
Bài đọc tham khảo
Boosting
- Phương pháp chung để cải thiện độ chính xác của bất kỳ thuật toán học cụ thể nào.
- Hoạt động bằng cách tạo một loạt các bộ dữ liệu thách thức mà ngay cả hiệu suất khiêm tốn nhất trên những bộ này cũng có thể được sử dụng để tạo ra một công cụ dự đoán tổng thể có độ chính xác cao.
- Hoạt động rất tốt trong thực tế — Adaboost và các biến thể của nó là một trong 10 thuật toán hàng đầu.
- Được hỗ trợ bởi nền móng vững chắc.
Bài đọc:

- Phương pháp Boosting học máy: Tổng quan. Rob Schapire, 2001
- Lý thuyết và ứng dụng của Boosting. Hướng dẫn NIPS. http://www.cs.princeton.edu/~schapire/talks/nips-tutorial.pdf
Kế hoạch cho hôm nay:
- Động lực.
- Một chút lịch sử.
- Adaboost: thuật toán, đảm bảo, thảo luận.
- Tập trung vào phân loại có giám sát.
Ví dụ: Phát hiện thư rác
- Vd: phân loại email nào là thư rác và email nào quan trọng.
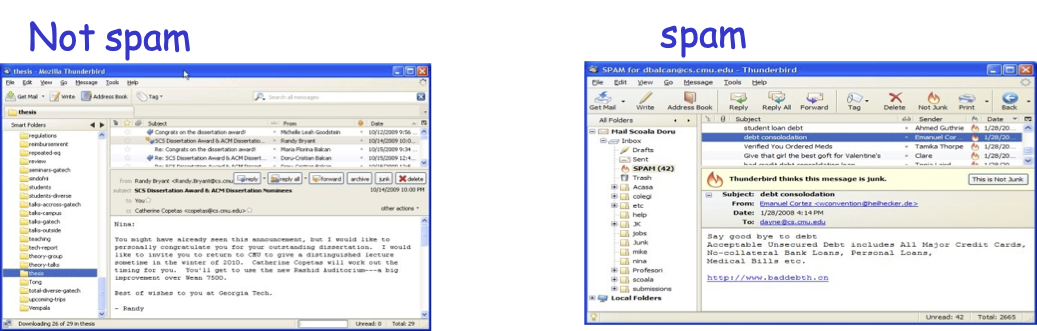
Quan sát/động lực chính:
- Dễ dàng tìm thấy các quy tắc ngón tay cái thường đúng.
- Ví dụ: “Nếu mua ngay trong tin nhắn, thì hãy dự đoán là thư rác.”
- Ví dụ: “Nếu nói lời tạm biệt với món nợ trong tin nhắn, thì hãy dự đoán thư rác.”
- Khó tìm quy tắc đơn lẻ có độ chính xác rất cao.
Ví dụ: Phát hiện thư rác
- Boosting: siêu thủ tục sử dụng thuật toán tìm quy tắc ngón tay cái (thuật toán học yếu). Tạo ra một quy tắc có độ chính xác cao, bằng cách gọi liên tục thuật toán học yếu trên các bộ dữ liệu được lựa chọn khéo léo.
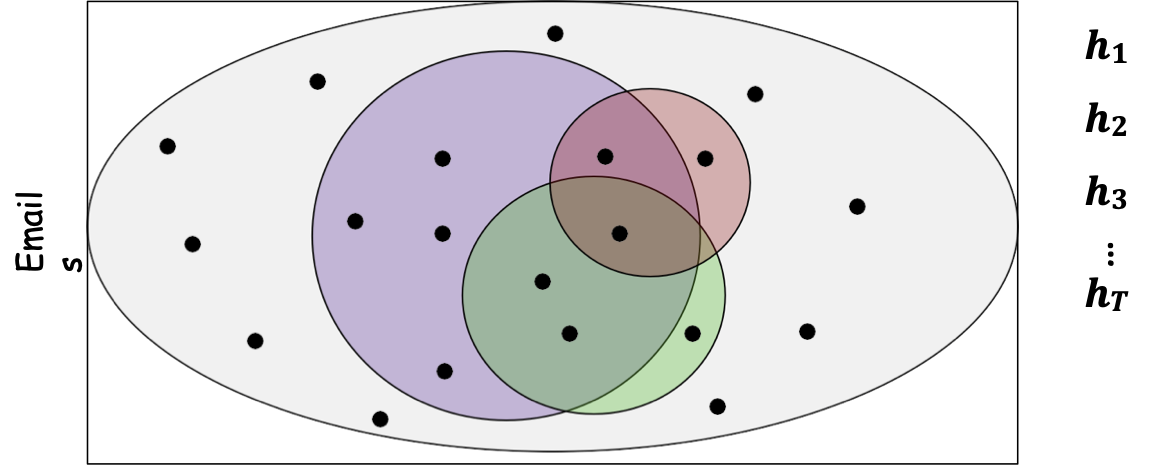
- áp dụng thuật toán học yếu cho một tập hợp con email, lấy quy tắc ngón tay cái
- áp dụng cho tập hợp con thứ 2 của email, lấy quy tắc ngón tay cái thứ 2
- áp dụng cho tập hợp con thứ 3 của email, lấy quy tắc ngón tay cái thứ 3
- lặp lại T lần; kết hợp các quy tắc yếu thành một quy tắc duy nhất có độ chính xác cao.
Boosting: Các khía cạnh quan trọng
Làm thế nào để chọn mẫu trên mỗi vòng?
- Thông thường, tập trung vào các mẫu “khó nhất” (những mẫu thường bị phân loại sai bởi các quy tắc ngón tay cái trước đó)
Làm cách nào để kết hợp các quy tắc ngón tay cái thành quy tắc dự đoán duy nhất?
