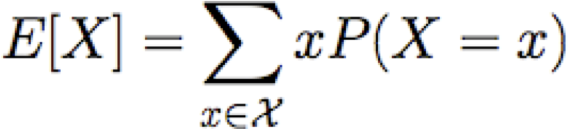Hôm nay:
- Quy tắc Bayes
- Ước tính tham số
- MLE
- MAP
Bài đọc:
Xem lại xác suất
- Bishop Ch. 1 đến 1.2.3
- Bishop, Ch. 2 đến 2.2
- Hướng dẫn trực tuyến của Andrew Moore
một số slide này được lấy từ William Cohen, Andrew Moore, Aarti Singh, Eric Xing, Carlos Guestrin. – Cảm ơn!
Thông báo
- Lớp học đang sử dụng Piazza để đặt câu hỏi/thảo luận về bài tập về nhà, v.v.
- xem trang web của lớp để biết địa chỉ Piazza
- http://www.cs.cmu.edu/~ninamf/courses/601sp15/
- Ôn tập thứ Năm từ 7-8 giờ tối, Wean 5409
- video để ôn tập trong tương lai (trang web của lớp)
- HW1 đã được chấp nhận cho đến 5 giờ chiều Chủ Nhật để lấy toàn bộ tín dụng
- HW2 sẽ ra mắt hôm nay trên trang web của lớp, sau 1 tuần nữa
- HW3 sẽ liên quan đến lập trình (trong Octave )
Quy tắc Bayes
Quy tắc Bayes
P(A|B) = P(B|A) * P(A)⁄P(B)
chúng ta gọi P(A) là “tiên nghiệm”
và P(A|B) là “hậu nghiệm”

Bayes, Thomas (1763) Một bài luận hướng tới việc giải quyết một vấn đề trong học thuyết về cơ hội. Philosophical Transactions of the Royal Society of London, 53:370-418
…không có nghĩa là chỉ là một suy đoán gây tò mò trong học thuyết về cơ hội, mà cần phải được giải đáp để có một nền tảng chắc chắn cho mọi lập luận của chúng ta liên quan đến các sự kiện trong quá khứ, và điều gì là rất có thể là sau này….
cần thiết được xem xét bởi bất kỳ điều gì có thể giải thích rõ ràng về sức mạnh của suy luận loại suy hoặc quy nạp…
Các dạng khác của Quy tắc Bayes
P(A|B) = P(B|A) * P(A)⁄P(B)
P(A|B) = P(B| A)P(A)⁄P(B| A)P(A) + P(B|~ A)P(~ A)
P(A|B∧X) = P(B| A∧ X)P(A∧ X)⁄P(B∧ X)
Áp dụng Quy tắc Bayes
P(A |B) = P(B| A)P(A)⁄P(B| A)P(A) + P(B|~ A)P(~ A)
A = bạn bị cúm, B = bạn vừa ho
Giả sử:
P(A) = 0,05
P(B|A) = 0,80
P(B| ~A) = 0,20
P(cúm | ho) = P(A|B) là gì?
tất cả những điều này có liên quan gì đến phép tính xấp xỉ hàm?
thay vì F: X →Y, hãy học P(Y | X)
Phân phối đồng thời
Công thức để tạo phân phối đồng thời của M biến:
Ví dụ: Các biến Boolean A, B, C

[A. Moore]
Phân phối đồng thời
Công thức để thực hiện phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả các tổ hợp giá trị (M biến Boolean → 2M hàng).
Ví dụ: Các biến Boolean A, B, C

[A. Moore]
Phân phối đồng thời
Công thức để thực hiện phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả các tổ hợp giá trị (M biến Boolean → 2M hàng).
- Đối với mỗi sự kết hợp của các giá trị, hãy cho biết mức độ nó có thể xảy ra.
Ví dụ: Các biến Boolean A, B, C

[A. Moore]
Phân phối đồng thời
Công thức để thực hiện phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả các tổ hợp giá trị (M biến Boolean → 2M hàng).
- Đối với mỗi sự kết hợp của các giá trị, hãy cho biết mức độ nó có thể xảy ra.
- Nếu bạn tin vào các tiên đề xác suất, thì các xác suất đó phải có tổng bằng 1.
Ví dụ: Các biến Boolean A, B, C

