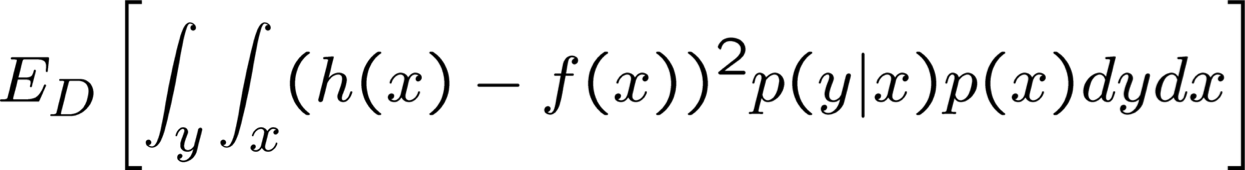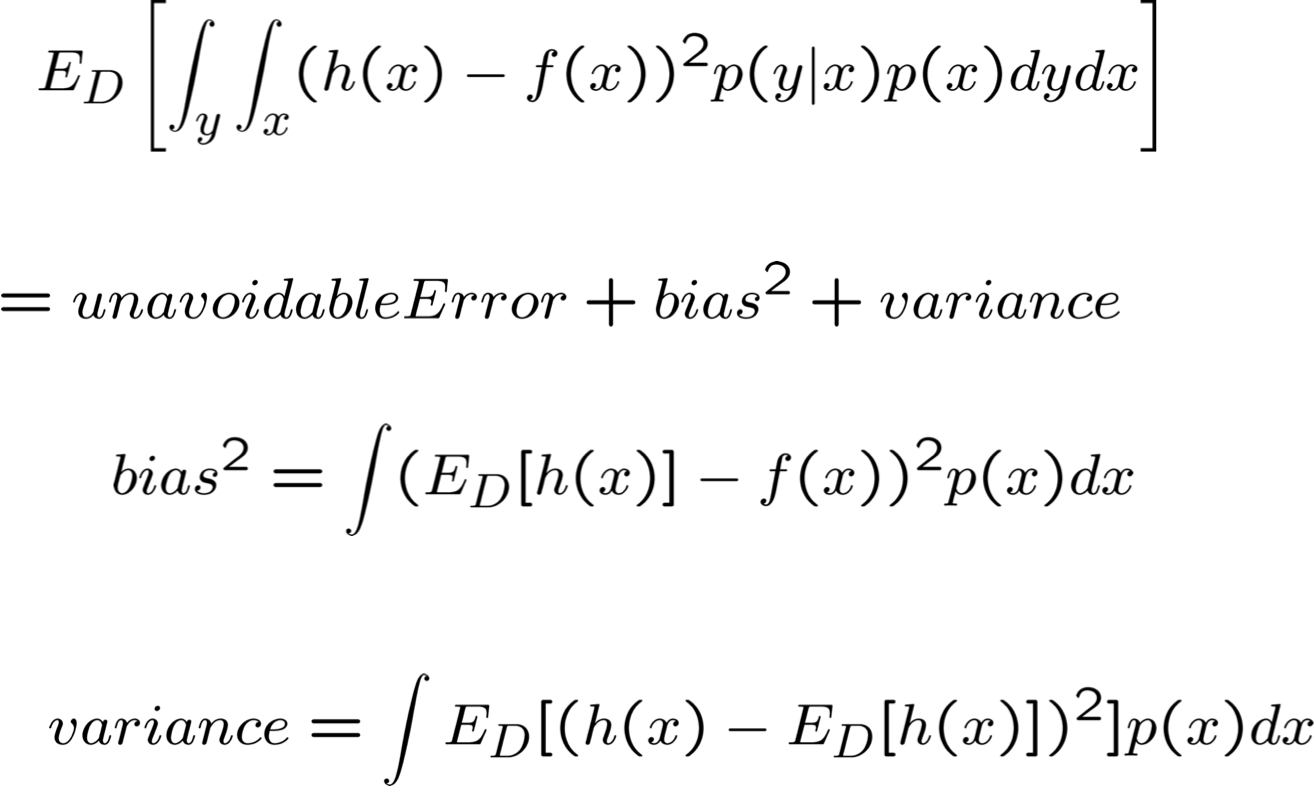Hôm nay:
- Phân loại tạo sinh – phân biệt
- Hồi quy tuyến tính
- Phân tách lỗi thành thiên vị, phương sai, không thể tránh khỏi
Bài đọc:
- Mitchell: “Naïve Bayes and Logistic Regression” (bắt buộc)
- Bài viết của Ng và Jordan (tùy chọn)
- Bishop, Ch 9.1, 9.2 (tùy chọn)
Hồi quy logistic
- Xem xét việc học f: X → Y, trong đó
- X là một vectơ của các đặc trưng có giá trị thực, < X1 … Xn >
- Y là boolean
- giả sử tất cả Xi đều độc lập có điều kiện với Y
- mô hình P(Xi | Y = yk) có dạng Gaussian N(µik,σi)
- mô hình P(Y) có dạng Bernoulli (π)
- Khi đó, P(Y|X) có dạng này và chúng ta có thể ước tính trực tiếp W
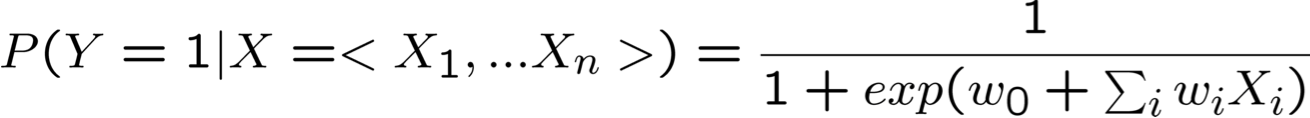
- Hơn nữa, điều tương tự cũng đúng nếu Xi là boolean
- cố gắng chứng minh điều đó với chính bạn
- Huấn luyện bằng ước tính tăng dần độ dốc của w’s (không có giả định!)
