
Hôm nay:
- Hồi quy logistic
- Phân loại Generative/Discriminative
Bài đọc: (xem trang web của lớp)
Bắt buộc:
- Mitchell: “Naïve Bayes và hồi quy logistic”
Tùy chọn
- Ng & Jordan
Thông báo
- HW3 đến hạn vào thứ Tư ngày 4 tháng 2
- HW4 sẽ được phát vào thứ Hai tuần sau, ngày 9 tháng 2
- có bài đọc mới:
- Estimating Probabilities: MLE và MAP (Mitchell)
- xem tab Bài giảng trên trang web của lớp
- bài đọc bắt buộc cho ngày hôm nay:
- Naïve Bayes và Logistic Regression (Mitchell)
Gaussian Naïve Bayes – bức tranh lớn
Ví dụ: Y= PlayBasketball (boolean), X1=Height, X2=MLgrade
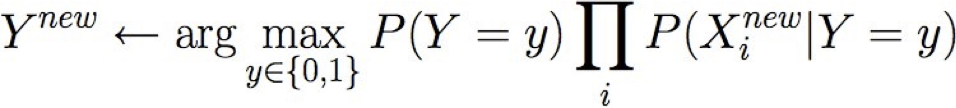
giả sử P(Y=1) = 0,5
Hồi quy logistic
Ý tưởng
- Naïve Bayes cho phép tính toán P(Y|X) bởi học P(Y) và P(X|Y)
- Tại sao không học trực tiếp P(Y|X)?
- Xem xét việc học f: X → Y, trong đó
- X là một vectơ của các đặc trưng có giá trị thực, < X1 … Xn >
- Y là boolean
- giả sử tất cả Xi đều độc lập có điều kiện với Y
- mô hình P(Xi | Y = yk) có dạng Gaussian N(µik,σi)
- mô hình P(Y) có dạng Bernoulli (π)
- Điều đó ngụ ý gì về dạng của P(Y|X)?
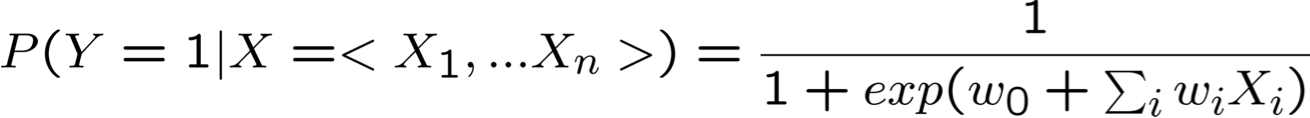
Rút ra dạng P(Y|X) cho Gaussian P(Xi|Y=yk) giả sử σik = σi
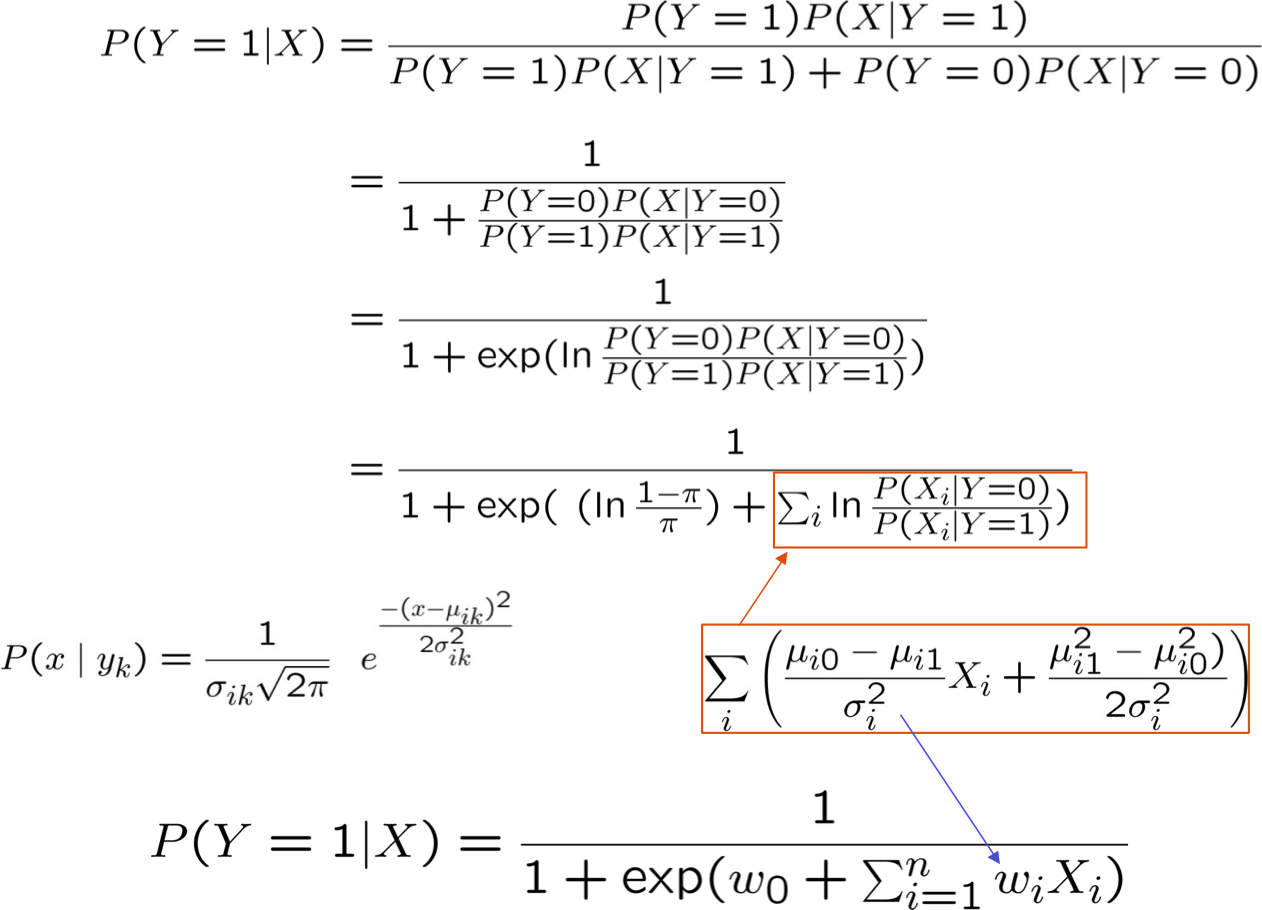
Rất thuận tiện!