[A. Moore]
Sử dụng Phân phối đồng thời
Một khi bạn có JD , bạn có thể yêu cầu xác suất của bất kỳ biểu thức logic nào liên quan đến các biến này
P(E) = ∑rows matching EP(row)
[A. Moore]
Sử dụng đồng thời

P(E) = ∑rows matching EP(row)
P(Nam Nghèo) = 0,4654
[A. Moore]
Sử dụng đồng thời

P(E) = ∑rows matching EP(row)
P(Nghèo) = 0,7604
[A. Moore]
Suy luận với đồng thời

P(E1 | E2 ) = P(E1 ∧ E2 )⁄P(E2 ) = ∑rows matching E1 and E2P(row)⁄∑rows matching E2P(row)
P(Nam | Nghèo) = 0,4654 / 0,7604 = 0,612
[A. Moore]
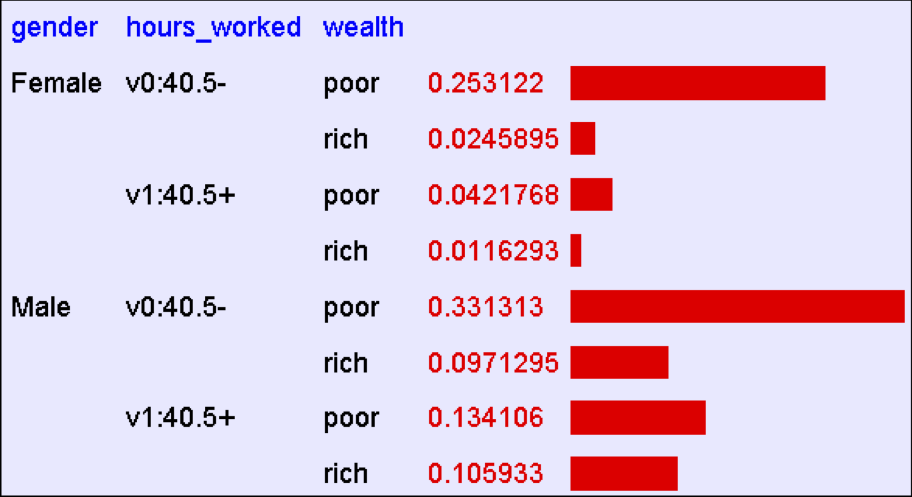
Học và Phân phối đồng thời
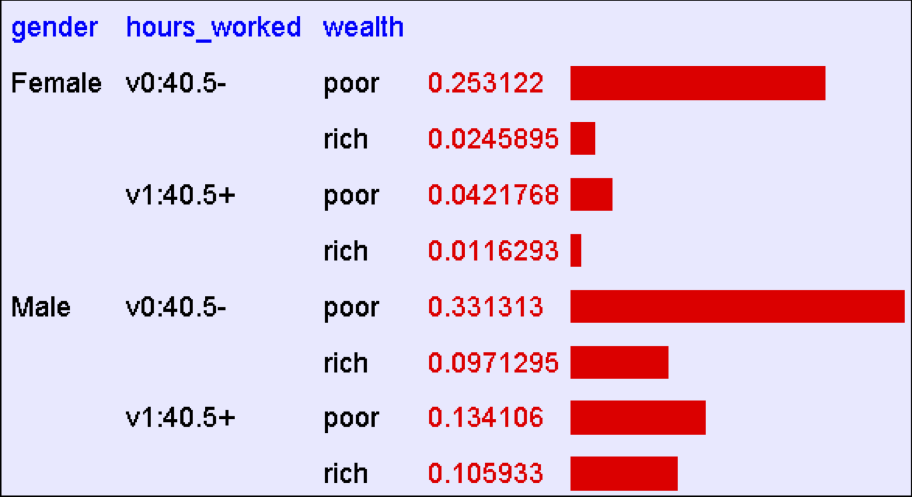
Giả sử chúng ta muốn học hàm f: <G, H> → W
Tương đương, P(W | G, H)
Giải pháp: học phân phối đồng thời từ dữ liệu, tính P(W | G, H)
ví dụ: P(W=giàu | G = nữ, H = 40,5- ) =
[A. Moore]
nghe giống như giải pháp để học F: X →Y, hay P(Y | X).
Chúng ta làm xong chưa?
nghe giống như giải pháp cho việc học F: X →Y, hoặc P(Y | X).
Vấn đề chính: học P(Y|X) có thể yêu cầu nhiều dữ liệu hơn chúng ta có
xem xét việc học Joint Dist. với 100 thuộc tính
số hàng trong bảng này?
số người trên trái đất?
phần của các hàng có 0 ví dụ đào tạo?
phải làm gì?
- Thông minh về cách chúng ta ước tính xác suất từ dữ liệu thưa thớt
- ước tính khả năng tối đa
- ước tính hậu nghiệm tối đa
- Thông minh về cách biểu diễn các phân phối đồng thời
- Mạng Bayes, mô hình đồ họa
1. Hãy thông minh về cách chúng ta ước tính xác suất
Ước tính Xác suất của mặt ngửa