MLE so với MAP
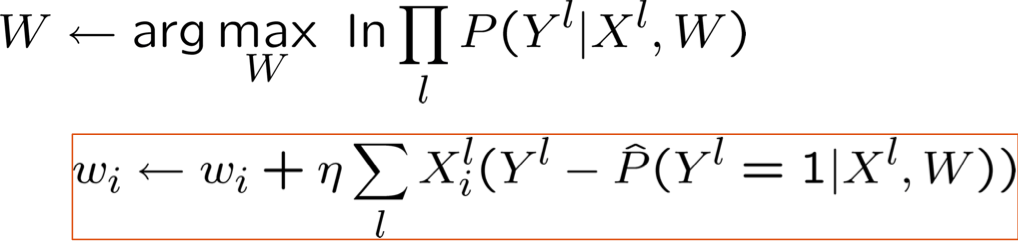
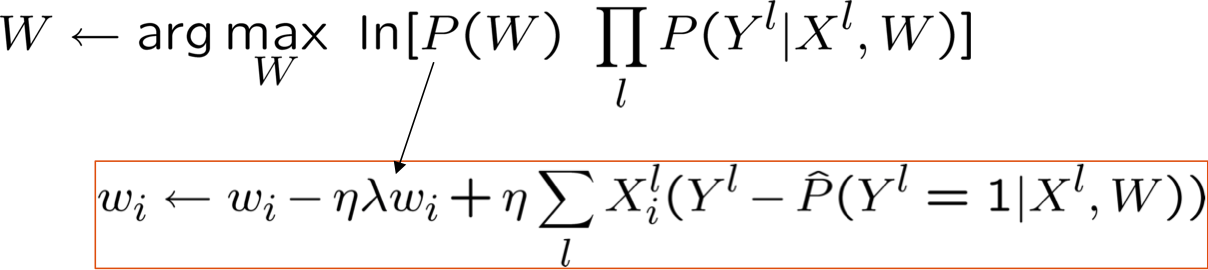
Ước tính MAP và Chính quy hóa
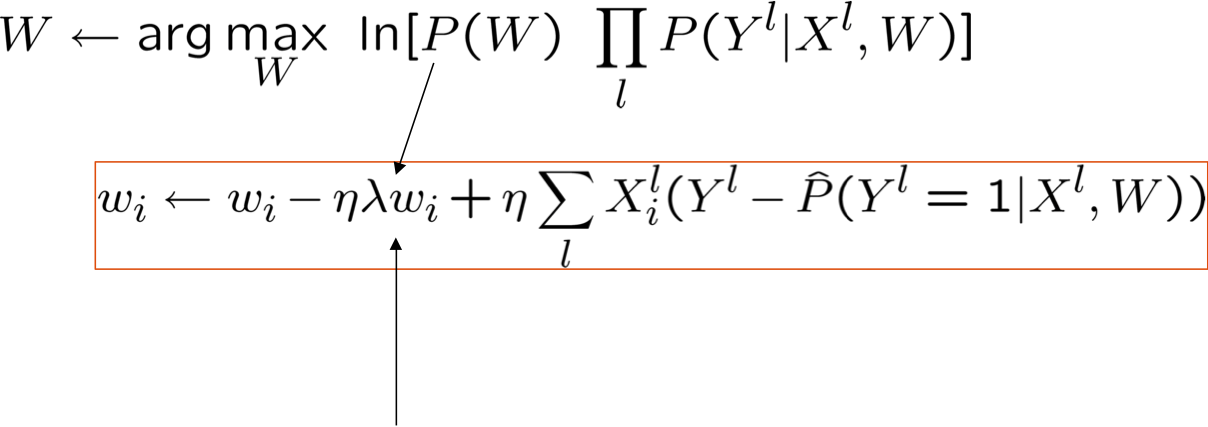
được gọi là thuật ngữ “chính quy hóa”
- giúp giảm khớp quá mức, đặc biệt là khi dữ liệu đào tạo thưa thớt
- giữ trọng số gần bằng 0 (nếu P(W) bằng 0 có nghĩa là Gaussian trước đó), hoặc bất cứ điều gì gợi ý trước
- được sử dụng rất thường xuyên trong hồi quy logistic
Phân loại tạo sinh so với phân loại phân biệt
Bộ phân loại đào tạo liên quan đến việc ước tính f: X → Y, hoặc P(Y|X)
Generative classifiers (ví dụ: Naïve Bayes)
- Giả sử một dạng hàm nào đó cho P(Y), P(X|Y)
- Ước tính các tham số của P(X|Y), P(Y) trực tiếp từ dữ liệu huấn luyện
- Sử dụng quy tắc Bayes để tính toán P(Y=y |X= x)
Phân loại phân biệt (ví dụ: Hồi quy logistic)
- Giả sử một dạng hàm nào đó cho P(Y|X)
- Ước tính các tham số của P(Y|X) trực tiếp từ dữ liệu huấn luyện
- LƯU Ý: mặc dù nguồn gốc của dạng P(Y|X) đã tạo ra các giả định kiểu GNB, quy trình đào tạo cho Hồi quy logistic thì không!
Sử dụng Naïve Bayes hay Logisitic Regression?
Xem xét
- Tính hạn chế của các giả định mô hình hóa (chúng ta có thể học tốt như thế nào với dữ liệu vô hạn?)