- lấy (có trọng số) biểu quyết theo đa số các quy tắc ngón tay cái
Về mặt lịch sử….
Học yếu so với Học mạnh/PAC

- [Kearns & Valiant ’88]: học yếu được định nghĩa: có thể dự đoán tốt hơn đoán ngẫu nhiên (sai số ≤ 1⁄2 − 𝛾) , một cách nhất quán.
- Đưa ra một pb mở: “Liệu có tồn tại một thuật toán Boosting biến một thuật toán học yếu thành một thuật toán học PAC mạnh (có thể tạo ra các giả thuyết chính xác tùy ý) không?”
- Không chính thức, đưa ra thuật toán học tập “yếu” có thể nhất quán tìm bộ phân loại có lỗi ≤ 1⁄2 − 𝛾, một thuật toán Boosting có thể chứng minh là xây dựng một bộ phân loại duy nhất có lỗi ≤ 𝜖.
Học Yếu so với Học Mạnh/PAC
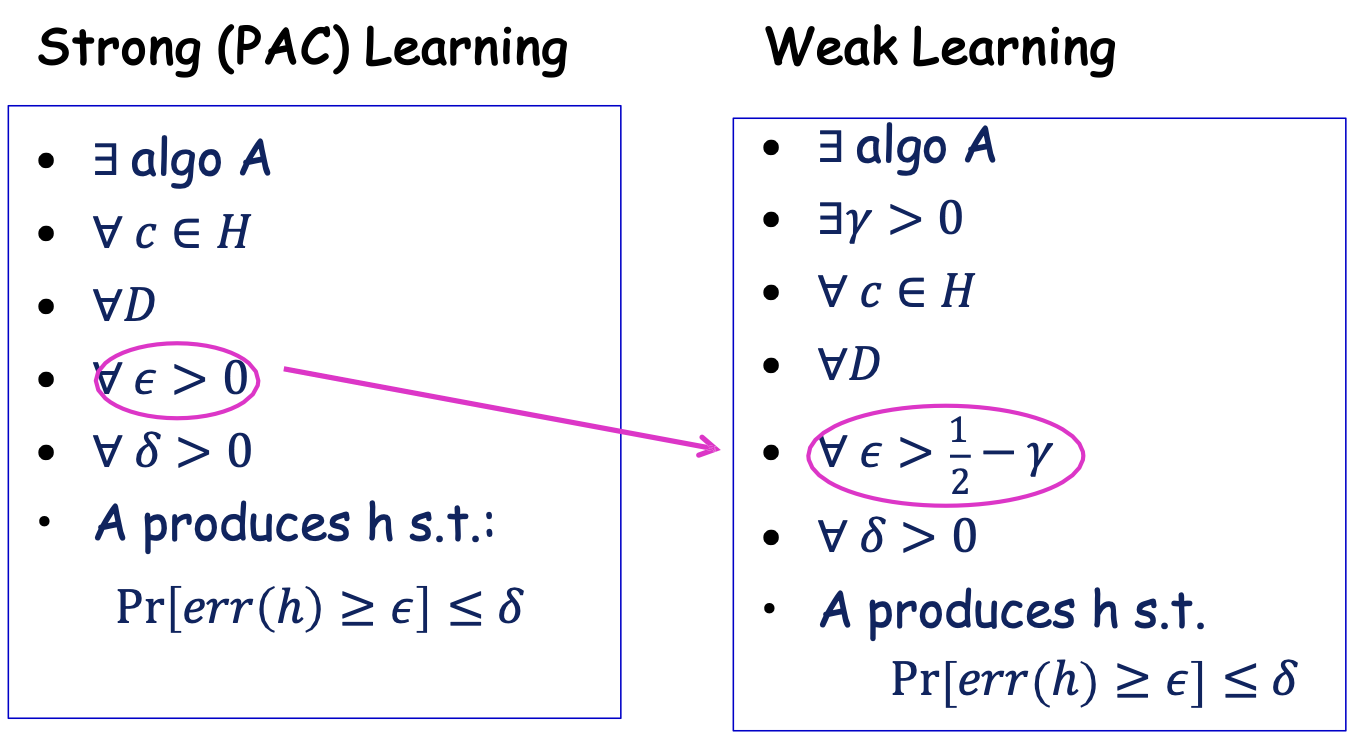
- [Kearns & Valiant ’88]: đã định nghĩa việc học yếu & đặt ra một pb mở về việc tìm kiếm một thuật toán Boosting.

Thật ngạc nhiên….
Học yếu = Học mạnh (PAC)
Xây dựng ban đầu [Schapire ’89]:

- thuật toán Boosting thời gian đa thức, khai thác mà chúng ta có thể học một chút trên mỗi bản phân phối.
- Một bộ Boosting khiêm tốn thu được bằng cách gọi thuật toán học yếu trên 3 bản phân phối.Lỗi = 𝛽 < 1⁄2 − 𝛾 → lỗi 3𝛽2 − 2𝛽3
- Sau đó, khuếch đại mức tăng độ chính xác vừa phải bằng cách chạy đệ quy bằng cách nào đó.
- Rất tốt về mặt khái niệm và kỹ thuật, không thực tế lắm.
Sự bùng nổ của công việc tiếp theo

Adaboost (Boosting thích ứng)
“A Decision-Theoretic Generalization of On-Line Learning and an Application để Boosting” [Freund-Schapire, JCSS’97]
Người đoạt giải Godel 2003
Mô tả không chính thức Adaboost
- Boosting: biến một thuật toán yếu thành một thuật toán học mạnh (PAC).