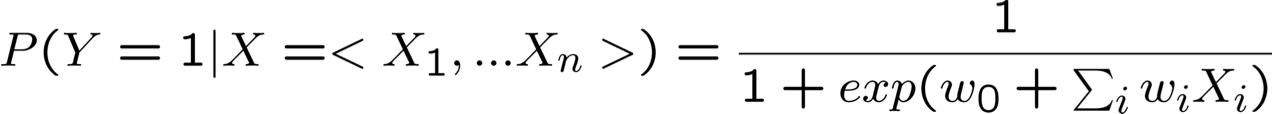
ngụ ý
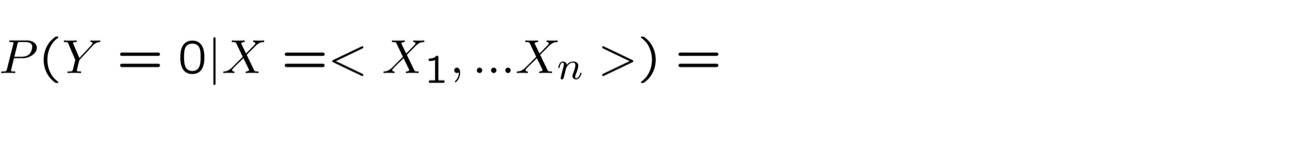
ngụ ý
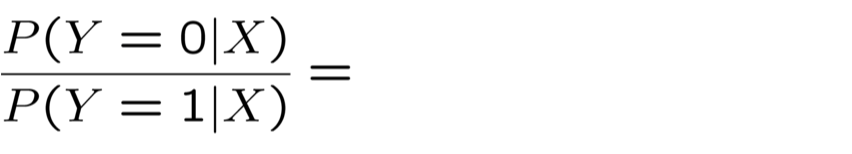
ngụ ý
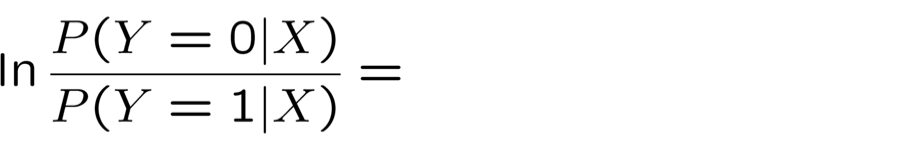
Rất tiện lợi!
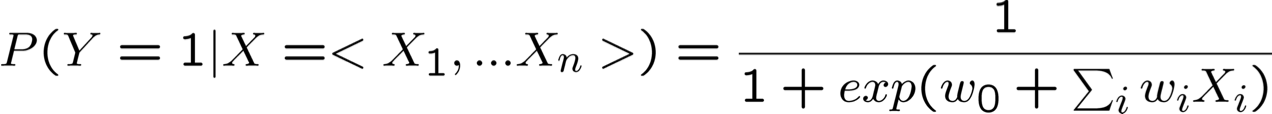
ngụ ý
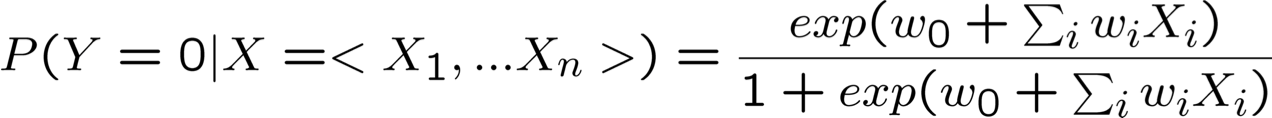
ngụ ý
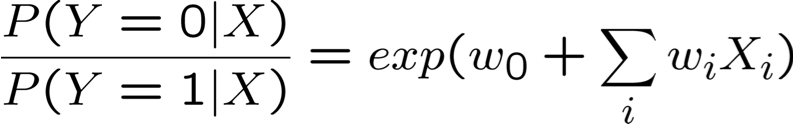
ngụ ý
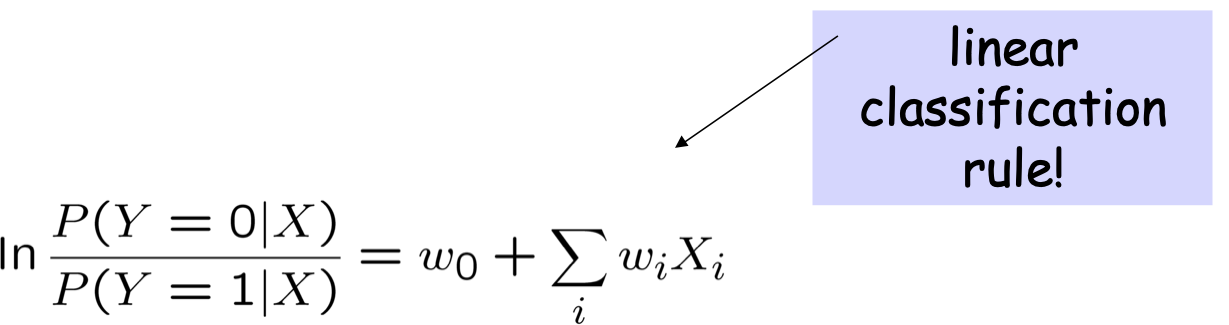
Hàm logistic
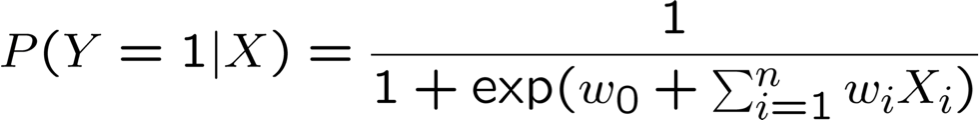
Hồi quy logistic tổng quát hơn
- Hồi quy logistic khi Y không phải là boolean (nhưng vẫn có giá trị rời rạc).