- Tốc độ hội tụ (về số lượng dữ liệu đào tạo) đối với giả thuyết tiệm cận (dữ liệu vô hạn)
- tức là, đường cong học tập
Naïve Bayes vs Hồi quy logistic
Xem xét Y boolean, Xi liên tục, X=<X1 … Xn>
Số tham số:
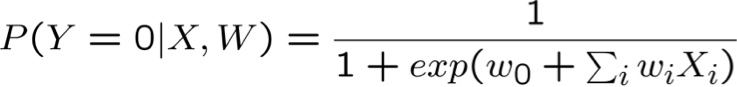
Phương pháp ước tính:
- Ước tính tham số NB không liên kết
- Ước tính tham số LR được liên kết
Gaussian Naïve Bayes – Big Picture
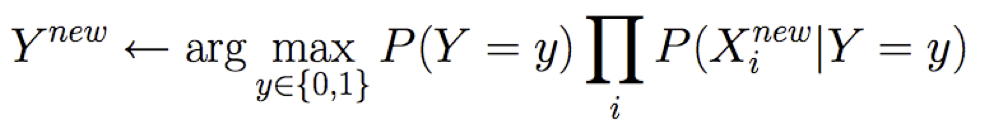
giả định P(Y=1) = 0,5
Gaussian Naïve Bayes – Big Picture
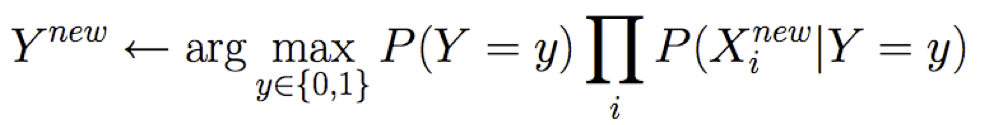
giả định P(Y=1) = 0,5
G.Naïve Bayes so với Hồi quy logistic
[Ng & Jordan, 2002]
Nhớ lại hai giả định dẫn xuất dạng LR từ GNBayes:
- Xi độc lập có điều kiện với Xk cho trước Y
- P(Xi | Y = yk) = N(µik,σi), ← not N(µik,σik)
Xem xét ba phương pháp học:
- GNB (chỉ giả định 1)
- GNB2 (giả định 1 và 2)
- LR
Phương pháp nào hoạt động tốt hơn nếu chúng ta có dữ liệu đào tạo vô hạn và…
- Cả (1) và (2) đều thỏa mãn
- Cả (1) và (2) đều không thỏa mãn
- (1) thỏa mãn nhưng không (2)
G.Naïve Bayes vs. Logistic Regression
[Ng & Jordan, 2002]
Nhớ lại hai giả định dẫn xuất dạng LR từ GNBayes:
- Xi độc lập có điều kiện với Xk cho trước Y
- P(Xi | Y = yk) = N(µik,σi), ← not N(µik,σik)
Xem xét ba phương pháp học:
- GNB (chỉ giả định 1) — bề mặt quyết định có thể phi tuyến tính
- GNB2 (giả định 1 và 2) – bề mặt quyết định tuyến tính
- LR — bề mặt quyết định tuyến tính, được huấn luyện khác
Phương pháp nào hoạt động tốt hơn nếu chúng ta có dữ liệu đào tạo vô hạn và…
- Cả (1) và (2) đều thỏa mãn: LR = GNB2 = GNB
- Cả (1) và (2) đều không thỏa mãn: LR > GNB2, GNB>GNB2
- (1) thỏa mãn nhưng không (2): GNB > LR, LR > GNB2
G.Naïve Bayes vs. Logistic Regression
[Ng & Jordan, 2002]
Điều gì sẽ xảy ra nếu chúng ta chỉ có dữ liệu huấn luyện hữu hạn?
Chúng hội tụ ở các tốc độ khác nhau đối với lỗi tiệm cận (∞ dữ liệu) của chúng
Gọi εA,n tham khảo lỗi dự kiến của thuật toán học A sau n mẫu đào tạo
Gọi d là số đặc trưng: <X1 … Xd>
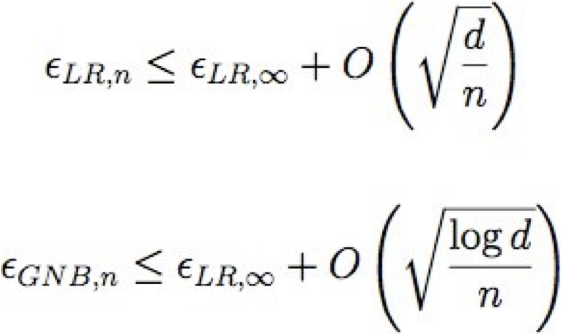
Vì vậy, GNB yêu cầu n = O(log d) để hội tụ, nhưng LR yêu cầu n = O(d)
Một số thử nghiệm từ bộ dữ liệu UCI
[Ng & Jordan, 2002]
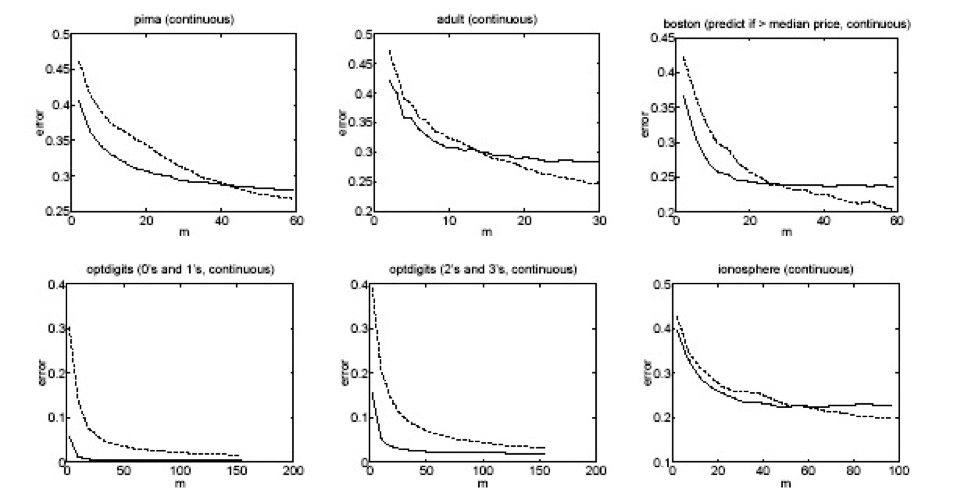
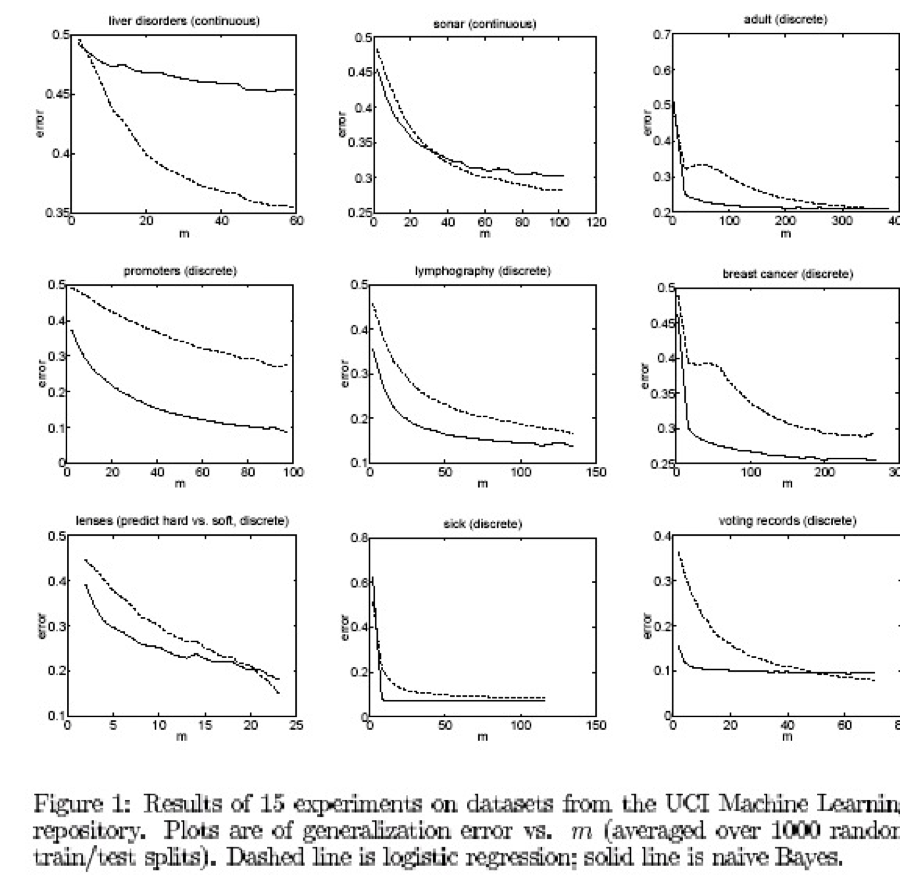
Naïve Bayes so với hồi quy logistic
điểm mấu chốt:
GNB2 và LR đều sử dụng các bề mặt quyết định tuyến tính, GNB không cần
Với dữ liệu vô hạn, LR tốt hơn GNB2 vì quy trình đào tạo không đưa ra giả định 1 hoặc 2 (mặc dù việc tạo ra dạng P(Y|X) của chúng ta đã làm).
Nhưng GNB2 hội tụ nhanh hơn với lỗi tiệm cận có lẽ kém chính xác hơn
Và GNB vừa sai lệch hơn (giả định 1) vừa ít hơn (không có giả định 2) so với LR, do đó cái này có thể đánh bại cái kia
Tốc độ hội tụ: hồi quy logistic
[Ng & Jordan, 2002]
Giả sử hDis,m là hồi quy logistic được đào tạo trên m mẫu trong n chiều. Thì, với xác suất cao:
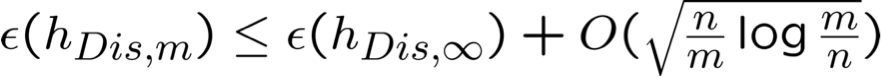
Hàm ý: nếu chúng ta muốn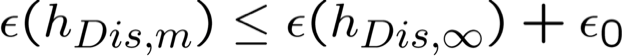 một hằng số ε0 nào đó, chỉ cần chọn thứ tự n mẫu là đủ
một hằng số ε0 nào đó, chỉ cần chọn thứ tự n mẫu là đủ
→ Hội tụ với bộ phân loại tiệm cận của nó, theo thứ tự n mẫu (kết quả theo sau giới hạn rủi ro cấu trúc của Vapnik, cộng với thực tế là VCDim của n chiều phân tách tuyến tính là n )
Tốc độ hội tụ: naïve Bayes parameters
[Ng & Jordan, 2002]

Những điều bạn nên biết:
- Hồi quy logistic
- Dạng hàm tuân theo các giả định của Naïve Bayes
- Đối với Gaussian Naïve Bayes giả định phương sai σi,k = σi
- Đối với Naïve Bayes có giá trị rời rạc cũng vậy
- Nhưng quy trình đào tạo chọn tham số mà không có sự độc lập có điều kiện giả định
- Huấn luyện MCLE: chọn W để tối đa hóa P(Y | X, W)
- Huấn luyện MAP: chọn W để tối đa hóa P(W | X,Y)
- chính quy hóa: ví dụ: P(W) ~ N(0,σ)
- giúp giảm tình trạng quá khớp
- Dạng hàm tuân theo các giả định của Naïve Bayes
- Tăng/giảm độ dốc
- Cách tiếp cận chung khi không có giải pháp dạng đóng cho MLE, MAP
- Phân loại tạo sinh so với phân biệt
- Sự đánh đổi giữa thiên vị và phương sai
Hôm nay:
- Hồi quy tuyến tính
- Phân tách sai số thành thiên vị, phương sai, không thể tránh khỏi
Bài đọc:
- Mitchell: “Naïve Bayes and Logistic Regression” (xem trang web của lớp)
- Bài viết của Ng và Jordan (trang web của lớp)
- Bishop, Ch 9.1, 9.2
Hồi quy
Cho đến nay, chúng ta quan tâm đến việc học P(Y|X) trong đó Y có các giá trị rời rạc (được gọi là ‘phân loại’)
Nếu Y liên tục thì sao? (được gọi là ‘hồi quy’)
- dự đoán trọng lượng từ giới tính, chiều cao, tuổi, …
- dự đoán giá cổ phiếu Google hôm nay từ giá Google, Yahoo, MSFT ngày hôm qua
- dự đoán cường độ từng pixel trong hình ảnh camera hiện tại của rô-bốt, từ hình ảnh trước đó và hành động trước đó
Regression
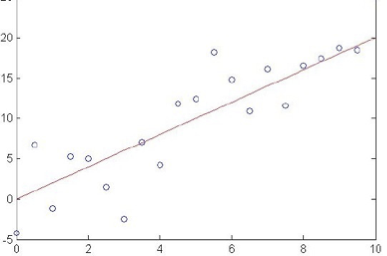
Mong để học f:X→Y, trong đó Y thực, cho trước {<x1,y1>…<xn,yn>}
Cách tiếp cận:
- chọn một số dạng tham số hóa cho P(Y|X; θ) ( θ là vectơ tham số)
- rút ra thuật toán học dưới dạng ước tính MCLE hoặc MAP cho θ
1. Chọn dạng tham số hóa cho P(Y|X; θ)
Giả sử Y là f(X) xác định nào đó, cộng với nhiễu ngẫu nhiên
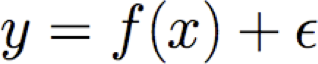 trong đó
trong đó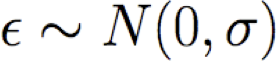
Do đó Y là biến ngẫu nhiên tuân theo phân phối
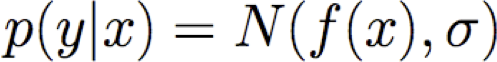
và giá trị kỳ vọng của y đối với bất kỳ x đã cho nào là f(x)
1. Chọn dạng tham số hóa cho P(Y|X; θ)
Giả sử Y là f(X) xác định nào đó, cộng với nhiễu ngẫu nhiên
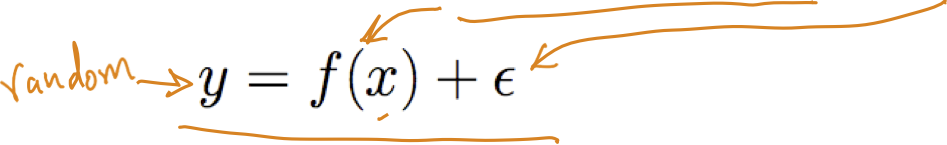 trong đó
trong đó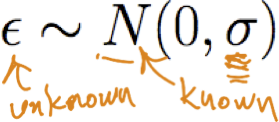
Do đó Y là biến ngẫu nhiên tuân theo phân phối
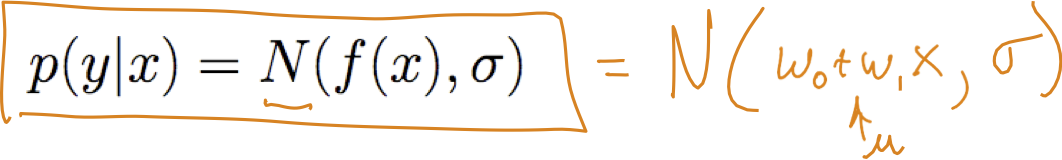
và giá trị kỳ vọng của y đối với bất kỳ x đã cho nào là f(x)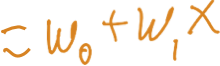
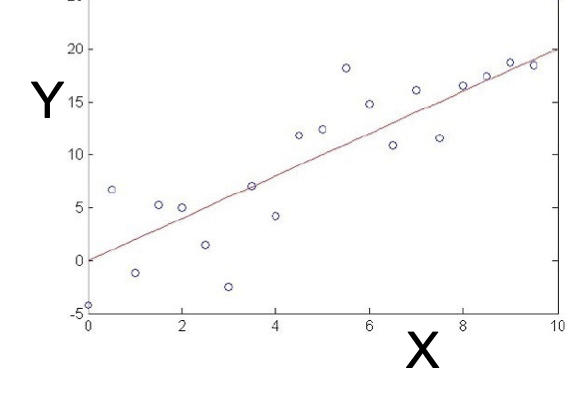
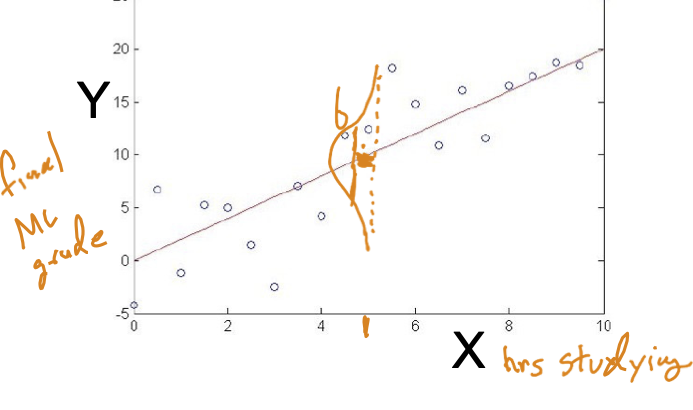
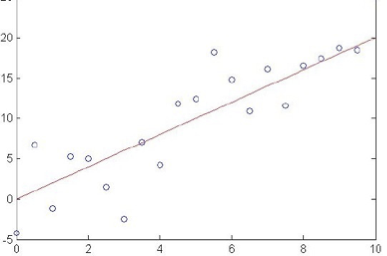
xem xét hồi quy tuyến tính
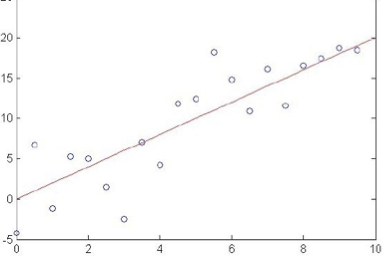
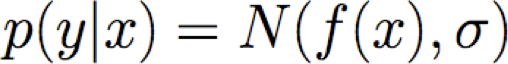
Ví dụ: giả sử f(x) là hàm tuyến tính của x
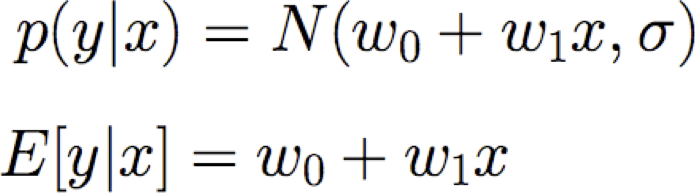
Ký hiệu: để làm cho các tham số của chúng ta rõ ràng, hãy viết
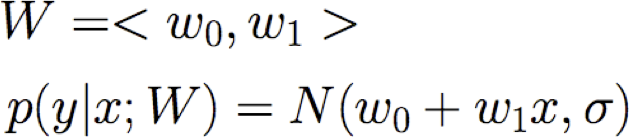
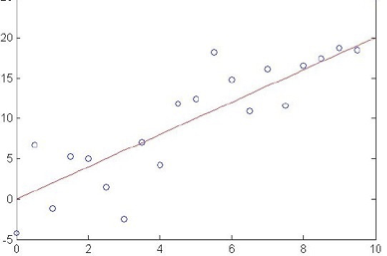
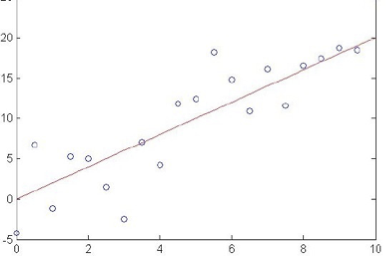
Đào tạo hồi quy tuyến tính
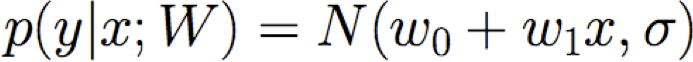
Làm thế nào chúng ta có thể học W từ dữ liệu đào tạo?
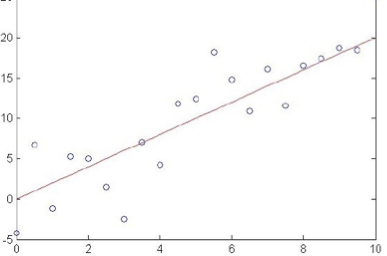
Đào tạo hồi quy tuyến tính
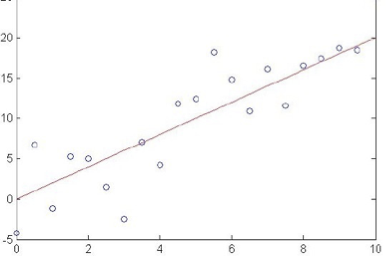
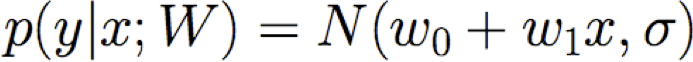
Làm thế nào chúng ta có thể học W từ dữ liệu đào tạo?
Học ước tính hợp lý có điều kiện tối đa!
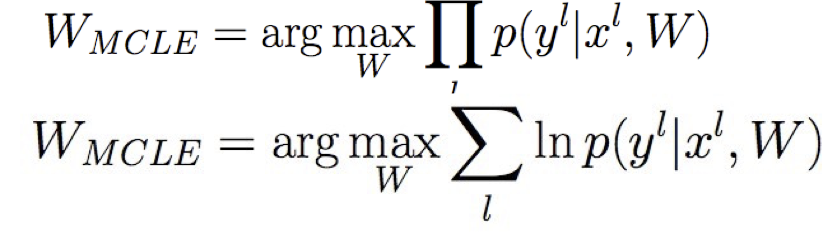
trong đó
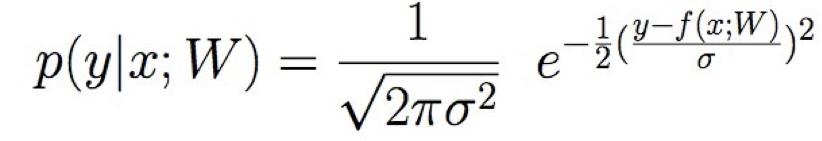
Đào tạo hồi quy tuyến tính
Học ước tính hợp lý có điều kiện tối đa
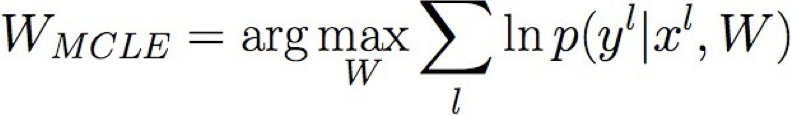
trong đó
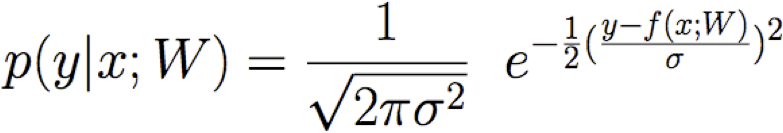
Đào tạo hồi quy tuyến tính
Học ước tính hợp lý có điều kiện tối đa
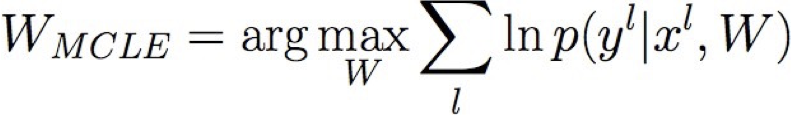
trong đó
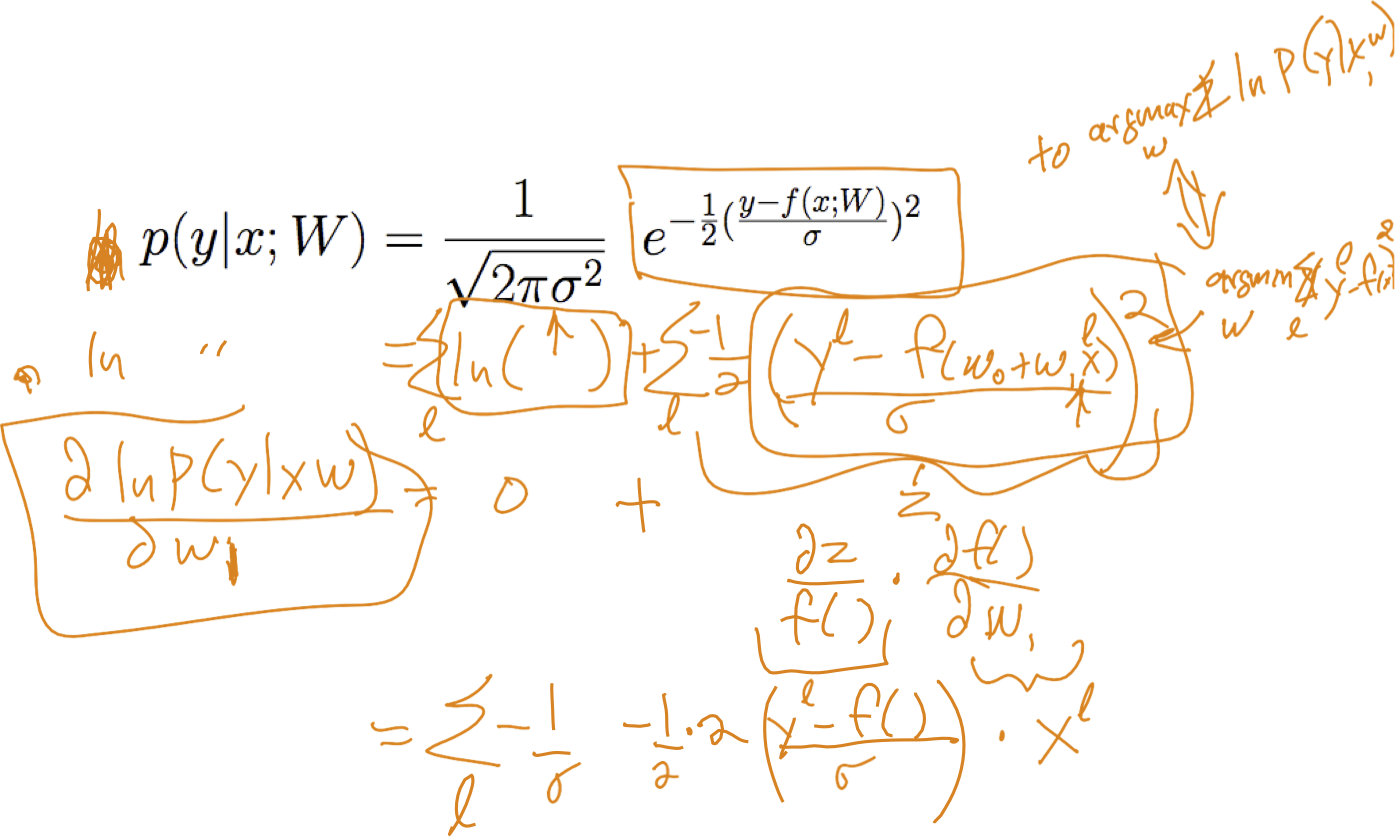
Đào tạo hồi quy tuyến tính
Học ước tính hợp lý có điều kiện tối đa
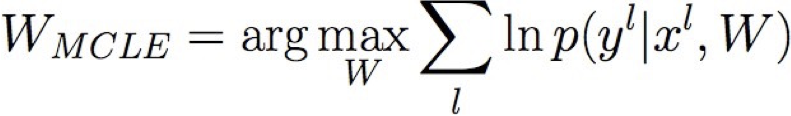
trong đó
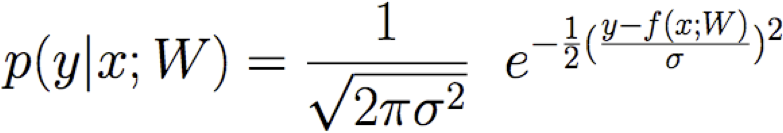
vì thế:
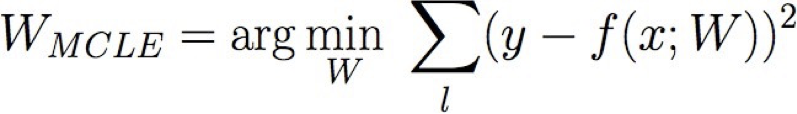
Đào tạo hồi quy tuyến tính
Học ước tính hợp lý có điều kiện tối đa
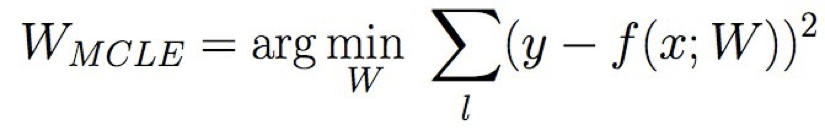
Chúng ta có thể rút ra quy tắc giảm độ dốc cho đào tạo không?
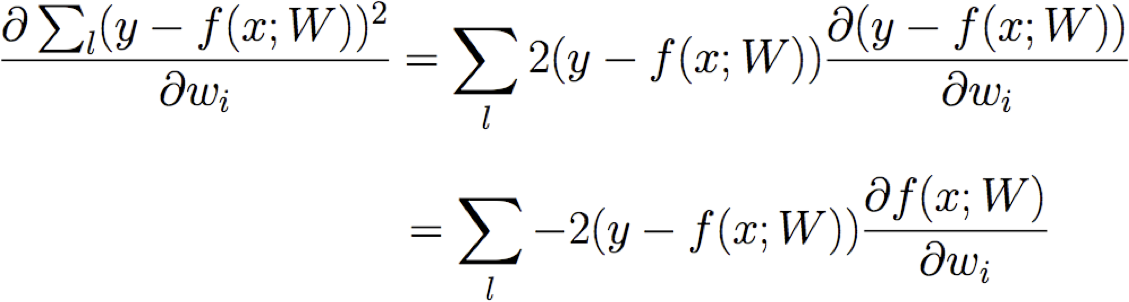
Làm thế nào về MAP thay vì ước tính MLE?
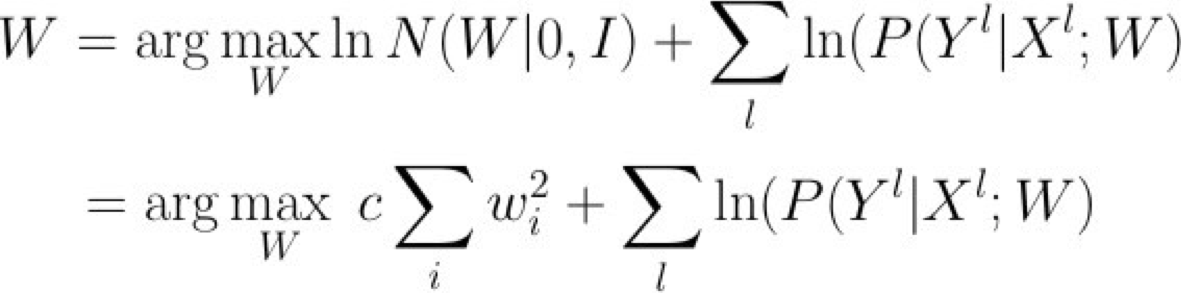
Hồi quy – Những điều bạn nên biết
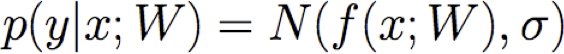
- MLE tương ứng với việc giảm thiểu tổng sai số dự đoán bình phương
- Ước tính MAP giảm thiểu SSE cộng với tổng trọng số bình phương
- Một lần nữa, việc học là một vấn đề tối ưu hóa khi chúng ta chọn hàm mục tiêu
- tối đa hóa hợp lý dữ liệu
- tối đa hóa xác suất hậu nghiệm của W
- Một lần nữa, chúng ta có thể sử dụng độ dốc giảm dần như một thuật toán học chung
- miễn là hàm mục tiêu fn của chúng ta khả vi đối với W
- mặc dù chúng ta có thể học các tối ưu cục bộ
- Hầu như chúng ta không nói gì ở đây yêu cầu f(x) tuyến tính theo x
Phân tích thiên vị/phương sai của sai số
Thiên vị và phương sai
được cung cấp một số công cụ ước tính Y cho một số tham số θ, chúng ta định nghĩa
thiên vị của công cụ ước tính Y = 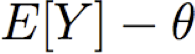
phương sai của công cụ ước tính Y =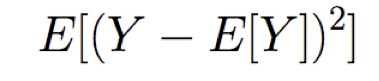
ví dụ: xác định Y là công cụ ước tính MLE cho xác suất mặt ngửa, dựa trên n lần tung đồng xu độc lập
thiên vị hay không thiên vị?
phương sai giảm khi sqrt(1/n)
Bias – Phân rã phương sai của lỗi
Đọc: Bishop chương 9.1, 9.2
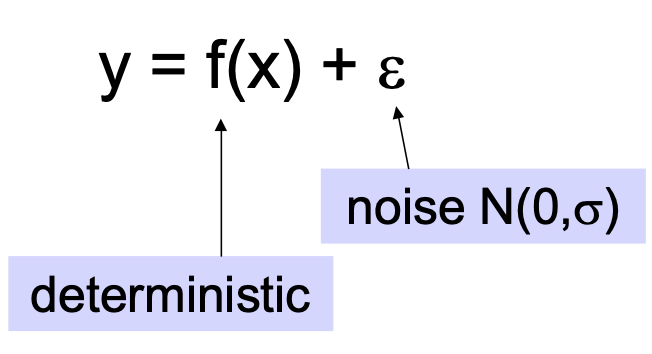
Nguồn gốc của sai số dự đoán là gì?
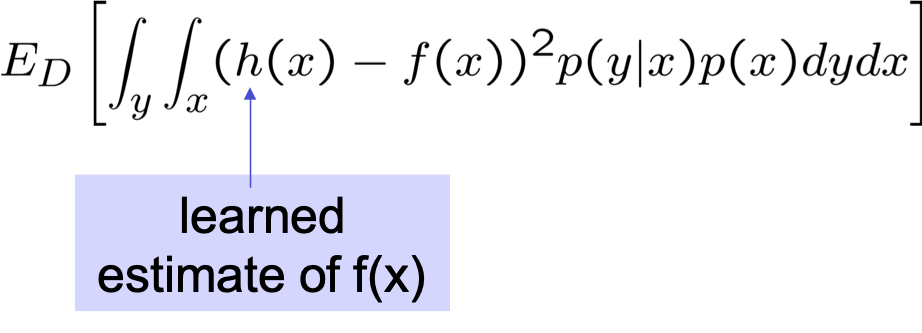
Nguồn lỗi
- Điều gì sẽ xảy ra nếu chúng ta có bộ học hoàn hảo, dữ liệu vô hạn?
- Tìm được h(x) thỏa mãn h(x)=f(x)
- Vẫn còn sai sót, khó tránh khỏi
σ2
Nguồn lỗi
- Nếu chúng ta chỉ có n mẫu huấn luyện thì sao?
- Lỗi dự kiến của chúng ta là gì
- Đã thực hiện các tập huấn luyện ngẫu nhiên có kích thước n, được rút ra từ phân phối D=p(x,y)