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)}; xi ∈ 𝑋, 𝑦𝑖 ∈ 𝑌 = {−1,1}
thuật toán học yếu A (ví dụ: Naïve Bayes, các gốc quyết định)
- Với t=1,2, … ,T
- Xây dựng Dt trên {x1, …, xm}
- Chạy A trên Dt tạo ra ht: 𝑋 → {−1,1} (phân loại yếu)
ϵt = Pxi ~Dt (ht(xi) ≠ yi) lỗi của ht trên Dt
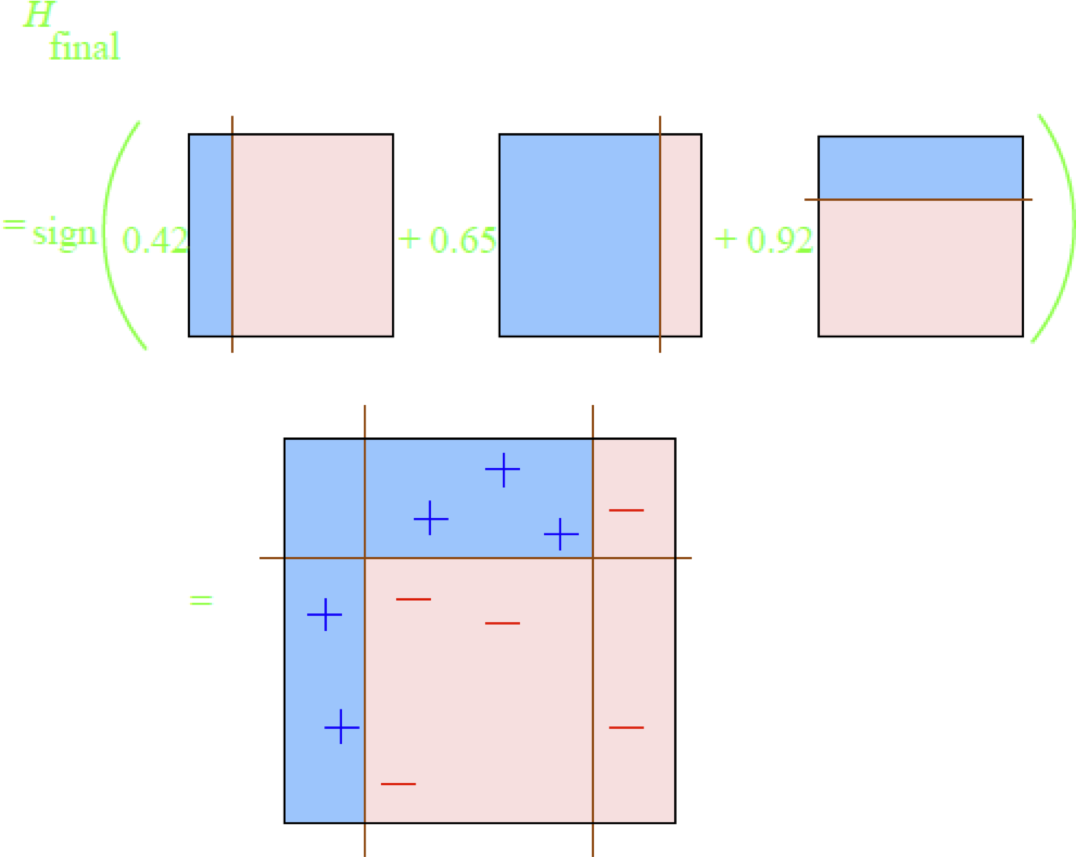
- Đầu ra Hfinal(𝑥) = sign(∑𝑡=1 𝛼𝑡ℎ𝑡(𝑥))
Nói đại khái Dt+1 tăng trọng lượng trên xi nếu ht sai trên xi ; giảm nó trên xi nếu ht đúng.
Adaboost (Boosting thích ứng)
- Thuật toán học yếu A.
- Với t=1,2, … ,T
- Xây dựng 𝐃𝐭 trên {𝐱𝟏, …, 𝒙𝐦}
- Chạy A trên Dt tạo ht
Dựng 𝐷𝑡
- D1 đồng nhất trên {x1, …, xm} [nghĩa là D1(𝑖) = 1⁄𝑚]
- Cho Dt và ht đặt
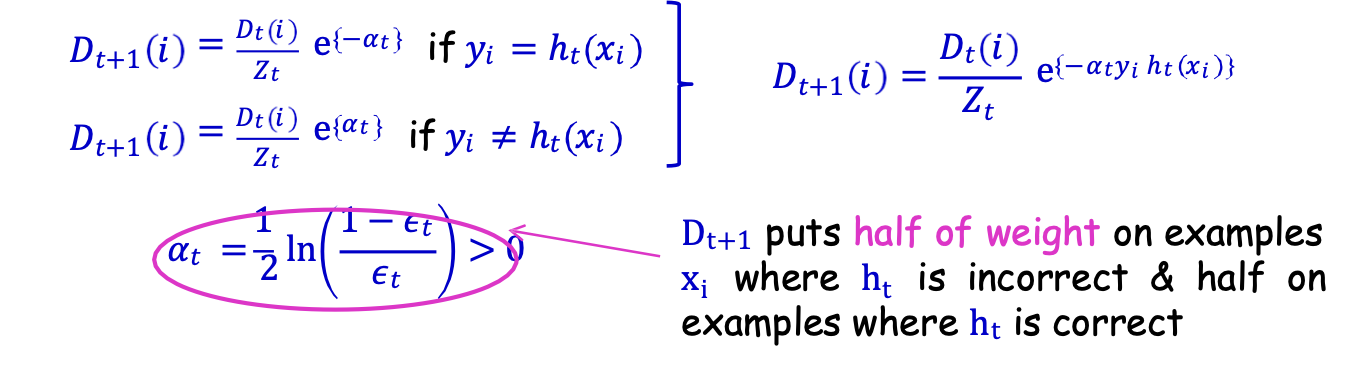
Dt+1 đặt một nửa trọng số cho các mẫu xi khi ht sai & một nửa cho các mẫu ht đúng
cuối cùng hyp: Hfinal(𝑥) = sign(∑𝑡 𝛼𝑡ℎ𝑡(𝑥))
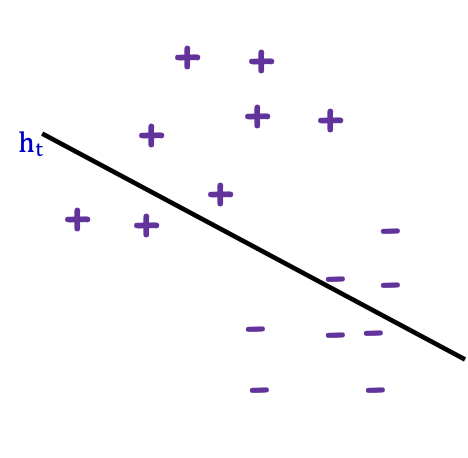
Adaboost: Một ví dụ đồ chơi
bộ phân loại yếu: nửa mặt phẳng dọc hoặc ngang (còn gọi là gốc cây quyết định)
Adaboost: Một ví dụ về đồ chơi
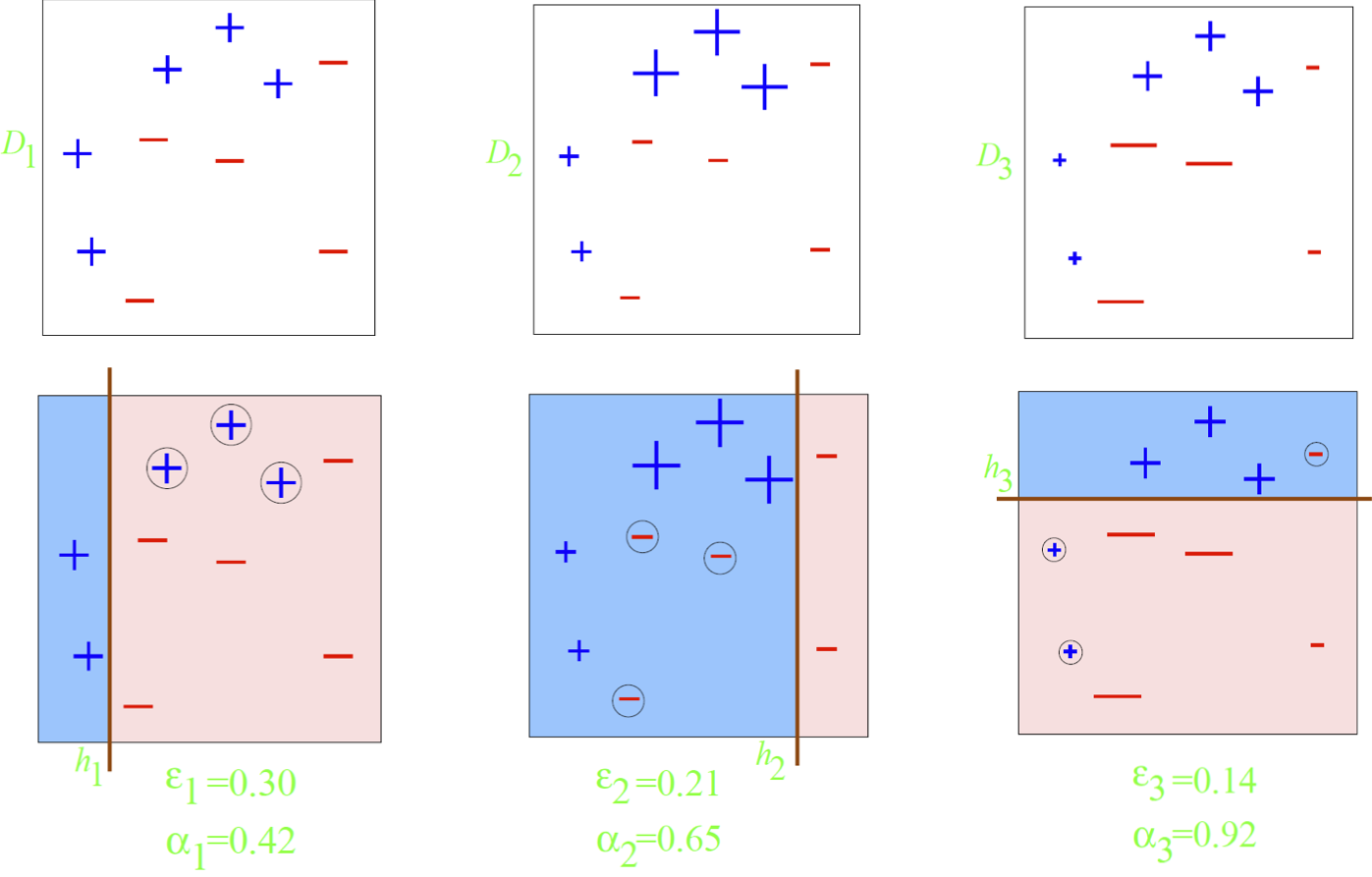
Adaboost: Một ví dụ về đồ chơi
Adaboost (Boosting thích ứng)
- Thuật toán học yếu A.
