
Bài đọc tham khảo
Hai khía cạnh cốt lõi của học máy
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
- Ví dụ: hồi quy logistic, SVM, Adaboost, v.v.
Dữ liệu (được gắn nhãn)
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc đối với dữ liệu trong tương lai.
Hôm nay:
Trọng tâm của ngày hôm nay: Độ phức tạp của mẫu để phân loại được giám sát (Xấp xỉ hàm)
- Statistical Learning Theory (Vapnik)
- PAC (Valiant)
- Nên đọc: Mitchell: Ch. 7
- Bài tập gợi ý: 7.1, 7.2, 7.7
- Tài liệu bổ sung: giáo trình lý thuyết học tập của tôi!
Học có giám sát
- Ví dụ: email nào là thư rác và email nào quan trọng.
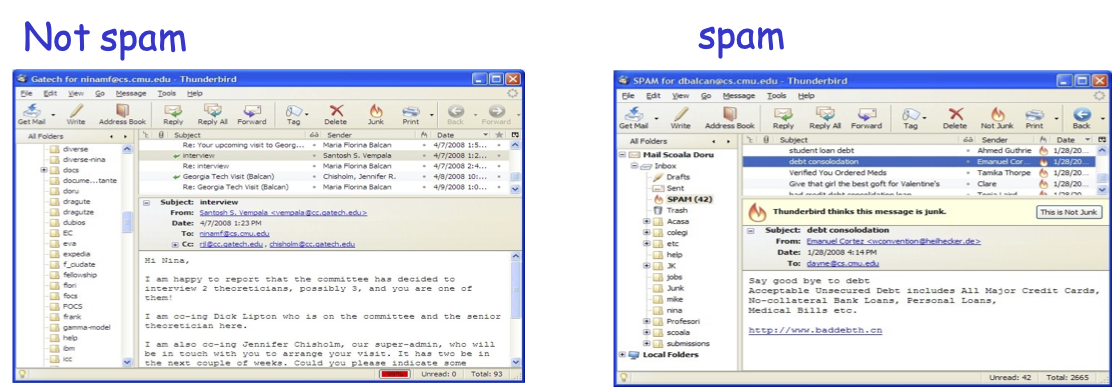
- Vd: phân loại hình ảnh là đàn ông so với phụ nữ.

Các mô hình PAC/SLT dành cho Học có giám sát
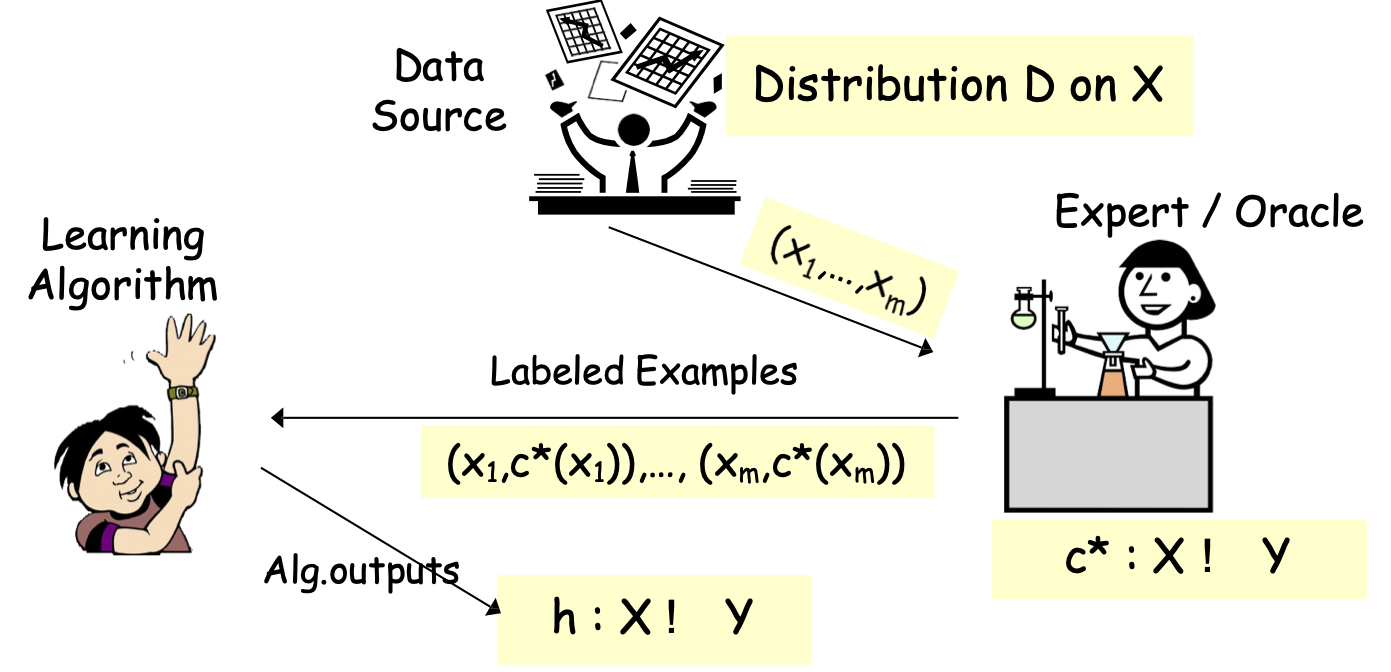
Các mô hình PAC/SLT cho Học có giám sát
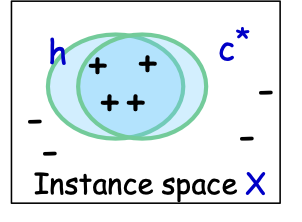
- X – không gian đối tượng/đặc trưng; phân phối D trên X
- ví dụ: X = Rd hoặc X = {0,1}d
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- các mẫu được gắn nhãn – i.i.d. được rút ra từ D và được gắn nhãn bởi đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán tối ưu hóa trên S, tìm giả thuyết ℎ.
- Mục tiêu: h có lỗi nhỏ trên D.
- 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))

Sai lệch: cố định không gian giả thuyết H [có độ phức tạp không quá lớn]
- Khả thi: 𝑐∗ ∈ 𝐻.
- Bất khả tri: 𝑐∗ “gần với” H.
Các mô hình PAC/SLT cho Học có giám sát
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- Thực hiện tối ưu trên S, tìm giả thiết ℎ ∈ 𝐻.
- Mục tiêu: h có sai số nhỏ trên D.
- Lỗi thực tế: errD (h) = Prx~ D (h(x) ≠ c∗(x))
- Tần suất ℎ(𝑥) ≠ 𝑐∗(𝑥) đối với các trường hợp trong tương lai được rút ngẫu nhiên từ D
- Lỗi thực tế: errD (h) = Prx~ D (h(x) ≠ c∗(x))
- Nhưng, chỉ có thể đo lường:
- Lỗi huấn luyện: errS (h) = 1⁄m ∑i I(h(xi) ≠ c∗(xi))
- Tần suất ℎ(𝑥) ≠ 𝑐∗(𝑥) đối với các trường hợp huấn luyện
- Lỗi huấn luyện: errS (h) = 1⁄m ∑i I(h(xi) ≠ c∗(xi))
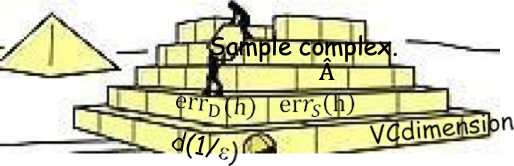
Độ phức tạp của mẫu: bị ràng buộc 𝑒𝑟𝑟𝐷 (ℎ) tính theo 𝑒𝑟𝑟𝑆 (ℎ)
Độ phức tạp của mẫu đối với học tập có giám sát
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với mẫu (nếu một mẫu tồn tại).

Chỉ có giới hạn logarit trong |H|, tuyến tính trong 1/𝜖
Xác suất đối với các mẫu khác nhau của m mẫu huấn luyện
Vậy nếu c∗ ∈ H và tìm được fns nhất quán thì chỉ cần ngần này mẫu là có được sai số tổng quát hóa ≤ 𝜖 với xác suất ≥ 1 − 𝛿
Độ phức tạp của mẫu đối với học có giám sát
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với mẫu (nếu tồn tại).
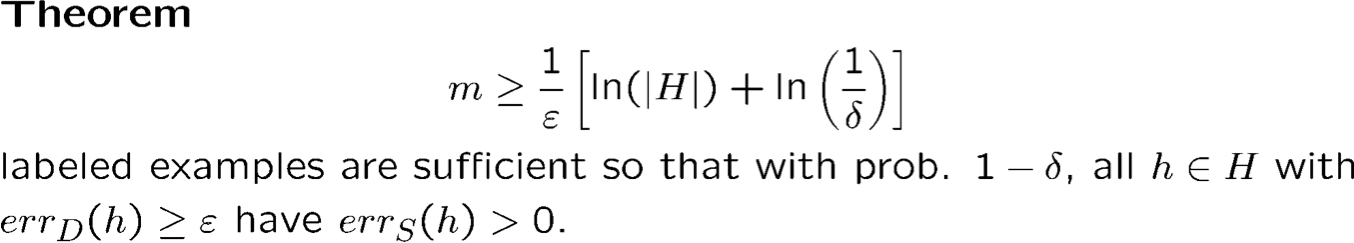
Ví dụ:
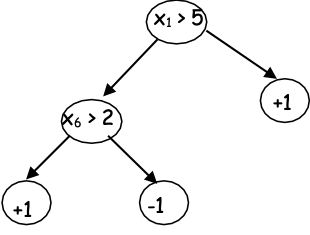
H là lớp liên từ trên X = {0,1}n. |H| = 3n
Ví dụ: h = x1 x3x5 hoặc h = x1 x2x4𝑥9
Khi đó 𝑚 ≥ 1⁄𝜖[𝑛 ln 3 + ln(1⁄𝛿)] đủ
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp có thể thực hiện được
1) PAC: Có bao nhiêu mẫu đủ để đảm bảo lỗi nhỏ whp.
