Skip to the content
Chiến thuật tính sẵn sàng
- Sự thất bại (Failure)
- Sai lệch với hành vi chức năng mong đợi
- Quan sát được bởi người dùng hệ thống
- Sự thất bại vs khuyết điểm (fault)
- Khuyết điểm: sự kiện mà có thể gây ra một sự thất bại
- Các chiến thuật tính sẵn sàng
- Giữ cho các khuyết điểm không trở thành thất bại
- Thực hiện các sửa chữa có thể
Chiến thuật tính sẵn sàng (2)
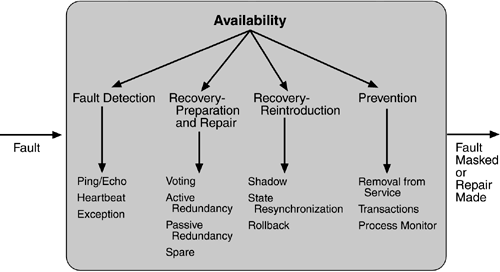
Phát hiện khuyết điểm: Ping / Echo
- Comp. 1 phát ra một “ping” đến comp. 2
- Comp. 1 mong đợi một “echo” từ comp. 2
- Trả lời trong khoảng thời gian xác định trước
- Có thể sử dụng cho một nhóm thành phần
- Cùng chịu trách nhiệm cho một nhiệm vụ
- Có thể sử dụng cho máy khách / máy chủ
- Kiểm tra máy chủ và đường truyền thông
- Hệ thống phân cấp của bộ phát hiện khuyết điểm cải thiện việc sử dụng băng thông
Phát hiện khuyết điểm: Heartbeat
- Comp. 1 phát ra thông báo “nhịp tim” (heartbeat) theo định kỳ
- Comp. 2 lắng nghe nó
- Nếu nhịp tim thất bại
- Comp. 1 giả định không thành công
- Thành phần sửa lỗi comp. 3 được thông báo
- Nhịp tim cũng có thể mang dữ liệu
Phát hiện khuyết điểm: Ngoại lệ
- Các lớp khuyết điểm: thiếu sót (omission), sự cố (crash), đáp ứng thời gian (timing), phản hồi sai (response)
- Khi một lớp khuyết điểm được nhận ra, ngoại lệ được đưa ra
- Do đó khuyết điểm được nhận ra
- Xử lý ngoại lệ
- Thực hiện trong cùng một tiến trình đã đưa ra ngoại lệ
- Thông thường thực hiện chuyển đổi ngữ nghĩa của khuyết điểm thành một dạng có thể xử lý
Phục hồi khuyết điểm: Bỏ phiếu
- Các tiến trình chạy trên bộ xử lý dự phòng lấy đầu vào tương đương và tính toán đầu ra
- Đầu ra được gửi đến người bỏ phiếu
- Người bỏ phiếu phát hiện hành vi sai lệch từ một bộ xử lý duy nhất => nó không thành công
- Phương pháp được sử dụng để sửa chữa
- Hoạt động bị lỗi của thuật toán
- Lỗi bộ xử lý
Phục hồi khuyết điểm: Dự phòng chủ động
- Tất cả các thành phần dự phòng phản ứng với các sự kiện song song => tất cả trong cùng một trạng thái
- Phản hồi từ chỉ một thành phần được sử dụng
- Thời gian chết (Downtime): thời gian chuyển mạch đến một thành phần cập nhật khác (ms)
- Được sử dụng trong cấu hình máy khách / máy chủ (hệ thống cơ sở dữ liệu)
- Phản hồi nhanh là quan trọng
- Đồng bộ hóa (Synchronization)
- Tất cả các thông báo đến bất kỳ thành phần dự phòng nào được gửi đến tất cả các thành phần dự phòng
Phục hồi khuyết điểm: Dự phòng bị động
- Thành phần chính
- đáp ứng các sự kiện
- thông báo cho các thành phần dự phòng về các cập nhật trạng thái mà chúng phải thực hiện
- Lỗi xảy ra:
- Hệ thống kiểm tra xem sao lưu đủ mới trước khi nối lại dịch vụ
- Thường được sử dụng trong hệ thống điều khiển
- Chuyển đổi định kỳ tăng tính khả dụng
Phục hồi khuyết điểm: Dự phòng thay thế
- Nền tảng điện toán dự phòng được cấu hình để thay thế nhiều thành phần bị lỗi khác nhau
- Phải khởi động lại đến cấu hình SW thích hợp
- Khởi tạo trạng thái của nó khi xảy ra lỗi
- Tạo điểm kiểm tra trạng thái hệ thống và ghi lại tất cả thay đổi trạng thái cho một thiết bị ổn định theo định kỳ
- Thời gian ngừng hoạt động: phút
Tái tạo khuyết điểm: Hoạt động bóng ma
- Thành phần bị lỗi trước đó có thể được chạy ở chế độ “bóng”
- Trong một thời gian
- Để đảm bảo rằng nó bắt chước hành vi của các thành phần đang hoạt động
- Trước khi khôi phục nó vào dịch vụ
Tái tạo khuyết điểm: Đồng bộ hóa lại trạng thái
- Dự phòng bị động và chủ động
- Thành phần được khôi phục nâng cấp trạng thái của nó trước khi trở lại dịch vụ
- Cập nhật phụ thuộc vào
- Thời gian ngừng hoạt động
- Kích thước của bản cập nhật
- Số lượng thông báo cần thiết cho bản cập nhật
- Một ưu tiên; nhiều hơn dẫn đến SW phức tạp
Tái tạo khuyết điểm: Điểm kiểm tra / Khôi phục
- Điểm kiểm tra
- Bản ghi về trạng thái nhất quán
- Được tạo định kỳ hoặc để phản ứng với các sự kiện cụ thể
- Hữu ích khi hệ thống bị lỗi bất thường, với trạng thái không nhất quán có thể phát hiện được: hệ thống được khôi phục bằng cách sử dụng
- Điểm kiểm tra trước đó của trạng thái nhất quán
- Nhật ký giao dịch xảy ra kể từ khi ảnh chụp nhanh được thực hiện
Phòng ngừa khuyết điểm
- Xóa khỏi dịch vụ
- Xóa comp khỏi hoạt động để trải qua một số hoạt động nhằm ngăn ngừa các lỗi dự đoán trước
- Exp: khởi động lại comp để ngăn rò rỉ bộ nhớ
- Tự động (thiết kế kiến trúc) hoặc thủ công (thiết kế hệ thống)
- Giao dịch
- các bước tuần tự được nhóm lại với nhau, như thế toàn bộ gói có thể được hoàn tác cùng một lúc
- Giám sát quy trình
- Nếu phát hiện lỗi trong tiến trình, thì tiến trình giám sát sẽ xóa tiến trình không hoạt động và tạo phiên bản mới của nó
- được khởi tạo đến một số trạng thái thích hợp như trong chiến thuật dự phòng thay thế
