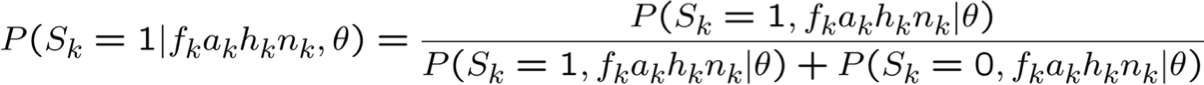
hãy sử dụng p(a,b) làm tốc ký cho p(A=a, B=b)
EM và ước tính θs|ij
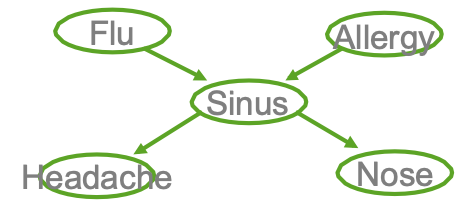
quan sát X = {F,A,H,N}, không quan sát Z={S}
Bước E: Tính P(Zk|Xk; θ) cho mỗi mẫu huấn luyện, k
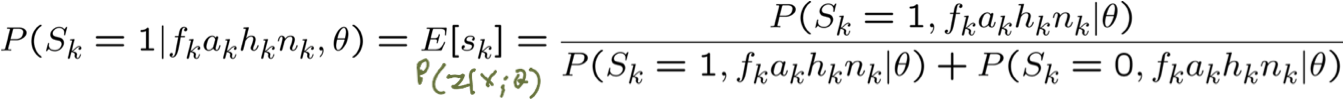
Bước M: cập nhật tất cả các tham số liên quan. Ví dụ:
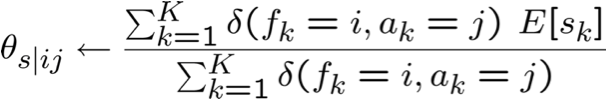
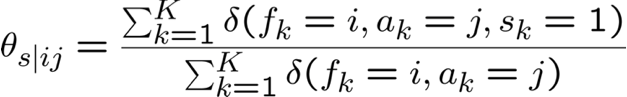
EM và ước tính θ
Tổng quát hơn,
Cho tập X quan sát được, tập Z không quan sát được của các giá trị boolean
Bước E: Tính toán cho từng mẫu đào tạo, k
- giá trị kỳ vọng của từng biến không quan sát
Bước M:
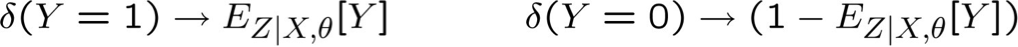
Sử dụng dữ liệu chưa được gắn nhãn để giúp huấn luyện Bộ phân loại Naïve Bayes
Học P(Y|X)
Bước E: Tính toán cho từng mẫu đào tạo, k
- giá trị kỳ vọng của từng biến không quan sát được
EM và ước tính θ
Cho tập X được quan sát, tập Y không được quan sát của các giá trị boolean