X=1 X=0
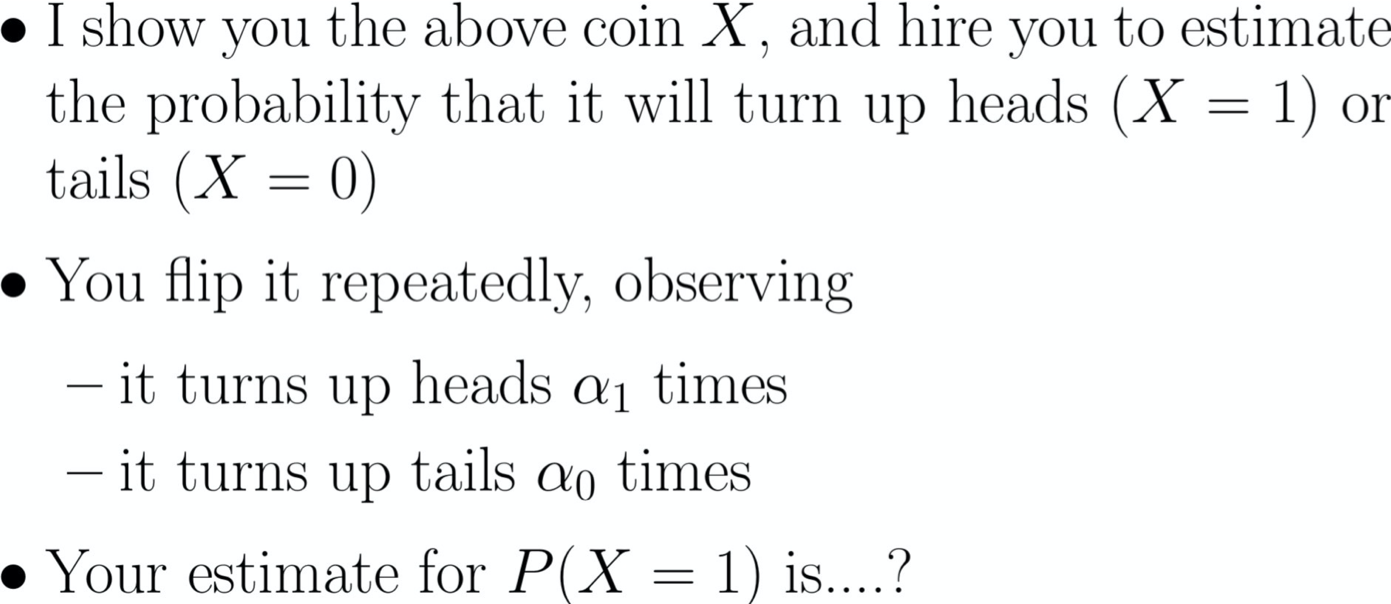
Ước tính θ = P(X=1)

X=1 X=0
Kiểm tra A:
100 lần lật: 51 mặt ngửa (X=1), 49 mặt sấp (X=0)
Bài kiểm tra B:
3 lần lật: 2 ngửa (X=1), 1 sấp (X=0)
Ước tính θ = P(X=1)