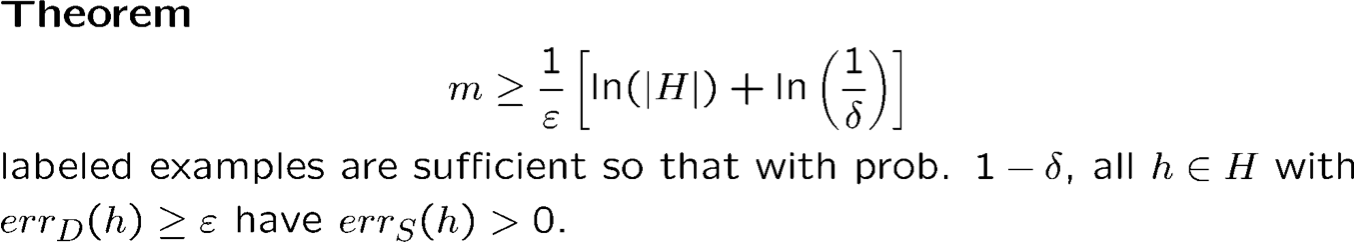
2) Cách học thống kê:
Với xác suất ít nhất là 1 − 𝛿, với mọi h ∈ H s.t. errS (h) = 0, chúng ta có
errD (h) ≤ 1⁄m (ln |H| + ln(1⁄𝛿)).
Học có giám sát: Mô hình PAC (Valiant)
- X – không gian thể hiện, ví dụ: X = {0,1}n hoặc X = Rn
- Sl={(xi, yi)} – các mẫu có nhãn được rút ra i.i.d. từ một số distr. D trên X và được gắn nhãn bởi một số khái niệm đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán A PAC-học lớp khái niệm H nếu đối với bất kỳ c* đích nào trong H, bất kỳ phân phối nào. D trên X, bất kỳ ε, 𝛿 > 0:
- A sử dụng nhiều nhất poly(n,1/ε,1/𝛿,size(c*)) mẫu và thời gian chạy.
- Với xác suất ≥ 1 − 𝛿, A tạo ra h trong H chứa lỗi ở mức ≤ ε.
 Nếu H là vô hạn thì sao?
Nếu H là vô hạn thì sao?
Ví dụ: dấu phân cách tuyến tính trong Rd

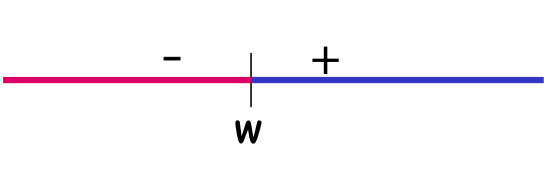
Ví dụ: ngưỡng trên đường thực
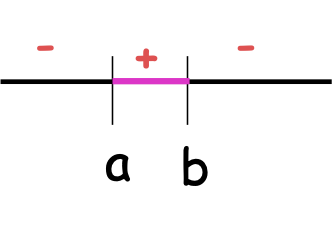
Ví dụ: các khoảng trên đường thẳng
Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
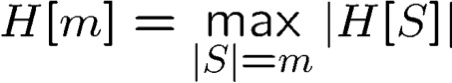
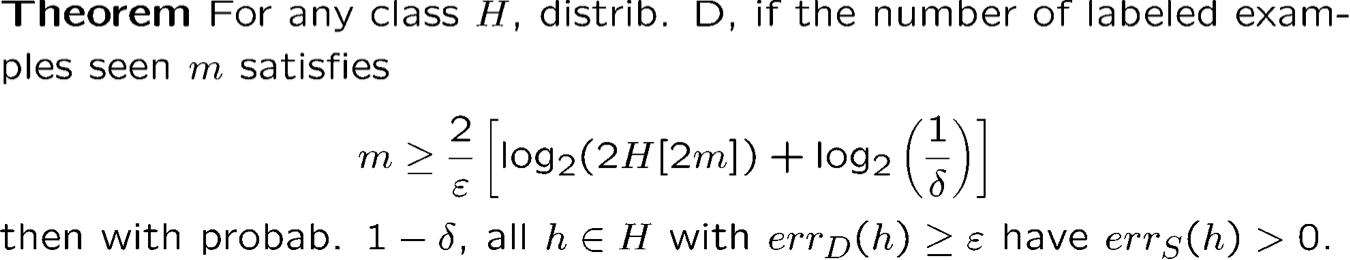
Bổ đề Sauer: H[m] = O (mVCdim (H))

Số giả thuyết hiệu quả
- H[S] – tập hợp các phép chia của tập dữ liệu S sử dụng các khái niệm từ H.
- H[m] – số cách tối đa để tách m điểm sử dụng các khái niệm trong H
H[m] = max|S| =m |H[S]|
Số giả thuyết hiệu quả
- H[S] – tập hợp các cách chia của tập dữ liệu S sử dụng các khái niệm từ H.
- H[m] – số cách tối đa để chia m điểm sử dụng các khái niệm trong H
H[m] = max|S| =m |H[S]| H[m] ≤ 2m
Ví dụ: H= Ngưỡng trên đường thực
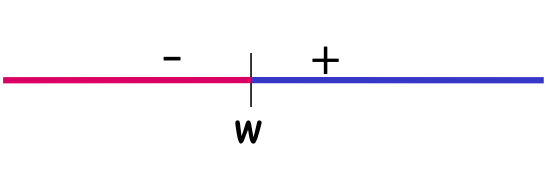
|H[S]| = 5
Nói chung, nếu |S|=m (đều khác nhau), |H[S]| = m + 1 ≪ 2m
Số lượng giả thuyết hiệu quả
- H[S] – tập hợp các phép tách của tập dữ liệu S sử dụng các khái niệm từ H.