Bước E: Tính toán cho từng mẫu huấn luyện, k
- giá trị kỳ vọng của từng biến không được quan sát Y
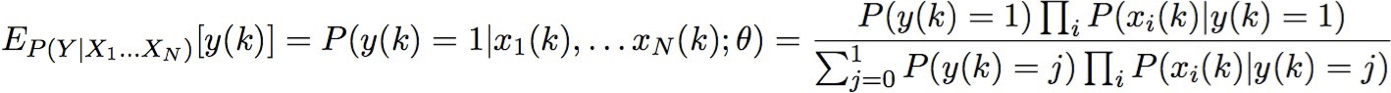
Bước M: Tính toán các ước tính tương tự như MLE, nhưng thay thế từng số đếm bằng số đếm kỳ vọng của nó
hãy sử dụng y(k) để chỉ ra giá trị của Y trên mẫu thứ k
EM và ước tính θ
Cho tập hợp X được quan sát, tập hợp Y không được quan sát của các giá trị boolean
Bước E: Tính toán cho từng mẫu đào tạo, k
- giá trị kỳ vọng của từng biến không được quan sát Y
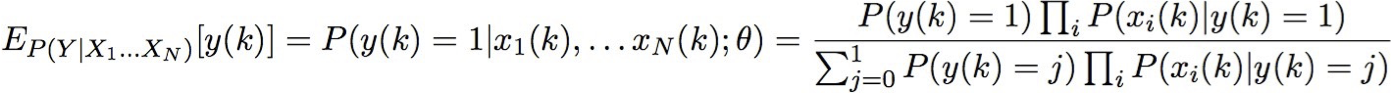
Bước M: Tính toán ước tính tương tự như MLE , nhưng thay thế mỗi số lượng bằng số lượng kỳ vọng của nó
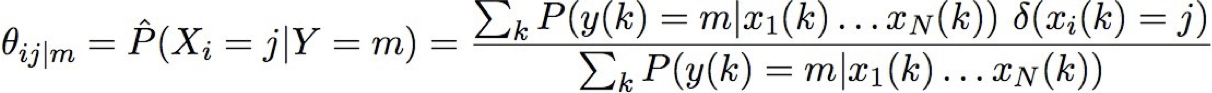
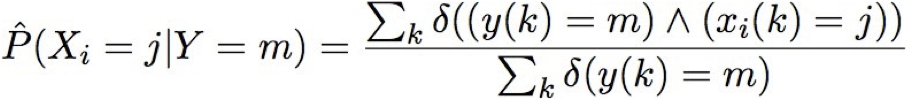
![HÌNH 13.23. Từ [Nigam et al., 2000].](https://cdn.jsdelivr.net/gh/vtgcdn/iml13.viettechgroup.com@latest/13_GrMod3fig23a.png)
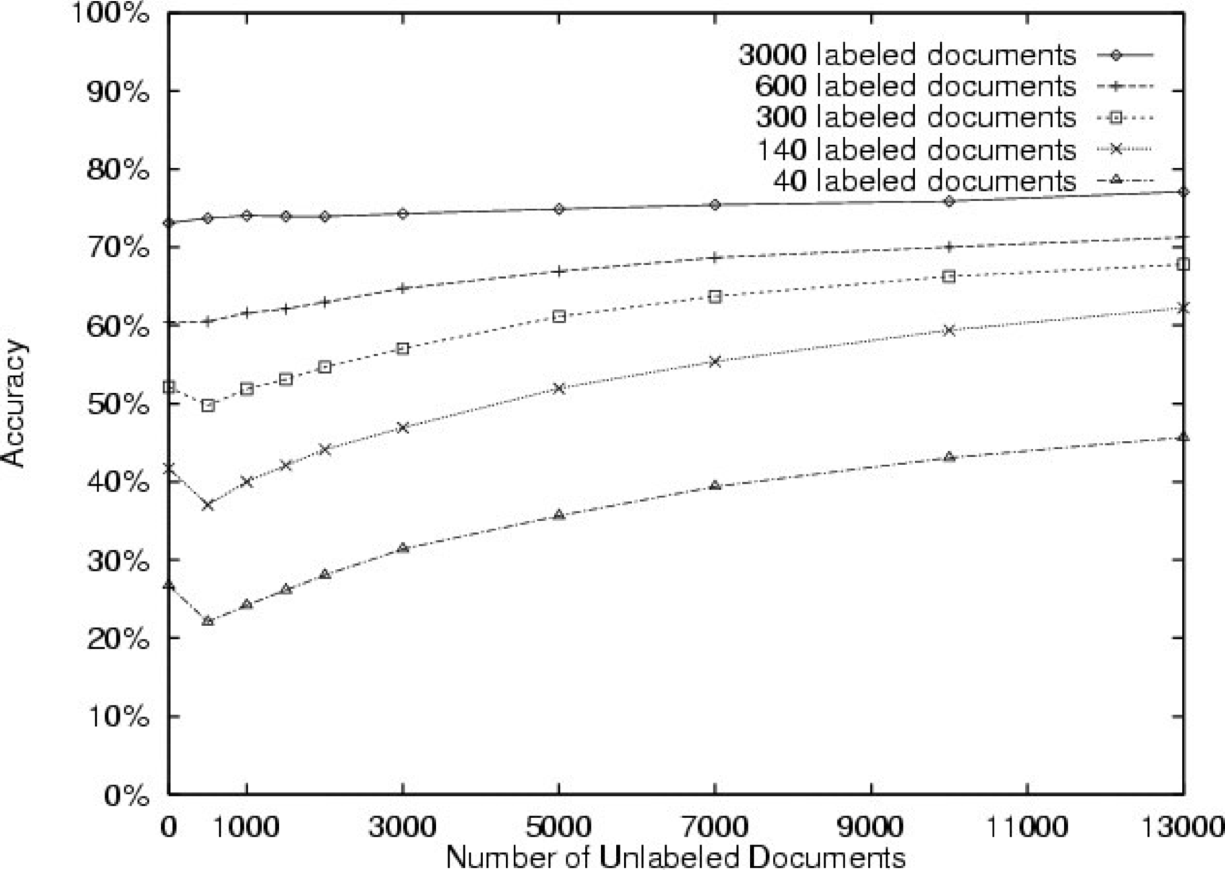
![HÌNH 13.23. Từ [Nigam et al., 2000].](https://cdn.jsdelivr.net/gh/vtgcdn/iml13.viettechgroup.com@latest/13_GrMod3fig23b.png)
