
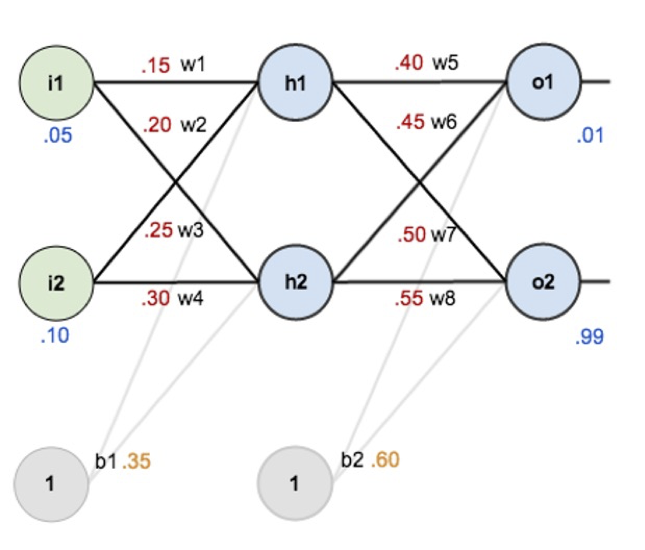
Overview : initial weights, the biases, and training inputs/outputs
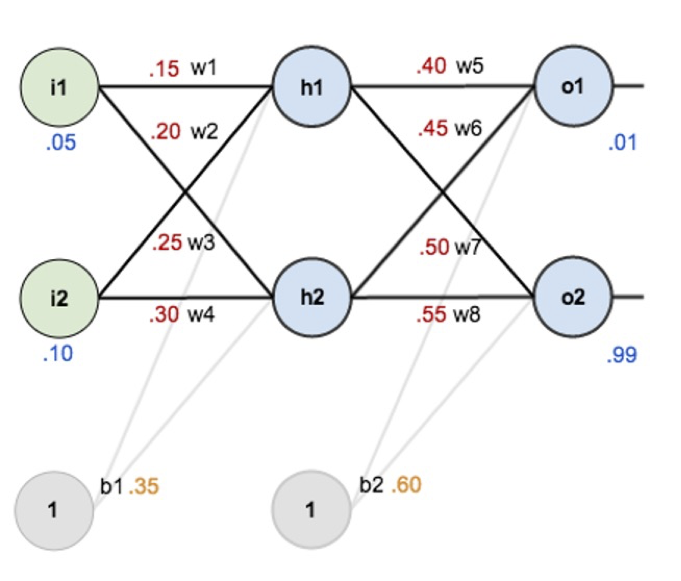
Forward-Computation : total net input, activation function
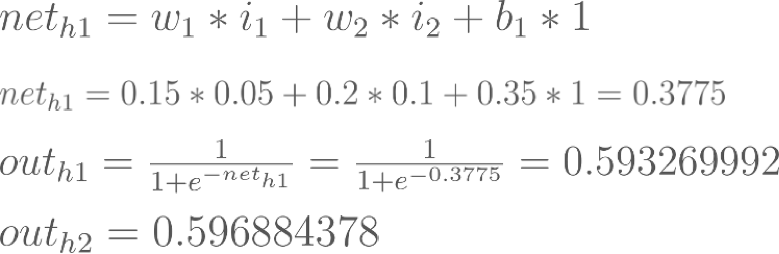
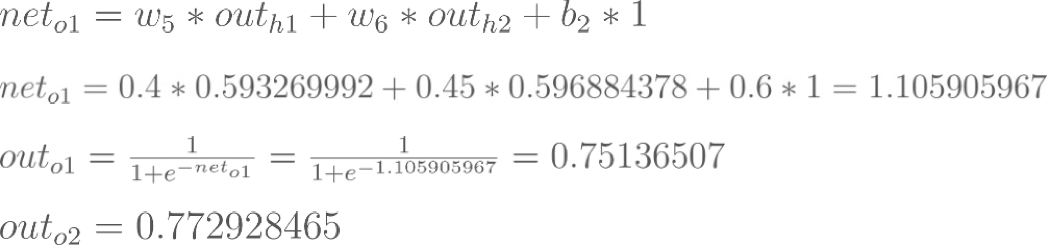
Calculating the Total Error : squared error function
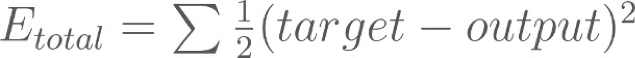
For example, the target output for O1 is 0.01 but the neural network output 0.75136507, therefore its error is:
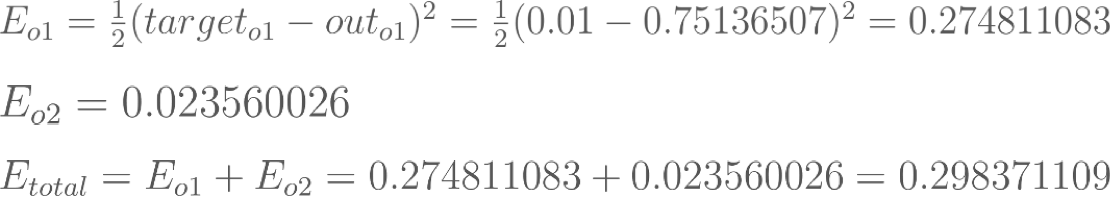
Backpropagation : Output Layer
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
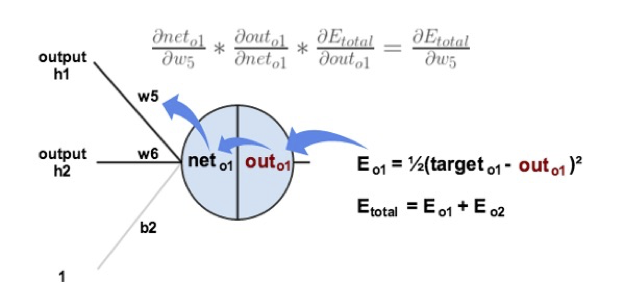
Consider w5. We want to know how much a change in w5 affects the total error, aka 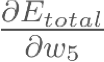 .
.
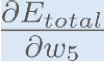 is read as “the partial derivative of Etotal with respect to w5“. You can also say “the gradient with respect to w5“.
is read as “the partial derivative of Etotal with respect to w5“. You can also say “the gradient with respect to w5“.
By applying the chain rule we know that:
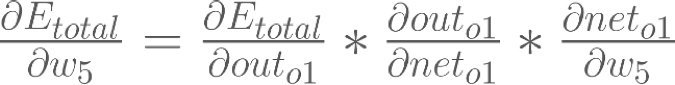
Backpropagation : Output Layer
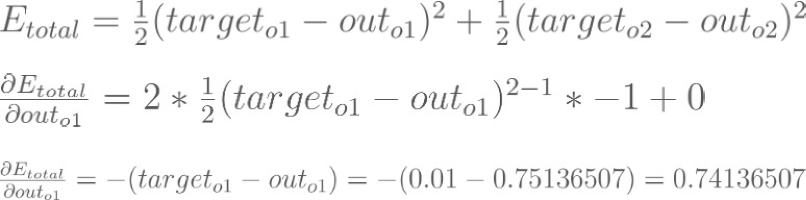

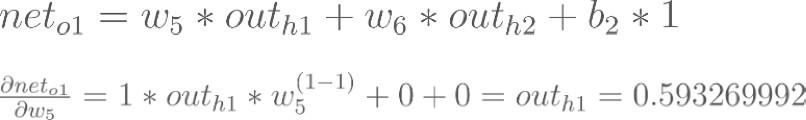
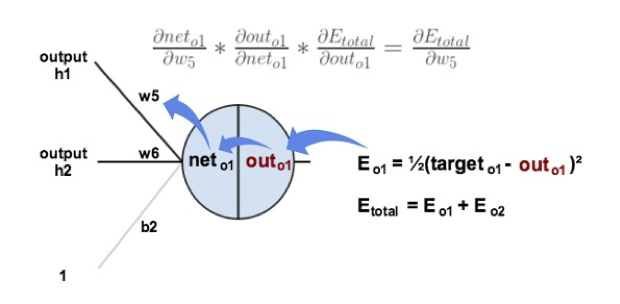
Backpropagation : Output Layer
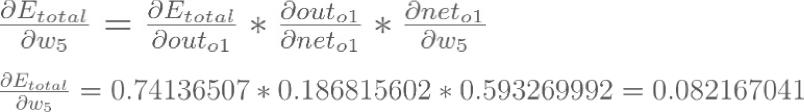
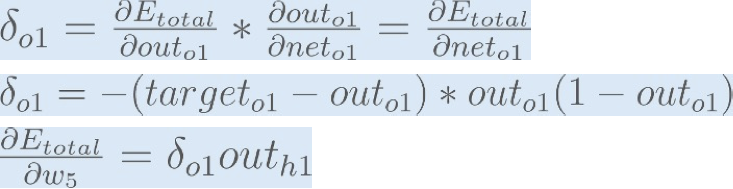
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

Backpropagation : Output Layer
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Backpropagation : Hidden Layer
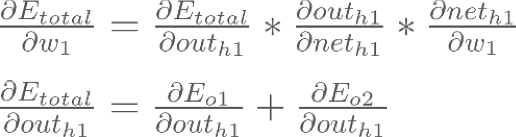
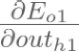 :
: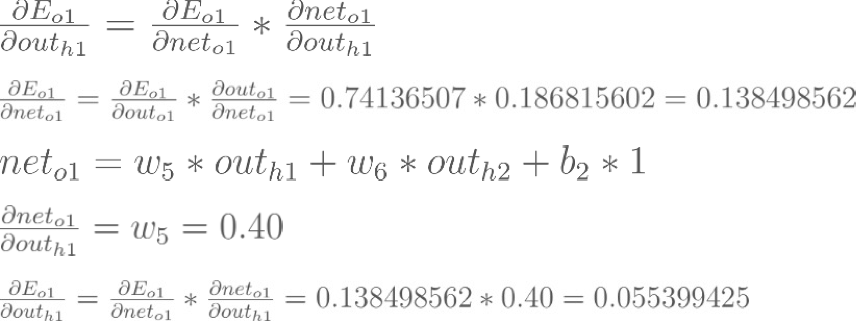
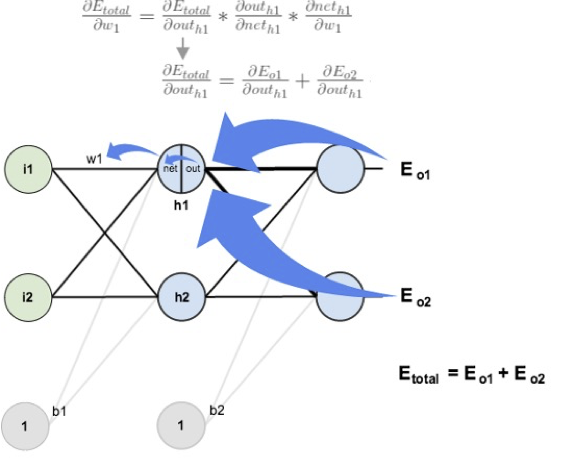
Backpropagation : Hidden Layer
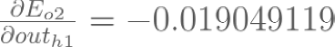
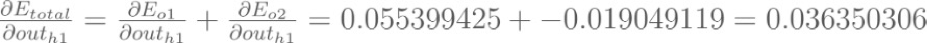

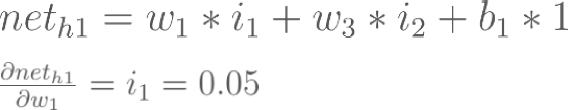
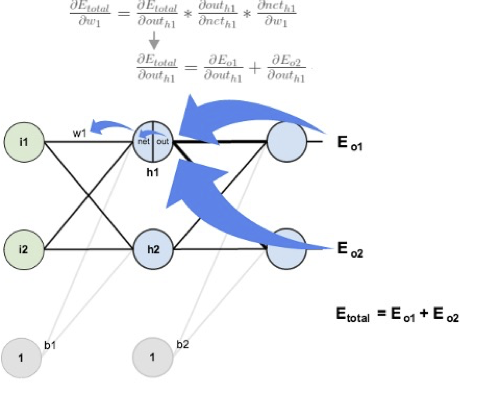
Backpropagation : Hidden Layer
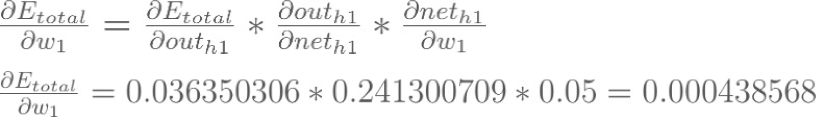


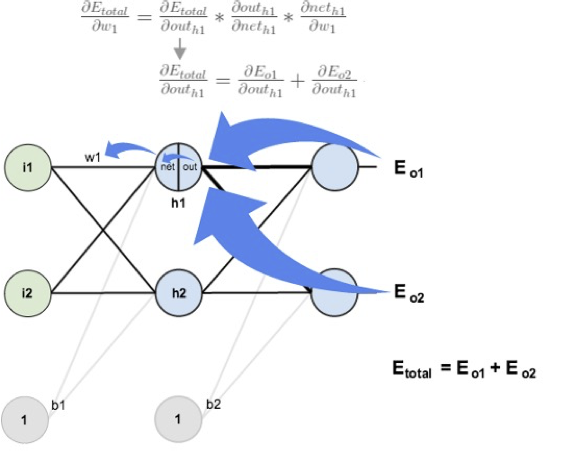
Backpropagation : Hidden Layer
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).