
VI PHÂN TỰ ĐỘNG DỰA TRÊN MÔ-ĐUN
Truyền ngược
Đào tạo
Vi phân tự động – Chế độ đảo ngược (hay còn gọi là truyền ngược)
Tính toán chuyển tiếp

Tính toán ngược (Phiên bản A)

Trả về đạo hàm riêng dy/dui cho tất cả các biến
Truyền ngược
Đào tạo
Vi phân tự động – Chế độ đảo ngược (hay còn gọi là truyền ngược)
Tính toán chuyển tiếp

Tính toán ngược (Phiên bản B)

Trả về đạo hàm riêng dy/dui cho tất cả các biến
Truyền ngược
Đào tạo
Tại sao thuật toán lan truyền ngược lại hiệu quả?
- Tái sử dụng tính toán từ lần truyền tới trong lần truyền ngược
- Tái sử dụng các đạo hàm riêng trong suốt quá trình truyền ngược (nhưng chỉ khi thuật toán sử dụng lại tính toán được chia sẻ trong bước chuyển tiếp)
(Ý tưởng chính: đạo hàm riêng trong quá trình truyền ngược nên được coi là các biến được lưu trữ để tái sử dụng)
Công thức cho Học máy
Kiến thức nền
1. Cho dữ liệu đào tạo:
2. Chọn các thành phần sau:
– Hàm quyết định
– Hàm mất mát
3. Xác định mục tiêu:
4. Đào tạo với SGD:
(đi những bước nhỏ ngược với độ dốc)

Độ dốc
Backpropagation có thể tính toán độ dốc này!
Và đây là trường hợp đặc biệt của thuật toán tổng quát hơn được gọi là phép tính vi phân tự động chế độ ngược có thể tính toán độ dốc của bất kỳ hàm khả vi nào một cách hiệu quả!
Truyền ngược: Hình ảnh trừu tượng
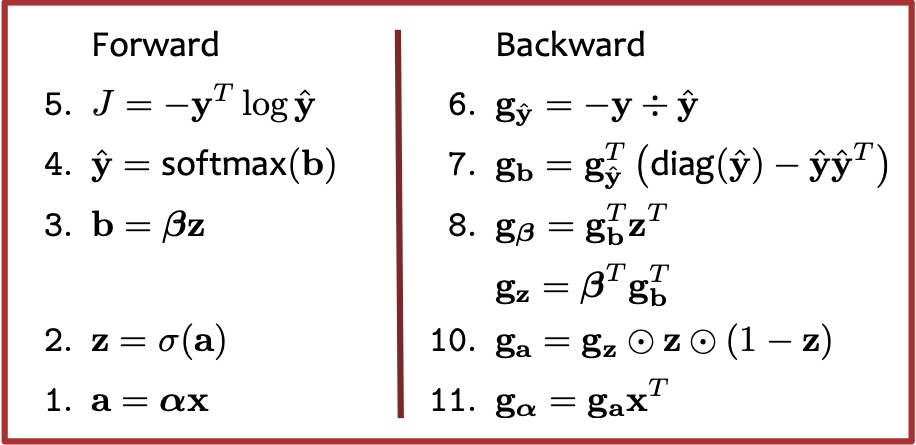
Truyền ngược: Phương pháp thủ tục


Nhược điểm của Phương pháp thủ tục
- Khó tái sử dụng / thích nghi với mô hình khác
- (Có thể) khó hơn để làm cho từng bước hiệu quả hơn
- Khó tìm ra vị trí của lỗi nếu phương pháp kiểm tra sai phân-hữu hạn báo có lỗi (vì nó chỉ cho bạn biết rằng có lỗi ở đâu đó trong 17 dòng mã đó)
AutoDiff dựa trên mô-đun
Vi phân tự động dựa trên mô-đun (AD / Autodiff) là một kỹ thuật có từ lâu đã được sử dụng để phát triển các thư viện cho việc học sâu
- Các gói mạng nơ-ron động cho phép đặc tả kỹ thuật đồ thị tính toán động khi chạy
– PyTorch http://pytorch.org
– Torch http://torch.ch
– DyNet https://dynet.readthedocs.io
– TensorFlow với Eager Execution https://www.tensorflow.org
- Các gói mạng nơ-ron tĩnh yêu cầu đặc tả kỹ thuật tĩnh của đồ thị tính toán sau đó được biên dịch thành mã
– TensorFlow với Graph Execution https://www.tensorflow.org
– Aesara (và Theano) https://aesara.readthedocs.io
– (Các thư viện này cũng dựa trên mô-đun, nhưng ở đây khi nói đến “AD dựa trên mô-đun” chúng ta muốn nói đến cách tiếp cận động)
AutoDiff dựa trên mô-đun
- Ý chính:
– phân chia thành các lớp tính toán của mạng nơ-ron
– mỗi lớp hợp nhất nhiều nút có giá trị thực trong đồ thị tính toán (một tập hợp con của chúng) thành một nút có giá trị vectơ (hay còn gọi là mô-đun)
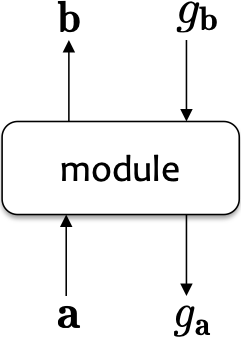
- Mỗi mô-đun có khả năng thực hiện hai hành động:
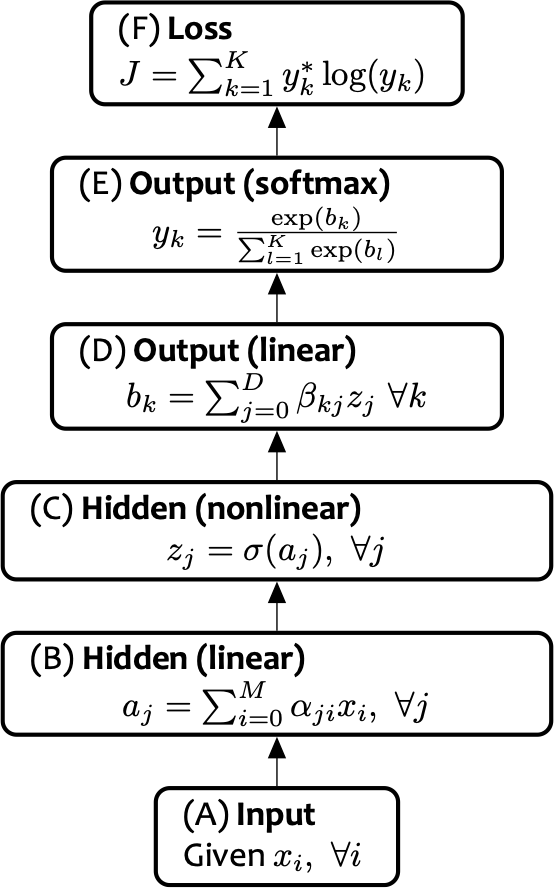
1. Tính toán chuyển tiếp đầu ra b = [b1, . . . , bB ] từ đầu vào đã cho a = [a1, . . . , aA] thông qua một hàm khả vi f . Đó là b = f(a).
2. Tính toán ngược lại độ dốc của đầu vào ga = ∇aJ = [ 𝜕𝐽/(𝜕𝑎1 ) , . . . , 𝜕𝐽/(𝜕𝑎𝐴 ) ] cho gradient của đầu ra gb = ∇bJ = [ 𝜕𝐽/(𝜕𝑏1 ) , . . . , 𝜕𝐽/(𝜕𝑏𝐵 ) ], trong đó J là giá trị thực cuối cùng đầu ra của toàn bộ đồ thị tính toán. Điều này được thực hiện thông qua quy tắc chuỗi 𝜕𝐽/𝜕𝑎i = ∑j=1J 𝜕𝐽/𝜕𝑏j 𝑑𝑏𝑗/𝑑𝑎i với mọi i ∈ {1, . . . , A}.
AutoDiff dựa trên mô-đun
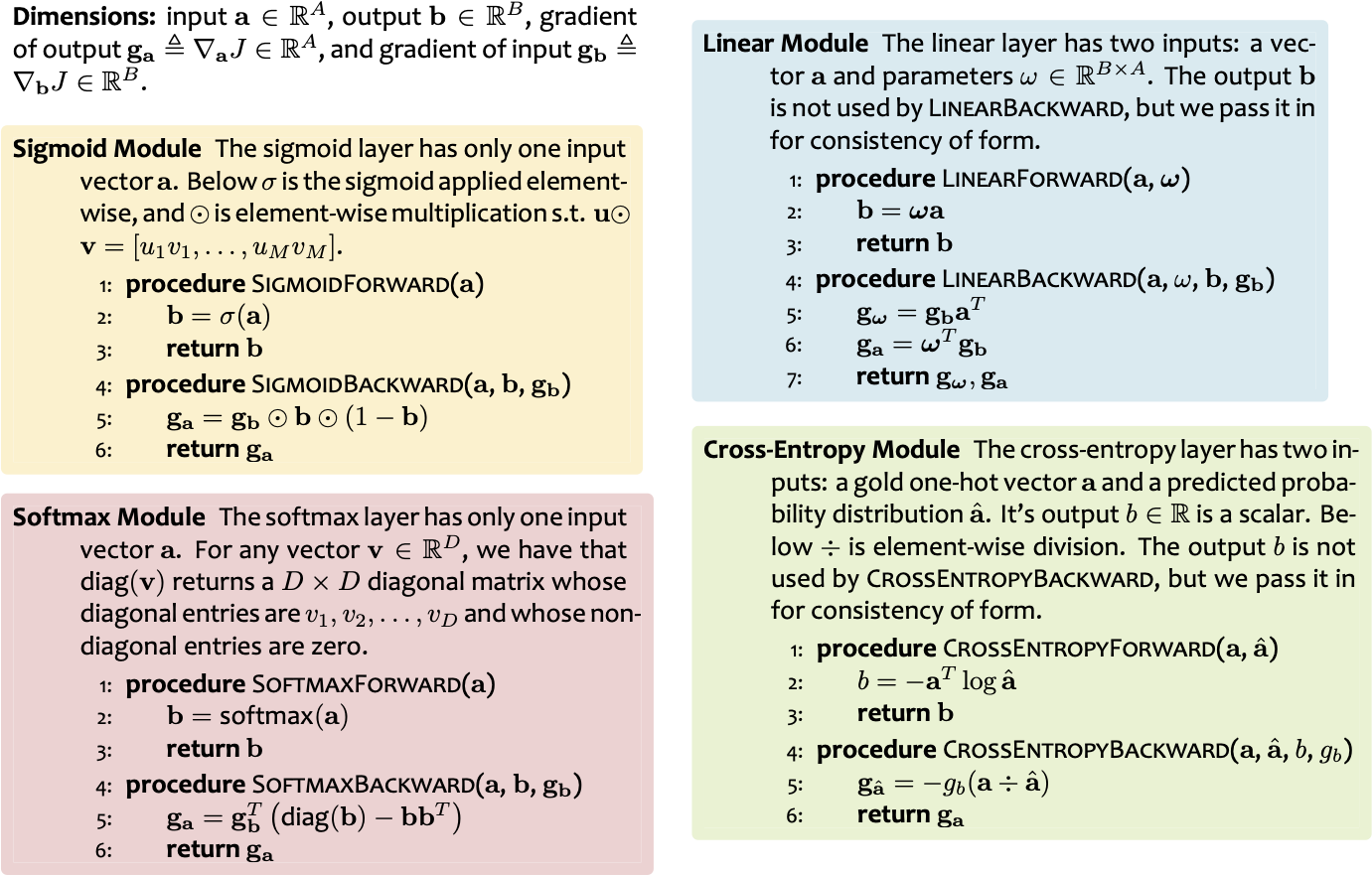
AutoDiff dựa trên mô-đun


Ưu điểm của AutoDiff Dựa trên mô-đun
- Dễ dàng tái sử dụng / thích nghi với mô hình khác
- Đóng gói các lớp dễ hơn để tối ưu hóa (ví dụ hiện thực trong C++ hoặc CUDA)
- Dễ dàng tìm thấy lỗi hơn vì chúng ta có thể chạy phương pháp kiểm tra sai phân-hữu hạn trên mỗi lớp một cách riêng biệt
AutoDiff dựa trên mô-đun (Phiên bản OOP)
Triển khai hướng đối tượng:
– Để mỗi mô-đun là một đối tượng
– Sau đó cho phép luồng điều khiển quyết định việc tạo đồ thị tính toán
– Không cần phải cài đặt NNBackward(·) nữa, chỉ cần duyệt phép tính đồ thị theo thứ tự tôpô ngược

AutoDiff dựa trên mô-đun (Phiên bản OOP)

AutoDiff dựa trên mô-đun (Phiên bản OOP)

AutoDiff dựa trên mô-đun (Phiên bản OOP)

PyTorch
Mạng nơ-ron đơn giản mà chúng ta đã định nghĩa bằng mã giả cũng có thể được định nghĩa trong PyTorch.

Ví dụ được chuyển thể từ https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
PyTorch
Q: Tại sao chúng ta không gọi linear.forward() trong PyTorch?
A: Đây chỉ là cú pháp ngọt ngào. Có một phương pháp đặc biệt trong Python __call__ cho phép bạn xác định điều gì xảy ra khi bạn xử lý một đối tượng như thể nó là một hàm.
Nói cách khác, khi chạy lệnh sau: linear(x)
tương đương với việc chạy: linear.__call__(x)
trong PyTorch (gần như) giống như chạy: linear.forward(x)
Điều này là do PyTorch định nghĩa phương thức __call__ của mọi Module để trở thành thứ gì đó như thế này:
def __call__(self):
self.forward()PyTorch
Q: Tại sao chúng ta không truyền tham số vào Module PyTorch?
A: Điều này chỉ làm cho mã của bạn gọn gàng hơn thôi.
Trong PyTorch, bạn lưu trữ các tham số bên trong Module và “đánh dấu” chúng như những tham số góp phần tạo nên độ dốc cuối cùng được sử dụng bởi một trình tối ưu hóa

MÔ HÌNH NGÔN NGỮ LỚN
ChatGPT là gì?
- ChatGPT là một mô hình ngôn ngữ lớn (theo nghĩa là có nhiều tham số), được tinh chỉnh để trở thành một tác nhân đối thoại
- Mô hình ngôn ngữ cơ sở là GPT-3.5 được đào tạo trên số lượng lớn văn bản
NHIỆM VỤ: MÔ HÌNH NGÔN NGỮ
Mô hình ngôn ngữ n-Gram
Câu hỏi: Làm thế nào chúng ta có thể xác định phân phối xác suất trên một chuỗi có độ dài T?
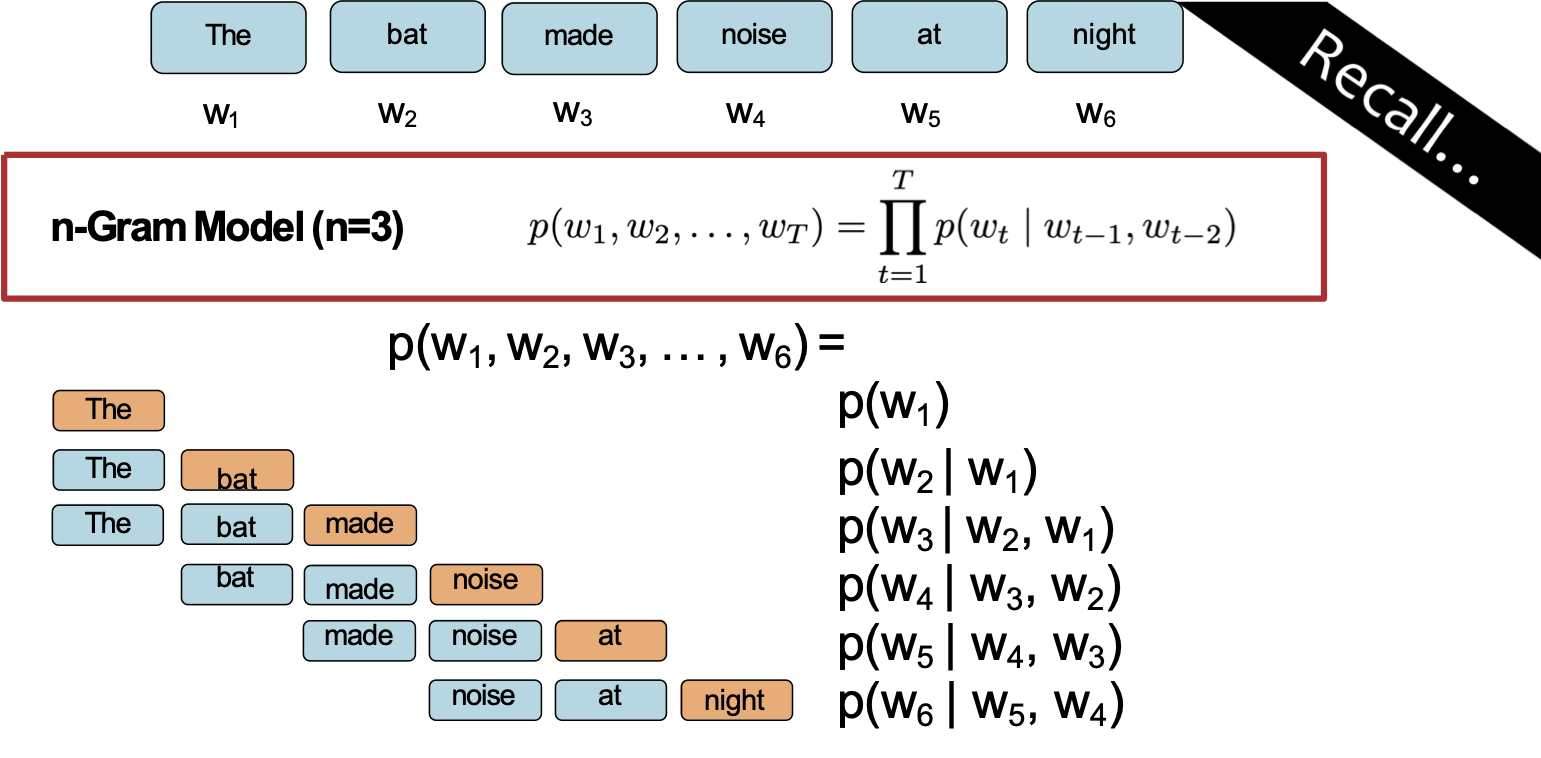
Mô hình ngôn ngữ n-Gram
Câu hỏi: Làm thế nào chúng ta có thể xác định phân phối xác suất trên một chuỗi có độ dài T?
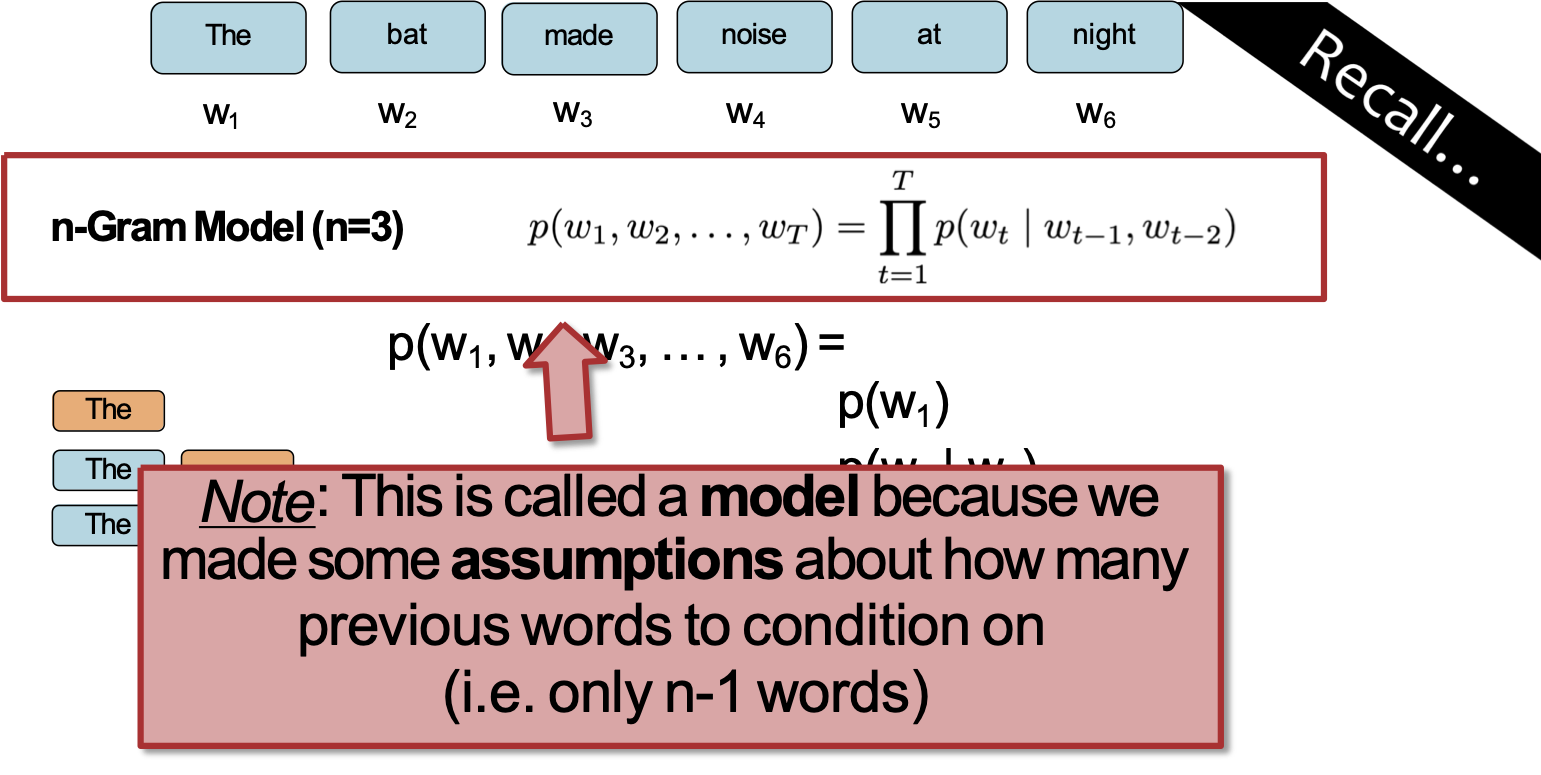
Lưu ý: Đây được gọi là mô hình vì chúng ta đã đưa ra một số giả định về số lượng từ trước để điều kiện hóa (tức là chỉ có n-1 từ)
Học mô hình n-Gram
Câu hỏi: Làm thế nào chúng ta học được xác suất cho Mô hình n-Gram?
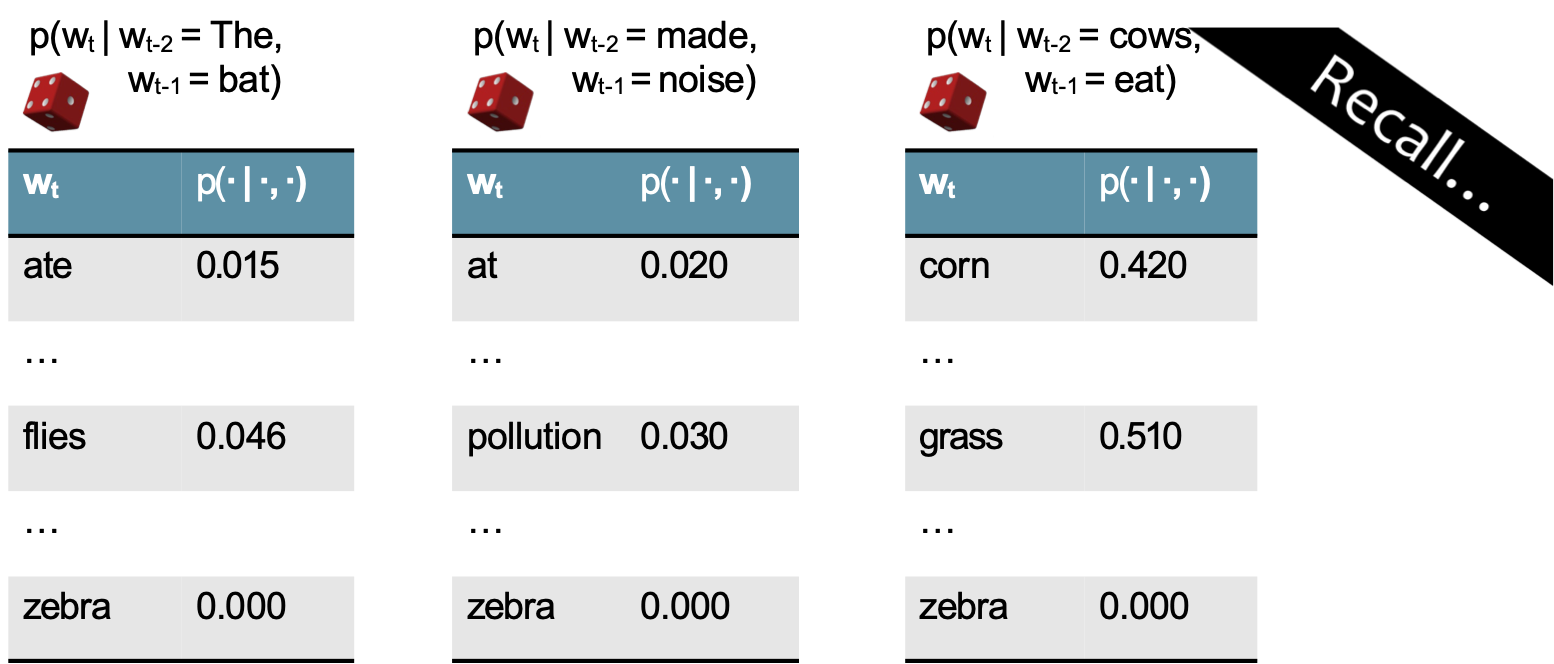
Học mô hình n-Gram
Câu hỏi: Làm thế nào chúng ta học được xác suất cho Mô hình n-Gram?
Trả lời: Từ dữ liệu! Chỉ cần đếm tần số n-gram

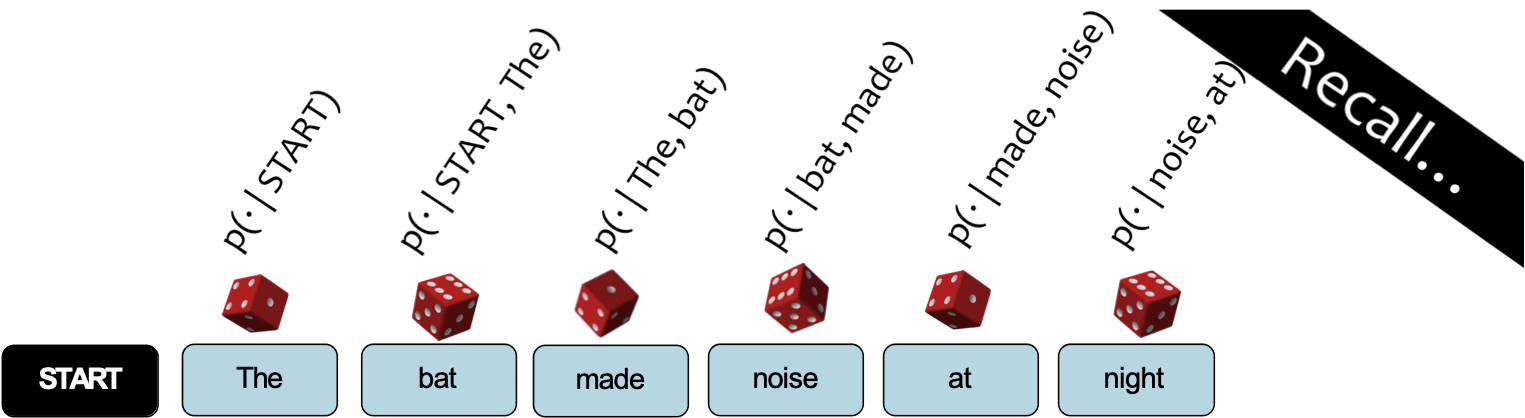
Lấy mẫu từ Mô hình ngôn ngữ
Câu hỏi: Làm thế nào để lấy mẫu từ Mô hình ngôn ngữ?
Trả lời:
- Coi mỗi phân phối xác suất như một con xúc xắc có trọng số (50k mặt)
- Chọn con xúc xắc tương ứng với p(wt | wt-2, wt-1)
- Tung con xúc xắc đó và tạo ra bất kỳ từ wt nào mà nó rơi xuống ngửa lên
- Lặp lại
Mô hình kênh nhiễu
- Trước năm 2017, có hai nhiệm vụ phụ thuộc nhiều vào mô hình ngôn ngữ:
– nhận dạng giọng nói
– dịch máy
- Định nghĩa: một mô hình kênh nhiễu kết hợp một mô hình truyền dẫn (xác suất chuyển đổi y thành x) bằng mô hình ngôn ngữ (xác suất của y)

- Mục tiêu: khôi phục y từ x
– Đối với lời nói: x là tín hiệu âm thanh, y là phiên âm
– Đối với bản dịch máy: x là câu trong ngôn ngữ nguồn, y là câu trong ngôn ngữ đích
Mô hình ngôn ngữ lớn (n-Gram)
- Các mô hình ngôn ngữ lớn đầu tiên (thực sự) là mô hình n-gram
- Google n-Gram:
– 2006: bản phát hành đầu tiên, n-gram tiếng Anh
- được đào tạo trên 1 nghìn tỷ mã thông báo văn bản web (95 tỷ câu)
- bao gồm 1 gam, 2 gam, 3 gam, 4 gam và 5 gam gam

– 2009 – 2010: n-gram trong tiếng Nhật, tiếng Trung, Thụy Điển, Tây Ban Nha, Rumani, Bồ Đào Nha, Ba Lan, Hà Lan, Ý, Pháp, Đức, Séc

Mô hình ngôn ngữ lớn (n-Gram)
- Các mô hình ngôn ngữ lớn đầu tiên (thực sự) là mô hình n-gram
- Google n-Gram:
– 2006: bản phát hành đầu tiên, n-gram tiếng Anh
- được đào tạo trên 1 nghìn tỷ mã thông báo văn bản web (95 tỷ câu)
- bao gồm 1 gam, 2 gam, 3 gam, 4 gam và 5 gam gam

– 2009 – 2010: n-gram trong tiếng Nhật, tiếng Trung, Thụy Điển, Tây Ban Nha, Rumani, Bồ Đào Nha, Ba Lan, Hà Lan, Ý, Pháp, Đức, Séc
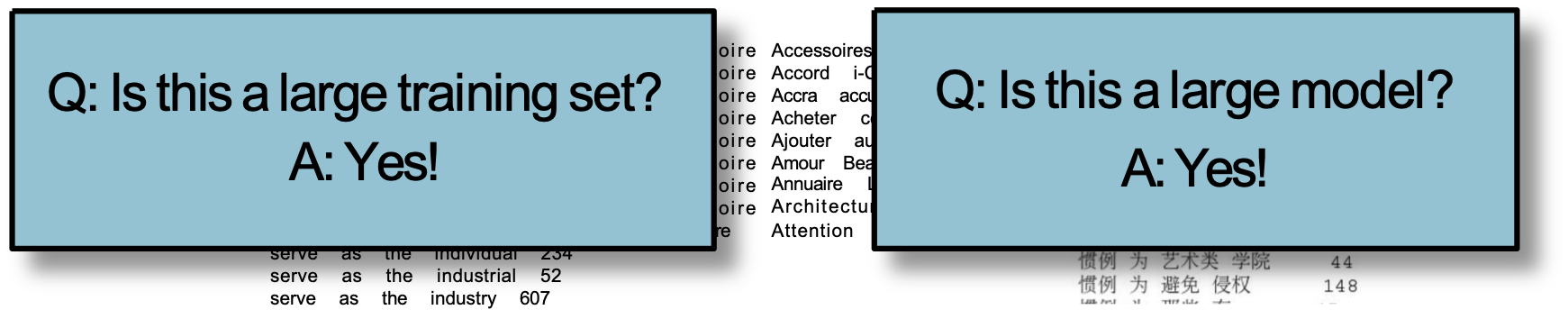
Q: Đây có phải là bộ huấn luyện lớn không?
A: Yes!
Q: Đây có phải là mô hình lớn không?
A: Yes!
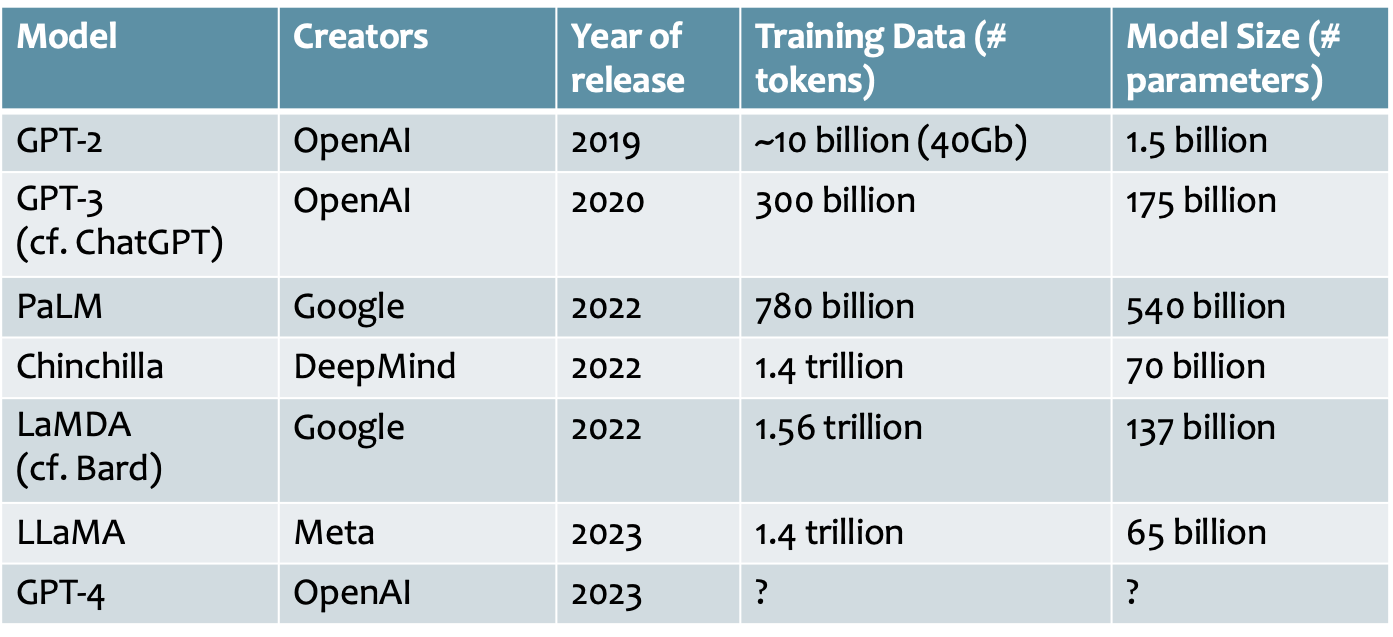
Các chương trình LLM có quy mô như thế nào?
So sánh một số mô hình ngôn ngữ lớn (LLM) gần đây
MÔ HÌNH: GPT
Mô hình ngôn ngữ Transformer
Các cách vẽ mạng nơ-ron
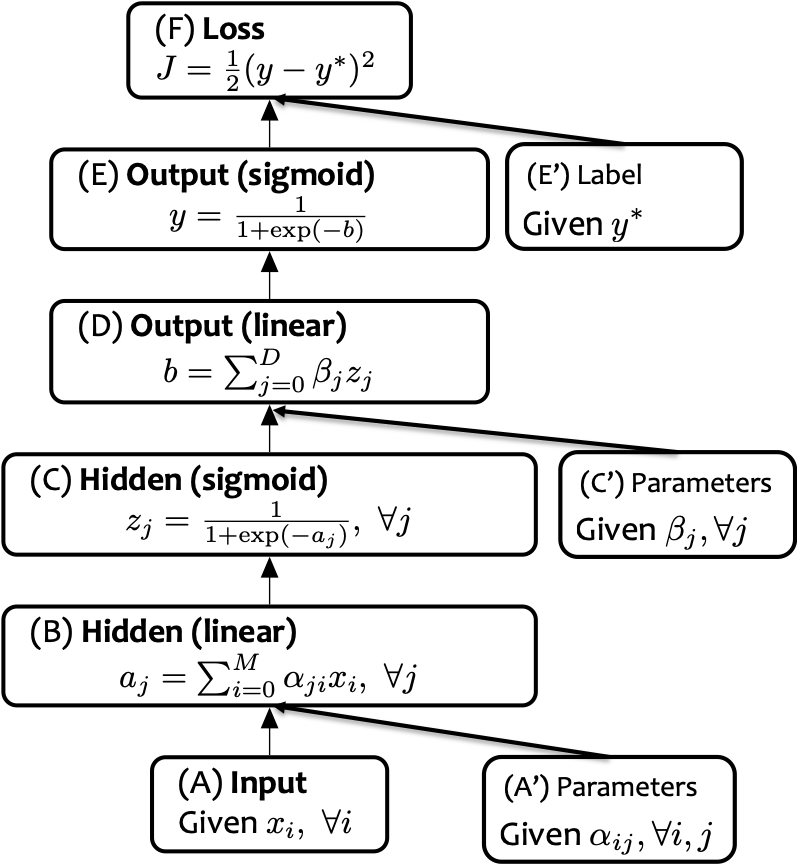
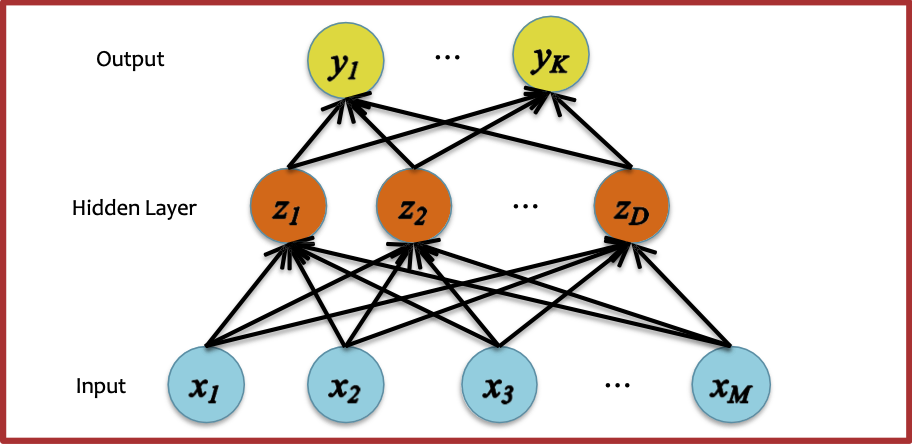
Đồ thị tính toán
- Sơ đồ biểu diễn một thuật toán
- Các nút là hình chữ nhật
- Một nút cho mỗi biến trung gian trong thuật toán
- Nút được gắn nhãn với chức năng mà nó tính toán (bên trong hộp) và cũng tên biến (bên ngoài hộp)
- Các cạnh là có hướng
- Các cạnh không có nhãn (vì cạnh không cần chúng)
- Đối với mạng nơ-ron:
– Mỗi hệ số chặn phải xuất hiện như một nút (nếu nó không được gấp lại ở đâu đó)
– Mỗi tham số sẽ xuất hiện dưới dạng một nút
– Mỗi hằng số, ví dụ như nhãn thực hoặc một vectơ đặc trưng sẽ xuất hiện trong đồ thị
– Hoàn toàn ổn khi bao gồm cả hàm mất mát
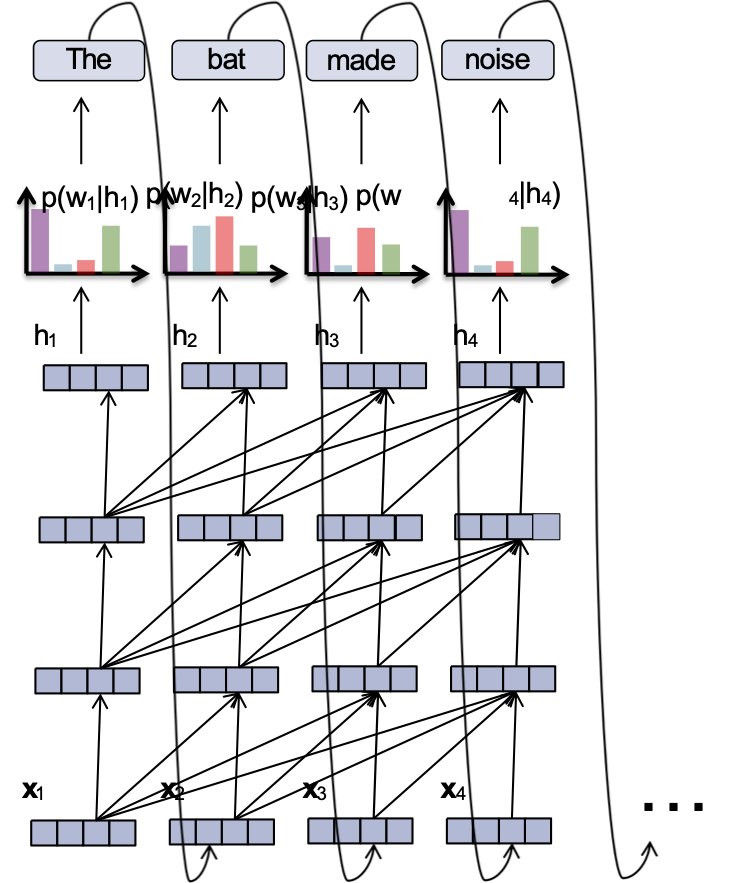
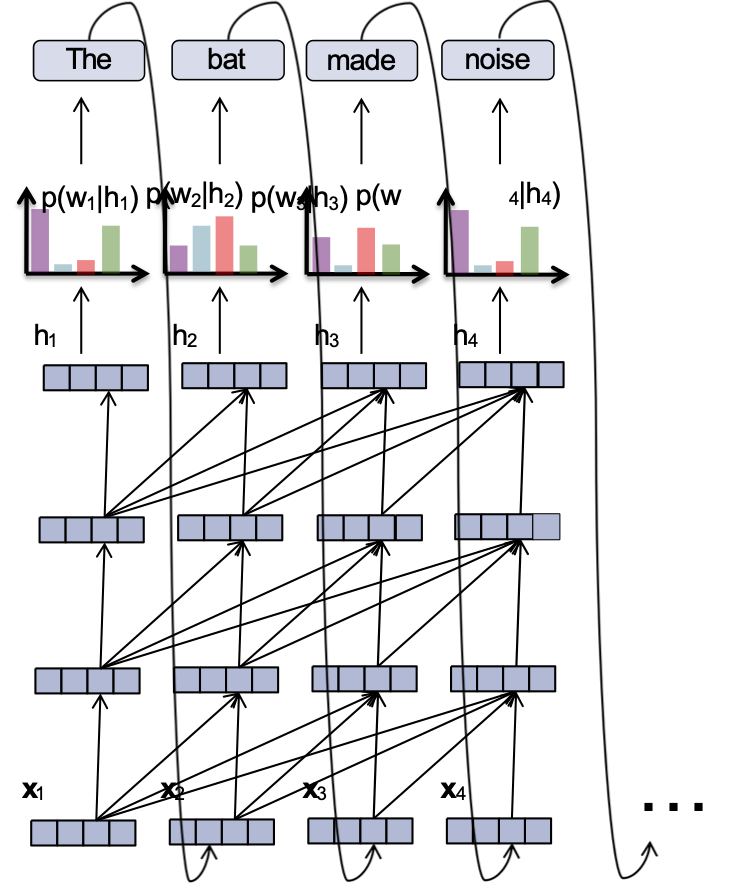
Mô hình ngôn ngữ RNN
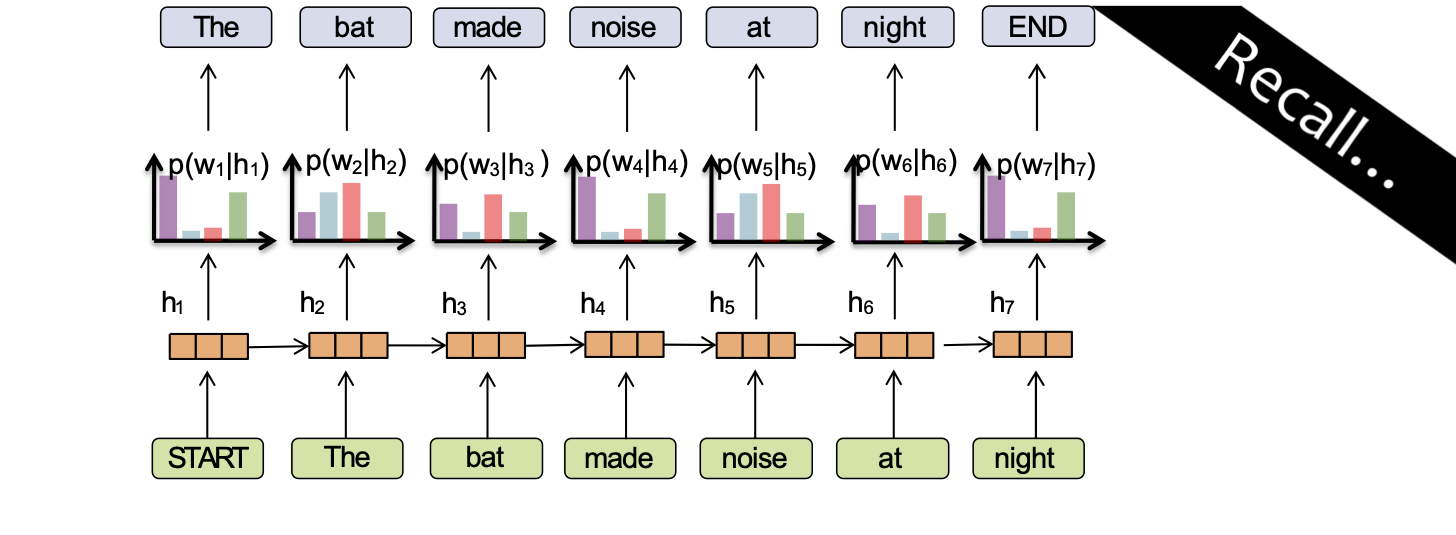
Ý chính:
(1) chuyển đổi tất cả các từ trước đó thành một vectơ có độ dài cố định
(2) định nghĩa phân phối p(wt | fθ(wt-1, …, w1)) có điều kiện trên vectơ ht = fθ(wt-1, …, w1)
RNN và sự lãng quên
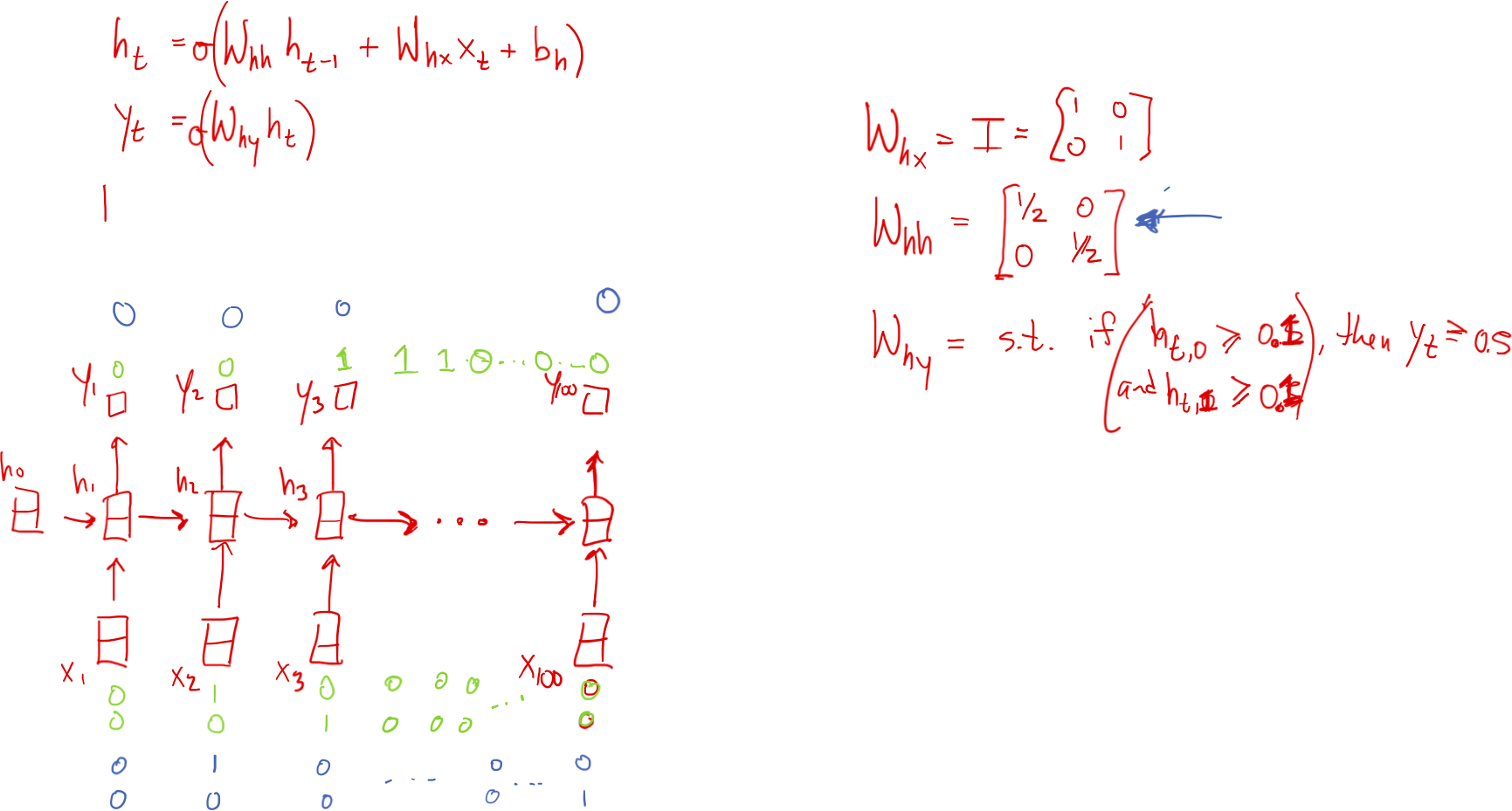
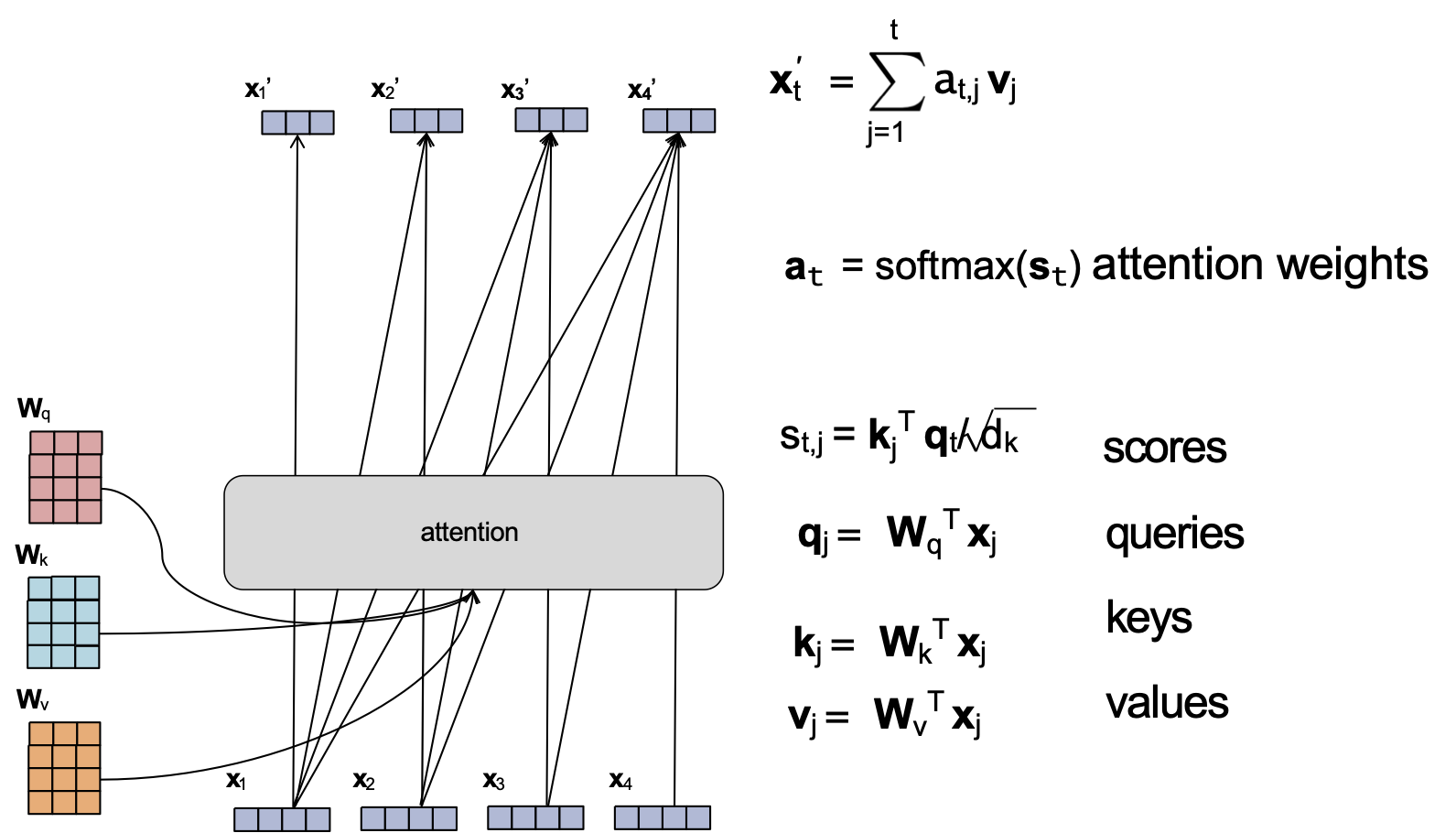
Cơ chế Attention
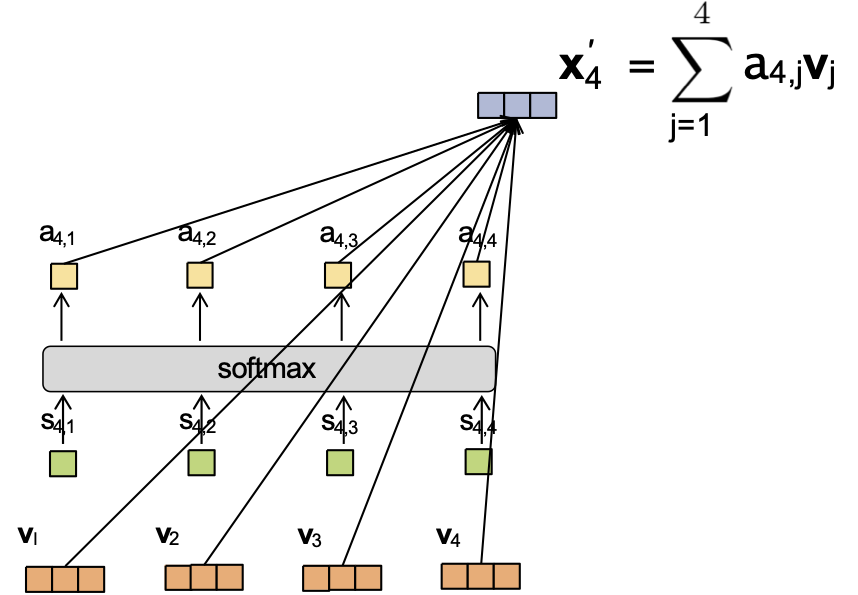
Cơ chế Attention
Cơ chế Attention
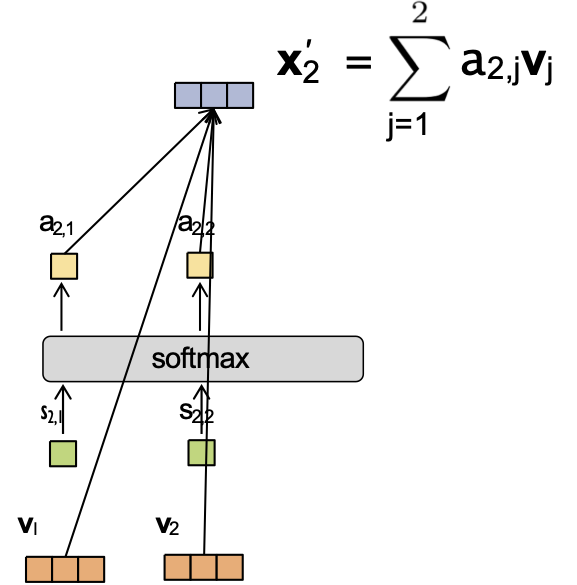
Cơ chế Attention
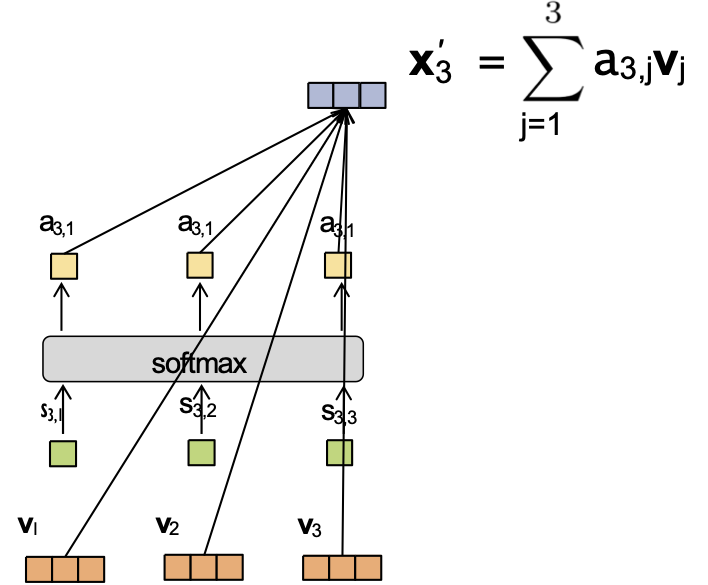
Cơ chế Attention
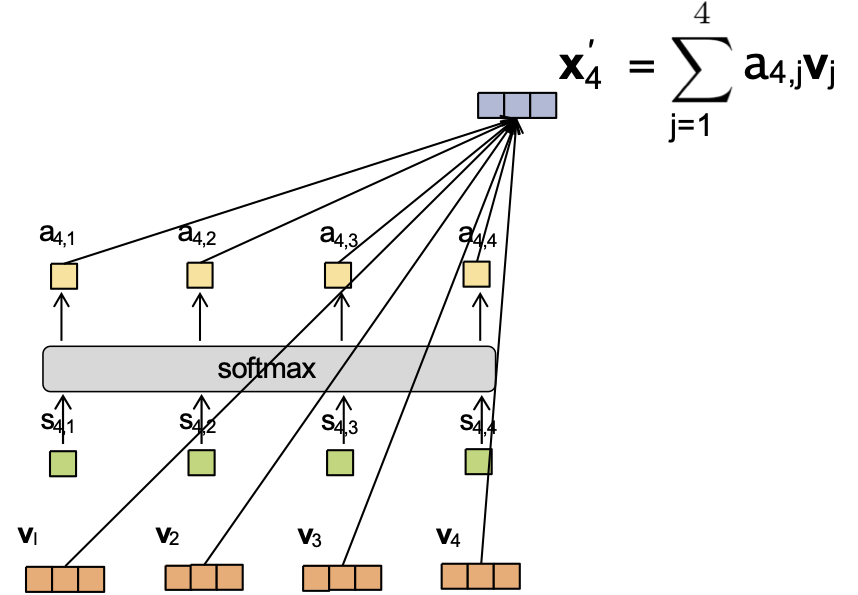
Cơ chế Attention
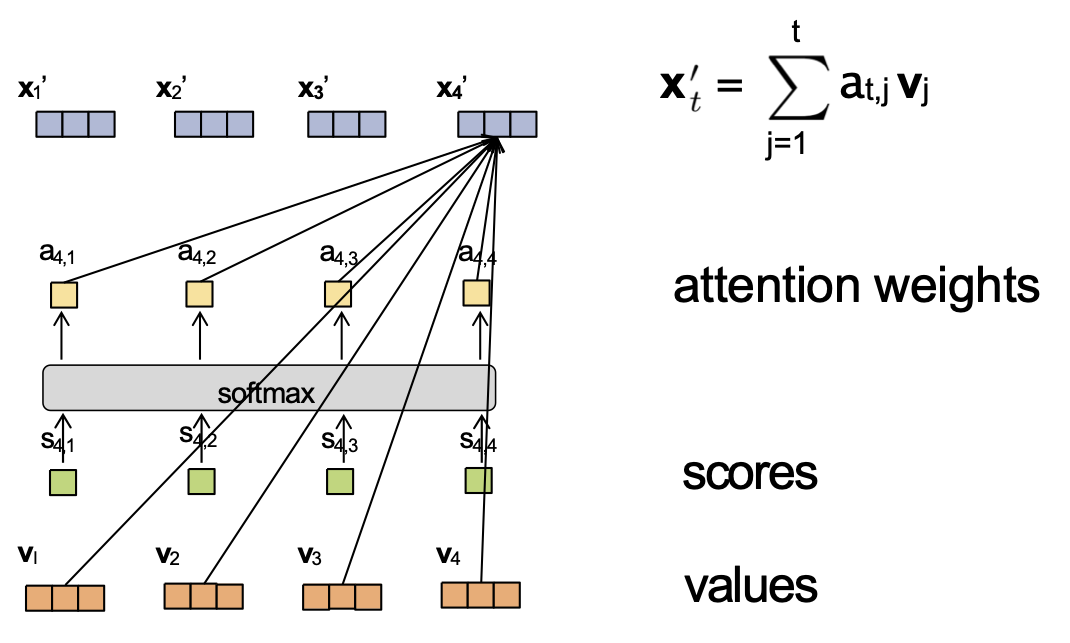
Attention tích vô hướng được chia tỷ lệ
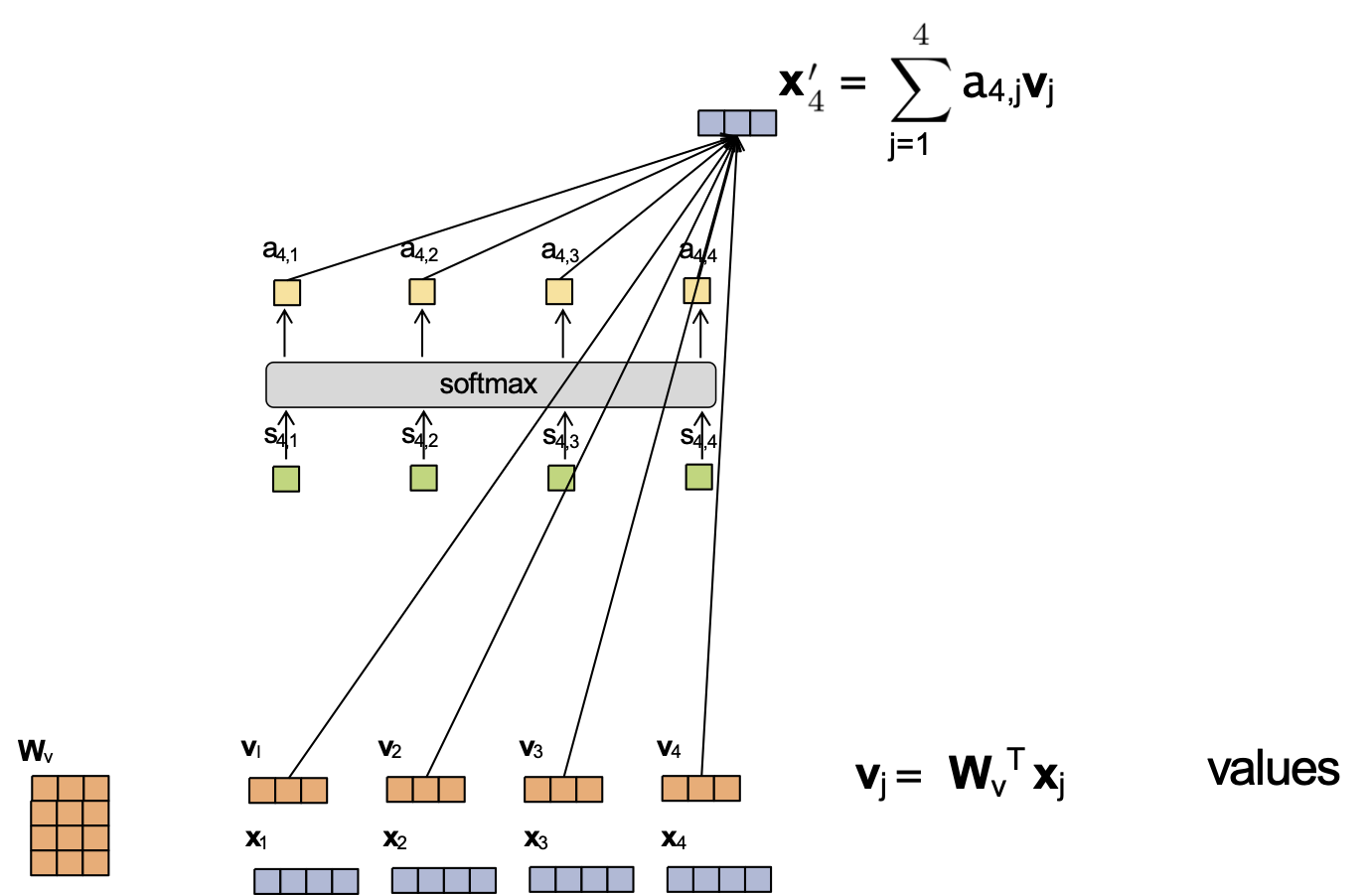
Attention tích vô hướng được chia tỷ lệ
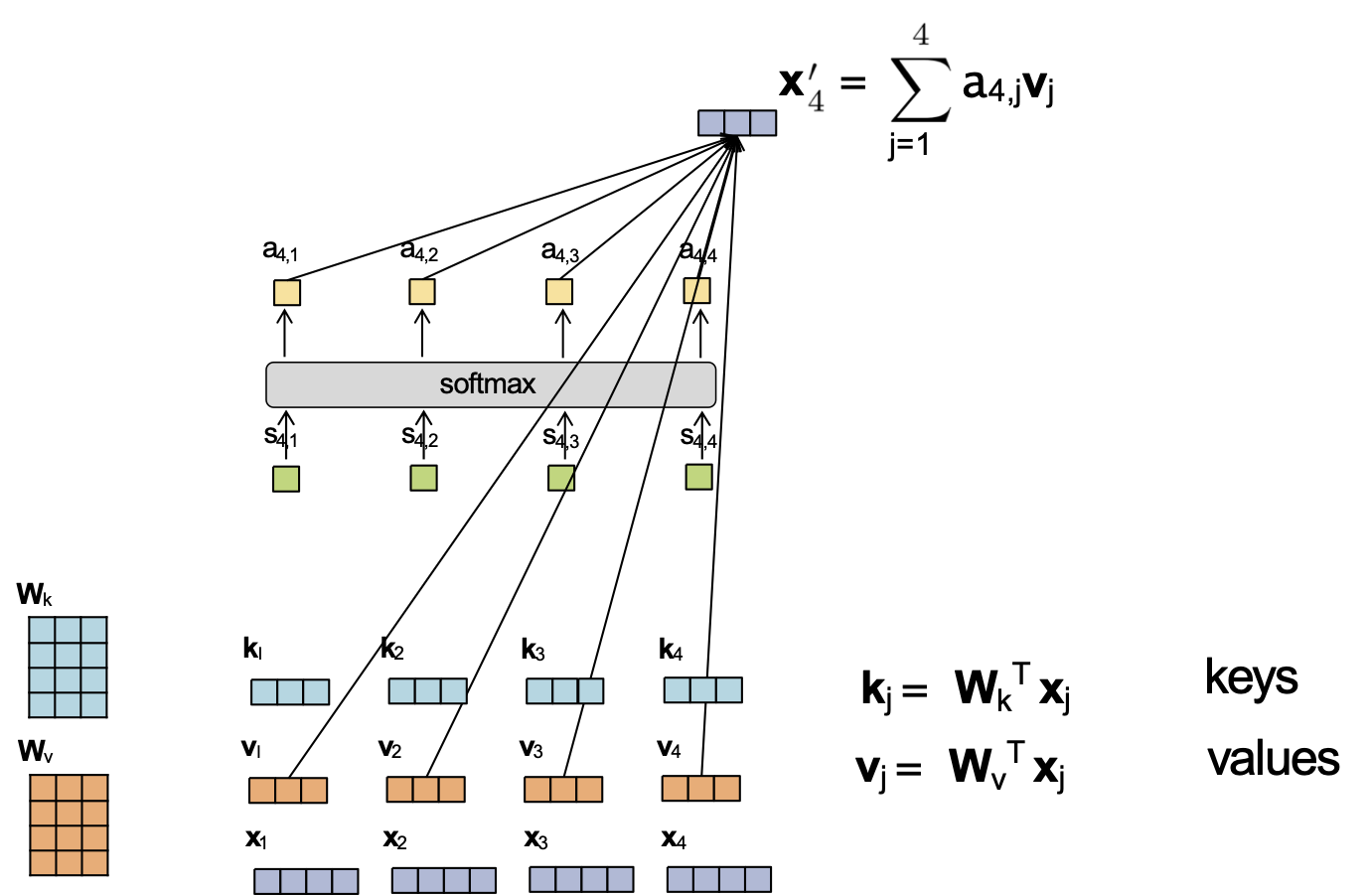
Attention tích vô hướng được chia tỷ lệ
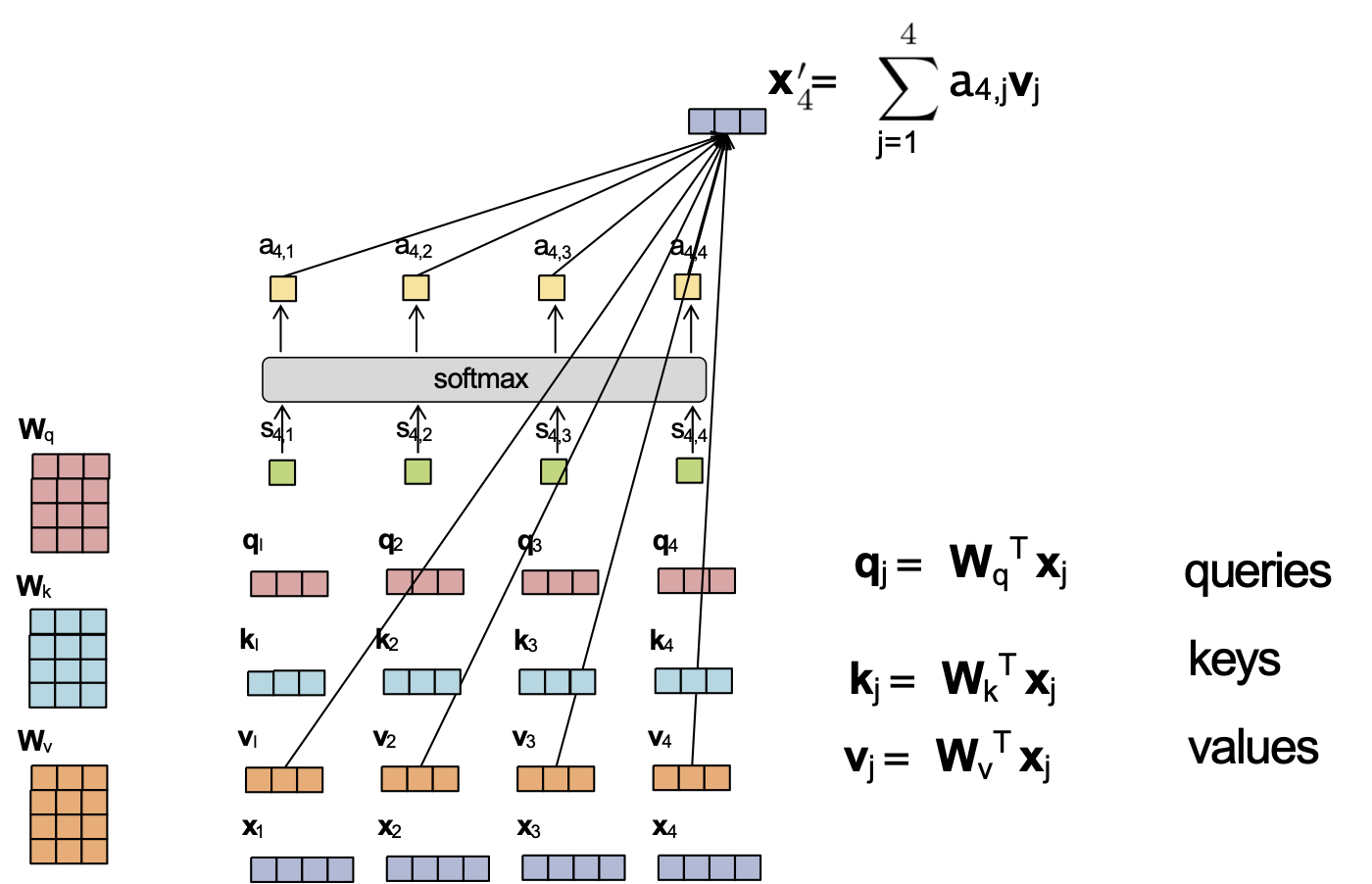
Attention tích vô hướng được chia tỷ lệ
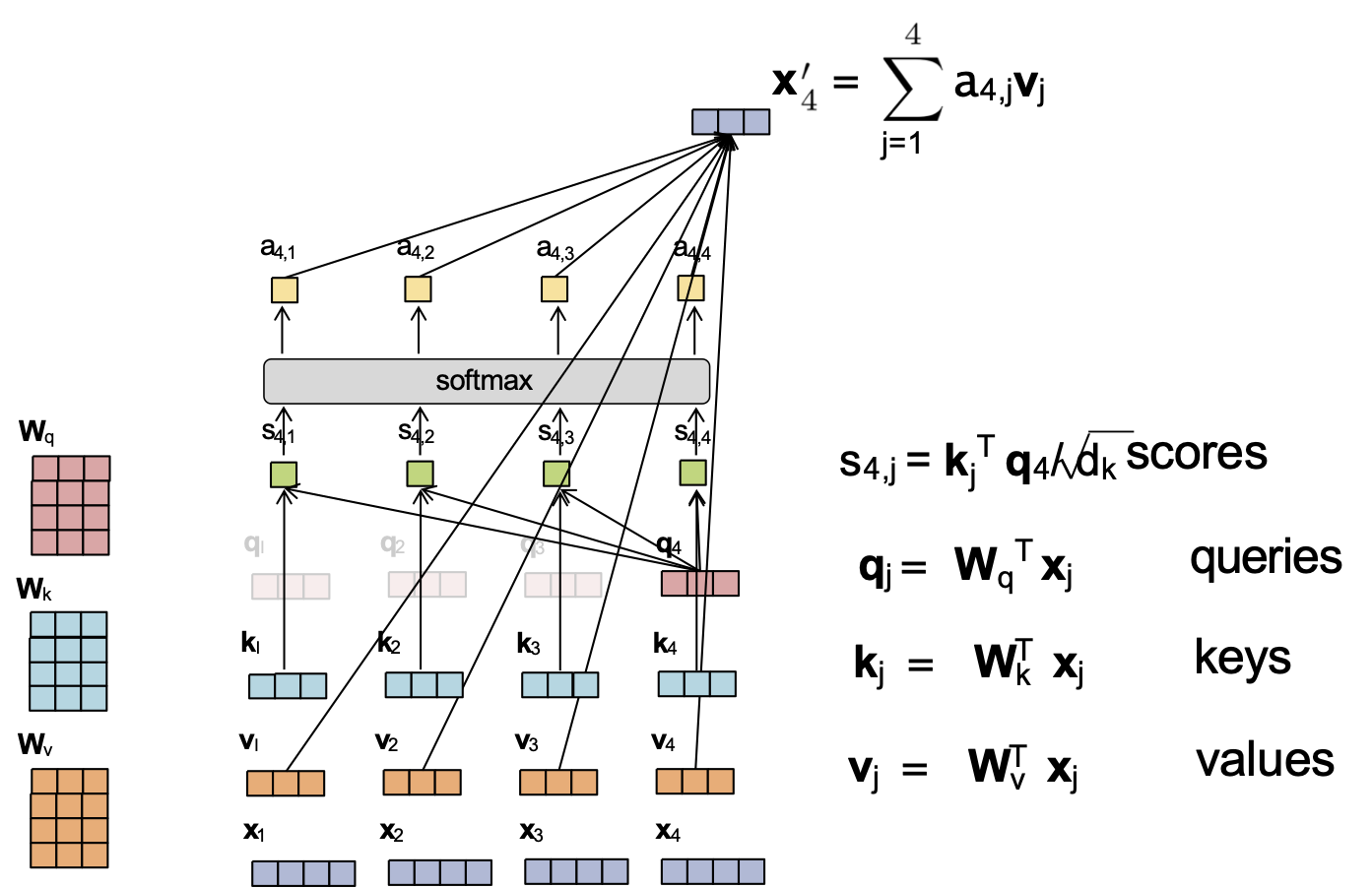
Attention tích vô hướng được chia tỷ lệ
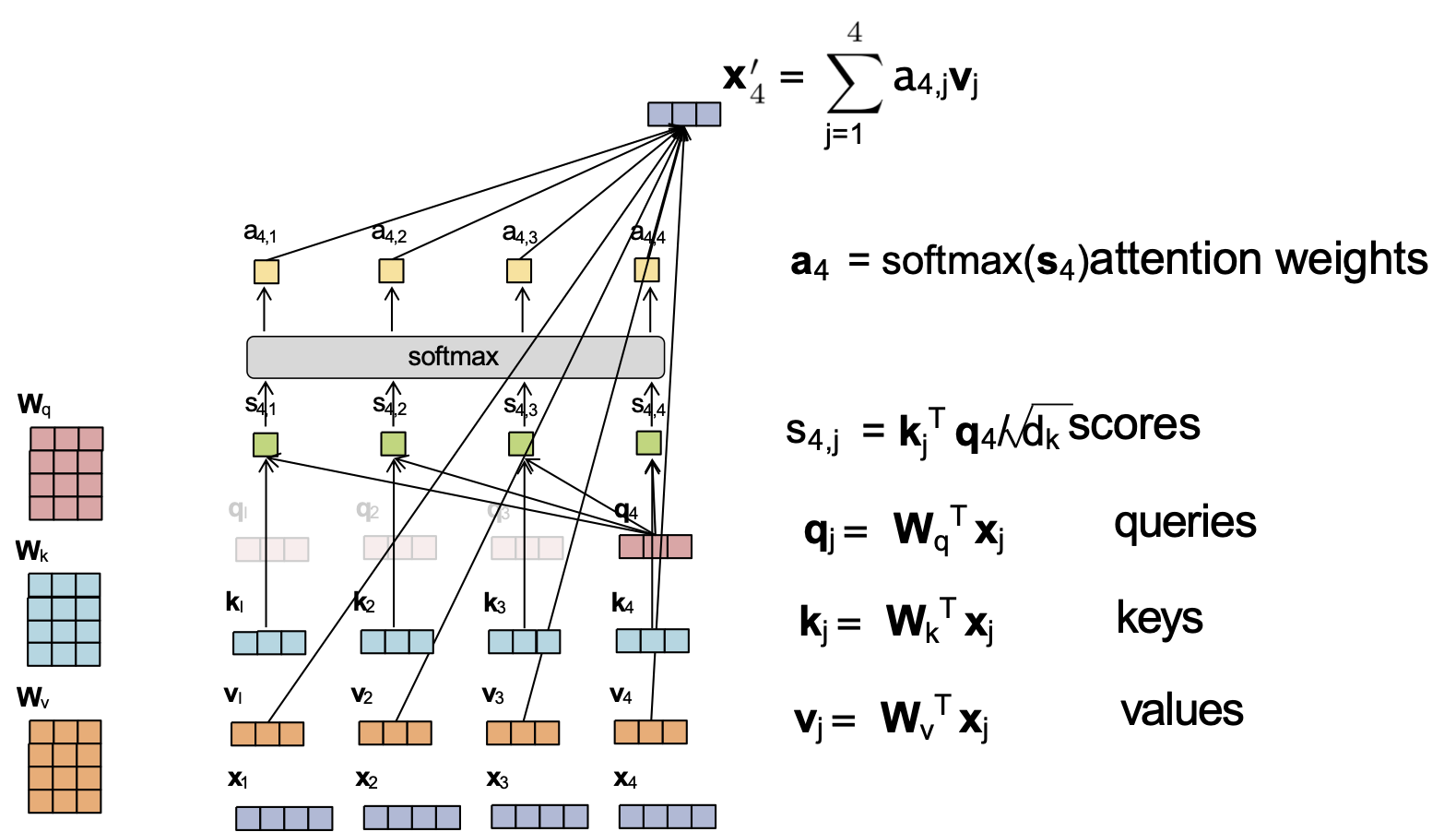
Attention tích vô hướng được chia tỷ lệ
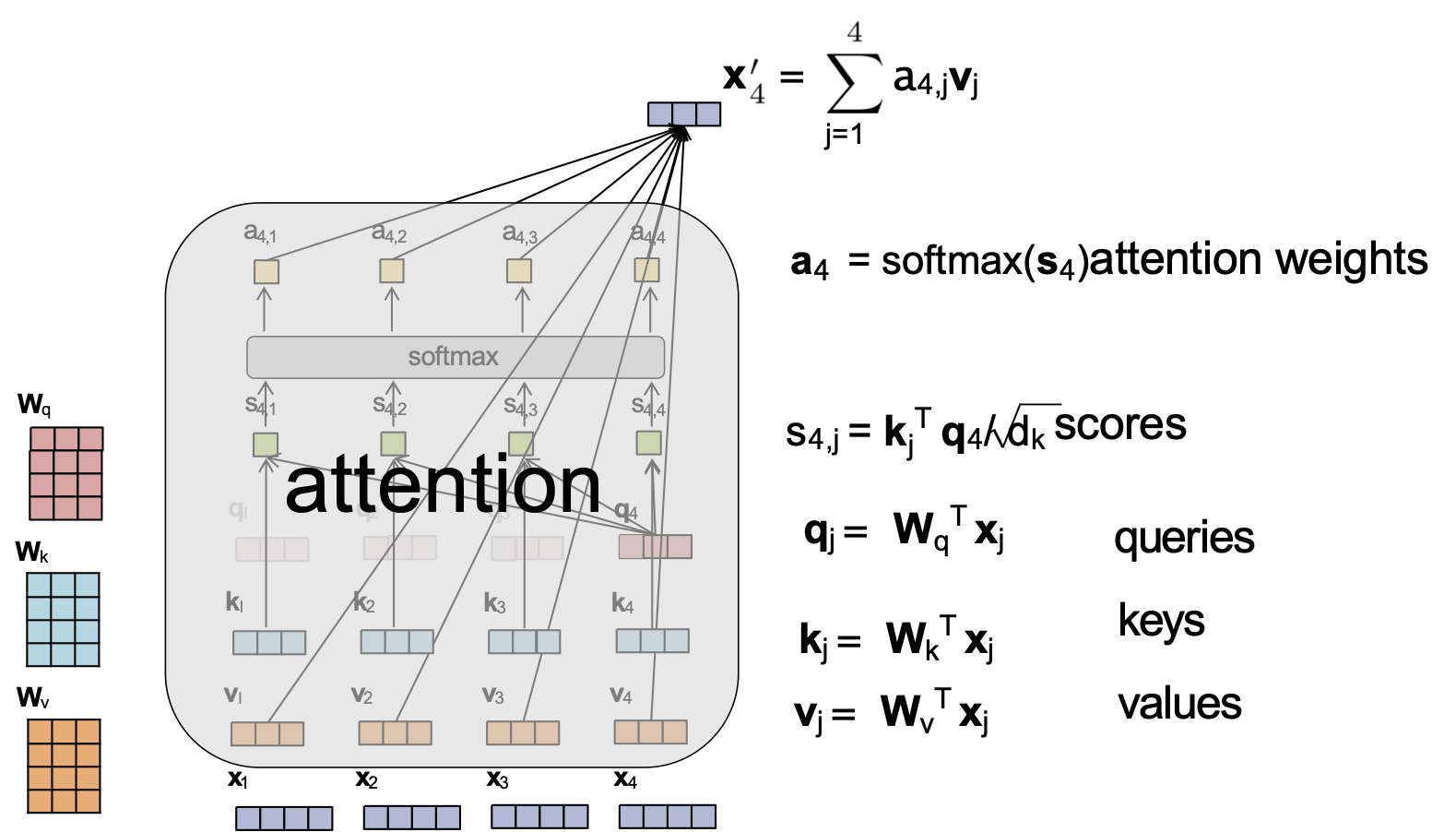
Attention tích vô hướng được chia tỷ lệ
Hoạt hình của phép tích chập 3D
http://cs231n.github.io/convolutional-networks/
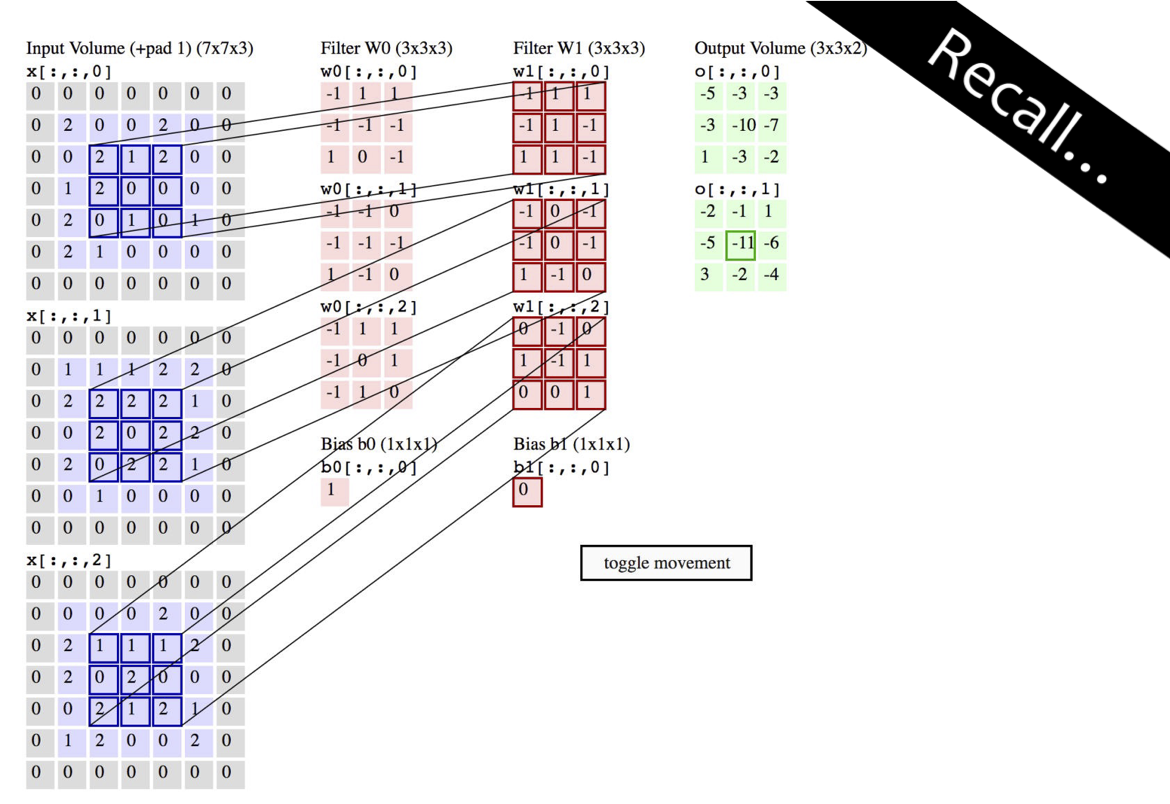
Hình từ Fei-Fei Li & Andrej Karpathy & Justin Johnson (CS231N)
Attention đa đầu
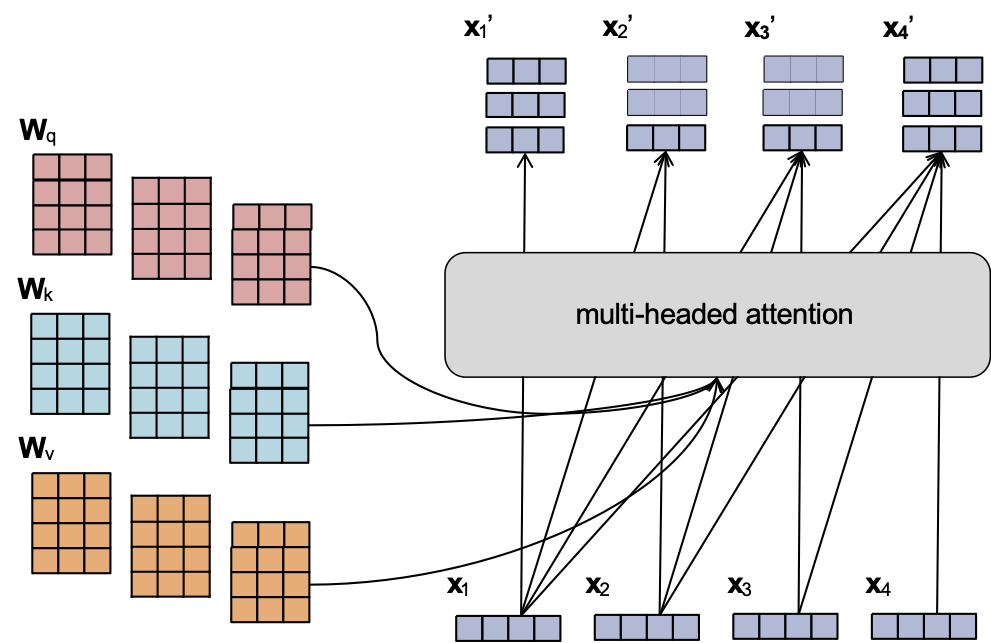
- Cũng giống như chúng ta có thể có nhiều kênh trong một lớp tích chập, chúng ta có thể sử dụng nhiều đầu trong một lớp attention
- Mỗi đầu có tham số riêng
- Chúng ta có thể nối tất cả đầu ra để có được một vector đơn cho mỗi bước thời gian
Attention đa đầu
- Cũng giống như chúng ta có thể có nhiều kênh trong một lớp tích chập, chúng ta có thể sử dụng nhiều đầu trong một lớp attention
- Mỗi đầu có tham số riêng
- Chúng ta có thể nối tất cả đầu ra để có được một vector đơn cho mỗi bước thời gian
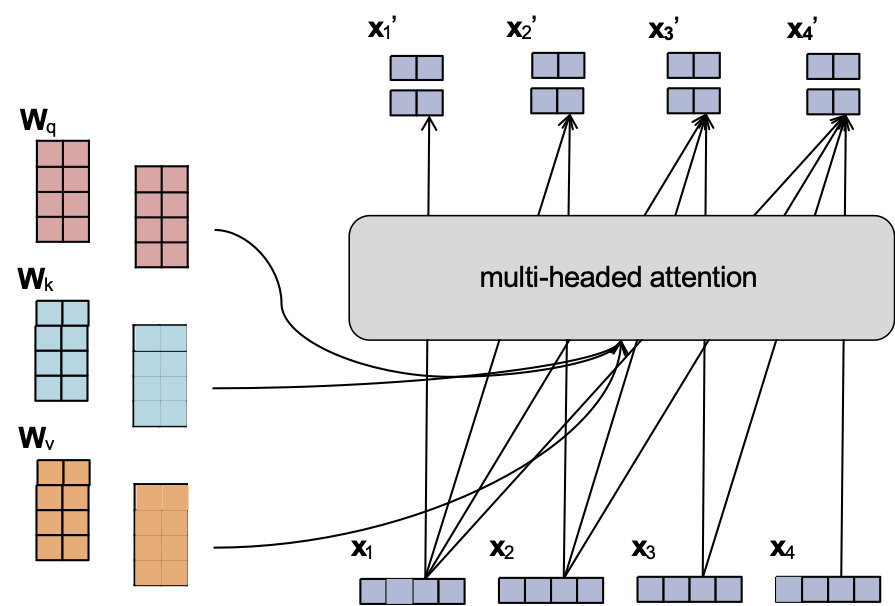
- Để đảm bảo kích thước của nhúng đầu vào xt giống với nhúng đầu ra xt’, Transformers thường chọn kích thước nhúng và số lượng đầu thích hợp:
- dmodel = dim. của đầu vào
- dk = dim. của mỗi đầu ra
- h = # đầu
- Chọn dk = dmodel / h
- Sau đó nối các đầu ra
Attention đa đầu
- Cũng giống như chúng ta có thể có nhiều kênh trong một lớp tích chập, chúng ta có thể sử dụng nhiều đầu trong một lớp attention
- Mỗi đầu có tham số riêng
- Chúng ta có thể nối tất cả đầu ra để có được một vector đơn cho mỗi bước thời gian
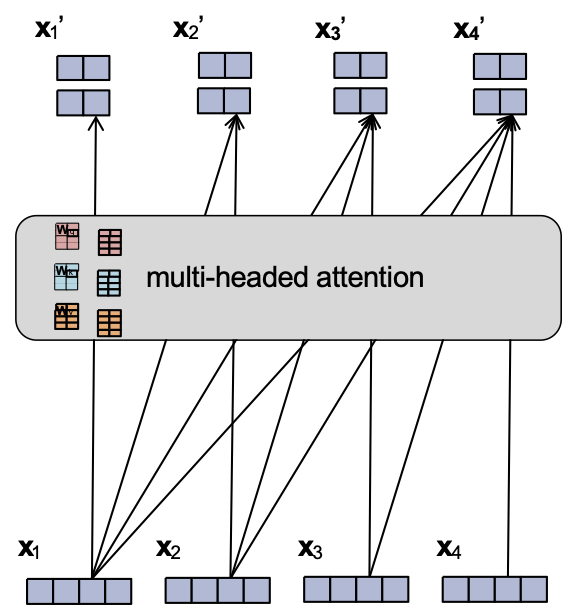
- Để đảm bảo kích thước của nhúng đầu vào xt giống với nhúng đầu ra xt’, Transformers thường chọn kích thước nhúng và số lượng đầu thích hợp:
- dmodel = dim. của đầu vào
- dk = dim. của mỗi đầu ra
- h = # đầu
- Chọn dk = dmodel / h
- Sau đó nối các đầu ra
Mô hình ngôn ngữ RNN
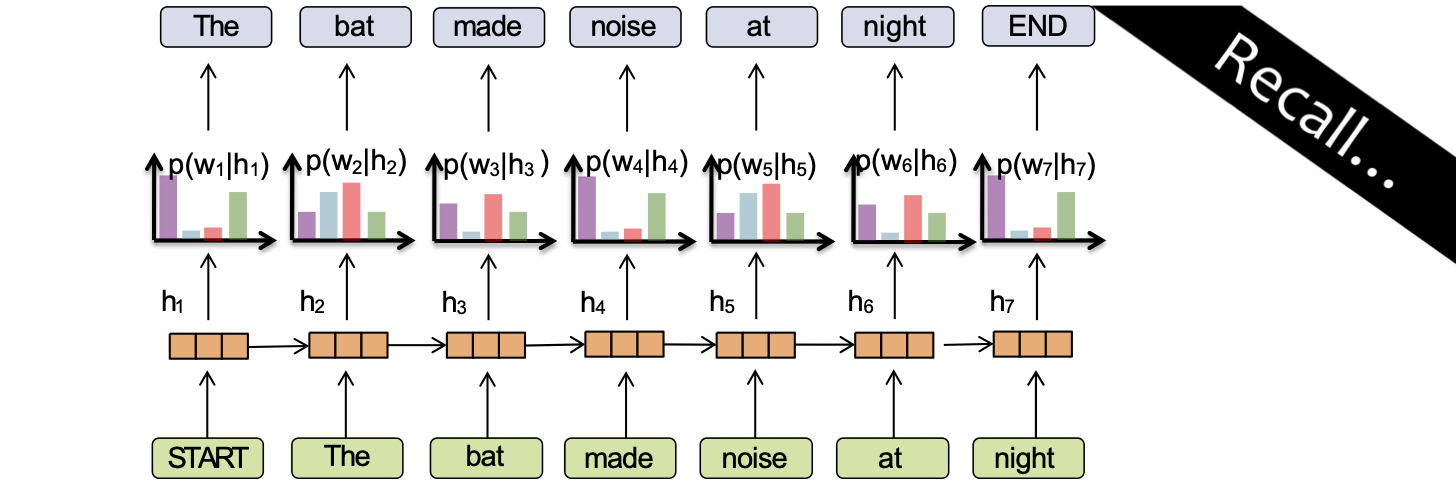
Ý chính:
(1) chuyển đổi tất cả các từ trước đó thành một vectơ có độ dài cố định
(2) định nghĩa phân phối p(wt | fθ(wt-1, …, w1)) có điều kiện trên vectơ ht = fθ(wt-1, …, w1)
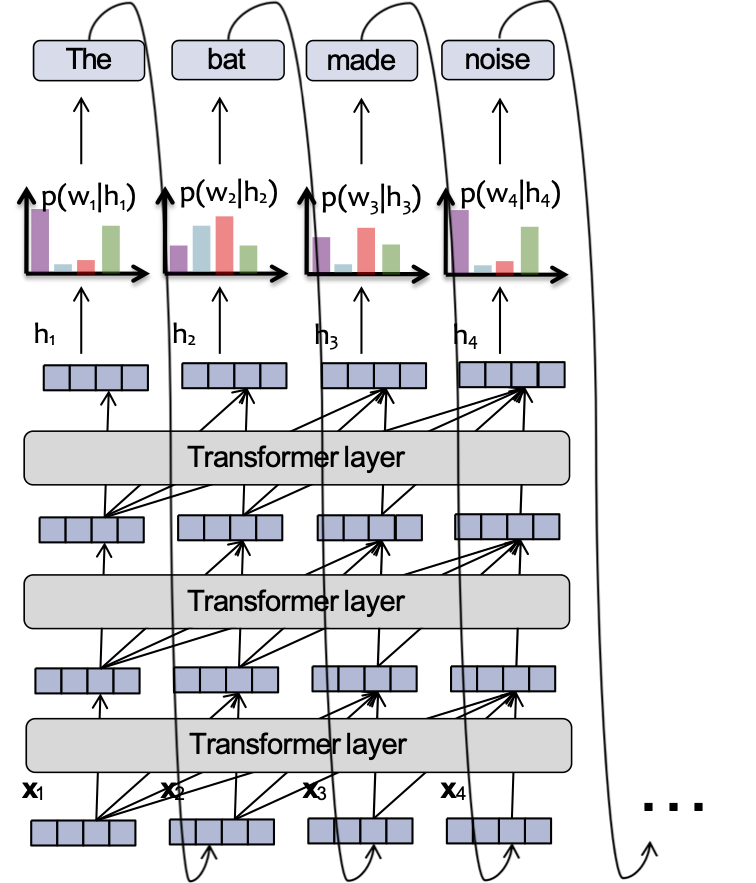
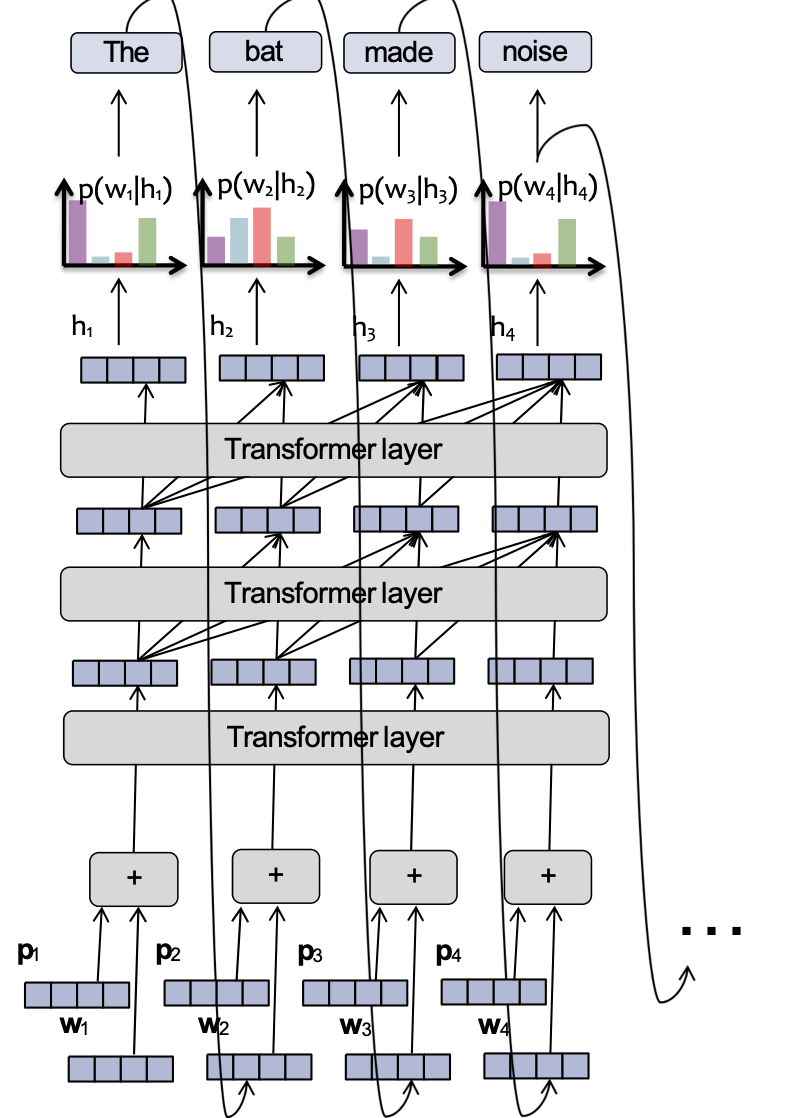
Mô hình ngôn ngữ Transformer
Mỗi vector ẩn nhìn lại các vectơ ẩn của hiện thời và các bước thời gian trước đó trong lớp trước.
Phần mô hình ngôn ngữ cũng giống như một RNN-LM!
Quan trọng!
- Đồ thị tính toán RNN tăng tuyến tính theo số lượng token đầu vào
- Đồ thị tính toán Transformer-LM tăng theo cấp số nhân bậc hai với số lượng token đầu vào
Mô hình ngôn ngữ Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư
Mỗi vector ẩn nhìn lại các vectơ ẩn của hiện thời và các bước thời gian trước đó trong lớp trước.
Phần mô hình ngôn ngữ cũng giống như một RNN-LM!
Quan trọng!
- Đồ thị tính toán RNN tăng tuyến tính theo số lượng token đầu vào
- Đồ thị tính toán Transformer-LM tăng theo cấp số nhân bậc hai với số lượng token đầu vào
Chuẩn hóa lớp
- Vấn đề: Dịch chuyển đồng biến bên trong xảy ra trong quá trình đào tạo mạng sâu khi một thay đổi nhỏ ở các lớp thấp khuếch đại thành một thay đổi lớn ở các lớp cao
- Một giải pháp: Chuẩn hóa lớp sẽ chuẩn hóa mỗi lớp và học độ lợi/độ lệch từng phần tử
- Việc chuẩn hóa như vậy cho phép tốc độ học tập cao hơn (để hội tụ nhanh hơn) mà không có vấn đề gì về gradient phân kỳ

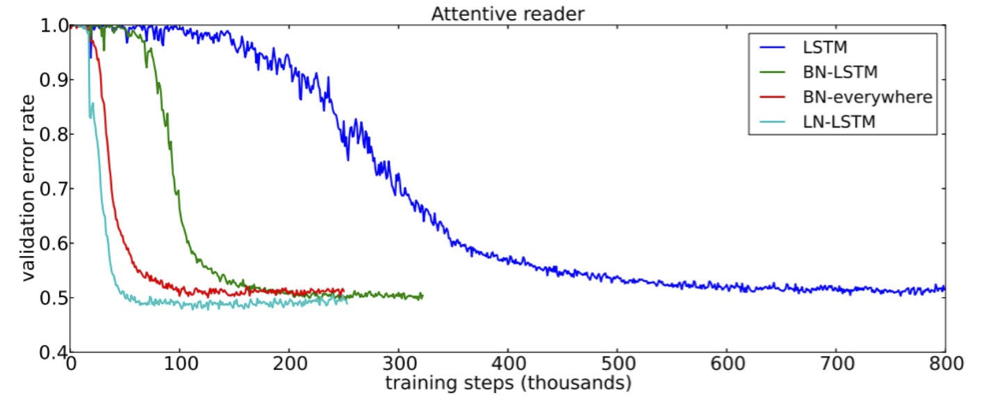
Hình từ https://arxiv.org/pdf/1607.06450.pdf
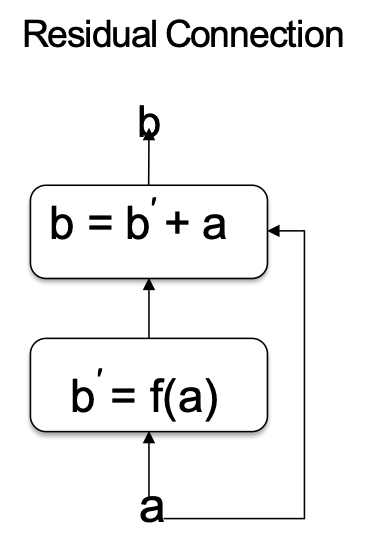
Kết nối phần dư
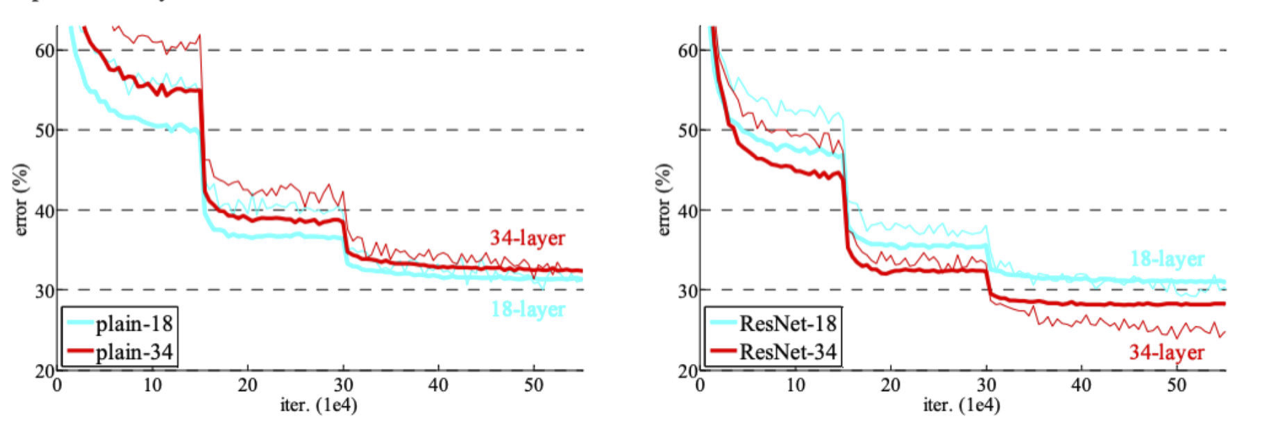
- Vấn đề: khi độ sâu mạng lưới phát triển rất lớn, một suy giảm hiệu suất xảy ra mà không được giải thích bằng cách khớp quá mức (tức là lỗi đào tạo / kiểm tra đều tệ hơn)
- Một giải pháp: Kết nối phần dư truyền một bản sao của đầu vào cùng với
- Những kết nối phần dư này cho phép đào tạo hiệu quả các mạng rất sâu hoạt động tốt hơn so với các mạng nông hơn (mặc dù vẫn sâu)
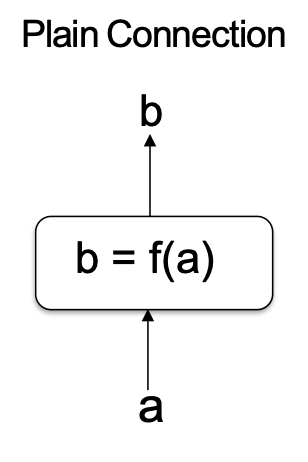
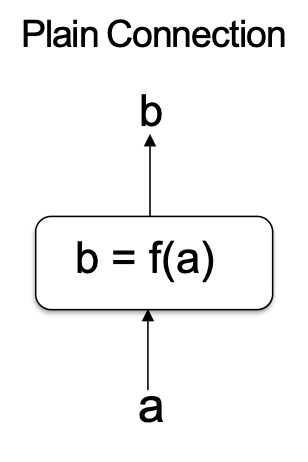
Kết nối đơn giản
Kết nối phần dư
Hình từ https://arxiv.org/pdf/1512.03385.pdf
Kết nối phần dư
- Vấn đề: khi độ sâu mạng lưới phát triển rất lớn, một suy giảm hiệu suất xảy ra mà không được giải thích bằng cách khớp quá mức (tức là lỗi đào tạo / kiểm tra đều tệ hơn)
- Một giải pháp: Kết nối phần dư truyền một bản sao của đầu vào cùng với
- Những kết nối phần dư này cho phép đào tạo hiệu quả các mạng rất sâu hoạt động tốt hơn so với các mạng nông hơn (mặc dù vẫn sâu)
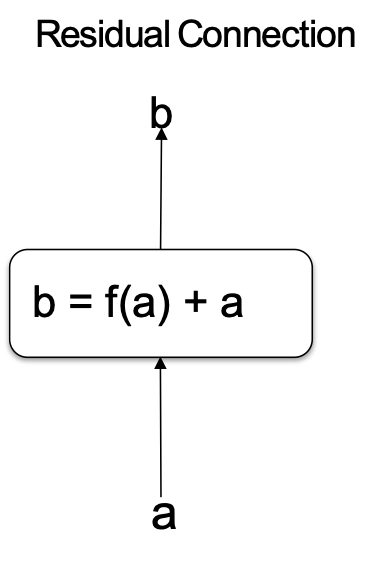
Kết nối đơn giản
Kết nối phần dư
Tại sao các kết nối phần dư lại hữu ích?
Thay vì f(a) phải học biến đổi đầy đủ của a, f(a) chỉ cần học một sửa đổi bổ sung của a (tức là phần dư).
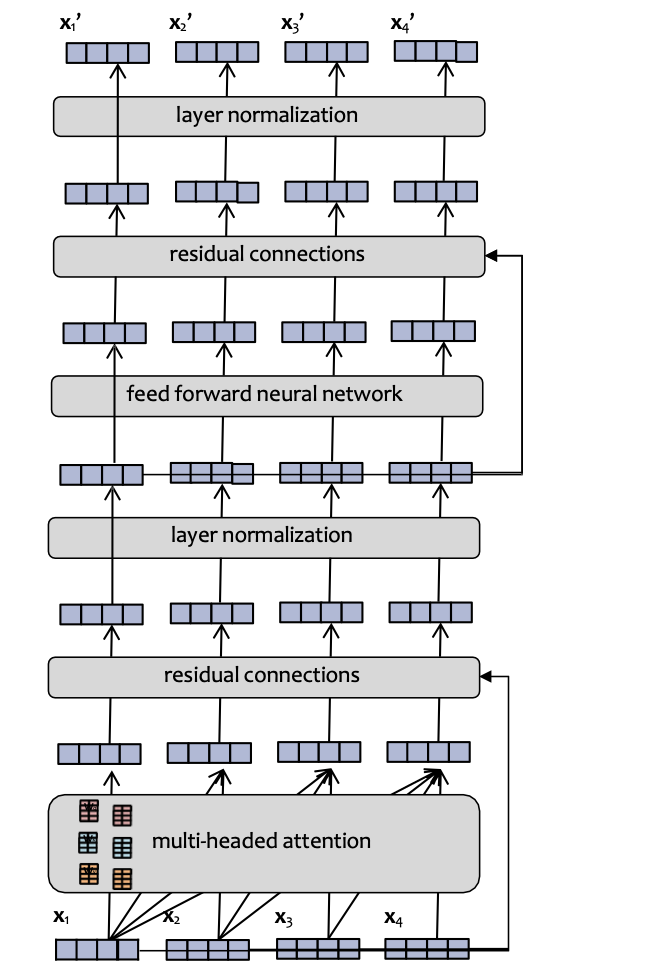
Lớp Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư
Lớp Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư
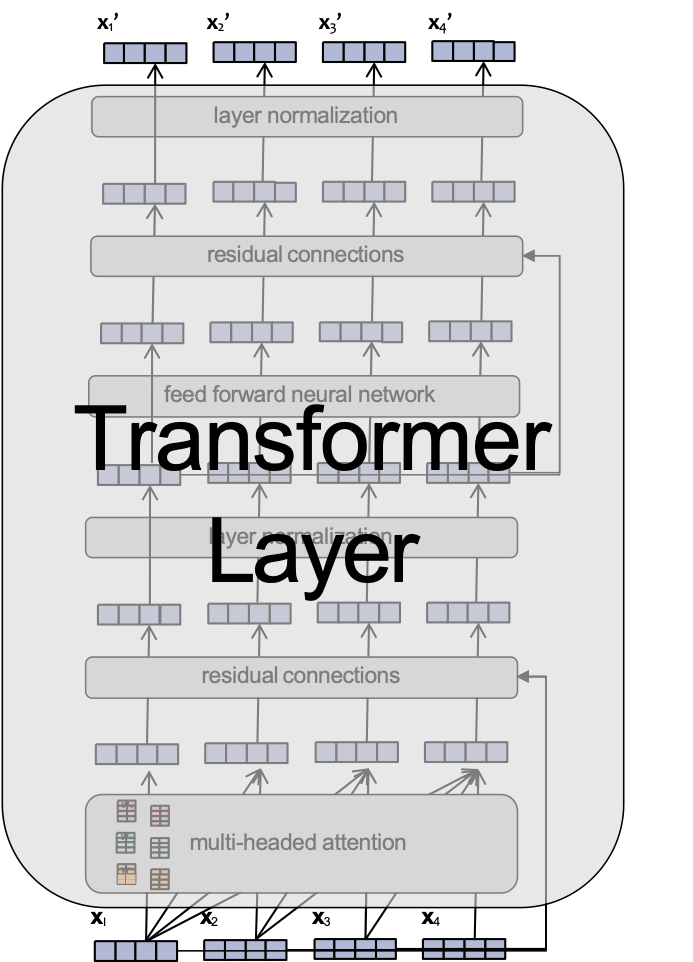
Lớp Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư

Lớp Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư
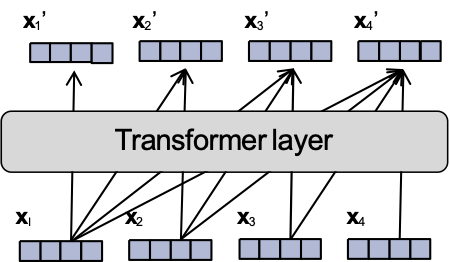
Mô hình ngôn ngữ Transformer
Mỗi lớp của một Transformer LM bao gồm một số lớp con:
- attention
- Mạng nơ-ron truyền thẳng
- chuẩn hóa lớp
- kết nối phần dư
Mỗi vector ẩn nhìn lại các vectơ ẩn của hiện thời và các bước thời gian trước đó trong lớp trước.
Phần mô hình ngôn ngữ cũng giống như một RNN-LM.
Cuộc thăm dò trong lớp
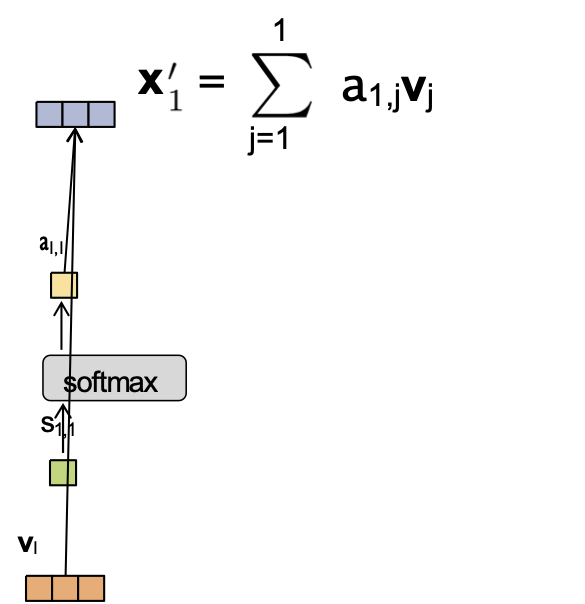
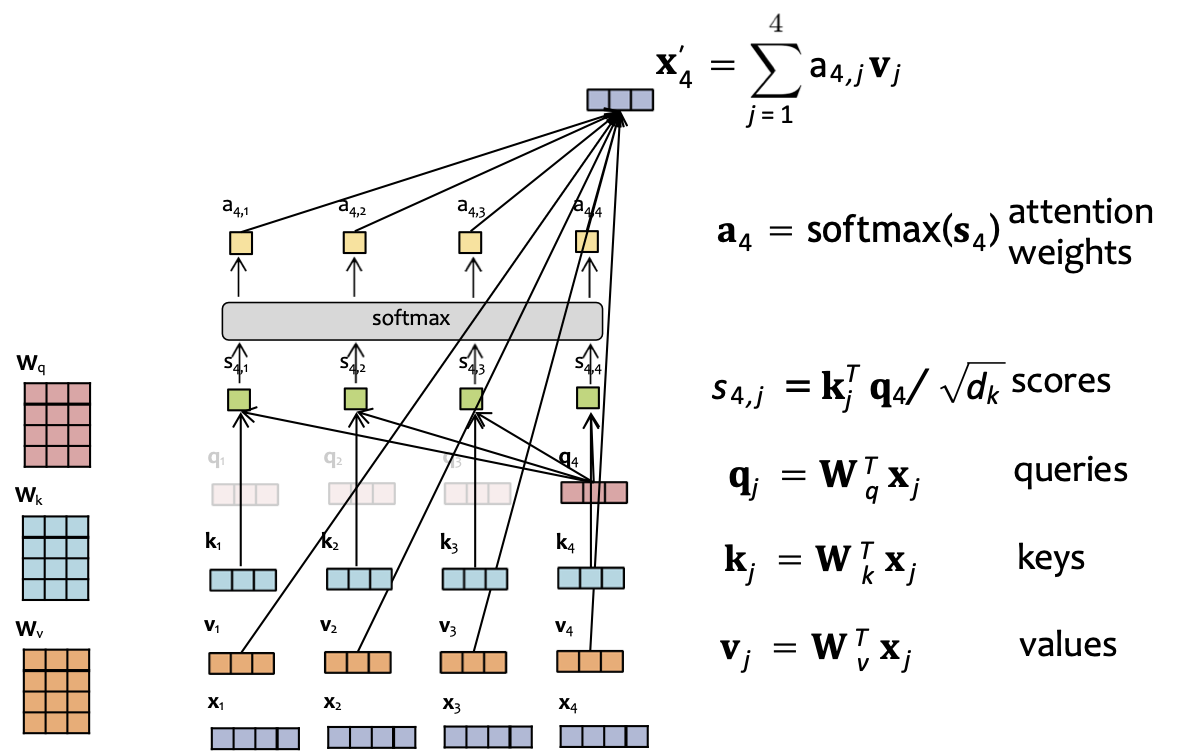
Câu hỏi:
Giả sử chúng ta có nhúng đầu vào và trọng số attention sau:
- x1 = [1,0,0,0] a4,1 = 0.1
- x2 = [0,1,0,0] a4,2 = 0.2
- x3 = [0,0,2,0] a4,3 = 0.6
- x4 = [0,0,0,1] a4,4 = 0.1
Và Wv = I. Khi đó ta có thể tính được x4‘.
Bây giờ giả sử chúng ta hoán đổi nhúng x2 và x3 sao cho
- x2 = [0,0,2,0]
- x3 = [0,1,0,0]
Giá trị mới của x4‘ là bao nhiêu?
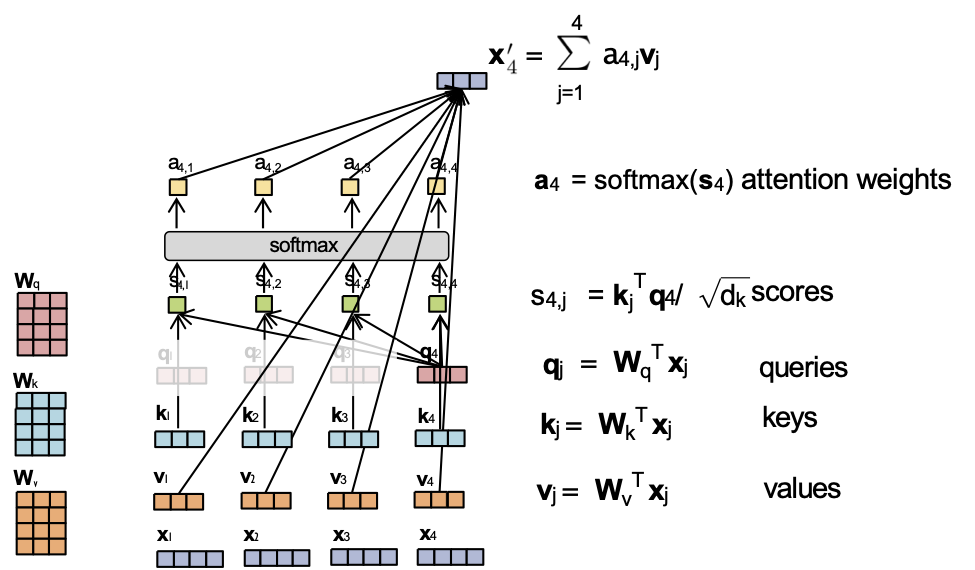
Trả lời:
Nhúng vị trí
- Vấn đề: Bởi vì attention là không phụ thuộc vào vị trí, chúng ta cần một cách để tìm hiểu về các vị trí
- Giải pháp: Sử dụng (hoặc học) một bộ các nhúng vị trí cụ thể: pt biểu thị ý nghĩa của nó ở vị trí t. Và cộng thêm pt này vào nhúng từ wt.
Ý tưởng chính là mọi từ xuất hiện ở vị trí t sử dụng cùng nhúng vị trí pt
- Có một số loại nhúng vị trí:
– Một số là cố định (dựa trên sin và cos), trong khi những cái khác được học (như nhúng từ)
– Một số là tuyệt đối (như mô tả ở trên) nhưng chúng ta cũng có thể sử dụng nhúng vị trí tương đối (tức là tương đối với vị trí của vectơ truy vấn)
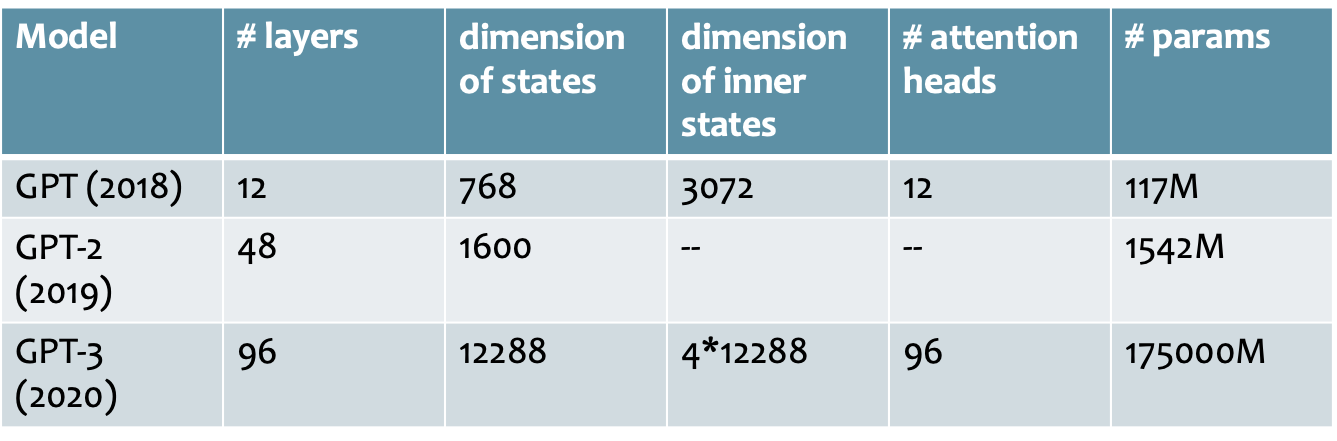
GPT-3
- GPT là viết tắt của Generative Pre-trained Transformer
- GPT chỉ là một Transformer LM, nhưng với số lượng lớn tham số
Dạng Ma trận của Attention tích vô hướng được chia tỷ lệ
- Để tăng tốc, chúng ta tính toán tất cả các truy vấn cùng một lúc sử dụng các phép toán ma trận
- Đầu tiên chúng ta đóng gói các truy vấn, chìa khóa, giá trị vào ma trận:
– Q = [q1,…,qN]T
– K = [k1,…,kN]T
– V = [v1,…,vN]T
- Sau đó chúng ta tính toán tất cả truy vấn cùng một lúc:

Dạng Ma trận của Attention tích vô hướng được chia tỷ lệ
- Để tăng tốc, chúng ta tính toán tất cả các truy vấn cùng một lúc sử dụng các phép toán ma trận
- Đầu tiên chúng ta đóng gói các truy vấn, chìa khóa, giá trị vào ma trận:
– Q = [q1,…,qN]T
– K = [k1,…,kN]T
– V = [v1,…,vN]T
- Sau đó chúng ta tính toán tất cả truy vấn cùng một lúc:

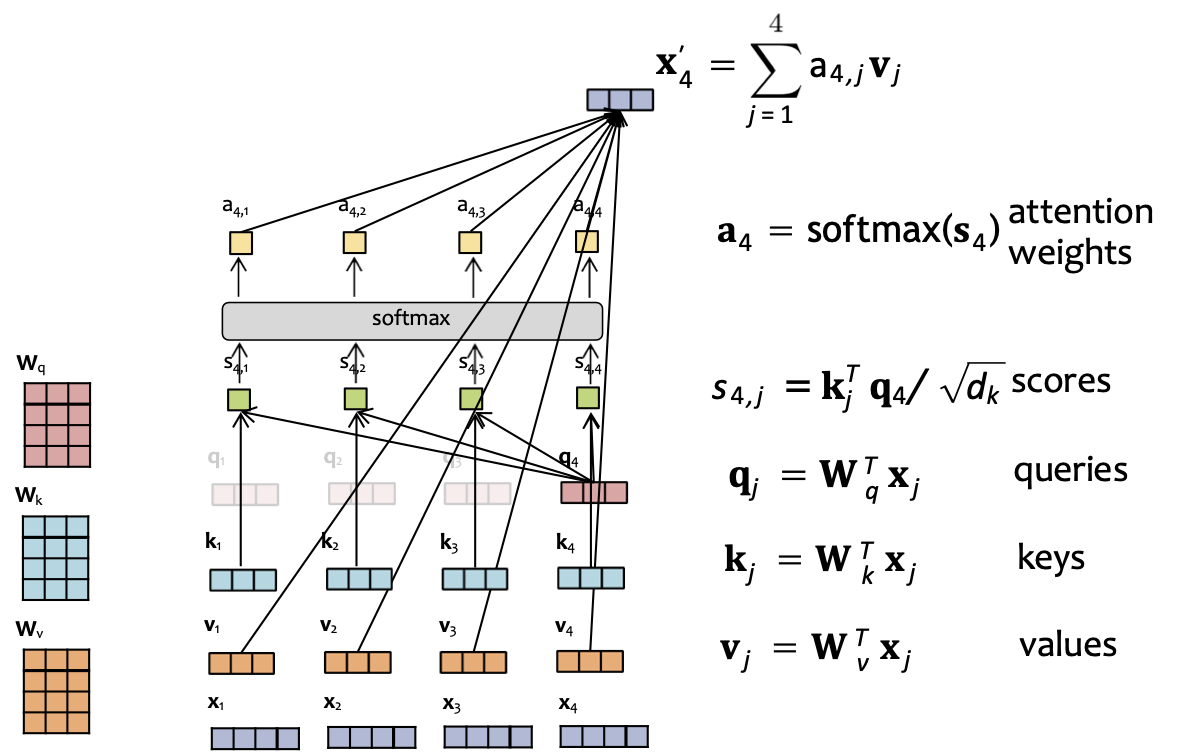
Trong thực tế, trọng số attention được tính toán cho mọi bước thời điểm T, sau đó chúng ta che giấu (bằng cách thiết lập thành –inf) tất cả các đầu vào softmax dành cho các bước thời gian ở bên phải truy vấn.
HỌC TRANSFORMER LM
Học một mô hình ngôn ngữ sâu
- Mỗi ví dụ đào tạo là một chuỗi (ví dụ câu), vì vậy chúng ta có dữ liệu đào tạo D = {w(1), w(2), …, w(N)}
- Hàm mục tiêu cho một LM sâu (ví dụ RNN-LM hoặc Tranformer-LM) thường là log-khả năng ví dụ đào tạo:
J(θ) = 𝛴i log pθ(w(i))
- Chúng ta đào tạo theo từng đợt nhỏ SGD (hoặc biến thể của mini-batch SGD bạn thích)
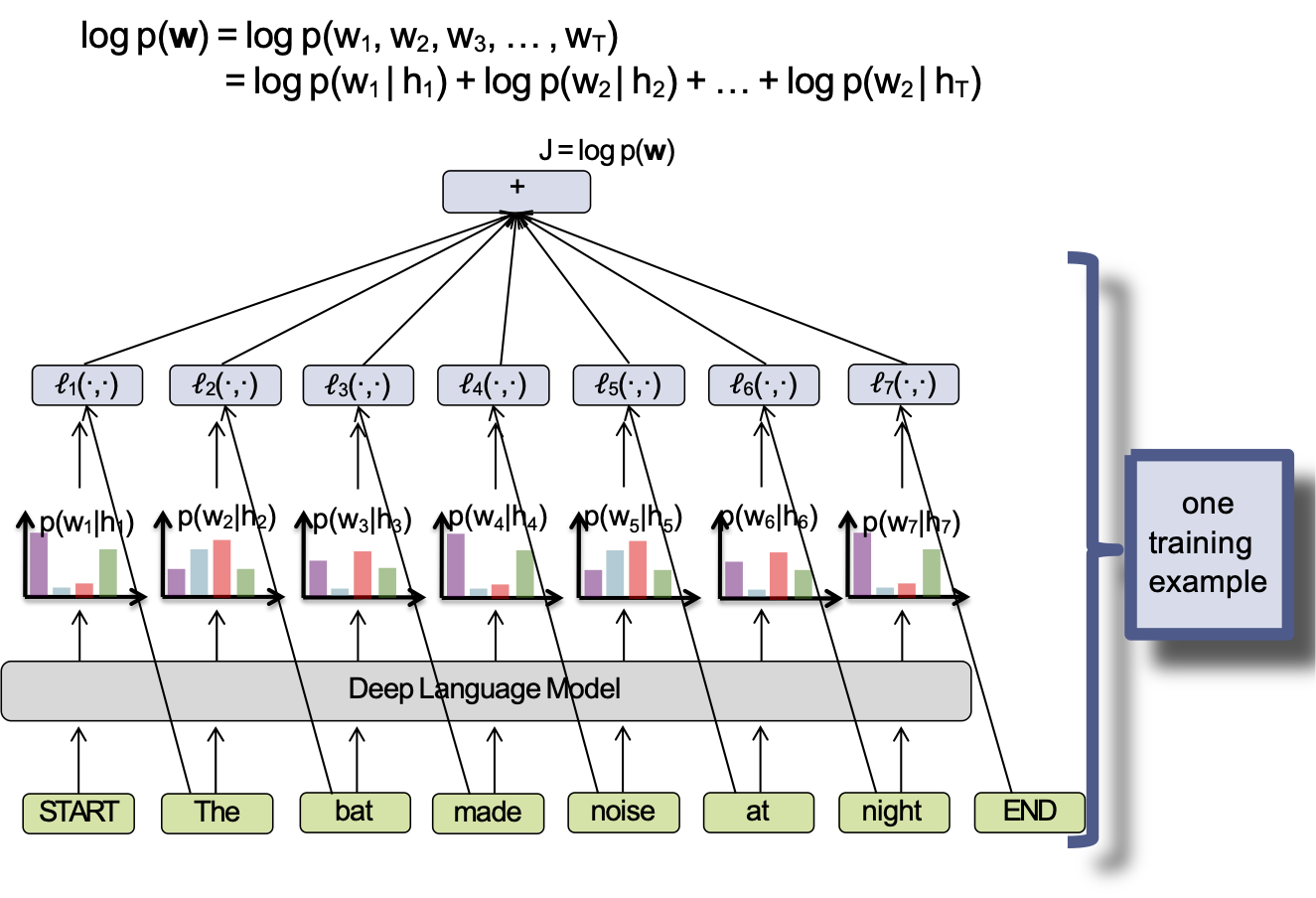
một ví dụ đào tạo
Học mô hình ngôn ngữ Transformer
- Mỗi ví dụ đào tạo là một chuỗi (ví dụ câu), vì vậy chúng ta có dữ liệu đào tạo D = {w(1), w(2), …, w(N)}
- Hàm mục tiêu cho một LM sâu (ví dụ RNN-LM hoặc Tranformer-LM) thường là log-khả năng ví dụ đào tạo:
J(θ) = 𝛴i log pθ(w(i))
- Chúng ta đào tạo theo từng đợt nhỏ SGD (hoặc biến thể của mini-batch SGD bạn thích)
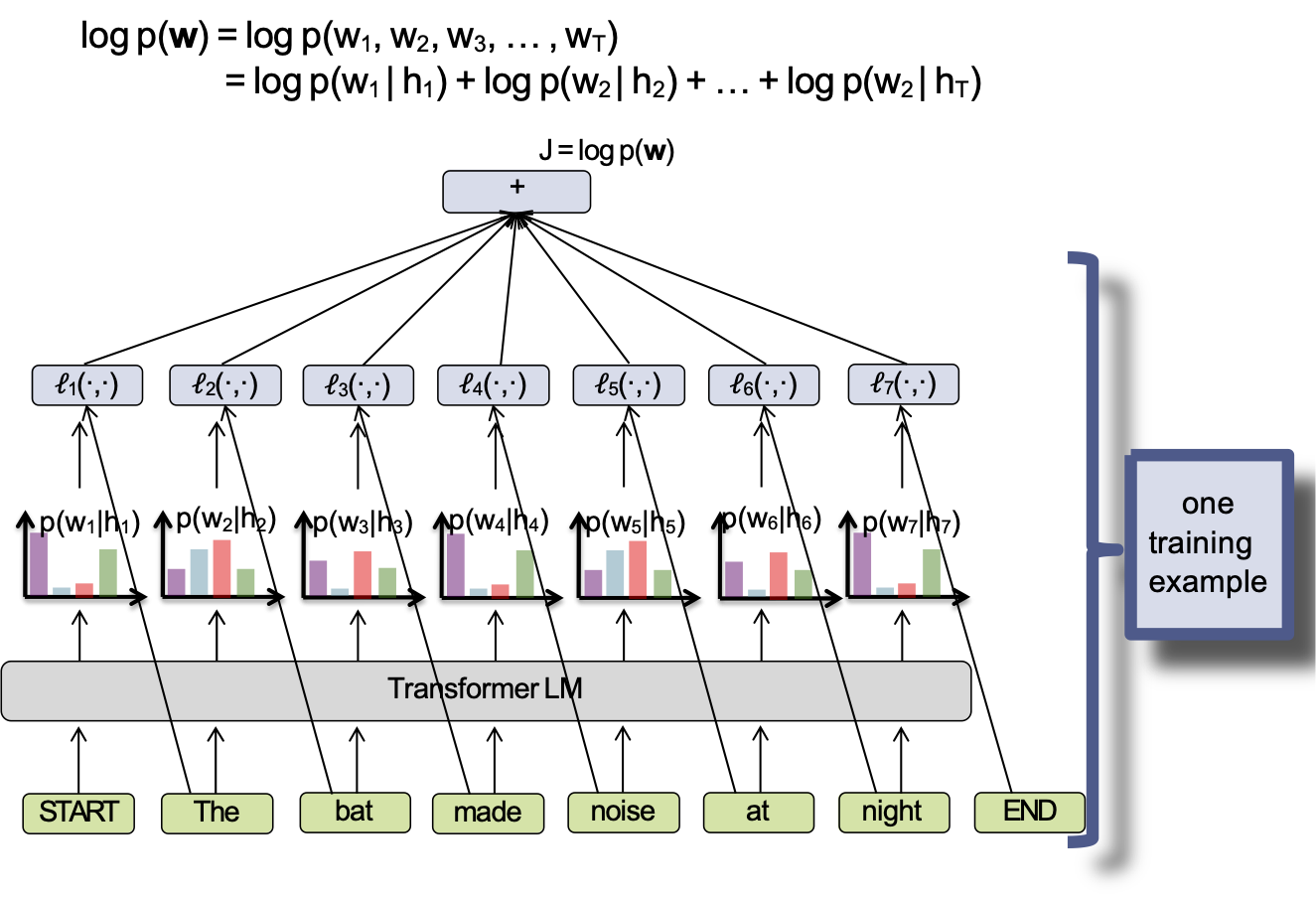
một ví dụ đào tạo
Mô hình hóa ngôn ngữ
Một điều nữa:
- Các mô hình ngôn ngữ hiện đại hiện nay có xu hướng dựa vào mạng lưới transformer (ví dụ GPT-2)
- RNN-LM bao gồm hầu hết các LM thần kinh ban đầu dẫn đến kiến trúc SOTA hiện tại
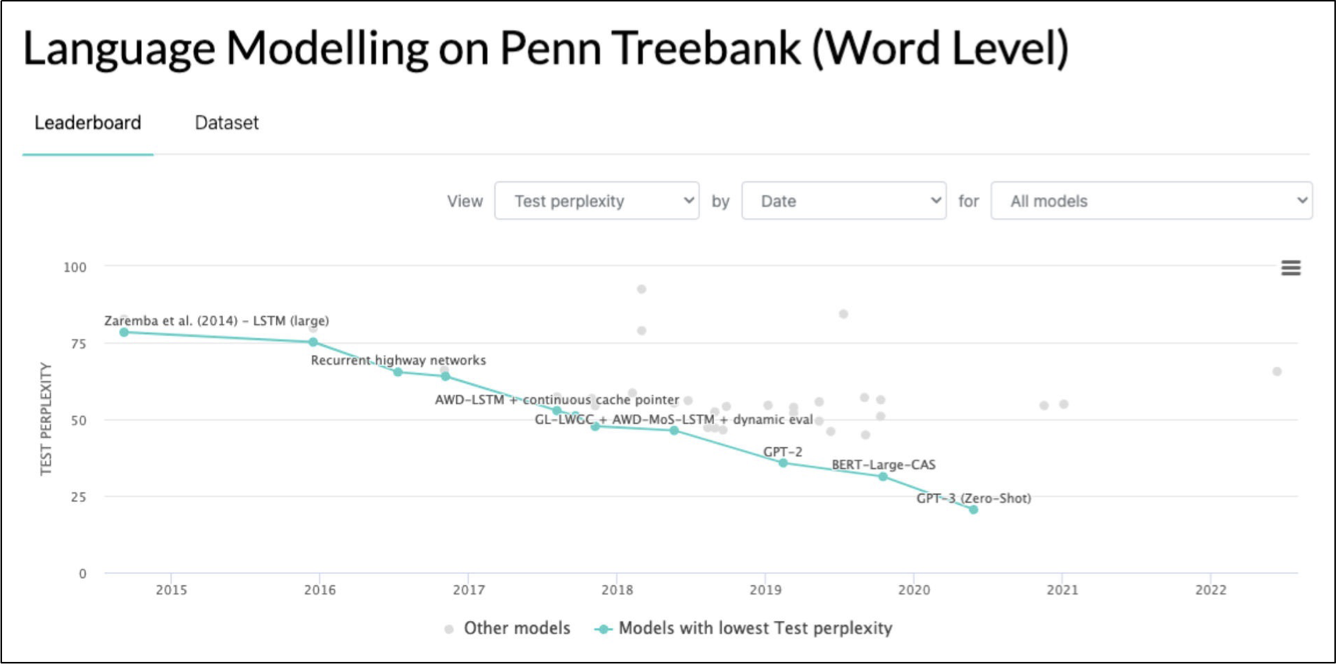
Hình ảnh từ https://paperswithcode.com/sota/language-modelling-on-penn-treebank-word
Tại sao hiệu quả lại quan trọng?
Nghiên cứu tình huống: GPT-3
- # token đào tạo = 500 tỷ
- # tham số = 175 tỷ
- Số chu kỳ = 50 petaflop/s-ngày (mỗi chu kỳ là 8,64e+19 flop)
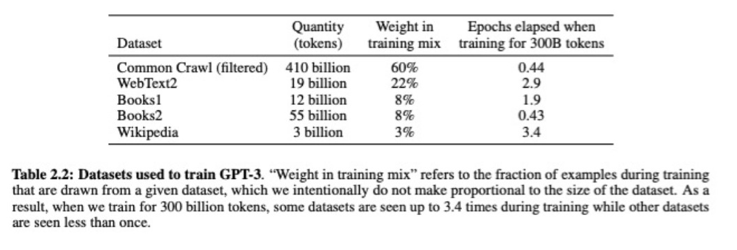
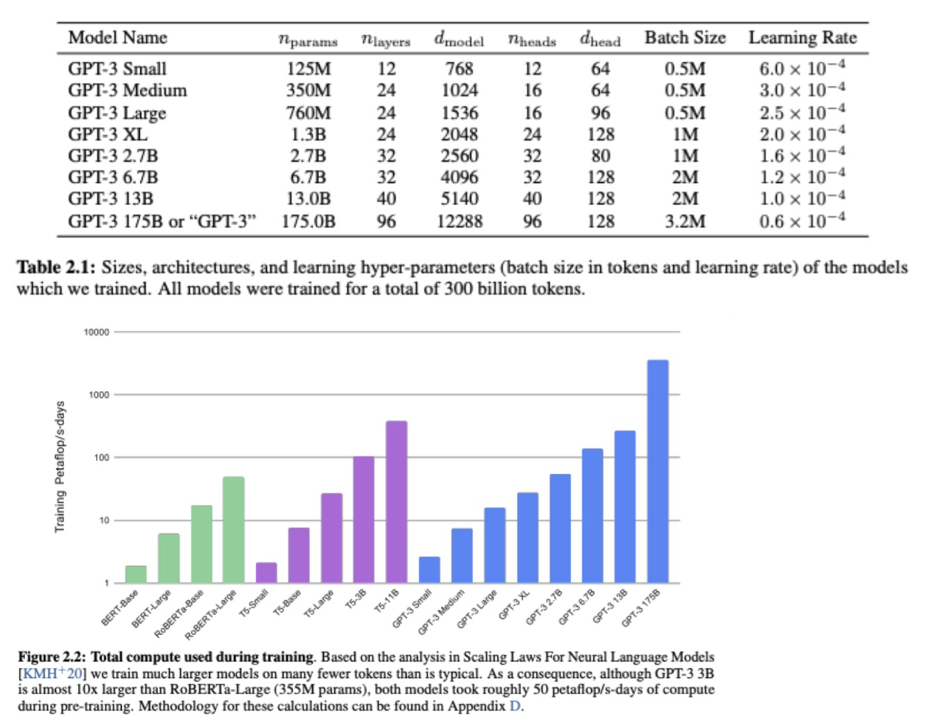
Hình từ https://arxiv.org/pdf/2005.14165.pdf
Bản tóm tắt
- Nhiệm vụ: Mô hình hóa ngôn ngữ
– mô hình kênh nhiễu (nói / MT)
– (lịch sử) LM lớn (mô hình n-gram)
- Mô hình: GPT
– Attention (đồ thị tính toán)
– Transformer-LM (so sánh với RNN-LM)
- Học tập cho LLM
– Đào tạo trước (học không giám sát)
– Học tăng cường với phản hồi của con người (học sâu)
- Tối ưu hóa cho LLM
– Adam (so sánh với SGD)
– Đào tạo phân tán
- Tác động xã hội của LLM