Đánh giá thử nghiệm
- Các bài đăng trong nhóm tin
- 20 nhóm tin, 1000/nhóm
- Phân loại trang web
- sinh viên, giảng viên, khóa học, dự án
- 4199 trang web
- Bài báo của Reuters newswire
- 12.902 bài báo
- 90 danh mục chủ đề
20 Nhóm tin
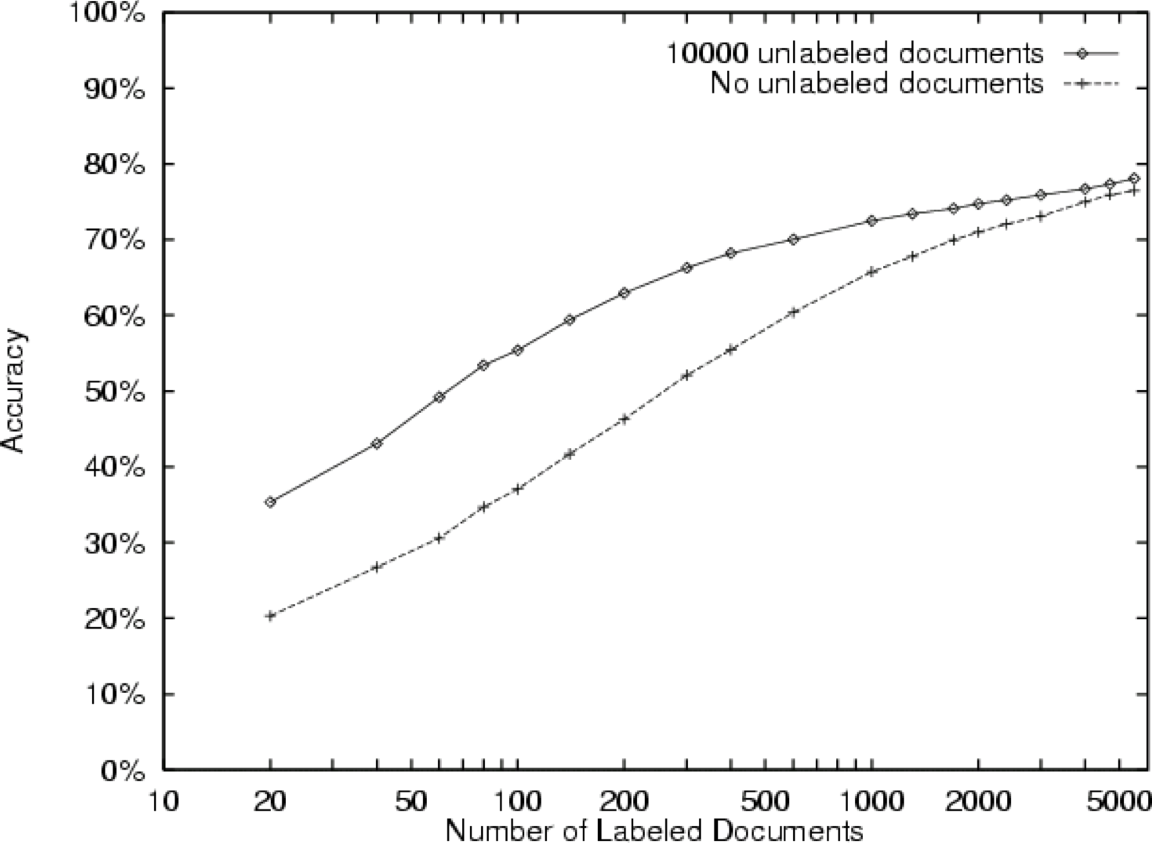

từ loại w được xếp hạng theo P(w|Y=khóa học) / P(w|Y ≠ khóa học)
Sử dụng một mẫu có nhãn cho mỗi lớp
20 Nhóm tin
Mạng lưới Bayes – Những điều bạn nên biết
- Biểu diễn
- Mạng Bayes biểu thị phân phối đồng thời dưới dạng DAG + Phân phối có điều kiện
- Phân tách D cho phép chúng ta giải mã các giả định độc lập có điều kiện
- Suy luận
- NP-nói chung là khó
- Đối với một số biểu đồ, một số truy vấn, có thể suy luận chính xác
- Các phương pháp gần đúng cũng vậy, ví dụ: phương pháp Monte Carlo, …
- Học tập
- Dễ dàng đối với biểu đồ đã biết, dữ liệu được quan sát đầy đủ (MLE’s, MAP est.)
- EM đối với dữ liệu được quan sát một phần, đã biết đồ thị