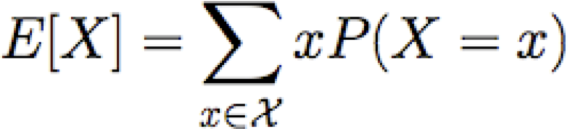Hôm nay:
- Bức tranh lớn
- Khớp quá mức
- Ôn tập: xác suất
Bài đọc:
Decision trees, overfiting
- Mitchell, Chương 3
Xem lại xác suất
- Bishop Ch. 1 đến 1.2.3
- Bishop, Ch. 2 đến 2.2
- Hướng dẫn trực tuyến của Andrew Moore
Xấp xỉ hàm:
Đặt vấn đề:
- Tập hợp các thể hiện X
- Hàm mục tiêu chưa xác định f : X→Y
- Tập các giả thuyết hàm H={ h | h : X→Y }
Đầu vào:
- Ví dụ huấn luyện {<x(i),y(i)>} của hàm đích f chưa biết
Đầu ra:
- Giả thuyết h ∈ H gần đúng nhất với hàm mục tiêu f
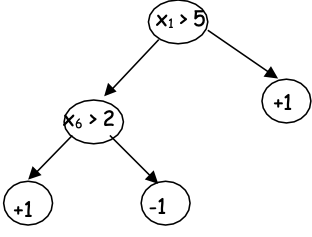
Xấp xỉ hàm: Học cây quyết định
Đặt vấn đề:
- Tập hợp các thể hiện X
- mỗi trường hợp x trong X là một vectơ đặc trưng x = < x1, x2 … xn>
- Hàm mục tiêu chưa xác định f : X→Y
- Y là giá trị rời rạc
- Tập các giả thuyết hàm H={ h | h : X→Y }
- mỗi giả thuyết h là một cây quyết định
Đầu vào:
- Ví dụ huấn luyện {<x(i),y(i)>} của hàm đích f chưa biết
Đầu ra:
- Giả thuyết h ∈ H gần đúng nhất với hàm mục tiêu f
Xấp xỉ hàm là Tìm kiếm giả thuyết tốt nhất
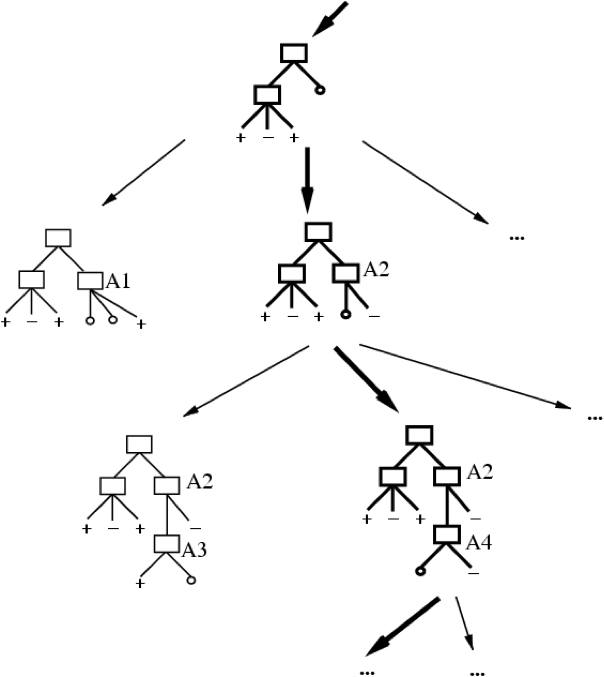
- ID3 thực hiện tìm kiếm heuristic trong không gian cây quyết định
Xấp xỉ hàm: Bức tranh toàn cảnh
Chúng ta nên xuất cây nào?
- ID3 thực hiện tìm kiếm heuristic trong không gian cây quyết định
- Nó dừng lại ở cây nhỏ nhất chấp nhận được. Tại sao?
Dao cạo của Occam: thích giả thuyết đơn giản nhất phù hợp với dữ liệu
Tại sao thích các giả thuyết ngắn? (Dao cạo của Occam)
Lập luận ủng hộ:
Lập luận phản đối:
Tại sao thích các giả thuyết ngắn? (Dao cạo của Occam)
Lập luận ủng hộ:
- Ít giả thuyết ngắn hơn giả thuyết dài
- → một giả thuyết ngắn phù hợp với dữ liệu ít có khả năng một sự trùng hợp thống kê
Lập luận phản đối:
- Cũng có ít giả thuyết hơn chứa số nguyên tố các nút và thuộc tính bắt đầu bằng “Z”
- Các giả thuyết “ngắn” có gì đặc biệt, thay vì “số nguyên tố của các nút và các cạnh”?
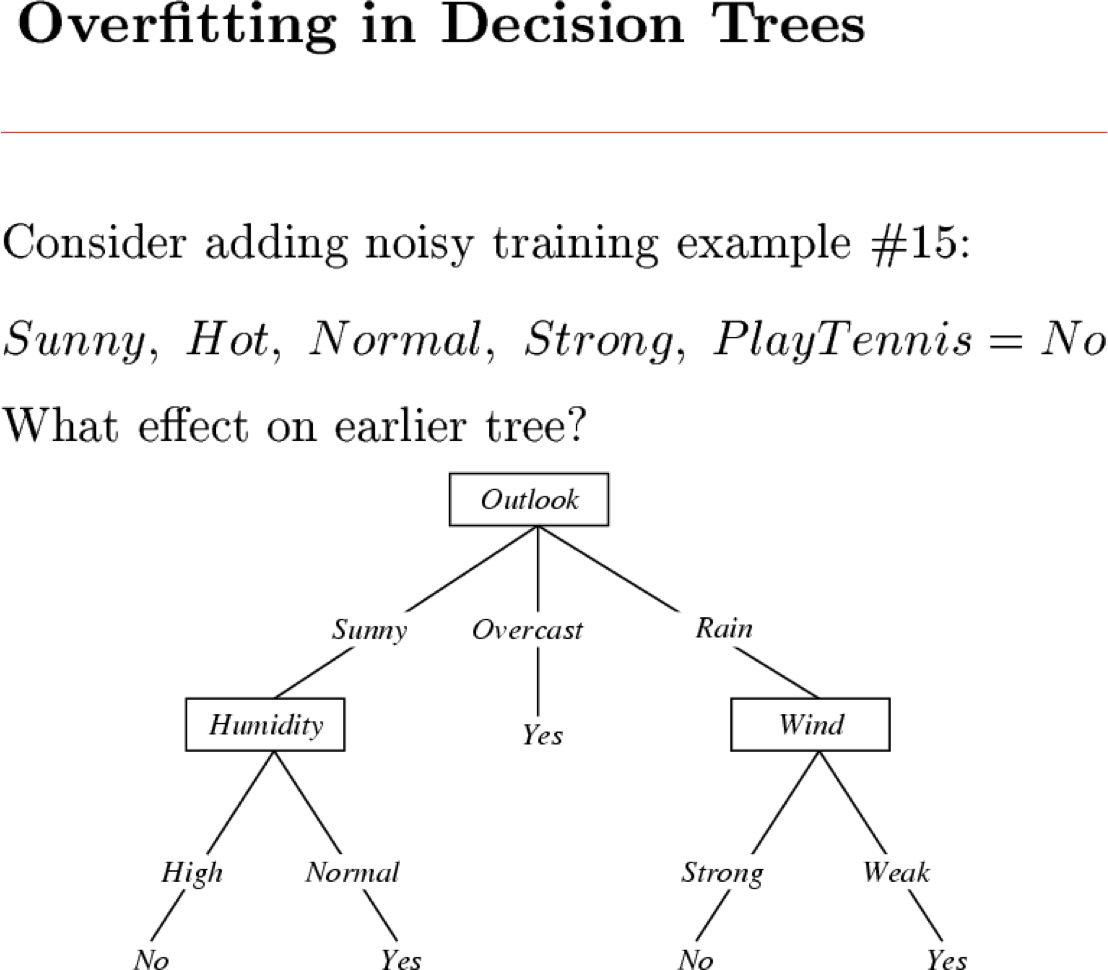
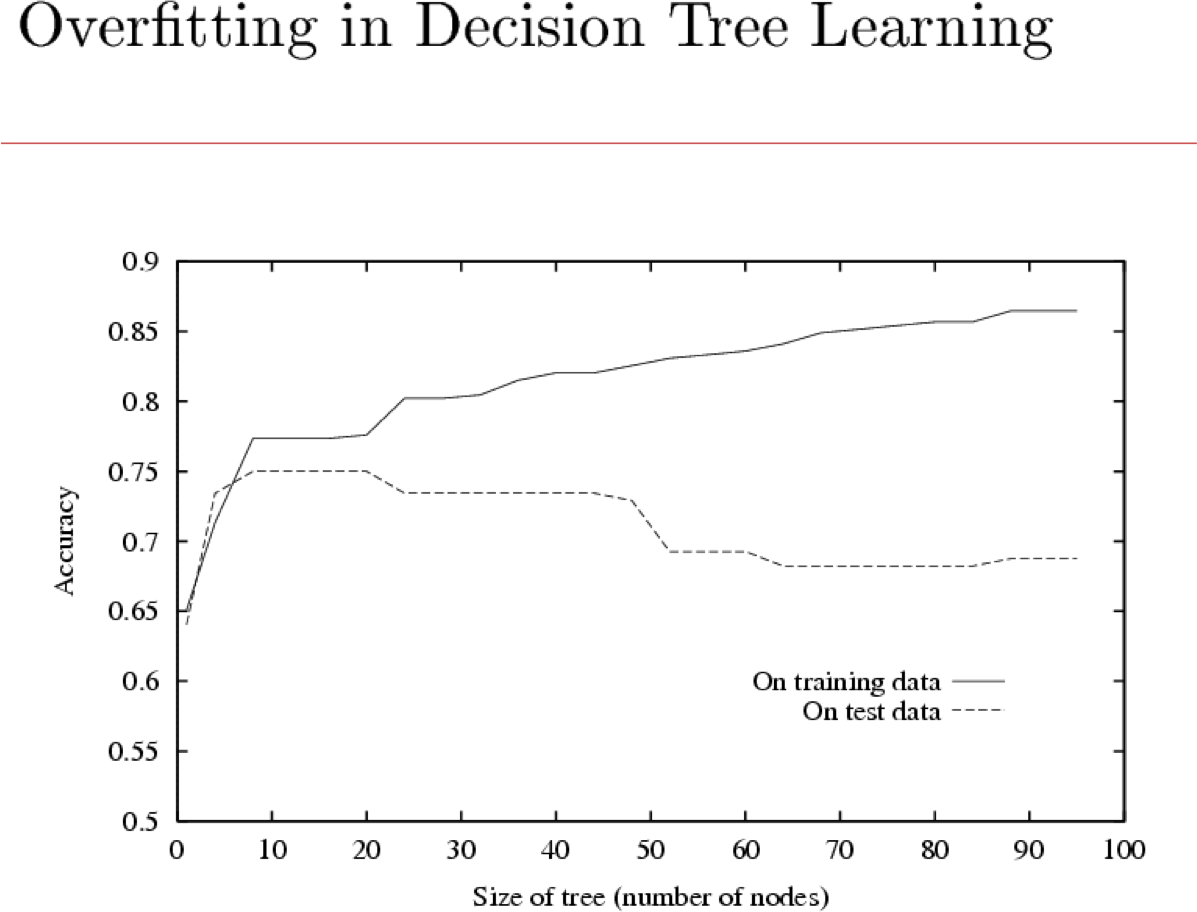
Khớp quá mức
Hãy xem xét một giả thuyết h và của nó
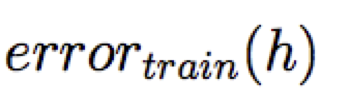
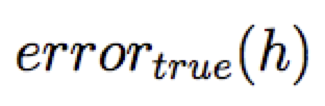
Khớp quá mức
Hãy xem xét một giả thuyết h và của nó
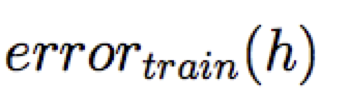
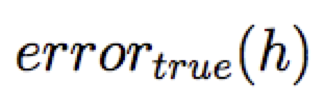
Ta nói h quá khớp với dữ liệu huấn luyện nếu
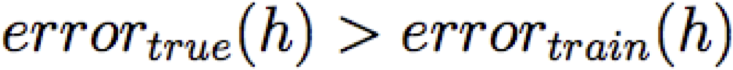
Số lượng khớp quá mức =
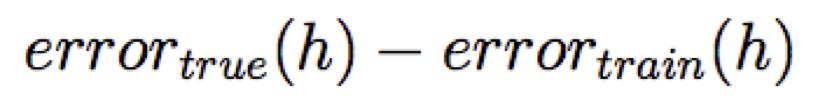


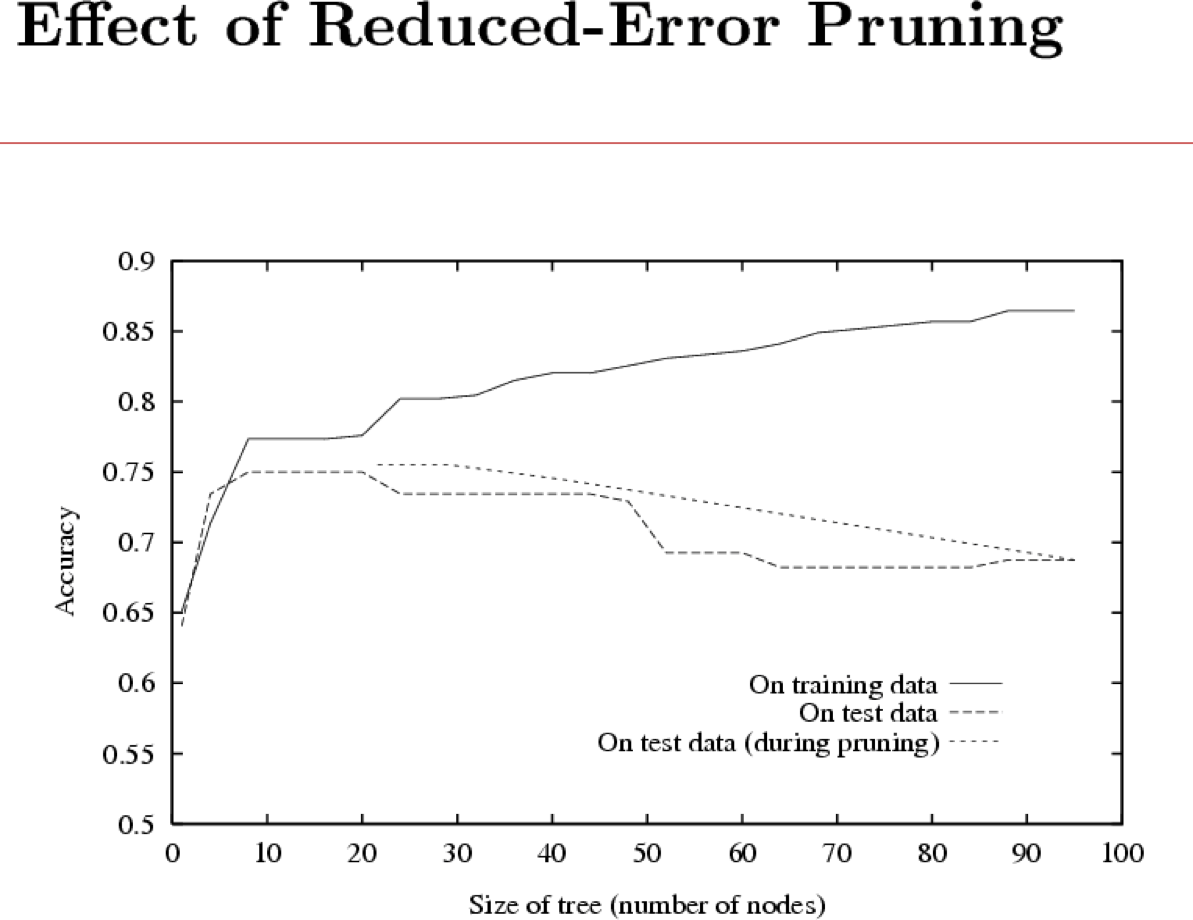
Học cây quyết định, bảo đảm chính thức
Học có giám sát hoặc Xấp xỉ hàm
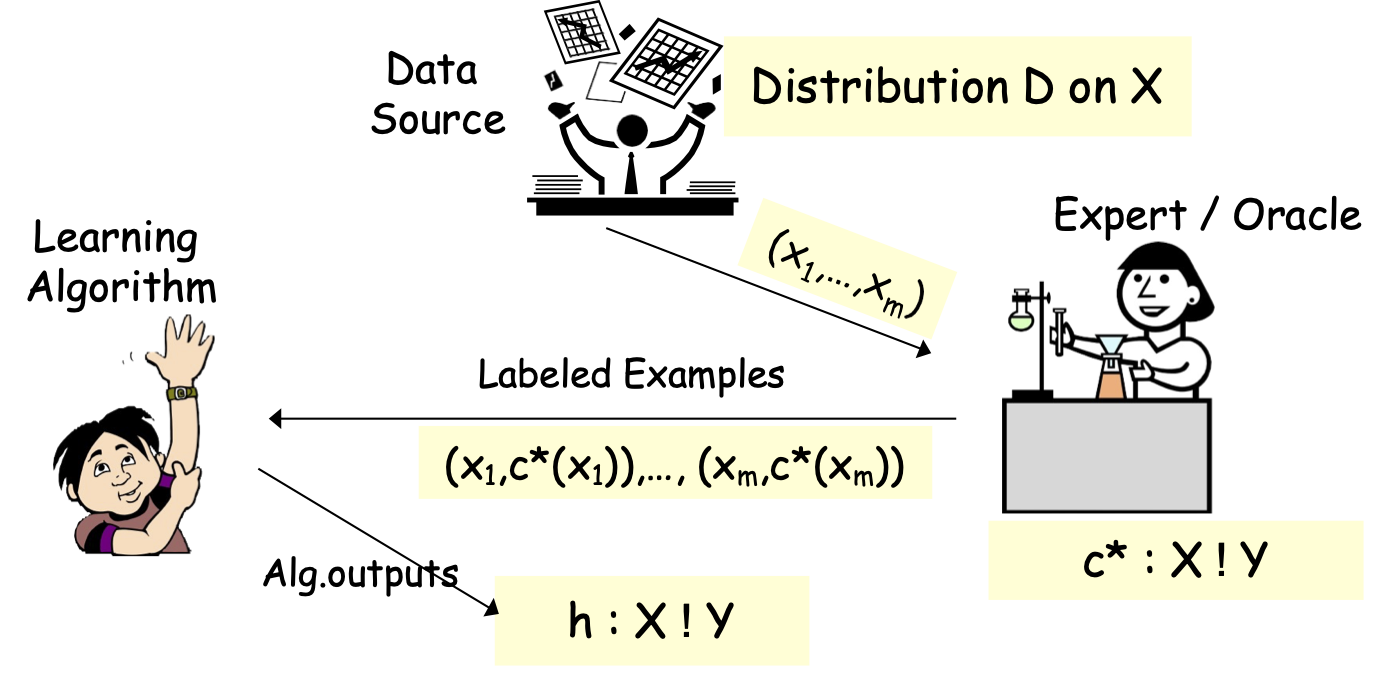
Học có giám sát hoặc Xấp xỉ hàm
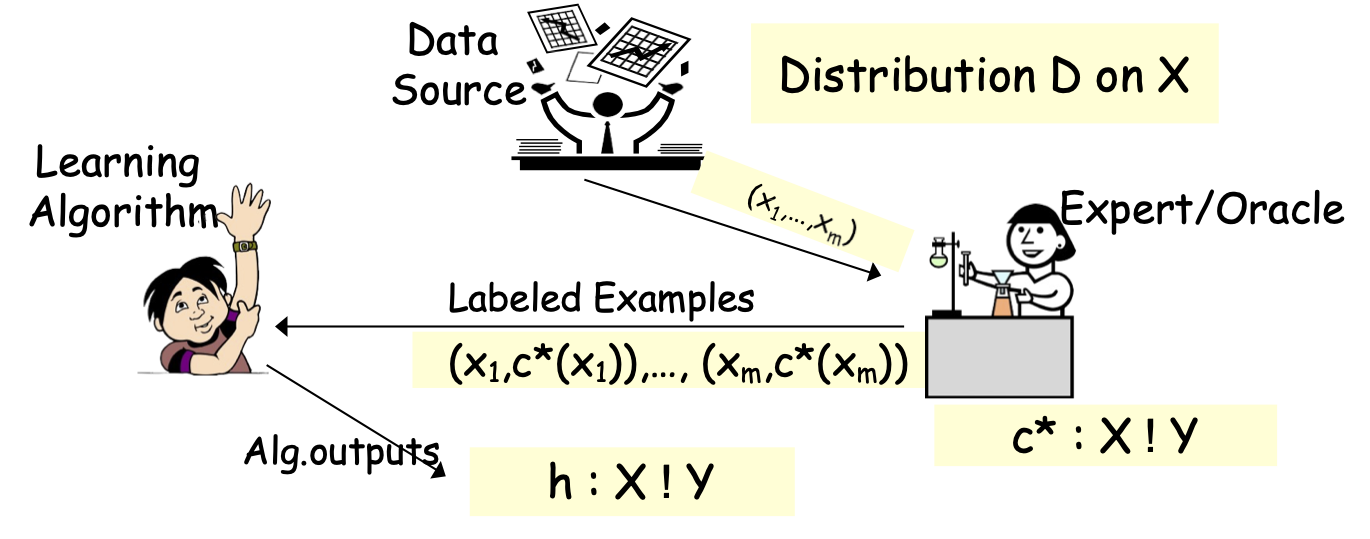
- Thuật toán xem mẫu huấn luyện S: (x1,c*(x1)),…, (xm,c*(xm)), xi iid từ D
- Tối ưu hóa trên S, tìm giả thuyết h (ví dụ: cây quyết định).
- Mục tiêu: h mắc lỗi nhỏ trên D.
err(h)=Prx 2 D(h(x) ≠ c*(x))
Hai khía cạnh cốt lõi của học máy
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
(Gắn nhãn) Dữ liệu
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc trên dữ liệu trong tương lai.
- Hiểu rất rõ: ràng buộc Occam, lý thuyết VC, v.v.
- Cây quyết định: nếu chúng ta có thể tìm thấy một cây quyết định nhỏ mà giải thích dữ liệu tốt, sau đó đảm bảo khái quát hóa tốt.

Thuật toán cây quyết định từ trên xuống
- Cây quyết định: nếu chúng ta có thể tìm thấy một cây quyết định nhỏ phù hợp với dữ liệu, thì đảm bảo khái quát hóa tốt.

- Rất tốt heuristics thực tế; thuật toán từ trên xuống, ví dụ: ID3
- Cách tiếp cận tham lam tự nhiên nơi chúng ta phát triển cây từ gốc đến lá bằng cách liên tục thay thế một lá hiện có bằng một nút bên trong.

Entropy như một biện pháp phân tách tốt hơn
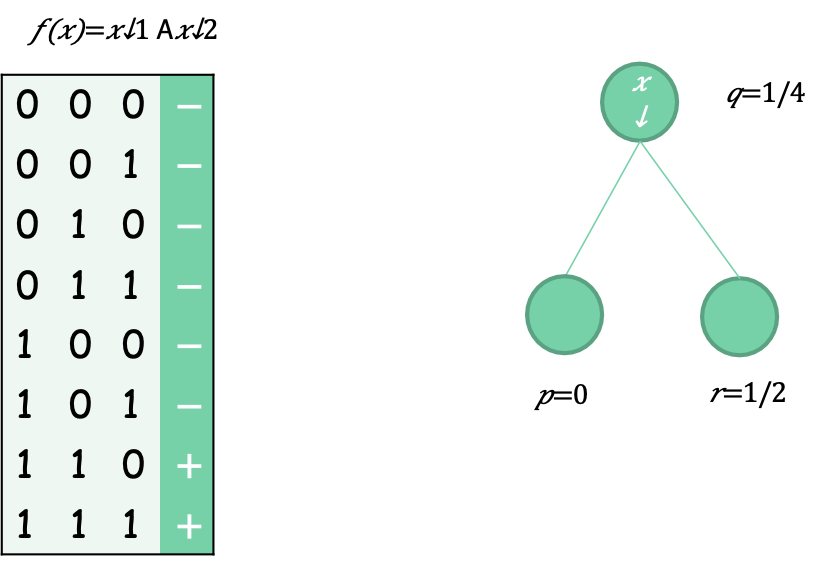
Tỷ lệ lỗi ban đầu là 1/4 (25% dương, 75% âm)
Tỷ lệ lỗi sau khi tách là 0.5∗0+0.5∗0.5=1/4 (lá bên trái là 100% âm; lá bên phải là 50/50)
Nhìn chung lỗi không giảm!
Entropy như một biện pháp phân tách tốt hơn
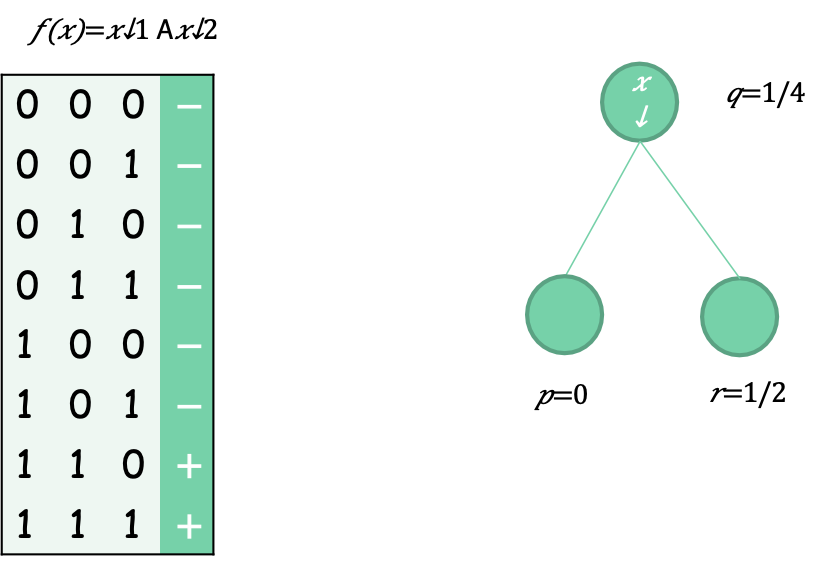
Entropy ban đầu là 1/4 ( log↓2 1/4)+ 3/4 ( log↓2 3/4 )=0.81
Entropy sau khi chia là 1/2 ∗0+1/2 ∗1=0.5
Entropy giảm!
Thuật toán cây quyết định từ trên xuống
- Cách tiếp cận tham lam tự nhiên nơi chúng ta phát triển cây từ gốc đến lá bằng cách liên tục thay thế một lá hiện có bằng một nút bên trong.

- [Kearns-Mansour’96]: nếu thước đo tiến độ là entropy, chúng ta có thể luôn đảm bảo thành công dưới một số mối quan hệ chính thức giữa loại phân tách và mục tiêu (loại phân tách có thể xấp xỉ yếu hàm mục tiêu).
- Cung cấp một cách suy nghĩ về hiệu quả của các thuật toán từ trên xuống khác nhau.
Thuật toán cây quyết định từ trên xuống
- Key: độ lõm mạnh của tiêu chí phân tách
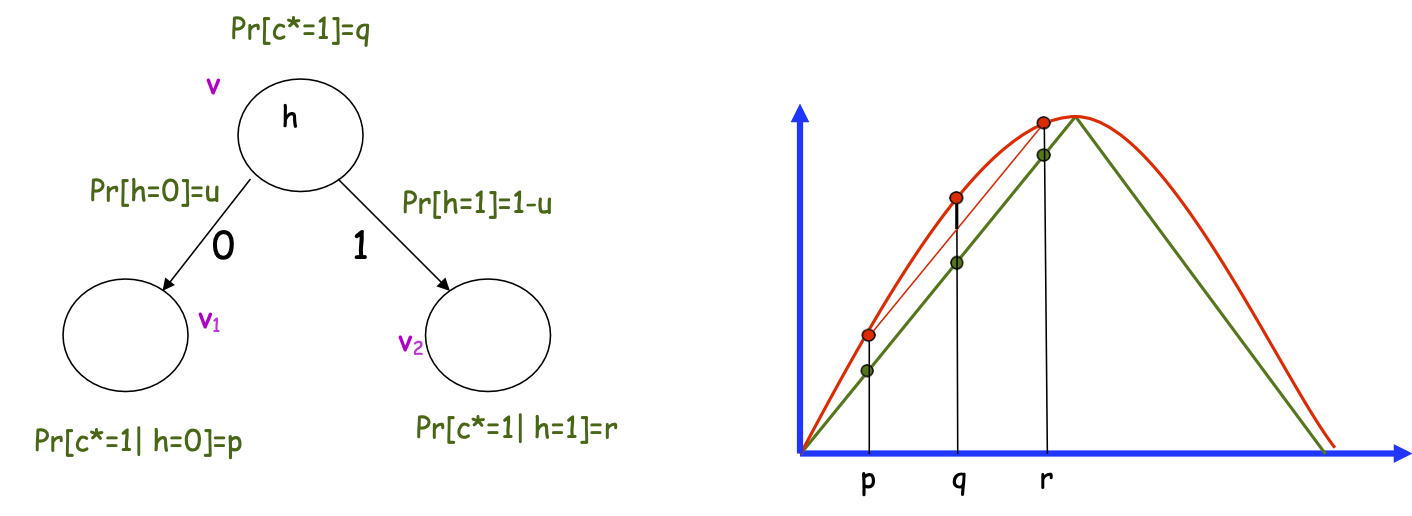
- q=up + (1-u) r. Muốn cận dưới: G(q) – [uG(p) + (1-u)G(r)]
- Nếu: G(q) =min(q,1-q) (tỷ lệ lỗi), thì G(q) = uG(p) + (1-u)G(r)
- Nếu: G(q) =H(q) (entropy), thì G(q) – [uG(p) + (1-u)G(r)] >0 nếu r-p>0 và u ≠1, u ≠0 (điều này xảy ra theo giả định học tập yếu)
Hai khía cạnh cốt lõi của học máy
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
(Gắn nhãn) Dữ liệu
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc trên dữ liệu trong tương lai.
Bạn nên biết điều gì:
- Các bài toán xấp xỉ hàm tốt:
- Không gian thể hiện, X
- Mẫu dữ liệu huấn luyện có nhãn { <x(i), y(i)>}
- Không gian giả thuyết, H = { f: X→Y }
- Học tập là vấn đề tìm kiếm/tối ưu hóa trên H
- Các hàm mục tiêu khác nhau
- giảm thiểu lỗi huấn luyện (mất mát 0-1)
- trong số các giả thuyết giảm thiểu sai số huấn luyện, chọn nhỏ nhất (?)
- Nhưng học quy nạp mà không có một số thiên vị là vô ích!
- Các hàm mục tiêu khác nhau
- Học cây quyết định
- Greedy top-down learning của cây quyết định (ID3, C4.5,…)
- Khớp quá mức và cắt tỉa cây sau khi cắt tỉa
- Phần mở rộng…
Slide bổ sung
Phần mở rộng cho việc học cây quyết định




Câu hỏi suy nghĩ (1)
- ID3 và C4.5 là các thuật toán heuristic tìm kiếm trong không gian của cây quyết định. Tại sao không chỉ làm một tìm kiếm toàn diện?
Câu hỏi suy nghĩ (2)
- Xét hàm mục tiêu f: <x1,x2> → y, trong đó x1 và x2 có giá trị thực, y là boolean. Tập hợp các bề mặt quyết định là gì có thể mô tả được với các cây quyết định sử dụng mỗi thuộc tính nhiều nhất một lần?
Câu hỏi suy nghĩ (3)
- Tại sao sử dụng Information Gain để chọn thuộc tính trong cây quyết định? Những tiêu chí nào khác dường như hợp lý, và những gì là sự đánh đổi trong đưa ra lựa chọn này?
Câu hỏi suy nghĩ (4)
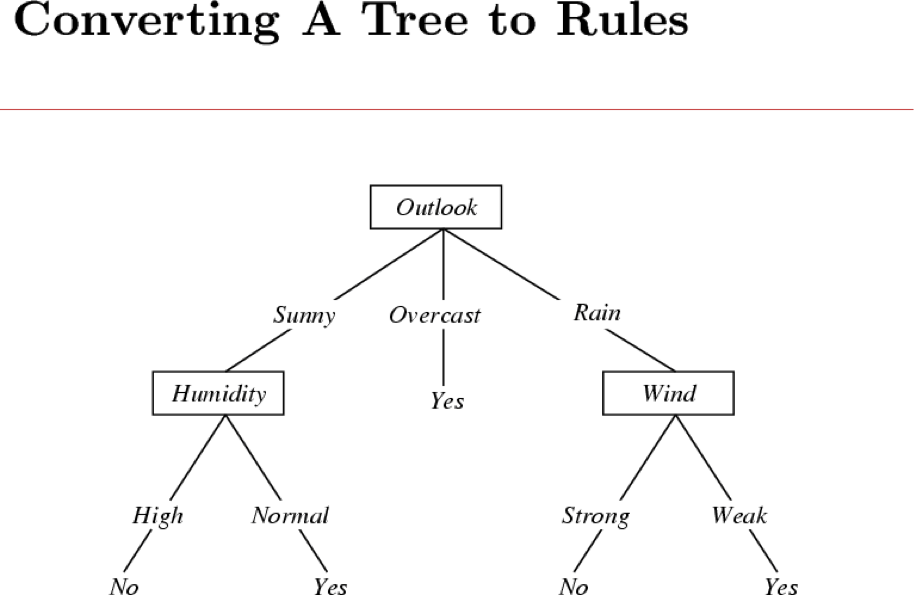
- Mối quan hệ giữa việc học cây quyết định và việc học các quy tắc IF-THEN là gì

Hôm nay:
- Ôn tập: xác suất
Bài đọc:
Xem lại xác suất
- Bishop Ch. 1 đến 1.2.3
- Bishop, Ch. 2 đến 2.2
- Hướng dẫn trực tuyến của Andrew Moore
nhiều trong số các slide này là bắt nguồn từ William Cohen, Andrew Moore, Aarti Singh, Eric Xing. Cảm ơn!
Tổng quan về xác suất
- Sự kiện
- biến ngẫu nhiên rời rạc, biến ngẫu nhiên liên tục, sự kiện phức hợp
- Tiên đề xác suất
- Điều gì định nghĩa một lý thuyết hợp lý về sự không chắc chắn
- Sự kiện độc lập
- Xác suất có điều kiện
- Quy tắc Bayes và niềm tin
- Phân phối xác suất đồng thời
- Kỳ vọng
- Độc lập, Độc lập có điều kiện
Biến ngẫu nhiên
- Một cách không chính thức, A là một biến ngẫu nhiên nếu
- A biểu thị một cái gì đó mà chúng ta không chắc chắn
- có lẽ là kết quả của một thí nghiệm ngẫu nhiên
- Ví dụ
- A = True nếu một người được chọn ngẫu nhiên từ lớp của chúng ta là nữ
- A = Quê hương của một người được chọn ngẫu nhiên từ lớp của chúng ta
- A = True nếu hai người được chọn ngẫu nhiên từ lớp của chúng ta có cùng ngày sinh
- Định nghĩa P(A) là “phần nhỏ của các thế giới khả dĩ mà A True” hoặc “phần nhỏ số lần A giữ được, trong các lần lặp lại thí nghiệm ngẫu nhiên”
- tập hợp các thế giới khả dĩ được gọi là không gian mẫu, S
- Biến ngẫu nhiên A là hàm xác định trên S
A: S → {0,1}
Một chút chủ nghĩa hình thức
Chính thức hơn, chúng ta có
- không gian mẫu S (ví dụ: tập sinh viên trong lớp của chúng ta)
- hay còn gọi là tập hợp các thế giới có thể
- biến ngẫu nhiên là hàm xác định trên không gian mẫu
- Giới tính: S → { m, f }
- Chiều cao: S → Real
- một biến cố là tập con của S
- ví dụ, tập hợp con của S mà Giới tính=f
- ví dụ: tập hợp con của S mà (Giới tính=m) AND (màu mắt=xanh lam)
- chúng ta thường quan tâm đến xác suất của các sự kiện cụ thể
- và của các sự kiện cụ thể có điều kiện dựa trên các sự kiện cụ thể khác
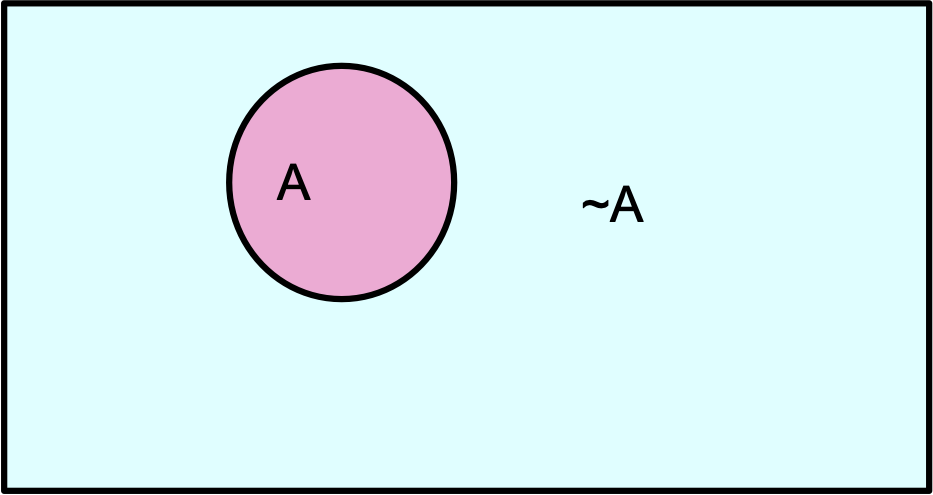
Hình dung A
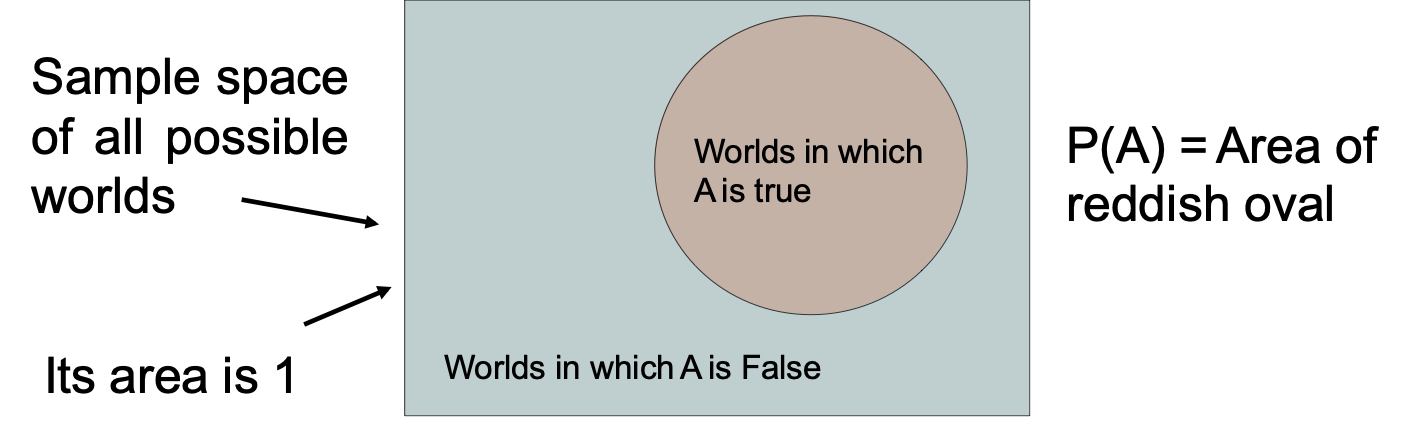
- Không gian mẫu của tất cả thế giới có thể
- Diện tích của nó là 1
- Thế giới trong đó A là True
- Thế giới trong đó A là False
- P(A) = Diện tích của hình bầu dục màu đỏ
Tiên đề xác suất
- 0 <= P(A) <= 1
- P(True) = 1
- P(False) = 0
- P(A hoặc B) = P(A) + P(B) – P(A và B)
[di Finetti 1931]:
khi đánh bạc dựa trên “chủ nghĩa hình thức không chắc chắn A”, bạn có thể bị đối thủ lợi dụng
nếu
chủ nghĩa hình thức không chắc chắn của bạn A vi phạm các tiên đề này
Xác suất sơ cấp trong hình ảnh
- P(~A) + P(A) = 1
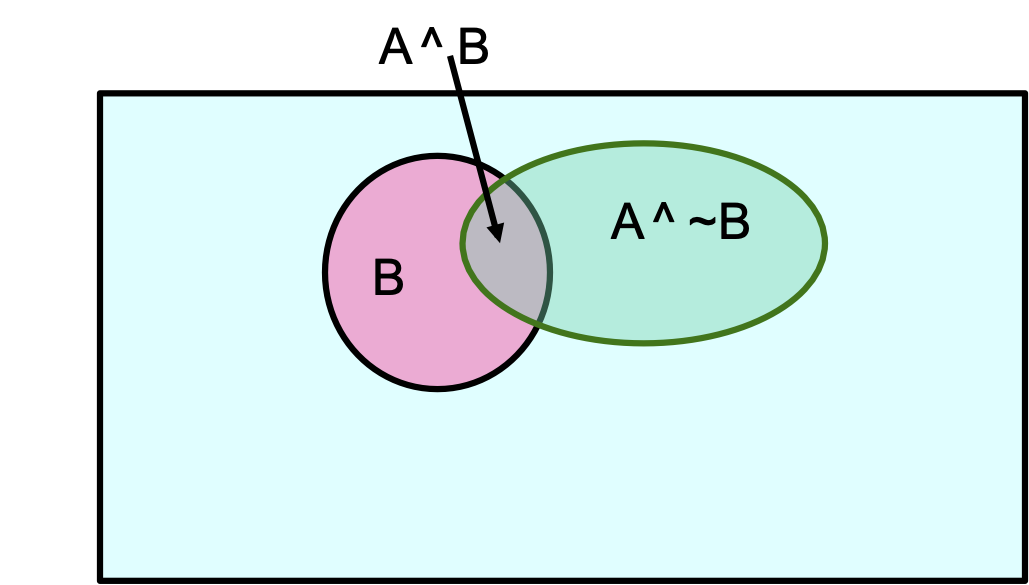
Một định lý hữu ích
- 0 <= P(A) <= 1, P(True) = 1, P(False) = 0, P(A hoặc B) = P(A) + P(B) – P(A và B)
- → P(A) = P(A ^ B) + P(A ^ ~B)
A = [A và (B hoặc ~B)] = [(A và B) hoặc (A và ~B)]
P(A) = P(A và B) + P(A và ~B) – P((A và B) và (A và ~B))
P(A) = P(A và B) + P(A và ~B) – P(A và B và A và ~B)
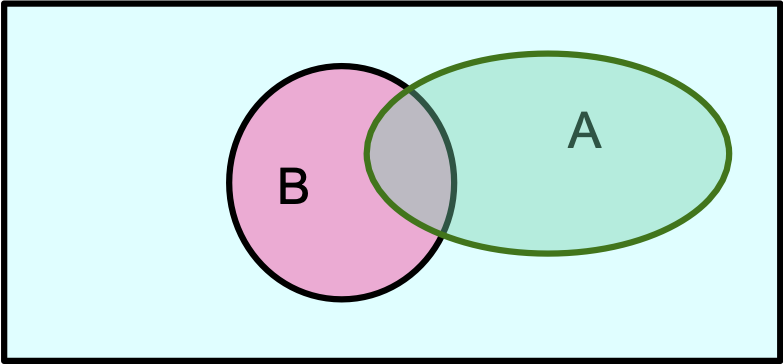
Xác suất sơ cấp trong hình ảnh
- P(A) = P(A ^ B) + P(A ^ ~B)
Định nghĩa xác suất có điều kiện
P(A|B) = P(A ^ B)⁄P(B)
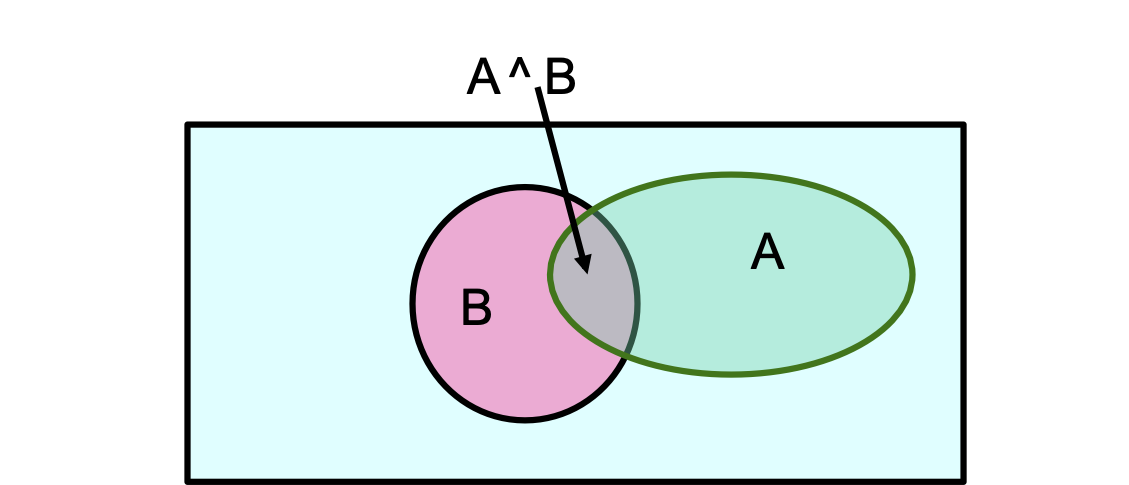
Định nghĩa xác suất có điều kiện
P(A|B) = P(A ^ B)⁄P(B)
Hệ quả: Quy tắc dây chuyền
P(A ^ B) = P(A|B) P(B)
Quy tắc Bayes
- hãy viết 2 biểu thức cho P(A ^ B)
Quy tắc Bayes
Quy tắc Bayes
P(A|B) = P(B|A) * P(A)⁄P(B)
chúng ta gọi P(A) là “tiên nghiệm”
và P(A|B) là “hậu nghiệm”

Bayes, Thomas (1763) Một tiểu luận hướng tới giải quyết một vấn đề trong học thuyết cơ hội. Giao dịch triết học của Hiệp hội Hoàng gia Luân Đôn, 53:370-418
…không có nghĩa là chỉ là một suy đoán tò mò trong học thuyết về cơ hội, nhưng cần thiết phải được giải quyết để có một nền tảng chắc chắn cho tất cả chúng ta lý luận liên quan đến các sự kiện trong quá khứ, và những gì có khả năng xảy ra sau đó….
cần thiết để được xem xét bởi bất kỳ điều gì sẽ đưa ra một tài khoản rõ ràng về sức mạnh của suy luận loại suy hoặc quy nạp…
Các hình thức khác của Quy tắc Bayes
P(A|B) =P(B| A)P(A)⁄P(B| A)P(A) + P(B|~ A)P(~ A)
P(A |B ∧ X ) = P(B | A ∧ X )P(A ∧ X )⁄P(B ∧ X )
Áp dụng quy tắc Bayes
P(A |B) = P(B | A)P(A)⁄P(B | A)P(A) + P(B |~ A)P(~ A)
A = bạn bị cúm, B = bạn chỉ ho
Giả định:
P(A) = 0,05
P(B|A) = 0,80
P(B| ~A) = 0,2
P(cúm | ho) = P(A|B) là gì?
tất cả những điều này có liên quan gì xấp xỉ hàm?
Phân phối đồng thời
Công thức làm phân phối đồng thời của M biến:
Ví dụ: Biến Boolean A, B, C
Phân phối đồng thời
Công thức làm phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả tổ hợp các giá trị của các biến của bạn (nếu có M biến Boolean thì bảng sẽ có 2M hàng).
Ví dụ: Biến Boolean A, B, C
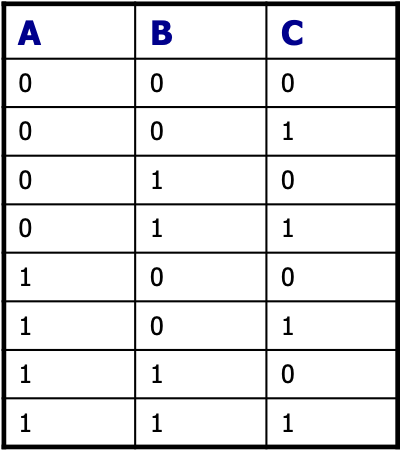
Phân phối đồng thời
Công thức làm phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả tổ hợp các giá trị của các biến của bạn (nếu có M biến Boolean thì bảng sẽ có 2M hàng).
- Đối với mỗi sự kết hợp của các giá trị, hãy cho biết mức độ nó có thể xảy ra.
Ví dụ: Biến Boolean A, B, C
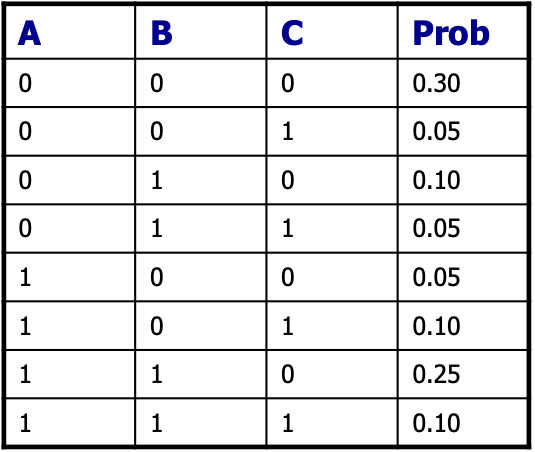
Phân phối đồng thời
Công thức làm phân phối đồng thời của M biến:
- Lập bảng chân lý liệt kê tất cả tổ hợp các giá trị của các biến của bạn (nếu có M biến Boolean thì bảng sẽ có 2M hàng).
- Đối với mỗi sự kết hợp của các giá trị, hãy cho biết mức độ nó có thể xảy ra.
- Nếu bạn tin vào tiên đề xác suất, những con số đó phải có tổng bằng 1.

Sử dụng Phân phối Đồng thời
Một khi bạn có JD, bạn có thể yêu cầu xác suất của bất kỳ biểu thức logic nào liên quan đến thuộc tính của bạn
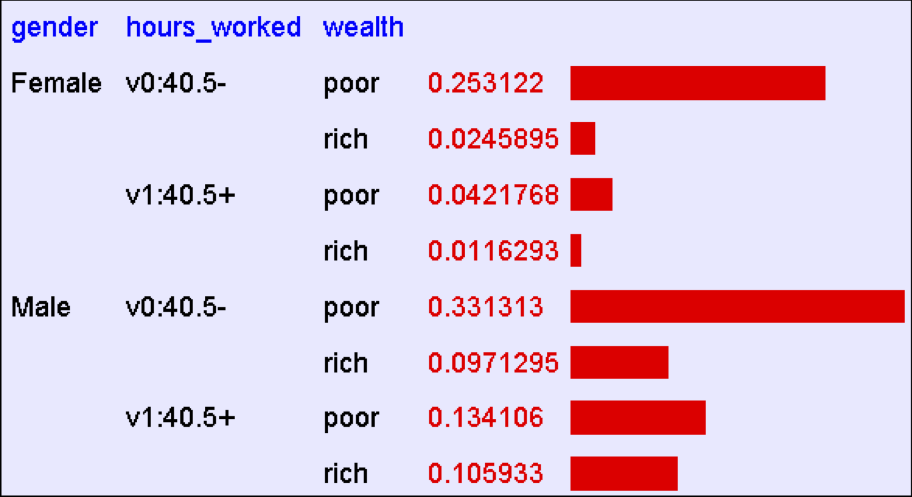
P(E) = ∑rows matching EP(row)
Sử dụng Đồng thời

P(E) = ∑rows matching EP(row)
P(Nam giới nghèo) = 0,4654
Sử dụng Đồng thời

P(E) = ∑rows matching EP(row)
P(Nghèo) = 0,7604
Sự suy luận với Đồng thời
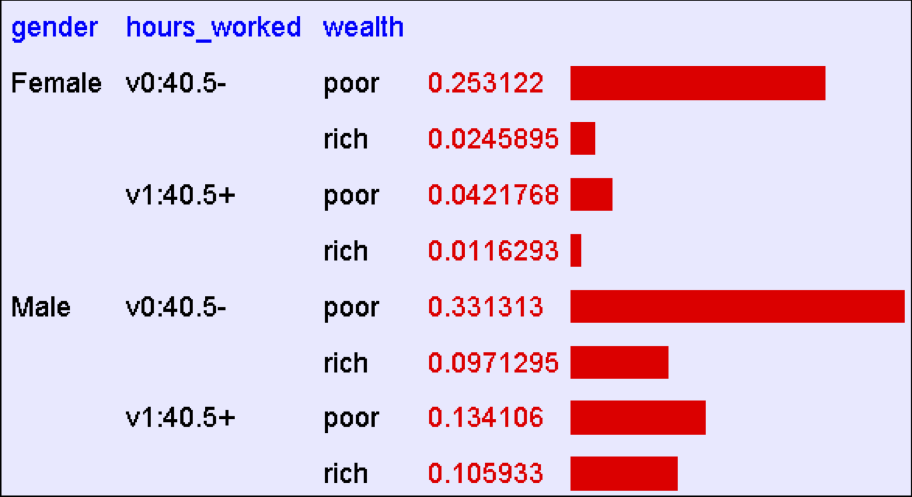
P(E1 | E2 ) = P(E1 ∧ E2 )⁄P(E2 ) = ∑rows matching E1 and E2P(row)⁄∑rows matching E2P(row)
Sự suy luận với Đồng thời

P(E1 | E2 ) = P(E1 ∧ E2 )⁄P(E2 ) = ∑rows matching E1 and E2P(row)⁄∑rows matching E2P(row)
P(Nam | Nghèo) = 0,4654 / 0,7604 = 0,612
Bạn nên biết
- Sự kiện
- biến ngẫu nhiên rời rạc, biến ngẫu nhiên liên tục, sự kiện phức hợp
- Tiên đề xác suất
- Điều gì định nghĩa một lý thuyết hợp lý về sự không chắc chắn
- Xác suất có điều kiện
- Quy tắc dây chuyền
- Quy tắc Bayes
- Phân phối đồng thời trên nhiều biến ngẫu nhiên
- cách tính các đại lượng khác từ phân phối đồng thời
Các giá trị kỳ vọng
Cho biến ngẫu nhiên rời rạc X, giá trị kỳ vọng của X, viết E[X] là
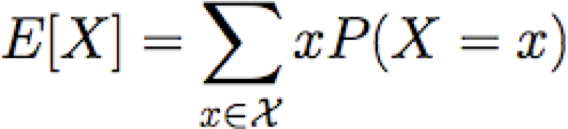
Chúng ta cũng có thể nói về giá trị kỳ vọng của hàm của X
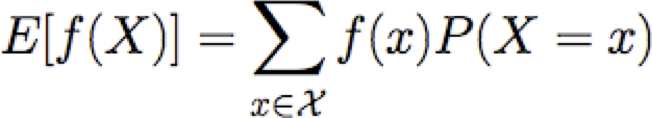
Hiệp phương sai
Cho hai rv rời rạc X và Y, chúng ta định nghĩa hiệp phương sai của X và Y là

ví dụ: X=giới tính, Y=lượt chơiBóng đá
hoặc X=giới tính, Y=thuận tay trái
Nhớ lại: