Bài đọc tham khảo
CS 5966/6966: Theory of Machine Learning (Lecture 6: Rademacher Complexity)
Understanding Machine Learning: From Theory to Algorithms (Chapter 26 + 8)
Hôm nay:
Độ phức tạp mẫu cho xấp xỉ hàm. Lựa chọn mô hình.
Hai khía cạnh cốt lõi của học máy
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
- Ví dụ: hồi quy logistic, SVM, Adaboost, v.v.
Dữ liệu (được gắn nhãn)
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc đối với dữ liệu trong tương lai.
Các mô hình PAC/SLT cho phân loại được giám sát
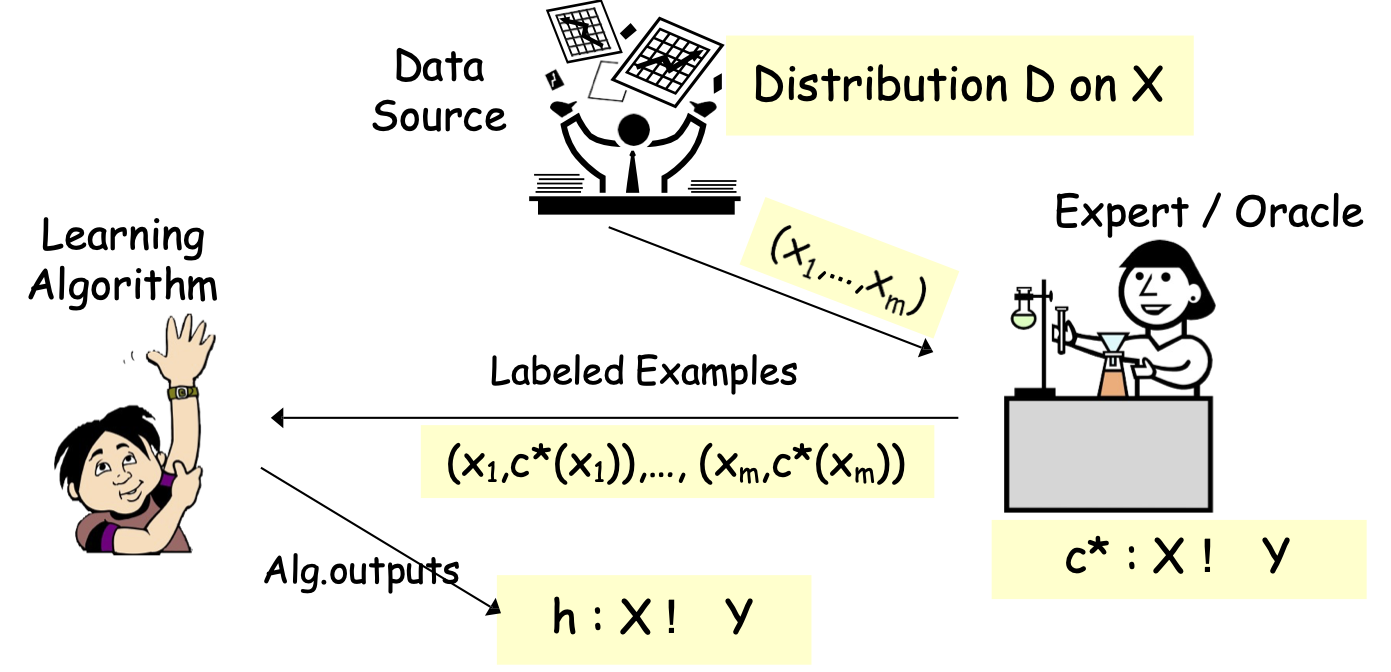
Các mô hình PAC/SLT cho Học có giám sát
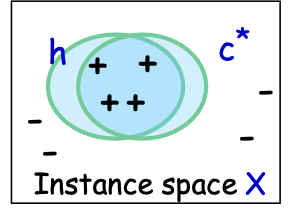
- X – không gian đối tượng/đặc trưng; phân phối D trên X
- ví dụ: X = Rd hoặc X = {0,1}d
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi i.i.d. từ D
- các mẫu được gắn nhãn – i.i.d. được rút ra từ D và được gắn nhãn bởi đích c*
- nhãn ∈ {-1,1} – phân loại nhị phân
- Thuật toán tối ưu hóa trên S, tìm giả thuyết ℎ.
- Mục tiêu: h có lỗi nhỏ trên D.
- 𝑒𝑟𝑟𝐷 (ℎ) = Pr𝑥~ 𝐷 (ℎ(𝑥) ≠ 𝑐∗(𝑥))
- Cố định không gian giả thuyết H [có độ phức tạp không quá lớn]
- Khả thi: 𝑐∗ ∈ 𝐻.
- Bất khả tri: 𝑐∗ “gần với” H.
Độ phức tạp của mẫu đối với học có giám sát
Trường hợp có thể thực hiện được
Người học nhất quán
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H phù hợp với S (nếu tồn tại).