- Bây giờ y ∈ {y1 … yR} : học R–1 bộ trọng số
cho k<R
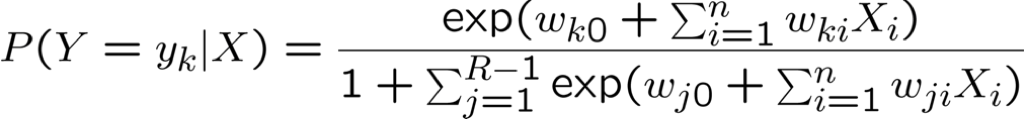
cho k=R
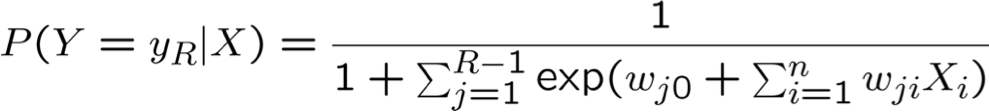
Đào tạo Hồi quy logistic: MCLE
- chúng ta có các mẫu đào tạo L:

- ước tính hợp lý tối đa cho các tham số W
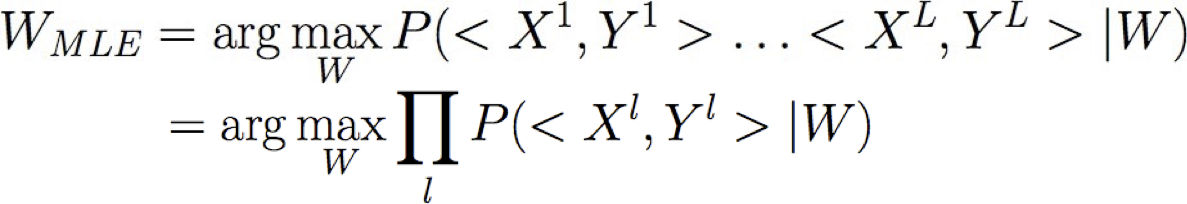
- ước tính hợp lý có điều kiện tối đa
Đào tạo Hồi quy logistic: MCLE
- Chọn tham số W=<w0, … wn> để tối đa hóa hợp lý có điều kiện của dữ liệu huấn luyện trong đó
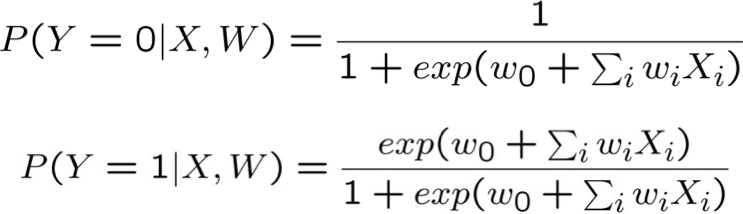
- Dữ liệu huấn luyện D =

- Hợp lý dữ liệu =

- Hợp lý có điều kiện của dữ liệu =
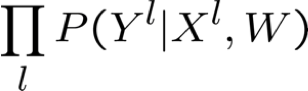
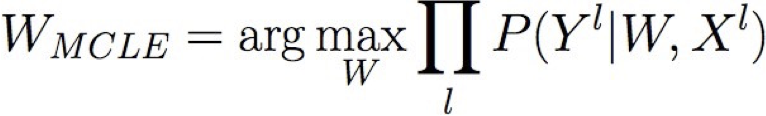
Biểu diễn hợp lý Log có điều kiện