- Với t=1,2, … ,T
- Xây dựng 𝐃𝐭 trên {𝐱𝟏, …, 𝒙𝐦}
- Chạy A trên Dt tạo ra ht
Dựng 𝐷𝑡
- D1 đồng nhất trên {x1, …, xm} [nghĩa là D1(𝑖) = 1⁄𝑚]
- Cho Dt và ht đặt
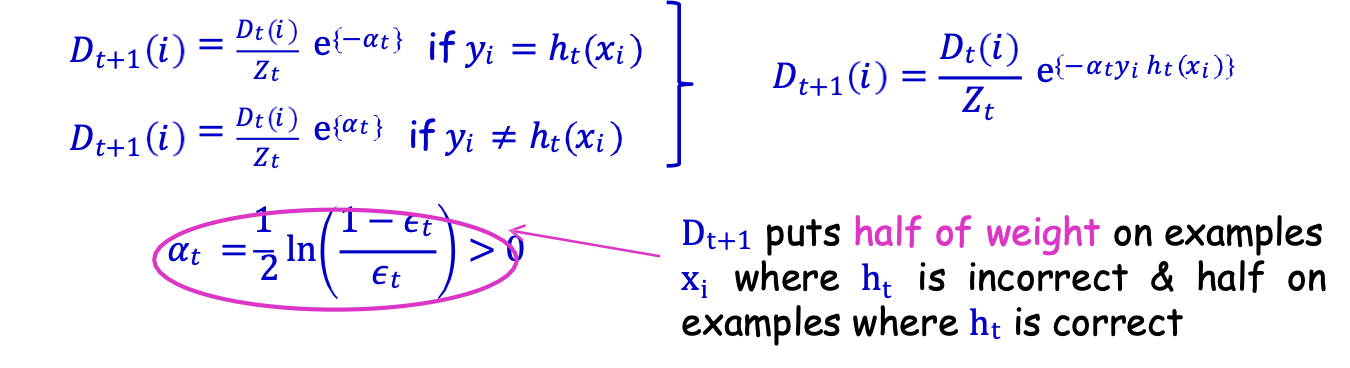
Dt+1 đặt một nửa trọng số cho các mẫu xi khi ht sai & một nửa cho các mẫu ht đúng
HYP cuối cùng: Hfinal(𝑥) = sign(∑𝑡 𝛼𝑡ℎ𝑡(𝑥))
Các tính năng hay của Adaboost
- Rất tổng quát: một siêu thủ tục, nó có thể sử dụng bất kỳ thuật toán học yếu nào!!! (ví dụ: Naïve Bayes, các gốc quyết định)
- Rất nhanh (dữ liệu đi qua một lần trong mỗi vòng) & viết mã đơn giản, không cần điều chỉnh tham số.
- Thay đổi tư duy: mục tiêu bây giờ chỉ là tìm ra các bộ phân loại tốt hơn một chút so với đoán ngẫu nhiên.
- Dựa trên lý thuyết phong phú.
- Phù hợp với thời đại dữ liệu lớn: nhanh chóng tập trung vào “những khó khăn cốt lõi”, rất phù hợp với các cài đặt phân tán, nơi dữ liệu phải được truyền đạt hiệu quả [Balcan-Blum-Fine-Mansour COLT’12].
Phân tích Lỗi Huấn luyện
Định lý 𝜖𝑡 = 1/2 − 𝛾𝑡 (lỗi của ℎ𝑡 trên 𝐷𝑡)
𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2]
Vì vậy, nếu ∀𝑡, 𝛾𝑡 ≥ 𝛾 > 0 thì 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp[ −2 𝛾2𝑇]
Sai số giảm hàm mũ!!!
Để nhận 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ 𝜖, chỉ cần 𝑇 = 𝑂 (1⁄𝛾2 log (1⁄𝜖)) Vòng
Adaboost là thích ứng
- Không cần biết 𝛾 hoặc T tiên nghiệm
- Có thể khai thác 𝛾𝑡 ≫ 𝛾
Tìm hiểu các bản cập nhật & chuẩn hóa
Yêu cầu: Dt+1 đặt một nửa trọng lượng lên xi khi ht sai và một nửa trọng số lên xi khi ht đúng.
Nhớ lại 𝐷𝑡+1(𝑖) = 𝐷𝑡(𝑖)⁄𝑍𝑡 e{−𝛼𝑡𝑦𝑖ℎ𝑡(𝑥𝑖)}
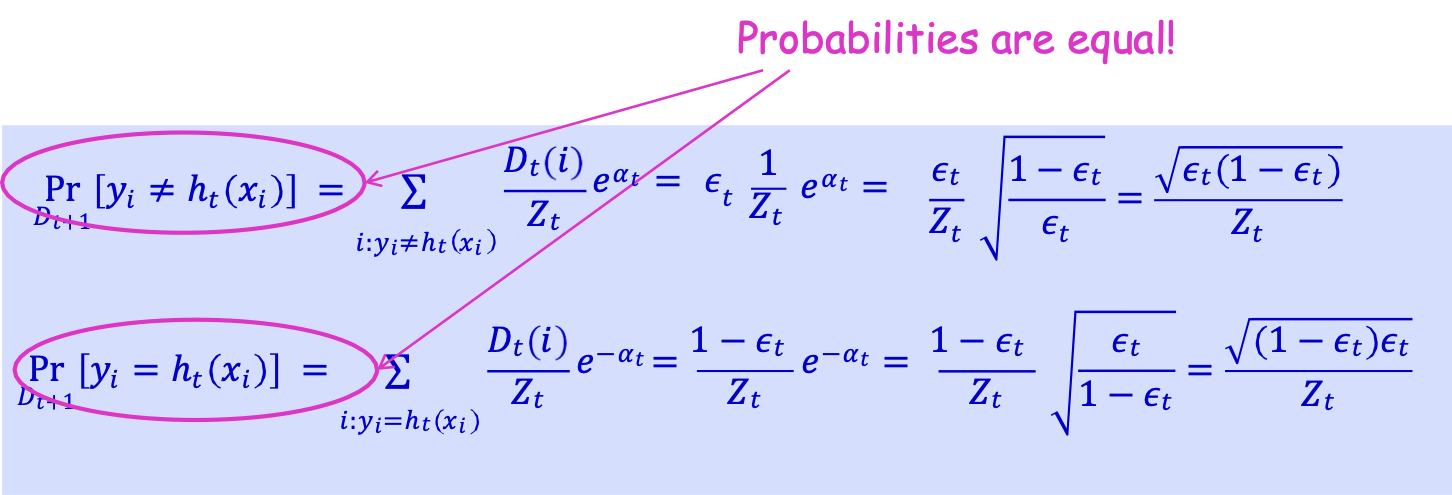
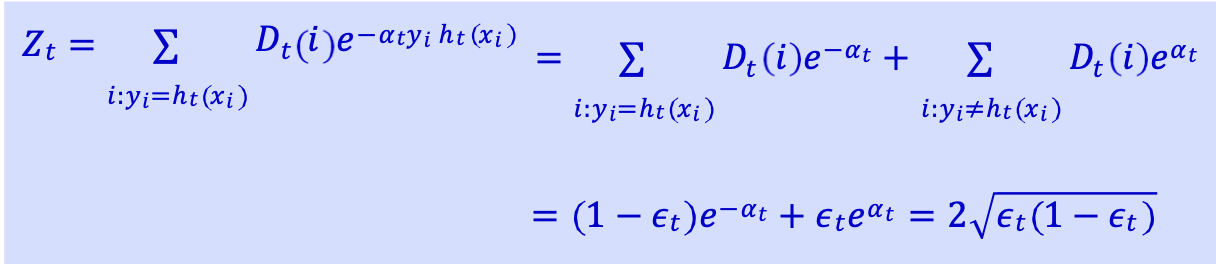
Xác suất là như nhau!
Phân Tích Lỗi Đào Tạo: Bằng Chứng Trực Giác
Định lý 𝜖𝑡 = 1/2 − 𝛾𝑡 (sai số của ℎ𝑡 trên 𝐷𝑡)
𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2]
- Ở vòng 𝑡, ta tăng trọng số của 𝑥𝑖 mà ℎ𝑡 sai.
- Nếu 𝐻𝑓𝑖𝑛𝑎𝑙 phân loại sai 𝑥𝑖,
- Khi đó 𝑥𝑖 được phân loại sai bởi (wtd) đa số ℎ𝑡‘s.
- Điều đó ngụ ý trọng số xác suất cuối cùng của 𝑥𝑖 lớn.
Có thể cho thấy xác suất ≥ 1⁄𝑚 (1⁄∐𝑡𝑍𝑡)
- Vì tổng của xác suất = 1, không thể có quá nhiều trọng số cao.
Có thể cho thấy # phân loại sai ≤ 𝑚 (∐𝑡𝑍𝑡).
Và (∐𝑡𝑍𝑡) → 0.
Phân tích lỗi huấn luyện: Toán chứng minh
Bước 1: mở gói lặp lại: 𝐷𝑇+1(𝑖) = 1⁄𝑚 (exp(−𝑦𝑖𝑓(𝑥𝑖))⁄∐𝑡𝑍𝑡) trong đó 𝑓(𝑥𝑖) = ∑𝑡 𝛼𝑡ℎ𝑡(𝑥𝑖). [Phiếu bầu có trọng số không giới hạn của ℎ𝑖 trên 𝑥𝑖 ]
Bước 2 : errS(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ ∐𝑡𝑍𝑡.
Bước 3: ∐𝑡𝑍𝑡 = ∐𝑡 2 √𝜖𝑡 (1 − 𝜖𝑡) = ∐𝑡 √1 − 4𝛾𝑡2 ≤ 𝑒−2 ∑𝑡 𝛾𝑡2
Phân tích lỗi huấn luyện: Toán chứng minh
Bước 1: mở gói lặp lại: 𝐷𝑇+1(𝑖) = 1⁄𝑚 (exp(−𝑦𝑖𝑓(𝑥𝑖))⁄∐𝑡𝑍𝑡) trong đó 𝑓(𝑥𝑖) = ∑𝑡 𝛼𝑡ℎ𝑡(𝑥𝑖).
Nhớ lại 𝐷1(𝑖) = 1⁄𝑚 và 𝐷𝑡+1(𝑖) = 𝐷𝑡(𝑖) exp(−𝑦𝑖𝛼𝑡ℎ𝑡(𝑥𝑖))⁄𝑍𝑡
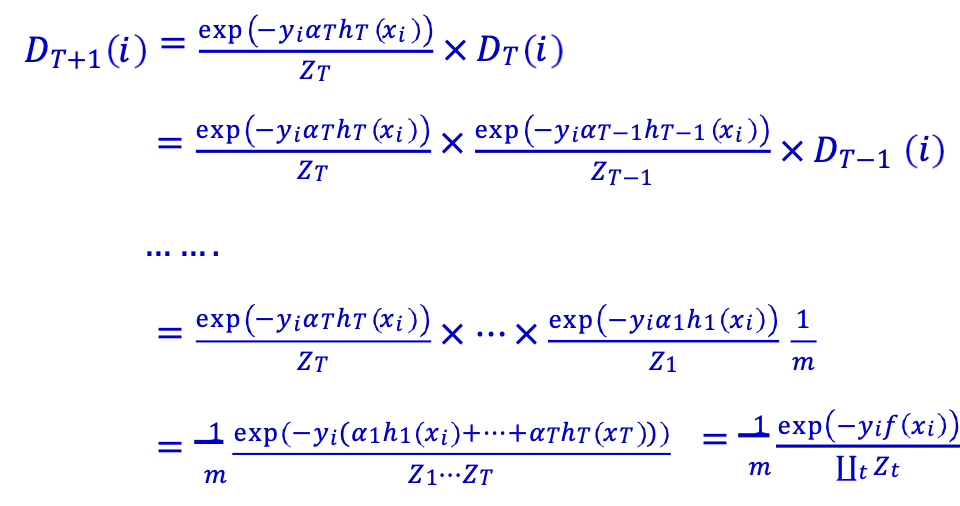
Phân tích lỗi huấn luyện: Toán chứng minh
Bước 1: mở gói lặp lại: 𝐷𝑇+1(𝑖) = 1⁄𝑚 (exp(−𝑦𝑖𝑓(𝑥𝑖))⁄∐𝑡𝑍𝑡) trong đó 𝑓(𝑥𝑖) = ∑𝑡 𝛼𝑡ℎ𝑡(𝑥𝑖).
Bước 2: errS(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ ∐𝑡𝑍𝑡.
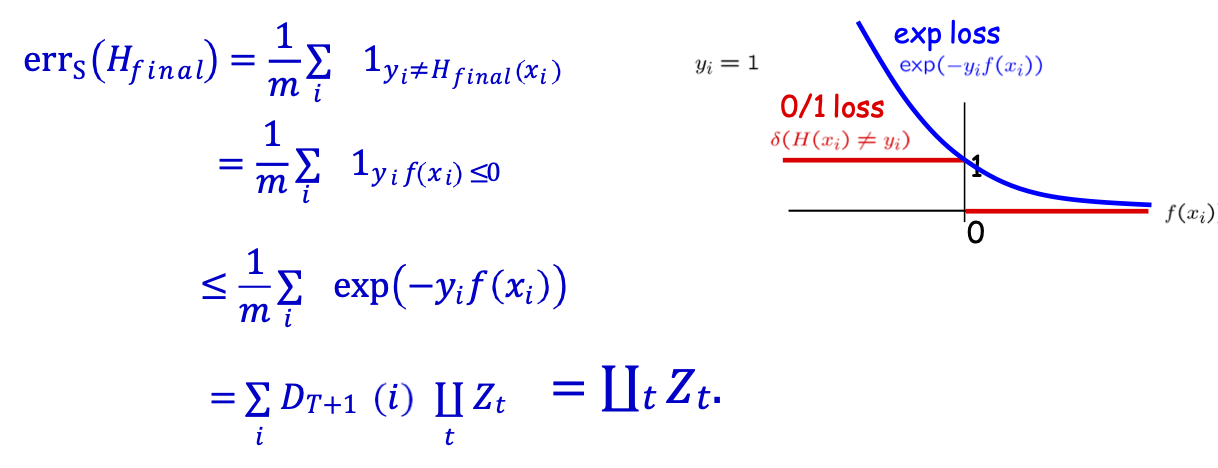
mất hàm mũ
Phân tích lỗi huấn luyện: Toán chứng minh
Bước 1: mở gói lặp lại: 𝐷𝑇+1(𝑖) = 1⁄𝑚 (exp(−𝑦𝑖𝑓(𝑥𝑖))⁄∐𝑡𝑍𝑡) trong đó 𝑓(𝑥𝑖) = ∑𝑡 𝛼𝑡ℎ𝑡(𝑥𝑖).
Bước 2: errS(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ ∐𝑡𝑍𝑡.
Bước 3: ∐𝑡𝑍𝑡 = ∐𝑡 2 √𝜖𝑡 (1 − 𝜖𝑡) = ∐𝑡 √1 − 4𝛾𝑡2 ≤ 𝑒−2 ∑𝑡 𝛾𝑡2
Lưu ý: nhớ lại 𝑍𝑡 = (1 − 𝜖𝑡)𝑒−𝛼𝑡 + 𝜖𝑡𝑒𝛼𝑡 = 2 √𝜖𝑡 (1 − 𝜖𝑡)
𝛼𝑡 cực tiểu của 𝛼 → (1 − 𝜖𝑡)𝑒−𝛼 + 𝜖𝑡𝑒𝛼
Phân tích lỗi huấn luyện: Chứng minh trực giác
Định lý 𝜖𝑡 = 1/2 − 𝛾𝑡 (sai số của ℎ𝑡 trên 𝐷𝑡)
𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2]
- Ở vòng 𝑡, ta tăng trọng số của 𝑥𝑖 mà ℎ𝑡 sai.
- Nếu 𝐻𝑓𝑖𝑛𝑎𝑙 phân loại sai 𝑥𝑖,
- Khi đó 𝑥𝑖 được phân loại sai bởi (wtd) đa số ℎ𝑡’s.
- Điều đó ngụ ý trọng số xác suất cuối cùng của 𝑥𝑖 lớn.
Có thể cho thấy xác suất ≥ 1⁄𝑚 (1⁄∐𝑡𝑍𝑡)
- Vì tổng của xác suất = 1, không thể có quá nhiều trọng số cao.
Có thể cho thấy # phân loại sai ≤ 𝑚 (∐𝑡𝑍𝑡).
Và (∐𝑡𝑍𝑡) → 0.
Đảm bảo khái quát hóa
Định lý 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2] trong đó 𝜖𝑡 = 1/2 − 𝛾𝑡
Làm thế nào về đảm bảo tổng quát?