Tuyến tính trong 1/𝜖
Xác suất trên các mẫu khác nhau của m mẫu huấn luyện
Độ phức tạp của mẫu: Không gian giả thuyết vô hạn
Trường hợp có thể thực hiện được

Ví dụ: H= dấu phân cách tuyến tính trong Rd
VCdim(H)= d+1

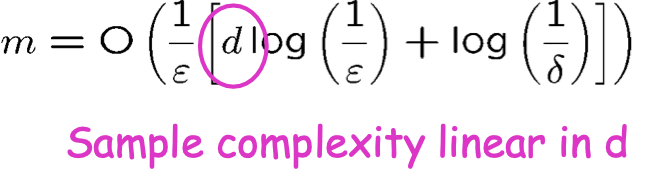
Độ phức tạp của mẫu tuyến tính theo d
Vì vậy, nếu nhân đôi số lượng tính năng, thì tôi chỉ cần gấp đôi số lượng mẫu để hoạt động tốt.
Nếu c∗ ∉ H thì sao?

Độ phức tạp của mẫu: Hội tụ đồng nhất
Trường hợp bất khả tri
Tối thiểu hóa rủi ro theo kinh nghiệm (ERM)
- Đầu vào: S: (x1,c*(x1)),…, (xm,c*(xm))
- Đầu ra: Tìm h trong H với errS(h) nhỏ nhất

1/𝜖2 phụ thuộc [ngược lại với 1/𝜖 để có thể thực hiện được]
Hoeffding bounds
Xét đồng xu thiên vị p lật m lần.
Gọi N là # mặt ngửa được quan sát. Rõ ràng E [N⁄m] = p.
[N = X1 + X2 + … + Xm, Xi = 1 với xác suất p, 0 với xác suất 1-p.]
Bất đẳng thức Hoeffding
Cho 𝛾 ∈ [0,1].
𝑃 [|𝑁⁄𝑚 − 𝑝| ≥ 𝛾] ≤ 𝑒−2𝑚𝛾2
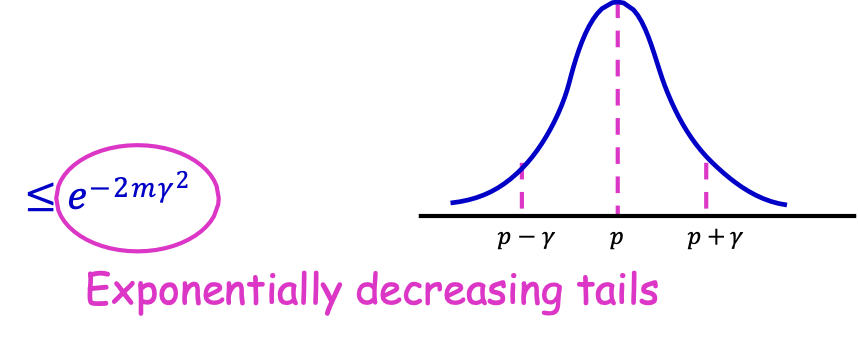
Đuôi giảm theo cấp số nhân
Bất đẳng thức đuôi: khối lượng xác suất giới hạn ở đuôi phân phối (mức độ tập trung của một biến ngẫu nhiên xung quanh kỳ vọng của nó).
Độ phức tạp của mẫu: Giả thuyết hữu hạn Không gian
Trường hợp bất khả tri
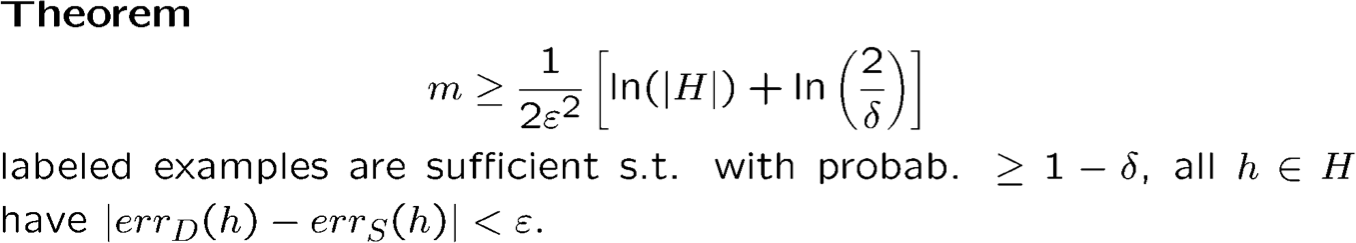
Chứng minh: Hoeffding & ràng buộc hợp.
- Cố định h; theo Hoeffding, xác suất rằng |errS (h) − errD (h)| ≥ ϵ tối đa là 2e−2mϵ2
- Bằng hợp bị chặn trên mọi ℎ ∈ 𝐻, xác suất rằng ∃h s.t. |errS (h) − errD (h)| ≥ ϵ nhiều nhất là 2|H|e−2mϵ2. Đặt thành 𝛿. Giải quyết.
Thực tế:
W.h.p. ≥ 1 − 𝛿,errD (ℎ^) ≤ errD (h∗) + 2ϵ, h^ là đầu ra ERM, h∗ là hyp. với tỷ lệ sai số thực nhỏ nhất .
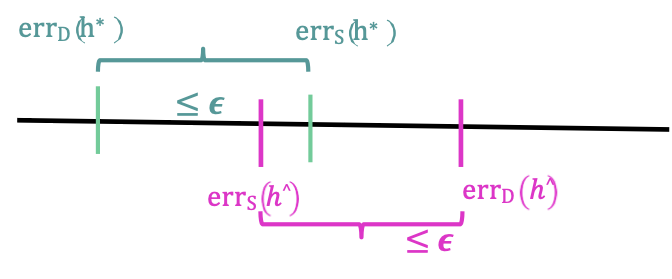
Độ phức tạp của mẫu: Không gian giả thuyết hữu hạn
Trường hợp bất khả tri
1) Có bao nhiêu mẫu đủ để có được UC whp (vì vậy thành công cho ERM).
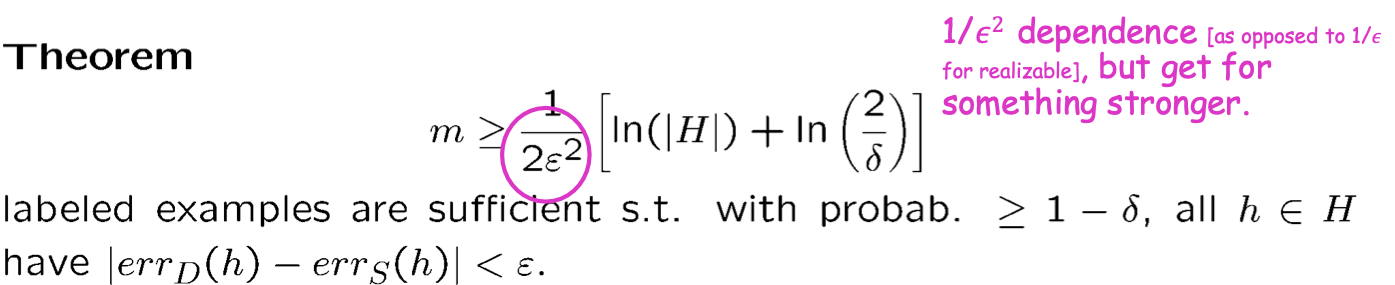
sự phụ thuộc 1/𝜖2 [ngược lại với 1/𝜖 cho khả thi], nhưng nhận được thứ gì đó mạnh hơn.
2) Phong cách Lý thuyết học thống kê:
Với xác suất ít nhất 1 − 𝛿, với mọi h ∈ H:
errD (h) ≤ errS (h) + √1⁄2m(ln(2|H|) + ln(1⁄𝛿)).
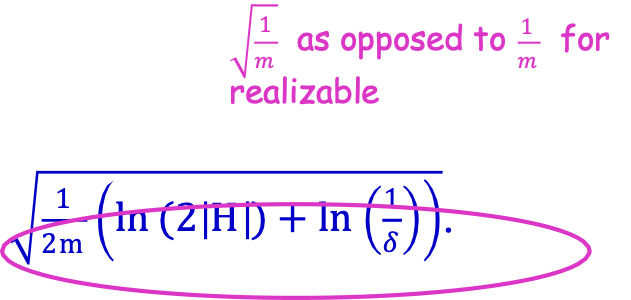
√1⁄𝑚 trái ngược với 1⁄𝑚 đối với có thể thực hiện được
Độ phức tạp mẫu: Không gian giả thuyết vô hạn
Trường hợp bất khả tri
1) Có bao nhiêu mẫu đủ để có được UC whp (vì vậy thành công cho ERM).
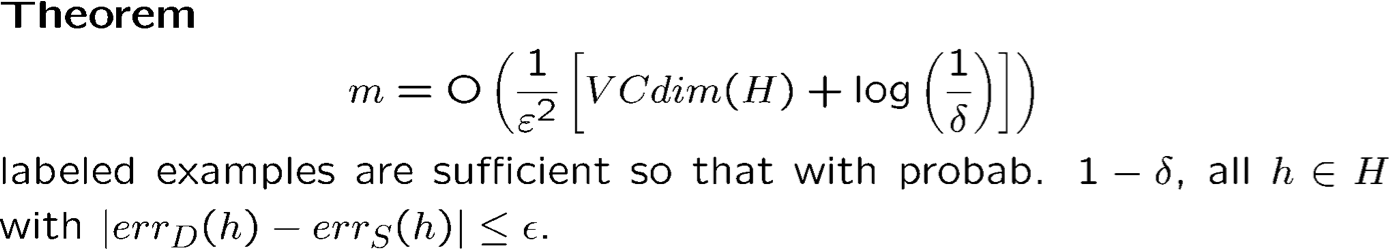
2) Phong cách Lý thuyết học thống kê:
Với xác suất ít nhất 1 − 𝛿, với mọi h ∈ H:
errD (h) ≤ errS (h) + O (√1⁄2m(VCdim(H) ln(em⁄VCdim(H)) + ln(1⁄δ))).
Giới hạn khái quát hóa chiều VC
Ví dụ, errD (h) ≤ errS (h) + O (√1⁄2m(VCdim(H) ln(em⁄VCdim(H)) + ln(1⁄δ))).
Giới hạn VC: giới hạn độc lập phân phối

- Generic: giữ cho bất kỳ lớp khái niệm và bất kỳ phân phối. [gần như chặt chẽ trong WC so với lựa chọn D]

- Có thể phân phối cụ thể rất lỏng lẻo. lành tính hơn trường hợp xấu nhất… .
- Giữ chỉ để phân loại nhị phân; chúng ta muốn giới hạn cho xấp xỉ fns nói chung (ví dụ: phân loại và hồi quy đa lớp).
Giới hạn độ phức tạp Rademacher
[Koltchinskii & Panchenko 2002]
- Phụ thuộc vào phân phối/dữ liệu. Chặt chẽ hơn cho các bản phân phối đẹp.
- Áp dụng cho các lớp chung của các hàm có giá trị thực & có thể được sử dụng để khôi phục VCbounds cho phân loại được giám sát.
- Kỹ thuật nổi bật về giới hạn tổng quát hóa trong thập kỷ qua.
Xem “Giới thiệu về lý thuyết học thống kê”
O. Bousquet, S. Boucheron và G. Lugosi.
Độ phức tạp Rademacher
Thiết lập vấn đề
- Một không gian Z và một distr. D|Z
- F là một lớp các hàm từ Z đến [0,1]
- S = {z1, … , zm} là i.i.d. từ D|Z
Muốn có xác suất cao. Giới hạn hội tụ đều, tất cả f ∈ F thỏa mãn:
ED [f(z)] ≤ ES [f(z)] + số hạng(độ phức tạp của F, độ đẹp của D/S)

Thước đo độ phức tạp nào?
Ví dụ, Z = X × Y, Y = {−1,1}, H = {h: X → Y} không gian hyp. (ví dụ: lin. sep)
Y rời rạc tổng quát
F = L(H) = {lh: X → Y}, trong đó lh(𝑧 = (x, y)) = 1{h(x)≠𝑦}
[Hàm mất fnc do h và mất 0/1]
Khi đó E𝑧~𝐷 [lh(z)] = errD (h) và ES [lh(z)] = errS (h).
errD [h] ≤ errS [h] + số hạng(độ phức tạp của H, độ đẹp của D/S)
Độ phức tạp Rademacher
Không gian Z và một distr. D|Z; F là một lớp các hàm từ Z đến [0,1]
Cho S = {z1, … , zm} là i.i.d từ D|Z.
Độ phức tạp Rademacher theo kinh nghiệm của F là:
R^m(F) = Eσ1,…,σm [supf∈F 1⁄m∑iσif(zi)]
trong đó 𝜎𝑖 là i.i.d. biến Rademacher được chọn thống nhất từ {−1,1}.
Độ phức tạp Rademacher của F là: Rm (F) = ES[R^m(F)]

sup đo lường cho bất kỳ tập S và véc tơ Rademacher 𝜎 đã cho, tương quan cực đại giữa f(zi) và 𝜎𝑖 với mọi f ∈ F
Vì vậy, lấy kỳ vọng trên 𝜎 điều này đo lường khả năng của lớp F phù hợp với nhiễu ngẫu nhiên.
Độ phức tạp Rademacher
Không gian Z và một distr. D|Z; F là một lớp các hàm từ Z đến [0,1]
Cho S = {z1, … , zm} là i.i.d từ D|Z.
Độ phức tạp Rademacher theo kinh nghiệm của F là:
R^m(F) = Eσ1,…,σm [supf∈F 1⁄m∑iσif(zi)]
trong đó 𝜎𝑖 là i.i.d. các biến Rademacher được chọn thống nhất từ {−1,1}.
Độ phức tạp Rademacher của F là: Rm (F) = ES[R^m(F)]
Định lý:
Whp mọi f ∈ F thỏa mãn:

Hữu ích nếu nó phân rã theo m.
Độ phức tạp Rademacher
Không gian Z và một distr. D|Z; F là một lớp các hàm từ Z đến [0,1]
Cho S = {z1, … , zm} là i.i.d từ D|Z.
Độ phức tạp Rademacher theo kinh nghiệm của F là:
R^m(F) = Eσ1,…,σm [supf∈F 1⁄m∑iσif(zi)]
trong đó 𝜎𝑖 là i.i.d. các biến Rademacher được chọn thống nhất từ {−1,1}.
Độ phức tạp Rademacher của F là: Rm (F) = ES[R^m(F)]
Ví dụ:
1) F={f}, thì R^m(F) = 0
[Tính tuyến tính của kỳ vọng: mỗi σif(zi) riêng lẻ có kỳ vọng 0.]
2) F={all 0/1 fnc}, thì R^m(F) = 1/2
[Để cực đại hóa tập hợp f(zi) = 1 khi σi = 1 và f(zi) = 0 khi σi = −1. Khi đó đại lượng bên trong kỳ vọng là #1′𝑠 ∈ 𝜎, là m/2 theo độ tuyến tính của kỳ vọng.]
Độ phức tạp Rademacher
Không gian Z và một distr. D|Z; F là một lớp các hàm từ Z đến [0,1]
Cho S = {z1, … , zm} là i.i.d từ D|Z.
Độ phức tạp Rademacher thực nghiệm của F là:
R^m(F) = Eσ1,…,σm [supf∈F 1⁄m∑iσif(zi)]
trong đó 𝜎𝑖 là i.i.d. biến Rademacher được chọn thống nhất từ {−1,1}.
Độ phức tạp Rademacher của F là: Rm (F) = ES[R^m(F)]
Ví dụ:
1) F={f}, thì R^m(F) = 0
2) F={all 0/1 fnc}, thì R^m(F) = 1/2
3) F=L(H), H=phân loại nhị phân thì:
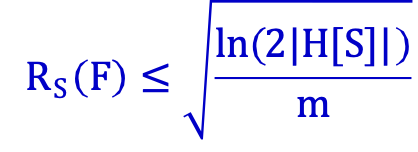
H hữu hạn:
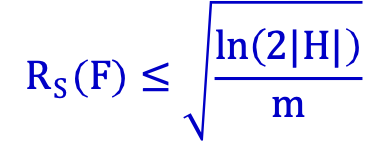
Giới hạn độ phức tạp Rademacher
Không gian Z và một distr. D|Z; F là một lớp các hàm từ Z đến [0,1]
Cho S = {z1, … , zm} là i.i.d từ D|Z.
Độ phức tạp Rademacher thực nghiệm của F là:
R^m(F) = Eσ1,…,σm [supf∈F 1⁄m∑iσif(zi)]
trong đó 𝜎𝑖 là i.i.d. biến Rademacher được chọn thống nhất từ {−1,1}.
Độ phức tạp Rademacher của F là: Rm (F) = ES[R^m(F)]
Định lý:
Whp tất cả f ∈ F thỏa mãn:

Dữ liệu phụ thuộc ràng buộc!
Kỳ vọng có giới hạn của từng f xét về giá trị trung bình theo kinh nghiệm của nó & RC của F
Proof sử dụng Thủ thuật đối xứng và lấy mẫu ma! (giống như đối với giới hạn VC)
Tổ hợp Rademacher: Phân loại nhị phân
Thực tế: H = {h: X → Y} không gian hyp. (ví dụ: lin. sep) F= L(H), d=VCdim(H):
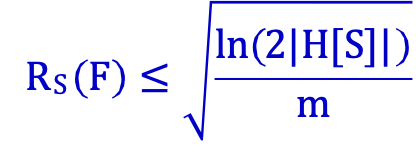 Vì vậy, theo bổ đề Sauer,
Vì vậy, theo bổ đề Sauer, 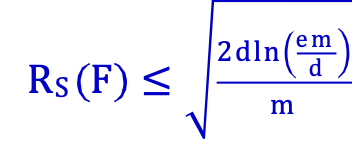
Định lý: Với mọi H, mọi distr. D, whp ≥ 1 − 𝛿 mọi h ∈ H thỏa mãn:
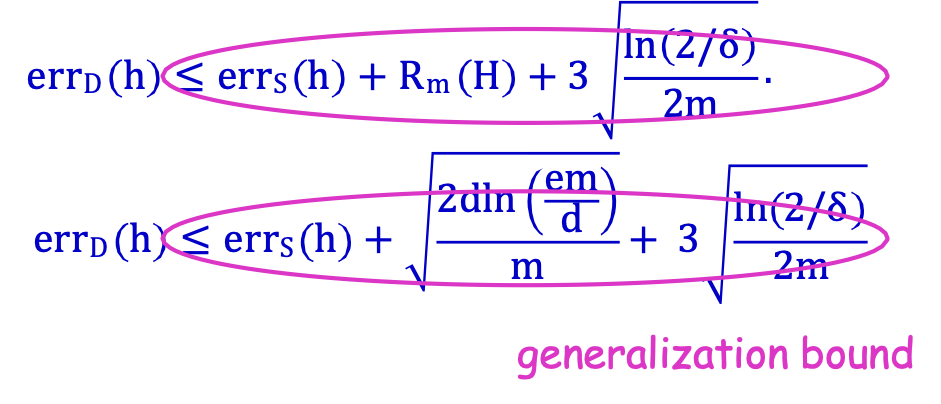
tổng quát hóa ràng buộc
Còn nhiều công dụng nữa!!! Giới hạn lề cho SVM, tăng cường, giới hạn hồi quy, v.v.
Chúng ta có thể sử dụng giới hạn của mình để lựa chọn mô hình không?

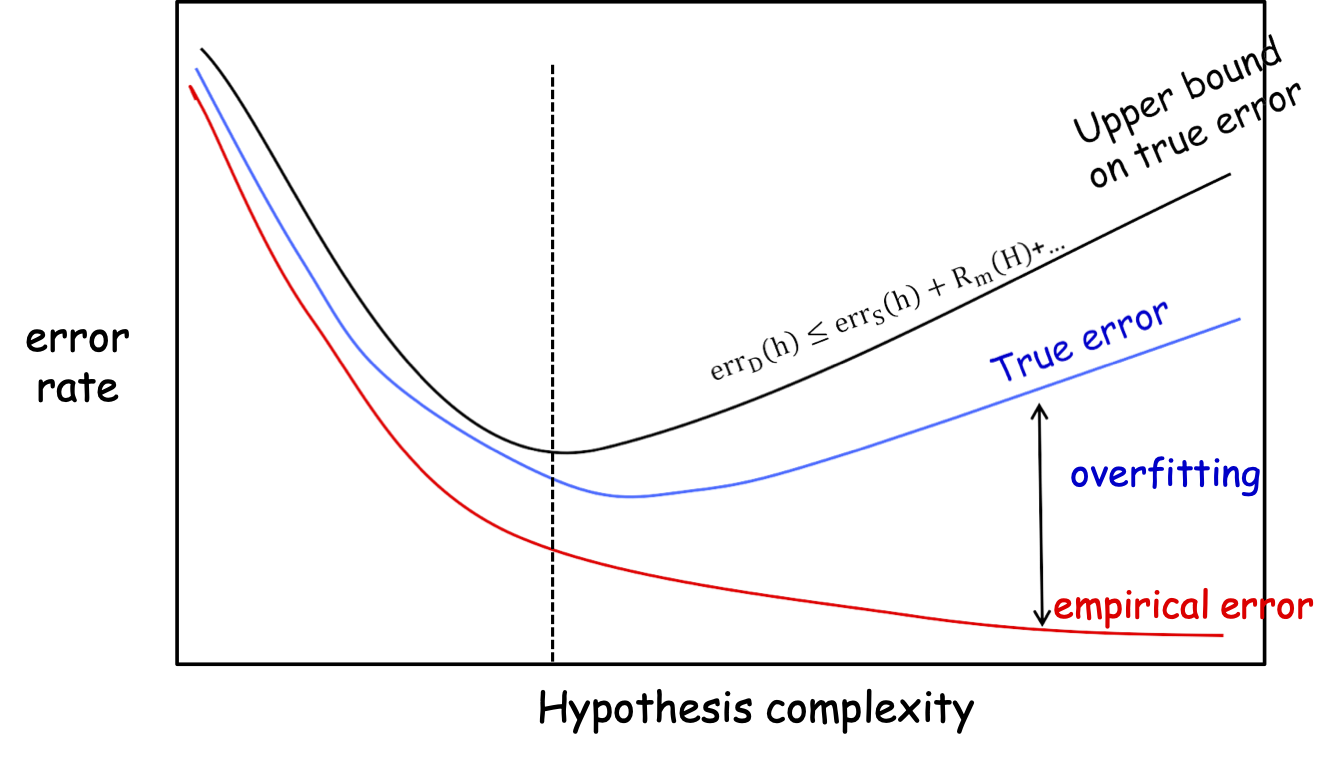
True Error, Training Error, Overfitting
Lựa chọn mô hình: cân bằng giữa việc giảm lỗi đào tạo và giữ cho H đơn giản.
errD (h) ≤ errS (h) + Rm (H) +…
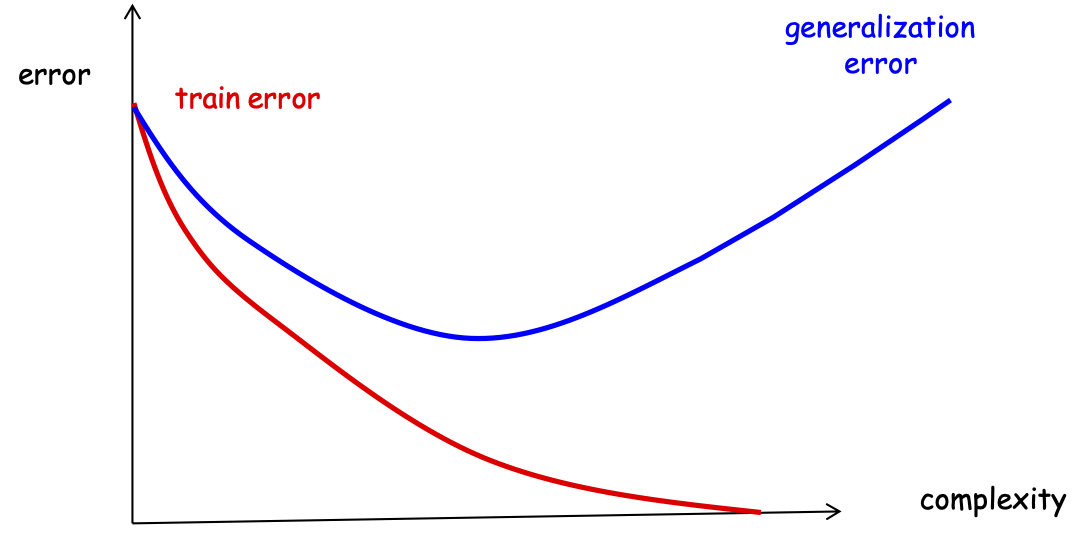
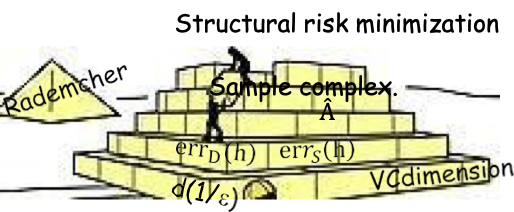
Tối thiểu hóa rủi ro cấu trúc (SRM)
𝐻1 ⊆ 𝐻2 ⊆ 𝐻3 ⊆ ⋯ ⊆ 𝐻𝑖 ⊆…
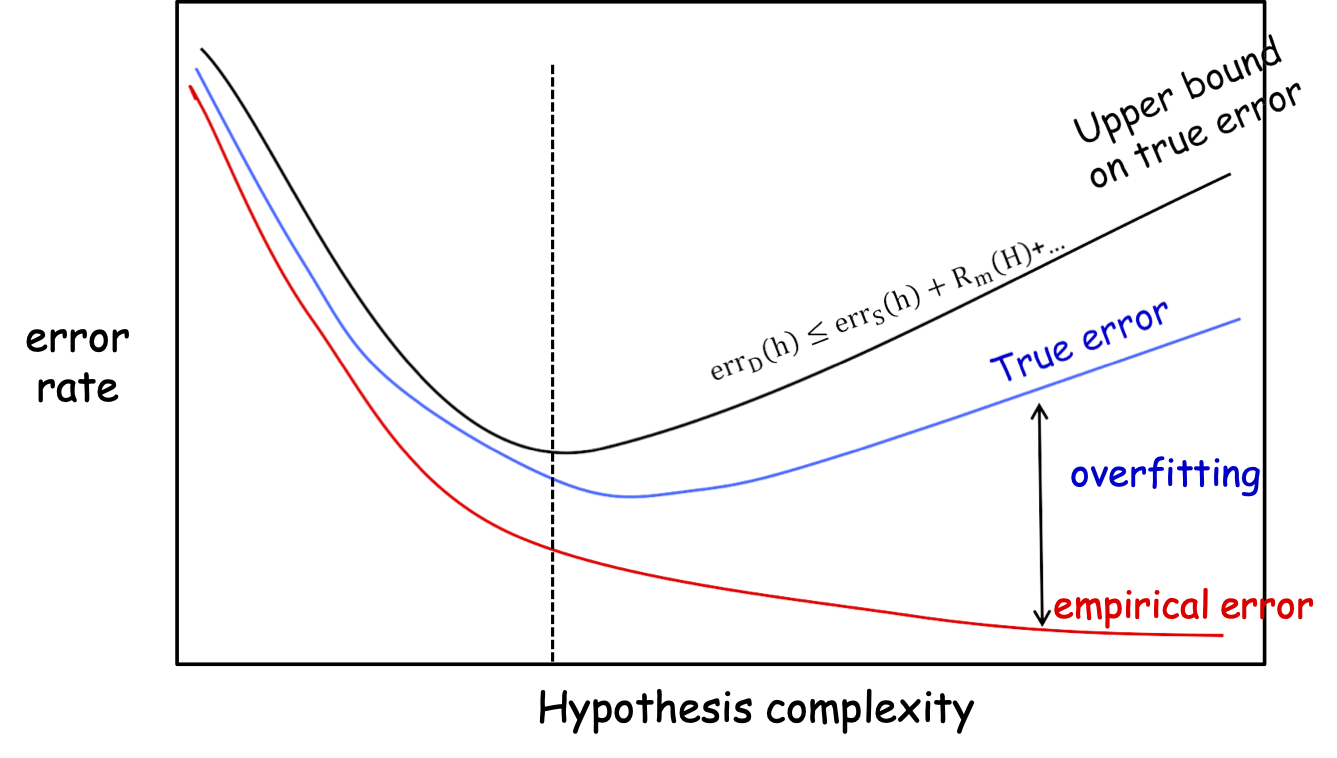
Điều gì xảy ra nếu chúng ta tăng m?
Đường cong màu đen sẽ ở gần đường cong màu đỏ lâu hơn, mọi thứ dịch chuyển sang phải…
Giảm thiểu Rủi ro Cấu trúc (SRM)
𝐻1 ⊆ 𝐻2 ⊆ 𝐻3 ⊆ ⋯ ⊆ 𝐻𝑖 ⊆…
Giảm thiểu Rủi ro Cấu trúc (SRM)
- 𝐻1 ⊆ 𝐻2 ⊆ 𝐻3 ⊆ ⋯ ⊆ 𝐻𝑖 ⊆…
- h^k = argminh∈Hk {errS(h)}
- Khi k tăng, errS (h^k) giảm nhưng số hạng phức tạp. tăng lên.
- 𝑘^ = argmink≥1{errS (h^k) + độ phức tạp(Hk)}
- Đầu ra ℎ^ = ℎ^𝑘^
Yêu cầu: W.h.p., errD (h^) ≤ mink∗minh∗∈Hk∗[errD (h∗) + 2complexity (Hk∗)]
Chứng minh:
- Chúng ta chọn h^ s.t. errs (h^) + độ phức tạp (Hk^) ≤ errS (h∗) + độ phức tạp (Hk∗).
- Whp, errD (h^) ≤ errs (h^) + độ phức tạp (Hk^).
- Whp, errS (h∗) ≤ errD (h∗) + độ phức tạp (Hk∗).
Các kỹ thuật để xử lý khớp quá mức
- Giảm thiểu rủi ro cấu trúc (SRM). 𝐻1 ⊆ 𝐻2 ⊆ ⋯ ⊆ 𝐻𝑖 ⊆…
Giảm thiểu chung chung. ràng buộc: ℎ^ = argmink≥1{errS (h^k) + complexity(Hk)}- Thường khó tính toán….
- Trường hợp tốt nếu có thể: M. Kearns, Y. Mansour, ICML’98, “A Fast, Bottom-Up Decision Tree Pruning Algorithm with Near-Optimal Generalization”
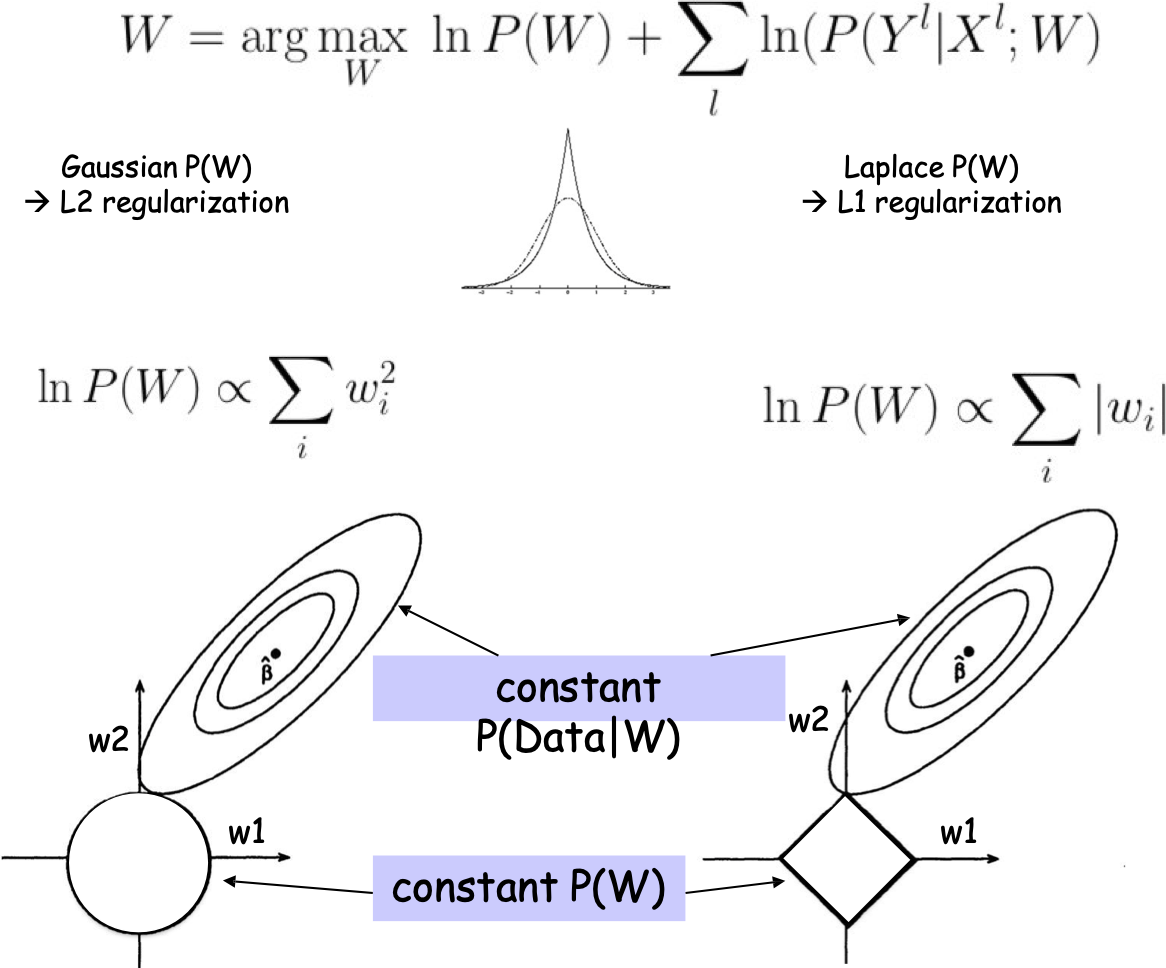
- Chính quy hóa: họ chung có liên quan chặt chẽ với SRM
- Xác thực chéo:
- Giữ lại một phần dữ liệu huấn luyện và sử dụng nó làm đại diện cho lỗi tổng quát hóa
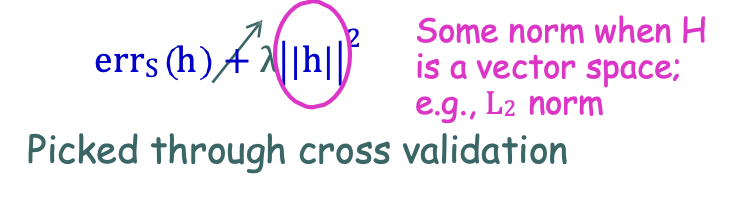
Những điều bạn nên biết
- Khái niệm về độ phức tạp của mẫu.
- Hiểu lý do đằng sau độ phức tạp của mẫu đơn giản giới hạn cho H [câu hỏi thi!].
- Sự phá vỡ, thứ nguyên VC như thước đo độ phức tạp, bổ đề Sauer, dạng giới hạn VC (giới hạn trên và giới hạn dưới).
- Độ phức tạp Rademacher.
- Lựa chọn mô hình, giảm thiểu rủi ro cấu trúc.