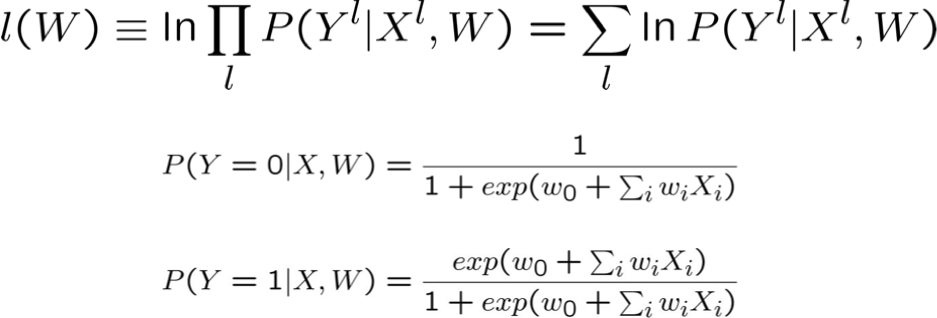
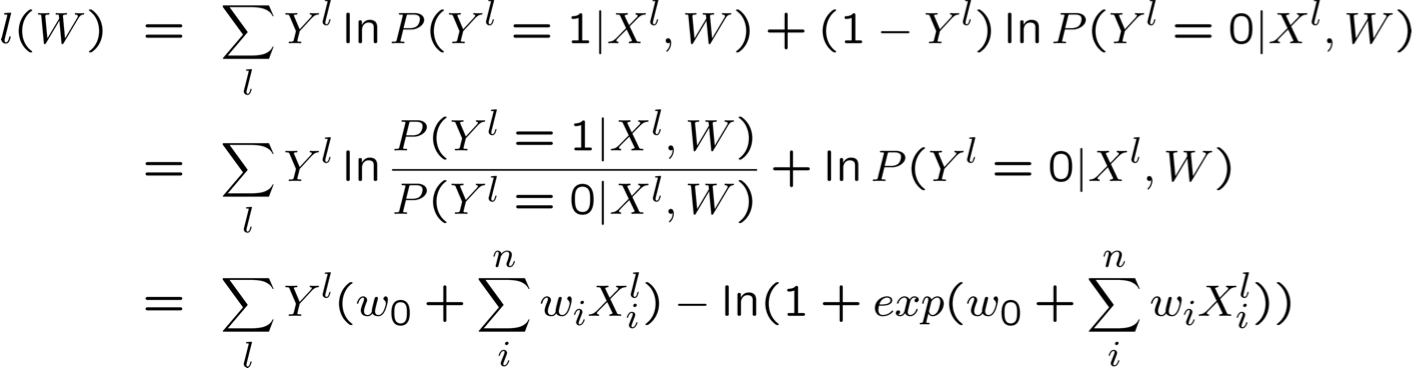
Tối đa hóa hợp lý Log có điều kiện
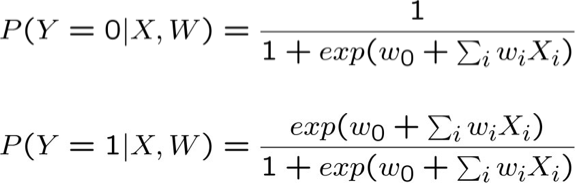
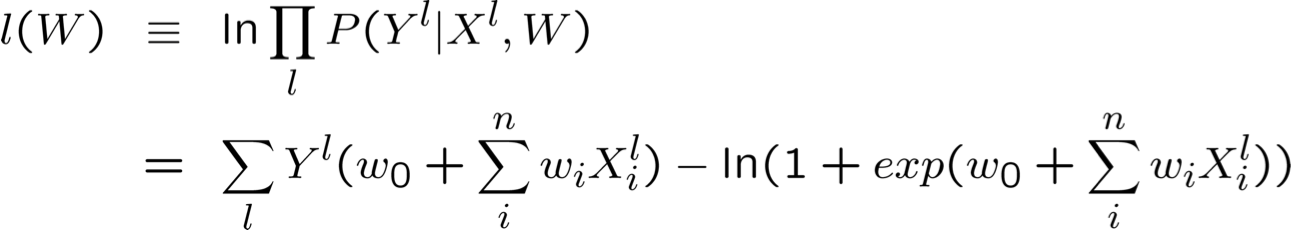
Tin tốt: l(W) là hàm lõm của W
Tin xấu: không có giải pháp dạng đóng nào để tối đa hóa l(W)
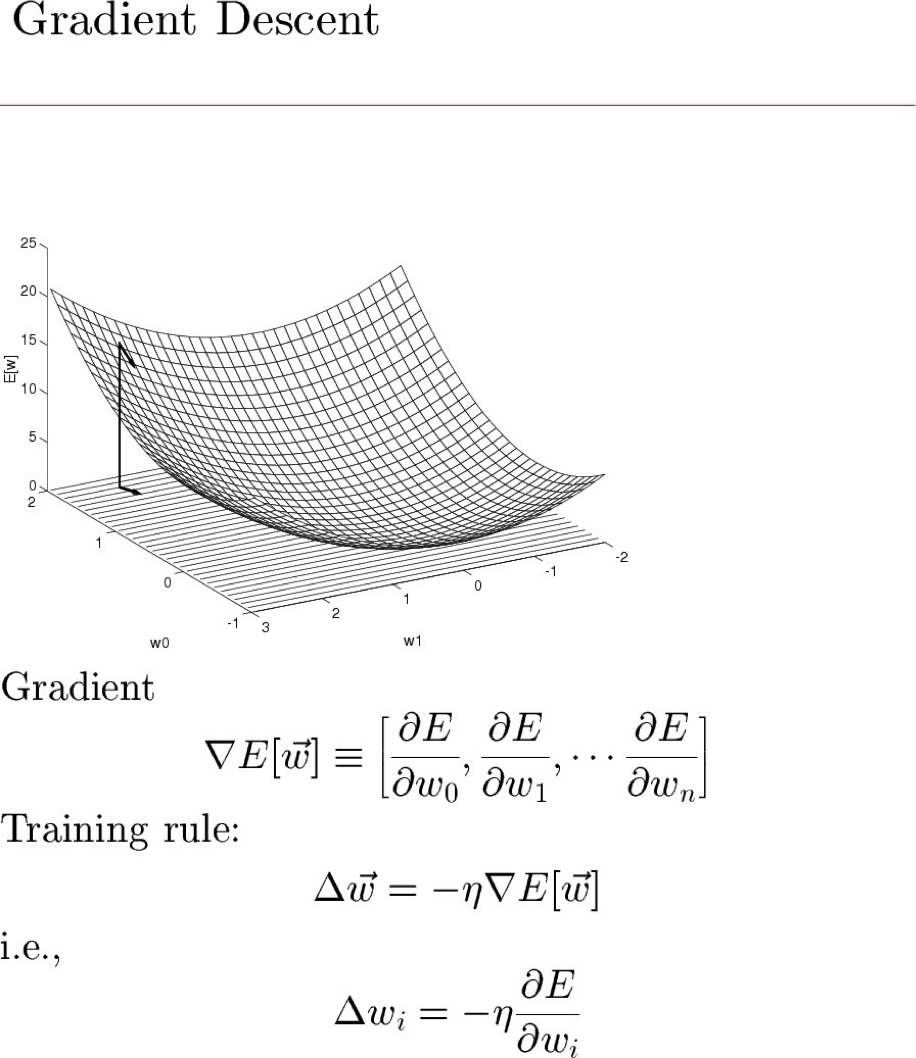
Gradient Descent:
Batch gradient: sử dụng lỗi ED(w) trên toàn bộ tập huấn luyện D
Thực hiện cho đến khi hài lòng:
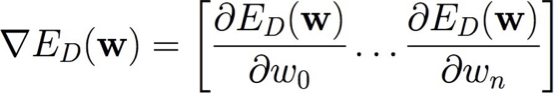
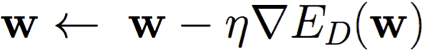
Độ dốc ngẫu nhiên: sử dụng lỗi Ed(w) đối với các mẫu đơn lẻ d ∈ D
Thực hiện cho đến khi hài lòng:
- Chọn (có thay thế) một mẫu đào tạo ngẫu nhiên d ∈ D
- Tính toán độ dốc chỉ dành cho d :