Giải tích ban đầu [Freund&Schapire’97]
- Không gian H của các giả thuyết yếu; d=VCdim(H)
𝐻𝑓𝑖𝑛𝑎𝑙 là một phiếu bầu có trọng số, vì vậy lớp giả thuyết là:
G = {tất cả các fns của dấu hiệu biểu mẫu sign(∑𝑇𝑡=1 𝛼𝑡ℎ𝑡(𝑥))}
Định lý [Freund & Schapire’97]
∀ 𝑔 ∈ 𝐺, 𝑒𝑟𝑟(𝑔) ≤ 𝑒𝑟𝑟𝑆(𝑔) + 𝑂 (√𝑇𝑑⁄𝑚) T= # vòng
Lý do chính: VCd𝑖𝑚(𝐺) = 𝑂(𝑑𝑇) cộng với các giới hạn VC điển hình.
Đảm bảo tổng quát hóa
Định lý [Freund&Schapire’97]
∀ 𝑔 ∈ 𝑐𝑜(𝐻), 𝑒𝑟𝑟(𝑔) ≤ 𝑒𝑟𝑟𝑆(𝑔) + 𝑂 (√𝑇𝑑⁄𝑚) trong đó d=VCdim(H)
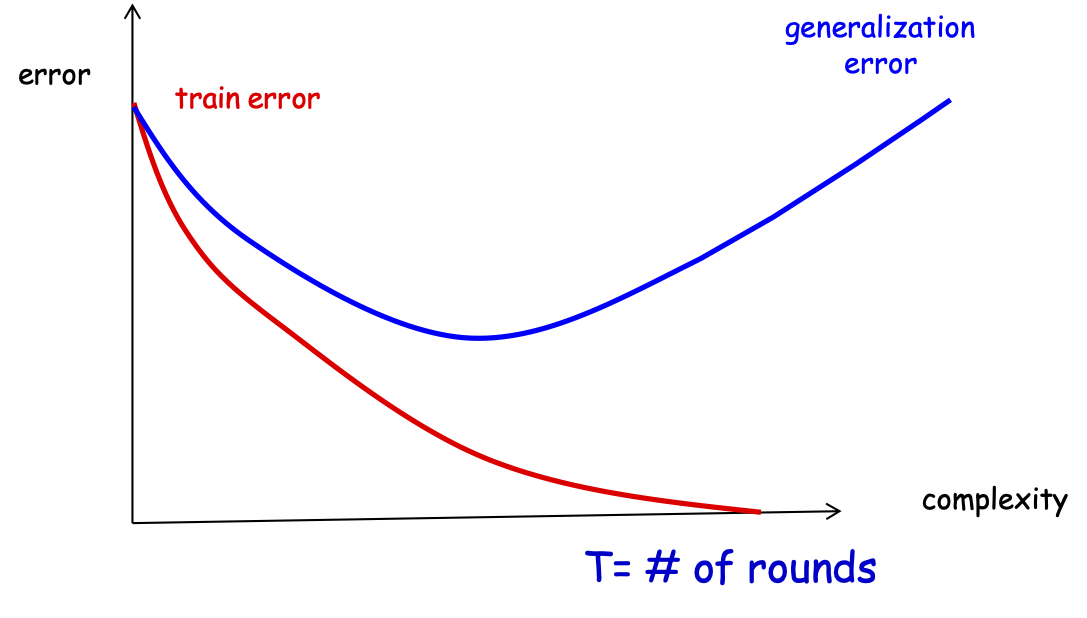
lỗi huấn luyện
lỗi tổng quát
T= # vòng
Đảm bảo tổng quát hóa
- Các thử nghiệm với việc tăng cường cho thấy lỗi kiểm tra của bộ phân loại được tạo ra thường không tăng khi kích thước của nó trở nên rất lớn.
- Thực nghiệm cho thấy việc tiếp tục thêm mới các học viên yếu kém sau khi phân loại đúng tập huấn luyện đã đạt được có thể cải thiện hơn nữa hiệu suất của bộ kiểm tra!!!
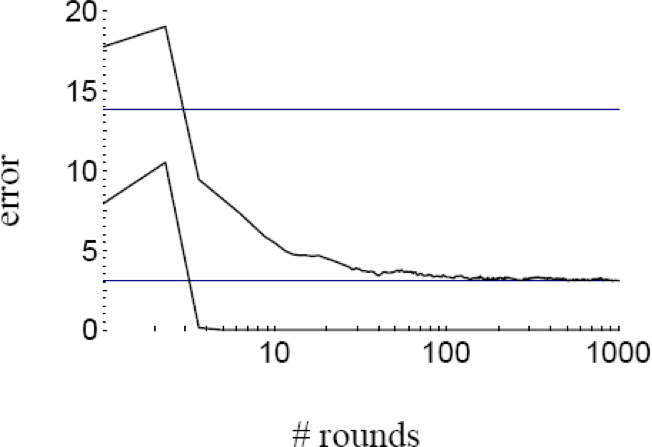
Đảm bảo tổng quát hóa
- Các thử nghiệm với việc tăng cường cho thấy lỗi kiểm tra của
bộ phân loại được tạo ra thường không tăng khi kích thước của nó trở nên rất lớn. - Các thử nghiệm cho thấy rằng việc tiếp tục thêm những học viên yếu mới sau khi đã đạt được phân loại chính xác của tập huấn luyện có thể cải thiện hơn nữa hiệu suất của tập kiểm tra!!!
- Những kết quả này dường như mâu thuẫn với FS’87 bound và Occam’s razor (để đạt được lỗi kiểm tra tốt, bộ phân loại phải càng đơn giản càng tốt)!
Làm thế nào chúng ta có thể giải thích các thí nghiệm?
R. Schapire, Y. Freund, P. Bartlett, WS Lee. trình bày trong “Tăng tỷ suất lợi nhuận: Một lời giải thích mới về tính hiệu quả của các phương pháp bỏ phiếu” một lời giải thích lý thuyết hay.
Ý tưởng chính:
Lỗi đào tạo không nói lên toàn bộ câu chuyện.
Chúng ta cũng cần xem xét độ tin cậy phân loại!!