X=1 X=0
Trường hợp C: (học trực tuyến)
- tiếp tục lật, muốn thuật toán học đơn đưa ra ước tính hợp lý sau mỗi lần lật
Nguyên tắc ước tính xác suất
Nguyên tắc 1 (khả năng xảy ra cực đại):
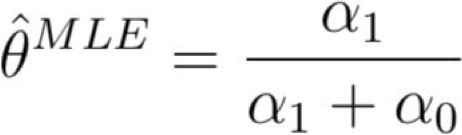
Nguyên tắc 2 (tối đa một xác suất hậu nghiệm):
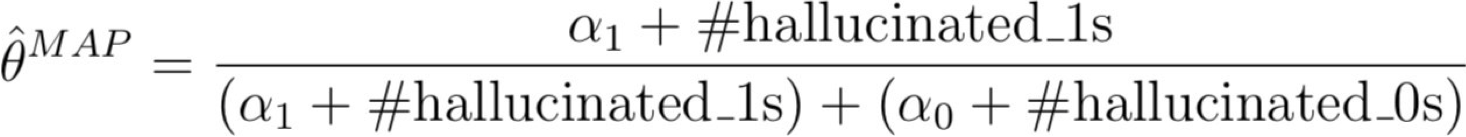
Ước tính khả năng xảy ra tối đa

X=1 X=0
P(X=1) = θ P(X=0) = (1-θ)
Dữ liệu D:
Các lần lật tạo ra dữ liệu D có α1 mặt ngửa, α0 mặt sấp
- các lần lật độc lập, được phân phối giống hệt các số 1 và 0 (Bernoulli)
- α1 và α0 là các số đếm tổng các kết quả này (Nhị thức)
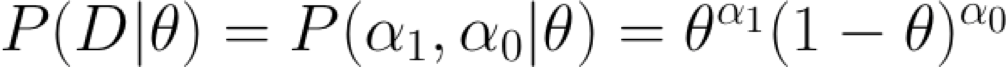
Ước tính Khả năng Tối đa cho Θ
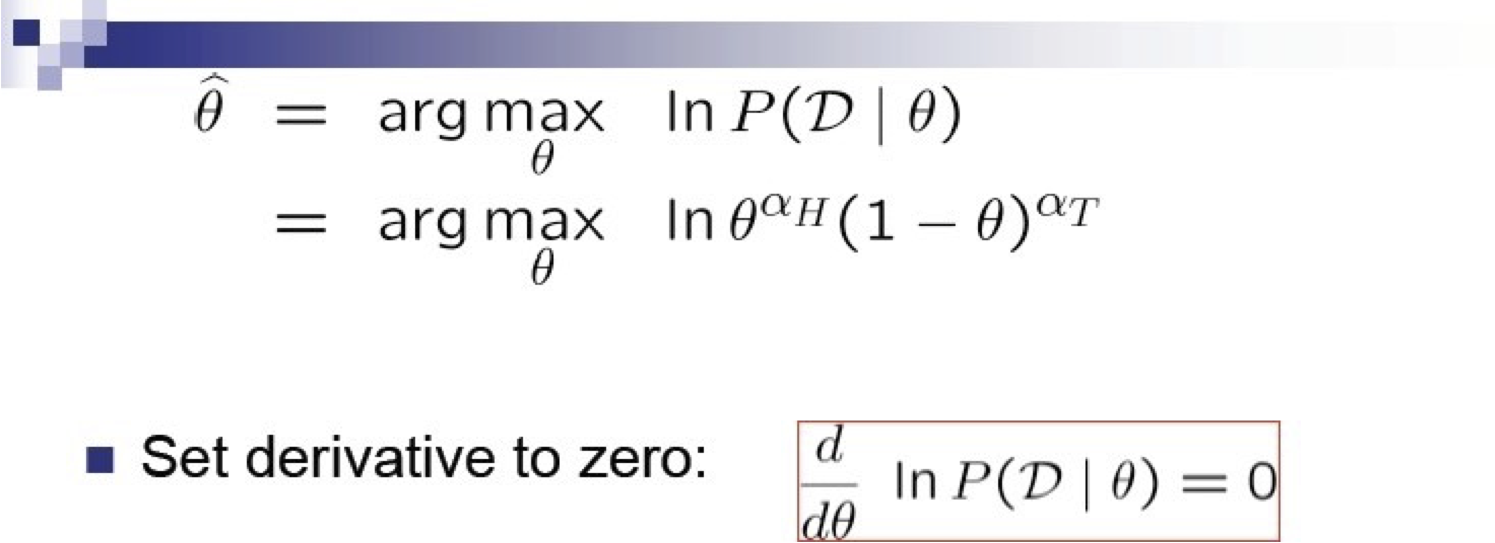
[C. Guestrin]
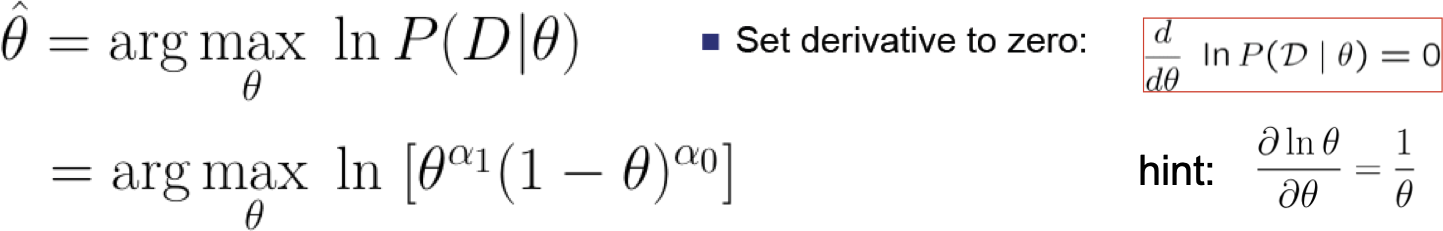
Tóm tắt: Ước tính Khả năng Tối đa