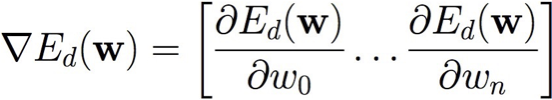
- Cập nhật vectơ tham số:
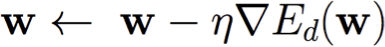
Stochastic xấp xỉ Batch gần tùy ý vì η → 0
Stochastic có thể nhanh hơn nhiều khi D rất lớn
Cách tiếp cận trung gian: sử dụng lỗi trên các tập con của D
Tối đa hóa hợp lý Log có điều kiện: Gradient Ascent
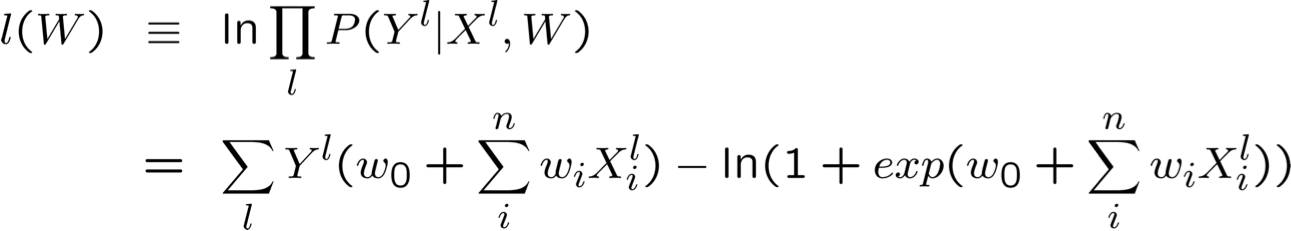
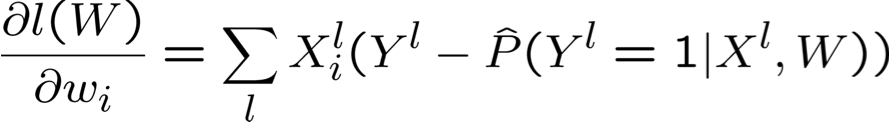
Tối đa hóa hợp lý log có điều kiện: Gradient Ascent
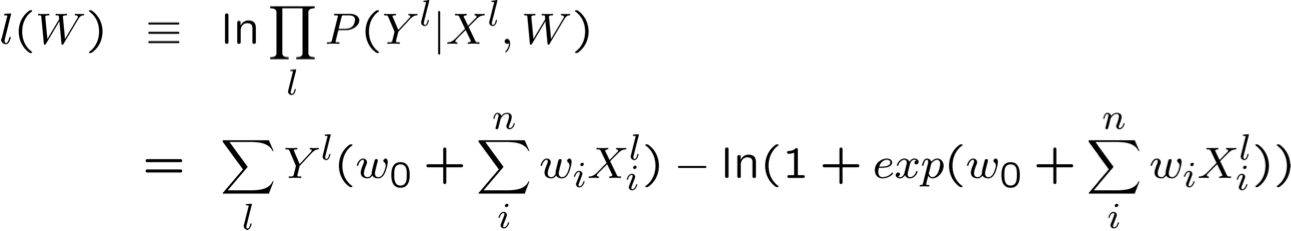
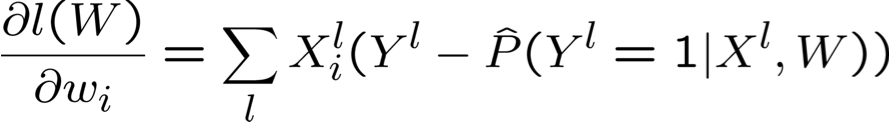
- Thuật toán tăng dần Gradient: lặp lại cho đến khi thay đổi < ε
- Đối với tất cả i lặp lại
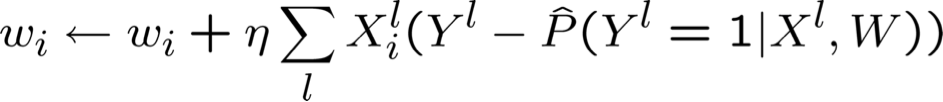
Đó là tất cả cho M(C)LE. Còn về MAP thì sao?
- Một cách tiếp cận phổ biến là xác định các ưu tiên trên W
- Phân phối chuẩn, trung bình bằng 0, hiệp phương sai đồng nhất
- Giúp tránh các trọng số rất lớn và quá khớp
- Ước tính MAP
- giả sử Gaussian trước: W ~ N(0, σ)
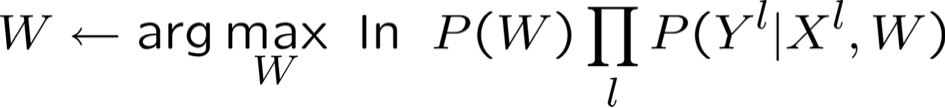
MLE so với MAP
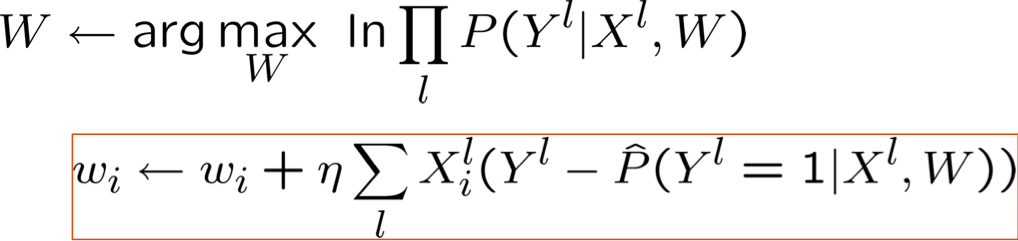
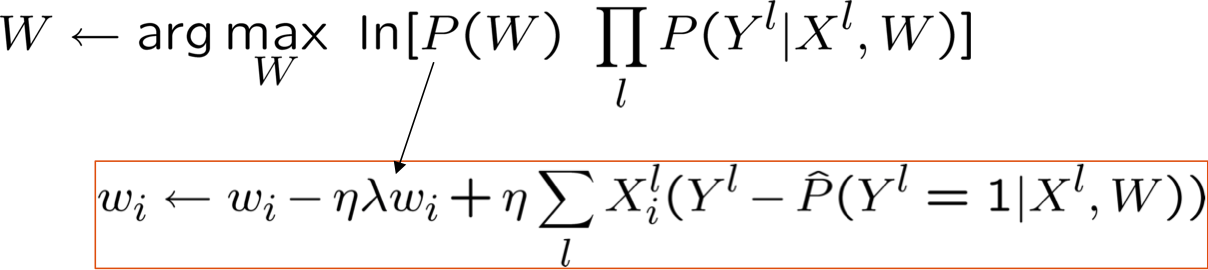
Ước tính MAP và Chính quy hóa
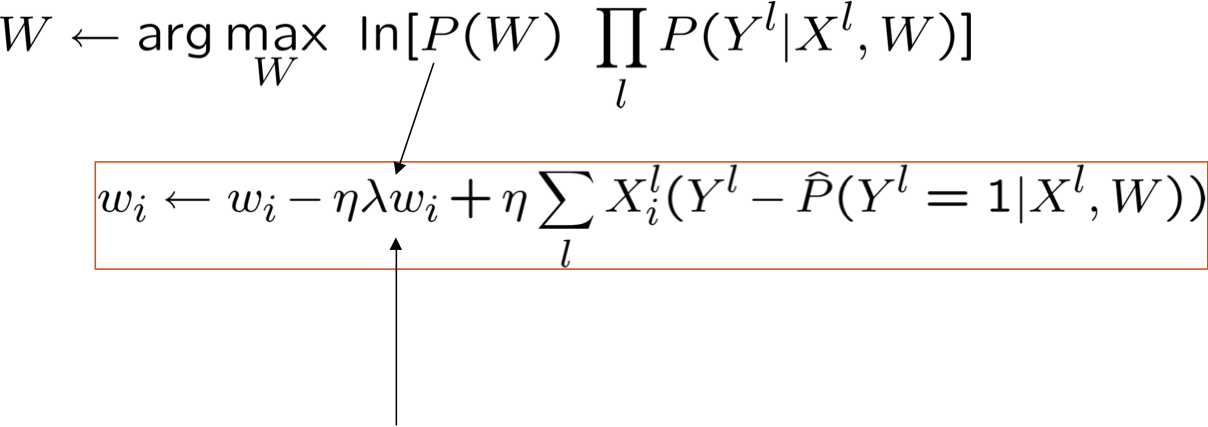
được gọi là thuật ngữ “chính quy hóa”
- giúp giảm khớp quá mức
- giữ trọng số gần hơn về 0 (nếu P(W) bằng 0 có nghĩa là Gaussian trước đó), hoặc bất cứ điều gì trước đó gợi ý
- được sử dụng rất thường xuyên trong Hồi quy logistic
Điểm mấu chốt
- Xem xét việc học f: X → Y, trong đó
- X là một vectơ của các đặc trưng có giá trị thực, < X1 … Xn >
- Y là boolean
- giả sử tất cả Xi đều độc lập có điều kiện với Y
- mô hình P(Xi | Y = yk) có dạng Gaussian N(µik,σi)
- mô hình P(Y) có dạng Bernoulli (π)
- Khi đó P(Y|X) có dạng này và chúng ta có thể ước tính trực tiếp W
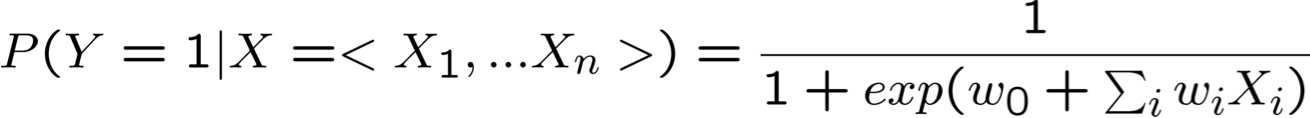
- Hơn nữa, điều tương tự cũng đúng nếu Xi là boolean
- đang cố gắng chứng minh điều đó với chính bạn
Bộ phân loại tạo sinh so với phân loại phân biệt
Bộ phân loại đào tạo liên quan đến việc ước tính f: X → Y hoặc P(Y|X)
Generative classifiers (ví dụ: Naïve Bayes)
- Giả sử một dạng hàm nào đó cho P(X|Y), P(X)
- Ước tính các tham số của P(X|Y), P(X) trực tiếp từ dữ liệu huấn luyện
- Sử dụng quy tắc Bayes để tính toán P(Y|X= xi)
Phân loại phân biệt (ví dụ: Hồi quy logistic)
- Giả sử một dạng hàm nào đó cho P(Y|X)
- Ước tính các tham số của P(Y|X) trực tiếp từ dữ liệu huấn luyện
Sử dụng Naïve Bayes hoặc Hồi quy Logisitic?
Xem xét
- Tính hạn chế của các giả định mô hình hóa
- Tỷ lệ hội tụ (về số lượng dữ liệu huấn luyện) đối với giả thuyết tiệm cận
Naïve Bayes vs Hồi quy logistic
Xét Y boolean, Xi liên tục, X=<X1 … Xn>
Số tham số cần ước lượng:
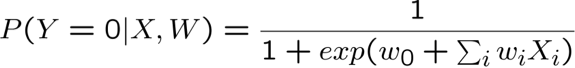
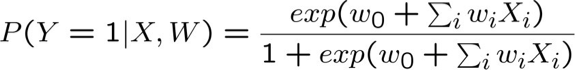
Naïve Bayes vs Hồi quy logistic
Xem xét Y boolean, Xi liên tục, X=<X1 … Xn>
Số tham số:
- NB: 4n +1
- LR: n+1
Phương pháp ước tính:
- Ước tính tham số NB không liên kết
- Ước tính tham số LR được liên kết
G.Naïve Bayes vs. Hồi quy logistic
Nhớ lại hai giả định dẫn xuất dạng LR từ GNBayes:
- Xi độc lập có điều kiện với Xk cho trước Y
- P(Xi | Y = yk) = N(µik,σi), ← not N(µik,σik)
Xem xét ba phương pháp học tập:
- GNB (chỉ giả định 1)
- GNB2 (giả định 1 và 2)
- LR
Phương pháp nào hoạt động tốt hơn nếu chúng ta có dữ liệu huấn luyện vô hạn, và…
- Cả (1) và (2) đều thỏa mãn
- Cả (1) và (2) đều không thỏa mãn
- (1) thỏa mãn nhưng không (2)
G.Naïve Bayes so với Hồi quy Logistic
[Ng & Jordan, 2002]
Nhớ lại hai giả định dẫn xuất dạng LR từ GNBayes:
- Xi độc lập có điều kiện với Xk cho trước Y
- P(Xi | Y = yk) = N(µik,σi), ← not N(µik,σik)
Xem xét ba phương pháp học tập:
- GNB (chỉ giả định 1)
- GNB2 (giả định 1 và 2)
- LR
Phương pháp nào hoạt động tốt hơn nếu chúng ta có dữ liệu đào tạo vô hạn và…
- Cả (1) và (2) đều thỏa mãn
- Cả (1) và (2) đều không thỏa mãn
- (1) thỏa mãn nhưng không (2)
G.Naïve Bayes vs. Logistic Regression
[Ng & Jordan, 2002]
Nhớ lại hai giả định dẫn xuất dạng LR từ GNBayes:
- Xi độc lập có điều kiện với Xk cho trước Y
- P(Xi | Y = yk) = N(µik,σi), ← not N(µik,σik)
Xem xét ba phương pháp học:
- GNB (chỉ giả định 1) — bề mặt quyết định có thể phi tuyến tính
- GNB2 (giả định 1 và 2) – bề mặt quyết định tuyến tính
- LR — bề mặt quyết định tuyến tính, được huấn luyện không có giả định 1.
Phương pháp nào hoạt động tốt hơn nếu chúng ta có dữ liệu đào tạo vô hạn và…
- Cả (1) và (2) đều thỏa mãn: LR = GNB2 = GNB
- (1) thỏa mãn nhưng không (2): GNB > GNB2, GNB > LR, LR > GNB2
- Cả (1) và (2) đều không thỏa mãn: GNB>GNB2, LR > GNB2, LR><GNB
G.Naïve Bayes vs. Logistic Regression
[Ng & Jordan, 2002]
Nếu chúng ta chỉ có dữ liệu đào tạo hữu hạn thì sao?
Chúng hội tụ ở các tốc độ khác nhau đối với lỗi tiệm cận (∞ dữ liệu) của chúng
Gọi εA,n tham khảo lỗi dự kiến của thuật toán học A sau n mẫu đào tạo
Gọi d là số đặc trưng: <X1 … Xd>
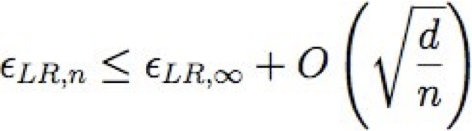
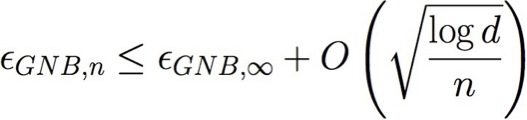
Vì vậy, GNB yêu cầu n = O(log d) để hội tụ, nhưng LR yêu cầu n = O(d)
Một số thử nghiệm từ bộ dữ liệu UCI
[Ng & Jordan, 2002]
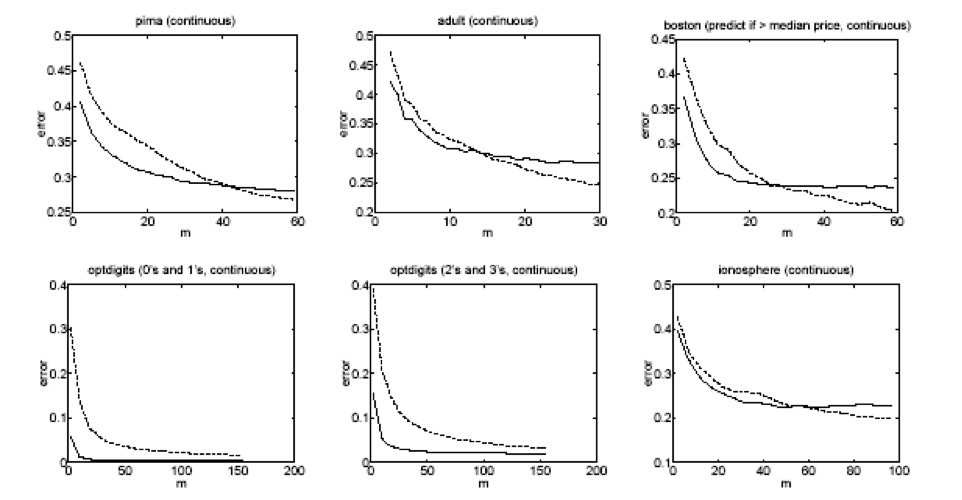
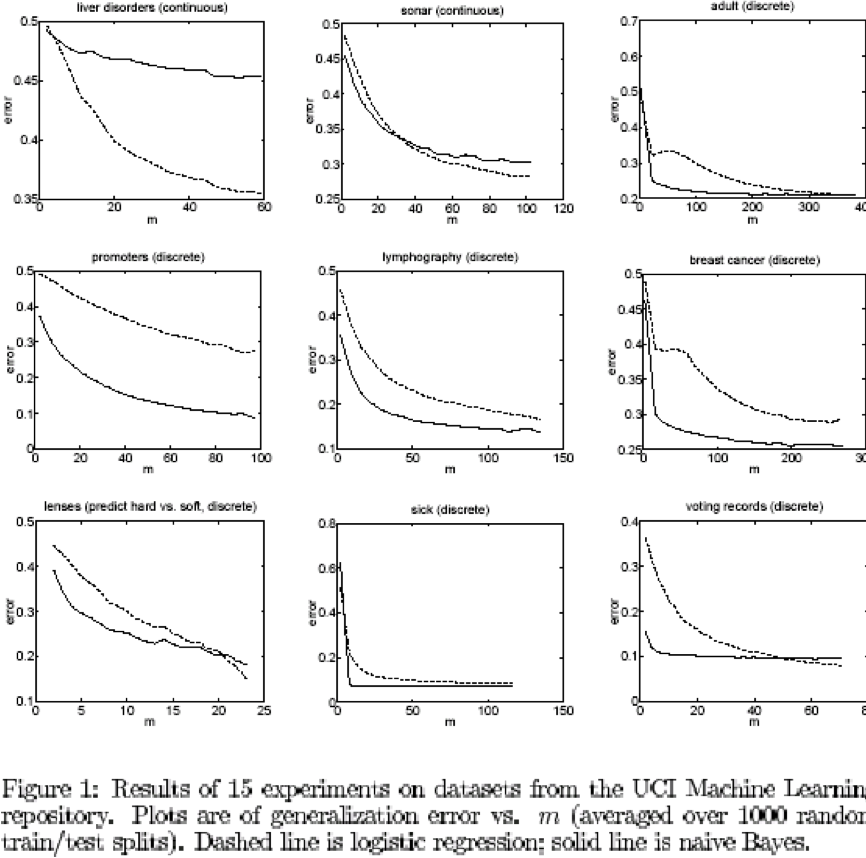
Naïve Bayes so với hồi quy logistic
điểm mấu chốt:
GNB2 và LR đều sử dụng các bề mặt quyết định tuyến tính, GNB không cần
Với dữ liệu vô hạn, LR tốt hơn hoặc bằng GNB2 vì quy trình đào tạo không đưa ra giả định 1 hoặc 2 (mặc dù việc tạo ra dạng P(Y|X) của chúng ta đã làm).
Nhưng GNB2 hội tụ nhanh hơn với lỗi tiệm cận có lẽ kém chính xác hơn
Và GNB vừa sai lệch hơn (giả định 1) vừa ít hơn (không có giả định 2) so với LR, do đó, cái này có thể tốt hơn cái kia
Những điều bạn nên biết:
- Hồi quy logistic
- Dạng hàm tuân theo các giả định Naïve Bayes
- Đối với Gaussian Naïve Bayes giả sử phương sai σi,k = σi
- Đối với Naïve Bayes có giá trị rời rạc cũng vậy
- Nhưng quy trình huấn luyện chọn tham số mà không đưa ra giả định về tính độc lập có điều kiện
- Huấn luyện MLE: chọn W để cực đại hóa P(Y | X, W)
- Huấn luyện MAP: chọn W để cực đại hóa P(W | X,Y)
- ‘chính quy hóa’
- giúp giảm hiện tượng quá khớp
- Dạng hàm tuân theo các giả định Naïve Bayes
- Tăng/giảm độ dốc
- Cách tiếp cận chung khi không có giải pháp dạng đóng
- Generative vs. Discriminative classifiers
- Sự đánh đổi giữa thiên vị và phương sai
các slide bổ sung
Lỗi tối thiểu có thể xảy ra là gì?
Trường hợp tốt nhất:
- giả định độc lập có điều kiện được thỏa mãn
- chúng ta biết P(Y), P(X|Y) một cách hoàn hảo (ví dụ: dữ liệu huấn luyện vô hạn)
Các câu hỏi cần suy nghĩ:
- Bạn có thể sử dụng Naïve Bayes cho sự kết hợp giữa Xi rời rạc và có giá trị thực không?
- Làm thế nào chúng ta có thể dễ dàng lập mô hình giả định rằng chỉ có 2 trong số n thuộc tính là phụ thuộc?
- Bề mặt quyết định của bộ phân loại Naïve Bayes trông như thế nào?
- Bạn sẽ chọn một tập con của Xi như thế nào?