- H[m] – số cách tối đa để tách m điểm sử dụng các khái niệm trong H
H[m] = max|S| =m |H[S]| H[m] ≤ 2m
E.g. , H= Khoảng cách trên đường thực
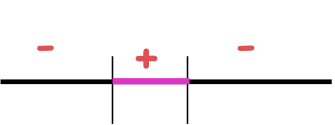
Nói chung, |S|=m (đều khác biệt), H[m] = m(m+1)⁄2 + 1 = O(m2) ≪ 2m
Có m+1 cách chọn cho phần đầu tiên, m còn lại cho phần thứ hai , thứ tự không quan trọng, vì vậy (m chọn 2) + 1 (cho khoảng trống).
Số lượng giả thuyết hiệu quả
- H[S] – tập hợp các phép tách của tập dữ liệu S sử dụng các khái niệm từ H.
- H[m] – số cách tối đa để tách m điểm sử dụng các khái niệm trong H
H[m] = max|S| =m |H[S]| H[m] ≤ 2m
Định nghĩa: H phân tách S Nếu |H[S]| = 2|𝑆|.
Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
- H[m] – số cách tối đa để chia m điểm bằng cách sử dụng các khái niệm trong H
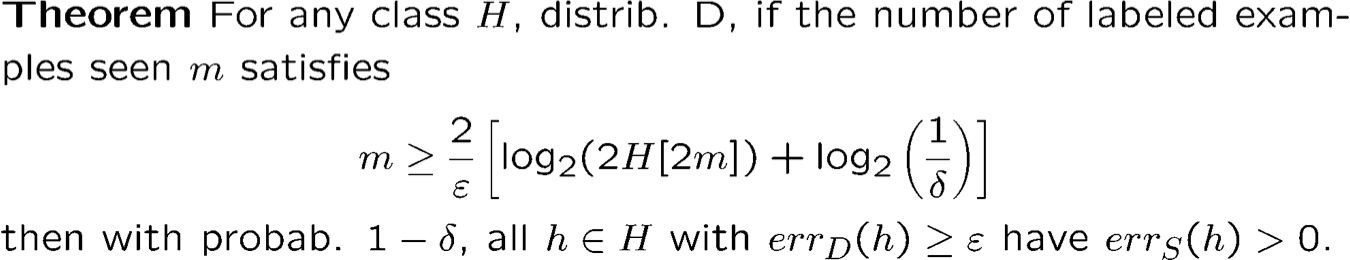
Ý tưởng rất rất thô:
S= {x1, x2, … , xm} i.i.d. từ D
B: ∃ h ∈ H với errS (h) = 0 nhưng errD (h) ≥ ϵ.
S’ ={x1′ , … , x𝑚′ } i.i.d. “mẫu ma” khác từ D
B’: ∃ h ∈ H với errS (h) = 0 nhưng errS′ (h) ≥ ϵ.
Khẳng định : Để ràng buộc P(B), đủ để ràng buộc P(B’)
Trên S ∪ S′ chỉ còn H[2m] giả thuyết hiệu quả… nhưng, không còn tính ngẫu nhiên.
Cần tính ngẫu nhiên để giới hạn xác suất của một sự kiện xấu, một thủ thuật đối xứng khác….
Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
Trường hợp có thể thực hiện được
H[m] – số cách tối đa để tách m điểm sử dụng các khái niệm trong H
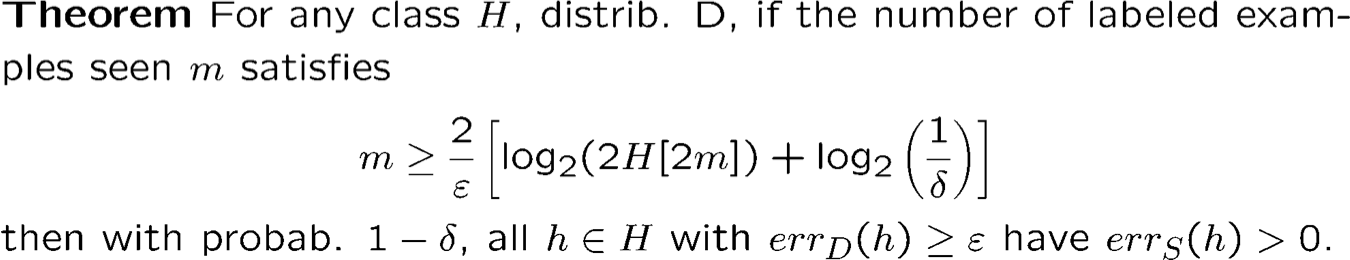
- Không quá dễ để diễn giải đôi khi khó tính toán chính xác, nhưng có thể đạt được giới hạn tốt khi sử dụng “thứ nguyên VC
- Nếu H[m] = 2m thì m ≥ m⁄ϵ (… . ) ☹
- Thứ nguyên VC đại khái là điểm mà H dừng lại , giống như nó chứa tất cả các hàm, vì vậy hy vọng sẽ giải được m.
Độ phức tạp mẫu: Không gian giả thuyết vô hạn
H[m] – số cách tối đa để chia m điểm bằng cách sử dụng các khái niệm trong H
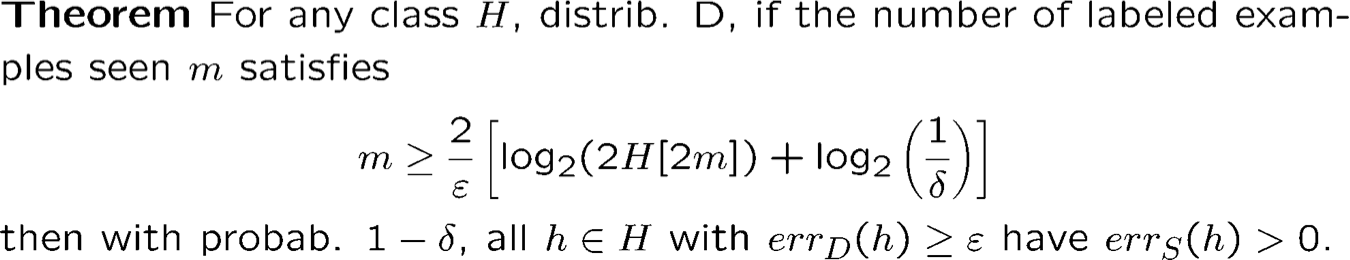
Bổ đề Sauer: H[m] = O (mVCdim (H))

Phá vỡ, chiều VC
Định nghĩa: H phá vỡ S nếu |H[S]| = 2|𝑆|.
Một tập hợp các điểm S bị chia cắt bởi H liệu có các giả thuyết trong H chia S thành tất cả 2|𝑆| cách có thể, tất cả các cách có thể phân loại các điểm trong S có thể đạt được bằng cách sử dụng các khái niệm trong H.
Định nghĩa: Thứ nguyên-VC (thứ nguyên Vapnik-Chervonenkis)
Chiều VC của không gian giả thuyết H là lực lượng của tập S lớn nhất có thể bị phá vỡ bởi H.
Nếu các tập hợp hữu hạn lớn tùy ý có thể bị phá vỡ bởi H, thì VCdim(H) = ∞
Phá vỡ, chiều VC
Định nghĩa: Thứ nguyên-VC (thứ nguyên Vapnik-Chervonenkis)
Chiều VC của không gian giả thuyết H là lực lượng của tập S lớn nhất có thể bị phá vỡ bởi H.
Nếu các tập hữu hạn lớn tùy ý có thể bị phá vỡ bởi H, thì VCdim(H) = ∞
Để chỉ ra rằng thứ nguyên VC là d:
- tồn tại tập d điểm có thể phá vỡ
- không có tập hợp d+1 điểm nào có thể bị phá vỡ.
Thực tế: Nếu H hữu hạn thì VCdim(H) ≤ log (|H|).
Phá vỡ, chiều VC
Nếu chiều VC là d, điều đó có nghĩa là tồn tại một tập hợp các điểm d có thể bị phá vỡ, nhưng không có tập hợp d+1 điểm nào có thể bị phá vỡ.
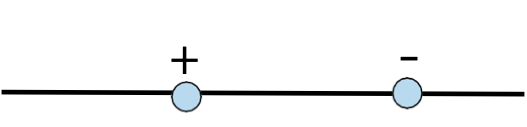
Ví dụ: H= Ngưỡng trên đường thực
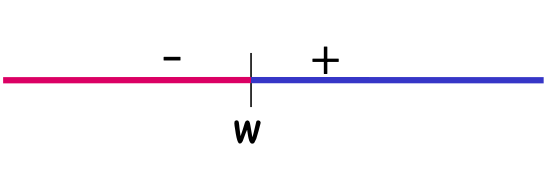
VCdim (H) = 1
Ví dụ: H= Khoảng cách trên đường thực
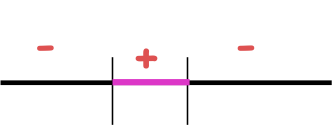
VCdim (H) = 2

Phá vỡ, chiều VC
Nếu chiều VC là d, điều đó có nghĩa là tồn tại một tập hợp các điểm d có thể bị phá vỡ, nhưng không có tập hợp d+1 điểm nào có thể bị phá vỡ.
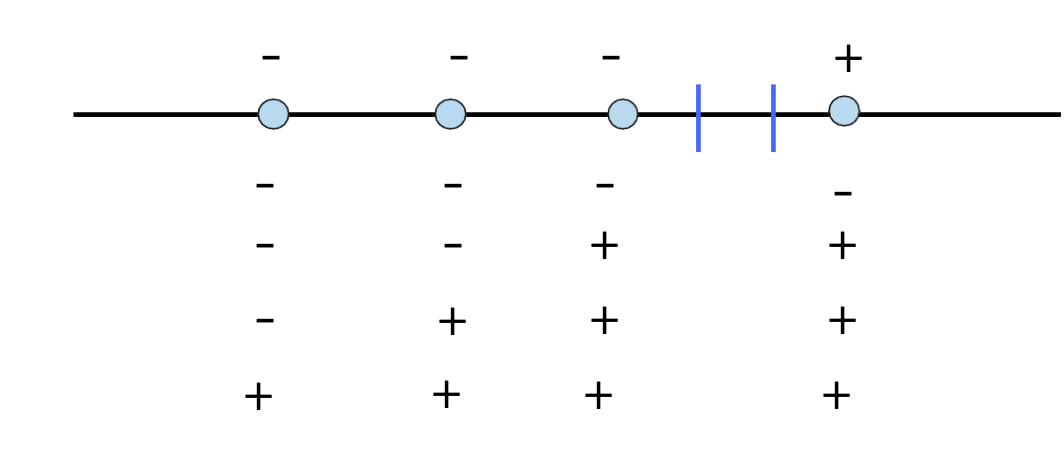
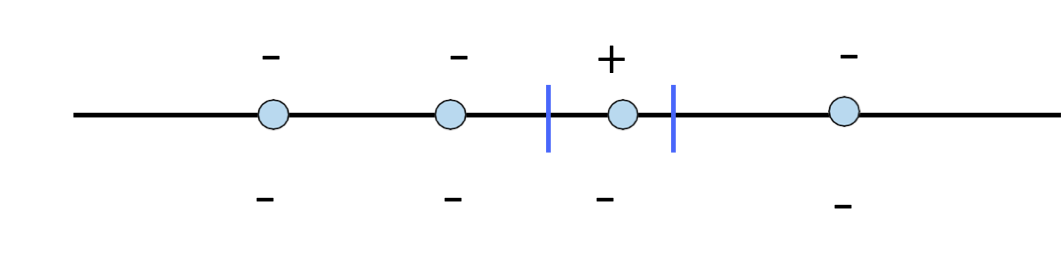
Ví dụ: H= Hợp của k khoảng trên đường thẳng thực
VCdim (H) = 2k

VCdim (H) ≥ 2k
Một mẫu có kích thước 2k bị phá vỡ (coi mỗi cặp điểm là một trường hợp riêng biệt của các khoảng)
VCdim (H) < 2k + 1

Phá vỡ, Chiều VC
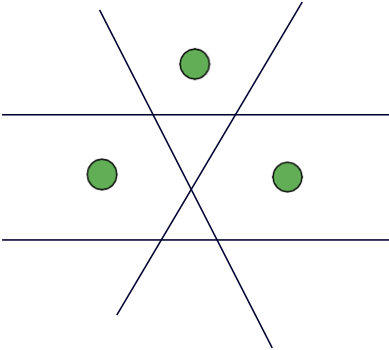
Ví dụ: H= dấu phân cách tuyến tính trong R2
VCdim (H) ≥ 3
Phá vỡ, Chiều VC
Ví dụ, H= các đường phân cách tuyến tính trong R2
VCdim (H) < 4
Trường hợp 1: một điểm bên trong tam giác được tạo bởi các điểm khác. Không thể gắn nhãn điểm bên trong là điểm dương và điểm bên ngoài là điểm âm.
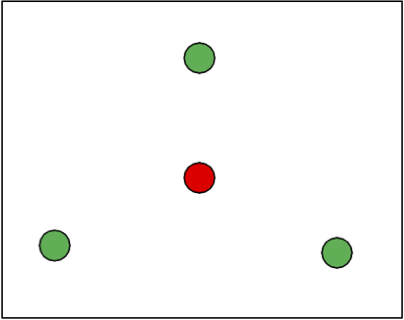
Trường hợp 2: tất cả các điểm trên biên (vỏ lồi). Không thể dán nhãn hai đường chéo là dương và hai đường chéo khác là âm.
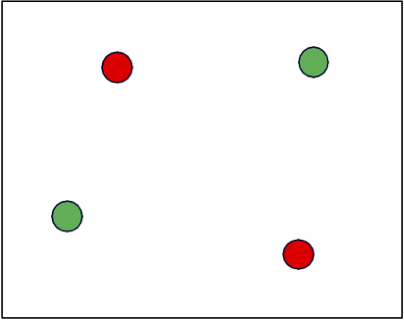
Thực tế: VCdim của các đường phân cách tuyến tính trong Rd là d+1
Bổ đề Sauer
Sauer’s Lemma:
Đặt d = VCdim(H)
- m ≤ d, khi đó H[m] = 2m
- m>d, khi đó H[m] = O (m𝑑)
Chứng minh: quy nạp trên m và d. Lập luận tổ hợp tuyệt vời!
Gợi ý: hãy thử chứng minh nó trong các khoảng…
Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
Trường hợp có thể thực hiện được
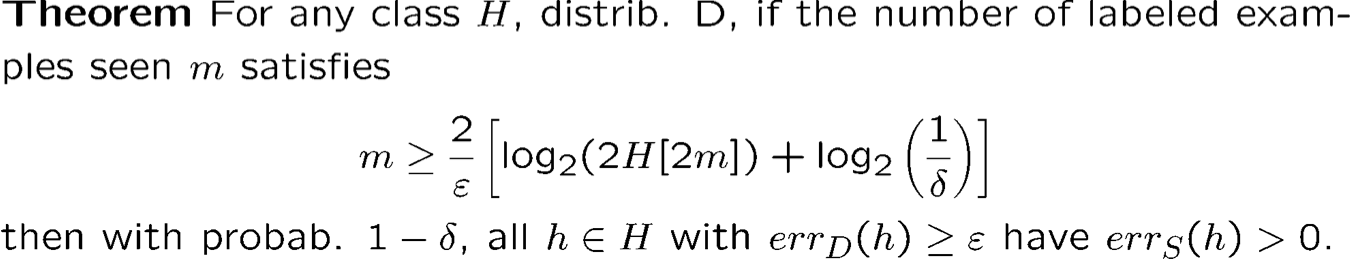
Bổ đề Sauer: H[m] = O (mVCdim (H))

Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
Trường hợp có thể thực hiện được

Ví dụ: H= dấu phân cách tuyến tính trong Rd
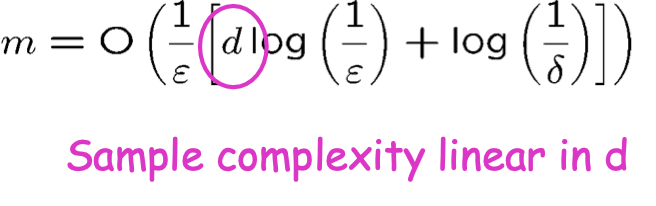
Độ phức tạp của mẫu tuyến tính theo d
Vì vậy, nếu nhân đôi số lượng tính năng, thì tôi chỉ cần gấp đôi số lượng mẫu để hoạt động tốt.
Giới hạn gần khớp

Định lý (cận dưới):
Với bất kỳ 𝐻, bất kỳ thuật toán 𝐴, bất kỳ 0 < 𝜖 < 1/8, bất kỳ 𝛿 < .01, ∃ distr. 𝐷 và mục tiêu 𝑐∗ ∈ 𝐻 s.t. nếu 𝐴 thấy ít hơn max [1⁄𝜖log(1⁄𝛿) , 𝑉𝐶𝑑𝑖𝑚(𝐻) −1⁄32𝜖] mẫu, khi đó với xác suất ≥ 𝛿, 𝐴 tạo ra ℎ với 𝑒𝑟𝑟𝐷 (ℎ) > 𝜖.
Lower Bound (dạng đơn giản hơn)
- Định lý: Với bất kỳ 𝐻 nào cũng tồn tại 𝐷 sao cho bất kỳ thuật toán nào cũng cần Ω (𝑉𝐶𝑑𝑖𝑚(𝐻)⁄𝜖) mẫu đạt sai số 𝜖 với prob ≥ 3⁄4.
- Chứng minh: xét 𝑑 = 𝑉𝐶𝑑𝑖𝑚(𝐻) điểm phá vỡ:
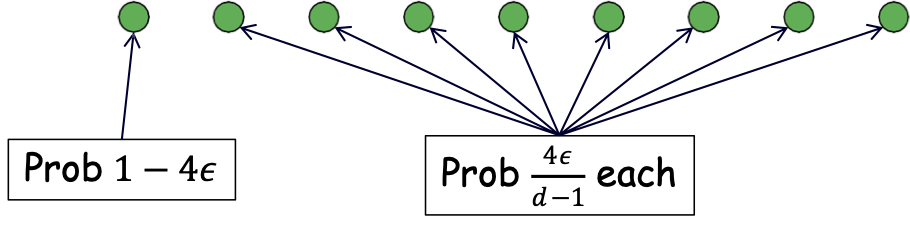
- Xét mục tiêu 𝑐∗ đánh dấu ngẫu nhiên các điểm này.
- Trừ khi tôi thấy khoảng ½ số điểm hiếm, có sai số ≥ 𝜖
- Mỗi mẫu chỉ có xác suất 4𝜖 là một trong các điểm hiếm và cần xem 𝑑−1⁄2 điểm hiếm nên cần xem Ω (𝑑⁄𝜖) toàn bộ.
Nếu c∗ ∉ H thì sao?

Hội tụ đồng nhất
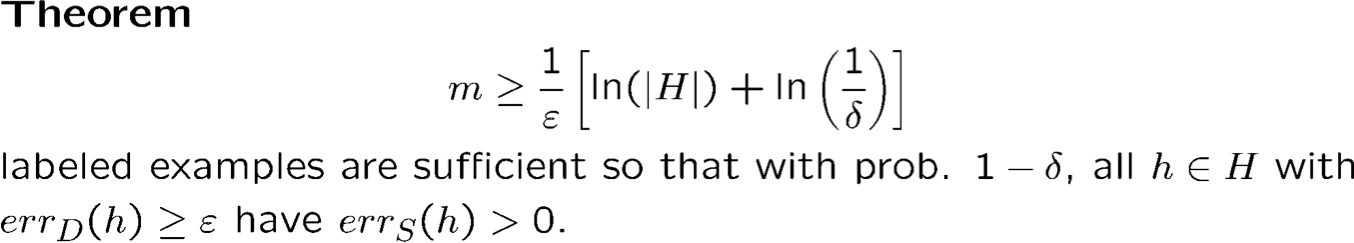
- Kết quả cơ bản này chỉ giới hạn khả năng một giả thuyết tồi có vẻ hoàn hảo trên dữ liệu. Nếu không có h∈H hoàn hảo (trường hợp bất khả tri) thì sao?
- Chúng ta có thể nói gì nếu c∗ ∉ H?
- Chúng ta có thể nói rằng whp tất cả h∈H thỏa mãn |errD(h) – errS(h)| ≤ ε?
- Gọi là “sự hội tụ đều”.
- Thúc đẩy tối ưu hóa trên S, ngay cả khi chúng ta không thể tìm thấy một hàm số hoàn hảo.
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp có thể thực hiện được
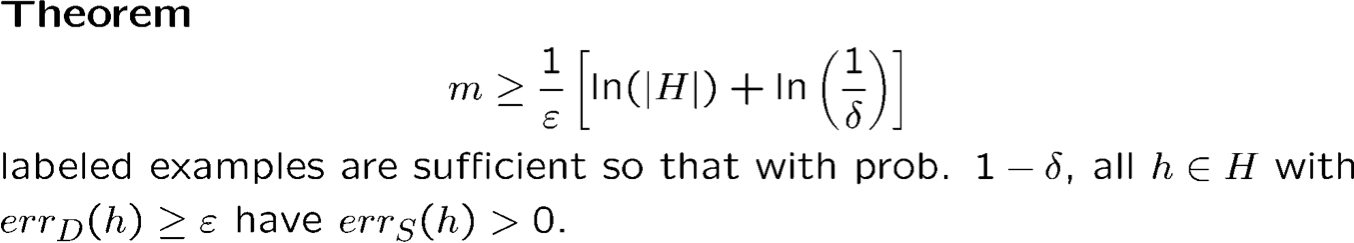
Trường hợp bất khả tri
Nếu không có h hoàn hảo thì sao?
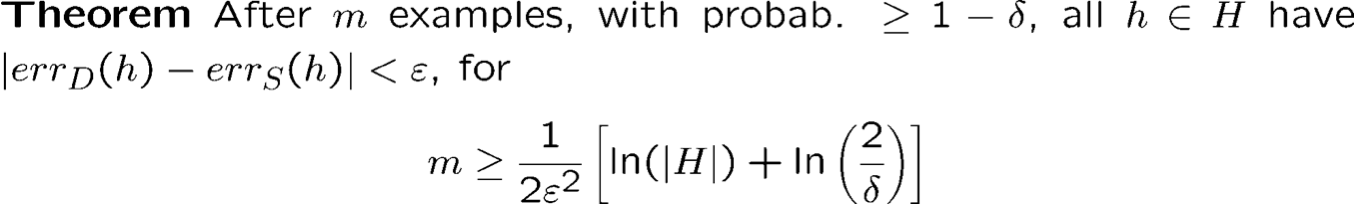
Để chứng minh các giới hạn như thế này, cần một số bất đẳng thức đuôi tốt.
Giới hạn Hoeffding
Xem xét đồng xu thiên vị p lật m lần.
Gọi N là # mặt ngửa được quan sát. Cho ε∈ [0,1].
Giới hạn Hoeffding:
- Pr[N/m > p + ε] ≤ e-2mε2, và
- Pr[N/m < p – ε] ≤ e-2mε2.
Hàm mũ giảm dần
- Bất đẳng thức đuôi: khối lượng xác suất bị ràng buộc ở đuôi phân phối (mức độ tập trung của một biến ngẫu nhiên xung quanh kỳ vọng của nó).
Độ phức tạp của mẫu: Giả thuyết hữu hạn Không gian
Trường hợp bất khả tri
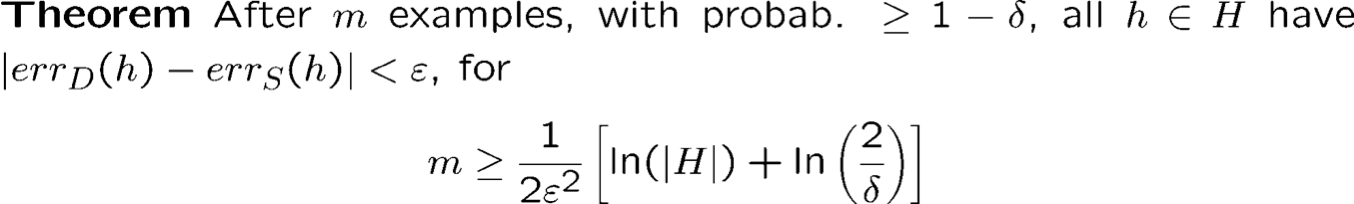
- Bằng chứng: Chỉ cần áp dụng Hoeffding.
- Cơ hội thất bại nhiều nhất là 2|H|e-2|S|ε2.
- Đặt thành 𝛿. Giải quyết.
- Vì vậy, whp, tốt nhất trên mẫu là ε-tốt nhất so với D.
- Lưu ý: giới hạn này kém hơn giới hạn trước (1/ε đã trở thành 1/ε2), bởi vì chúng ta đang yêu cầu một thứ gì đó mạnh hơn.
- Cũng có thể có giới hạn “giữa” hai cái này.
Những điều bạn nên biết
- Khái niệm về độ phức tạp của mẫu.
- Hiểu lý do đằng sau độ phức tạp của mẫu đơn giản giới hạn cho H hữu hạn.
- Phá vỡ, chiều VC như thước đo độ phức tạp, bổ đề Sauer, dạng giới hạn VC (giới hạn trên và giới hạn dưới).