X=1 X=0
P(X=1) = θ
P(X=0) = 1-θ
(Bernoulli)
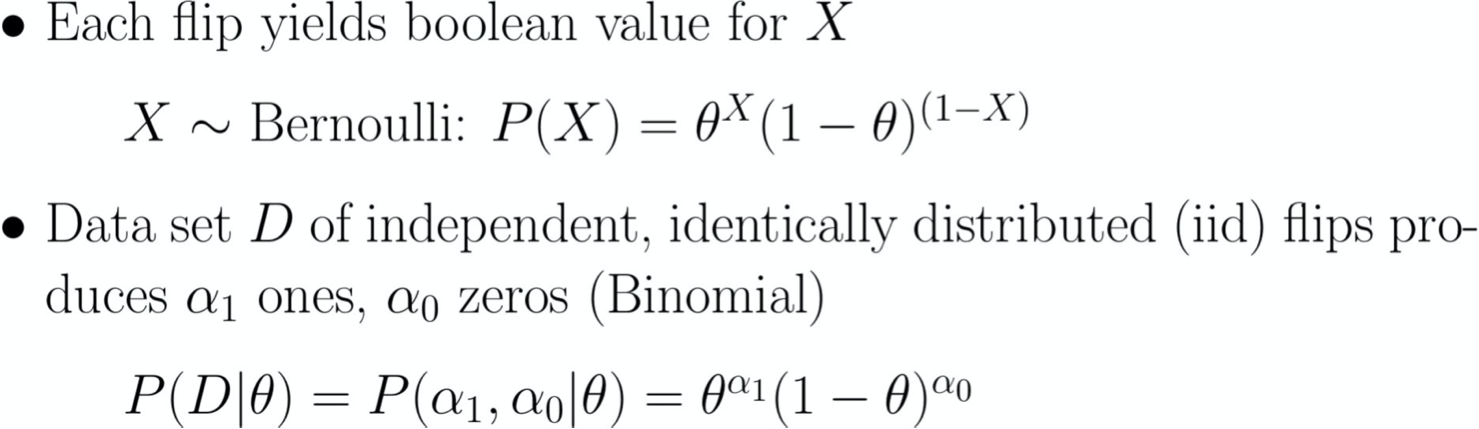
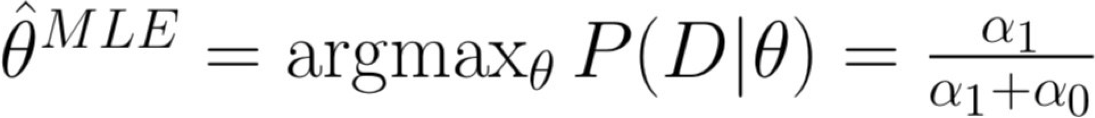
Nguyên tắc ước tính xác suất
Nguyên tắc 1 (khả năng xảy ra tối đa):
- chọn tham số θ tối đa hóa P(dữ liệu | θ)
Nguyên tắc 2 (tối đa một xác suất hậu nghiệm):
- chọn tham số θ tối đa hóa P(θ | dữ liệu) = P(dữ liệu | θ) P(θ)⁄P(dữ liệu)
Phân phối trước beta – P(θ)
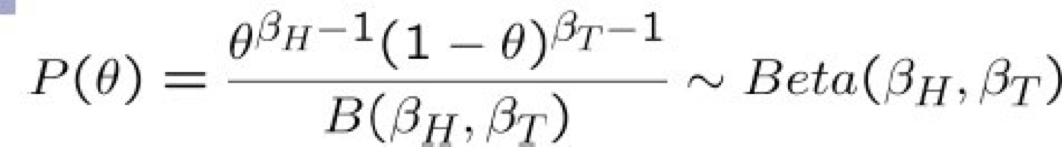
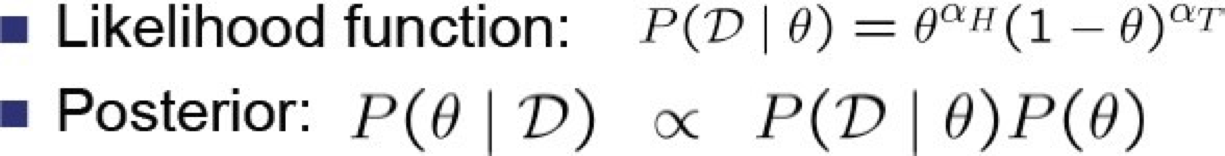
Phân phối trước beta – P(θ)
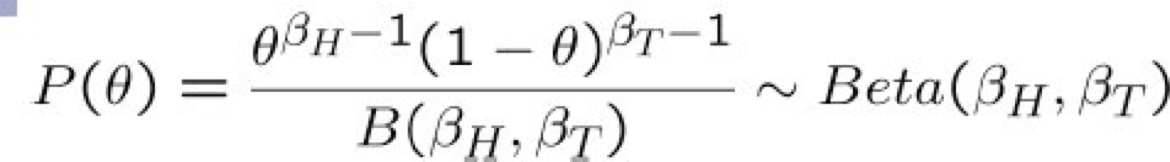
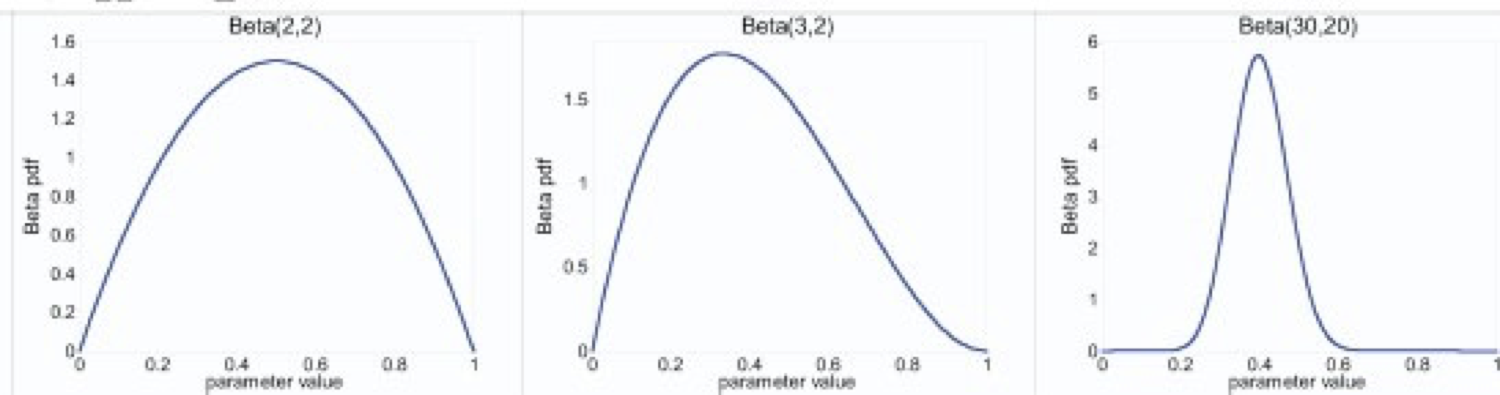
[C. Guestrin]

và ước tính MAP là do đó
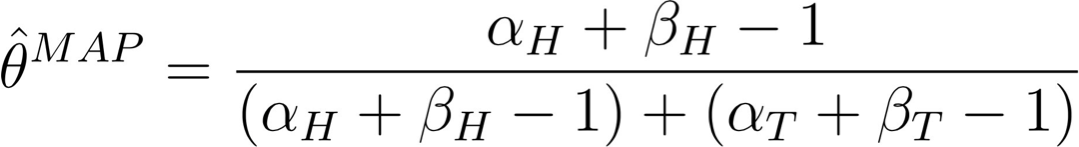

và ước tính MAP là do đó
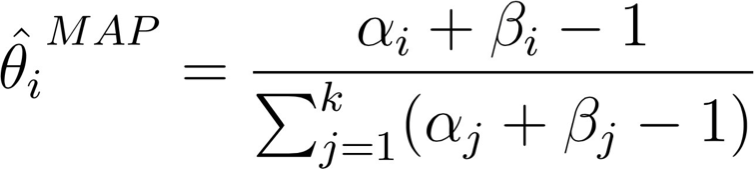
Một số thuật ngữ
- Hàm khả năng: P(dữ liệu | θ)
- Trước: P(θ)
- Sau: P(θ | dữ liệu)
- Liên hợp trước: P(θ) là liên hợp trước cho hàm khả năng P(dữ liệu | θ) nếu các dạng của P(θ) và P(θ | dữ liệu) giống nhau.
Bạn nên biết
- Kiến thức cơ bản về xác suất
- biến ngẫu nhiên, xác suất có điều kiện, …
- Quy tắc Bayes
- Phân phối xác suất đồng thời
- tính toán xác suất từ phân phối đồng thời
- Ước tính tham số từ dữ liệu
- ước lượng khả năng tối đa
- ước lượng hậu nghiệm tối đa
- phân phối – nhị thức, Beta, Dirichlet, …
- tiên nghiệm liên hợp
Các slide phụ
Biến cố độc lập
- Định nghĩa: hai biến cố A và B độc lập nếu P(A ^ B)=P(A)*P(B)
- Trực giác: biết A không cho ta biết gì về giá trị của B (và ngược lại)
Picture “A độc lập với B”
Giá trị kỳ vọng
Cho một biến ngẫu nhiên rời rạc X, giá trị kỳ vọng của X, được viết E[X] là
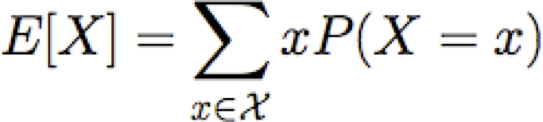
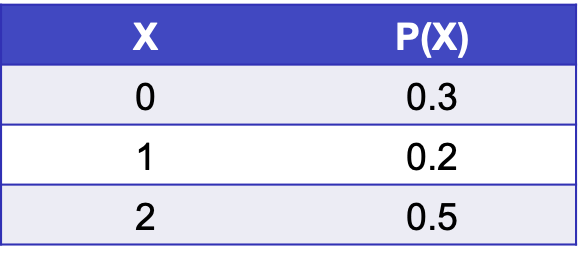
Thí dụ:
Giá trị kỳ vọng
Cho biến ngẫu nhiên rời rạc X, giá trị kỳ vọng của X, được viết E[X] là
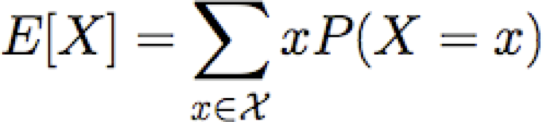
Chúng ta cũng có thể nói về giá trị kỳ vọng của các hàm X
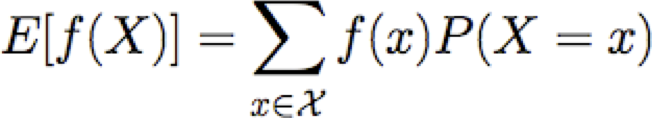
Hiệp phương sai
Cho hai rv rời rạc X và Y, chúng ta định nghĩa hiệp phương sai của X và Y là

ví dụ: X=giới tính, Y=lượt chơiBóng đá
hoặc X=giới tính, Y=thuận tay trái
Nhớ lại: