
CÔNG THỨC CHO ML
Công thức cho Học máy
Kiến thức nền
1. Dữ liệu đào tạo cho sẵn:
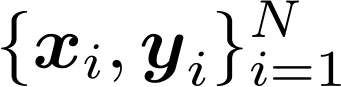
2. Chọn các thành phần sau:
– Hàm quyết định
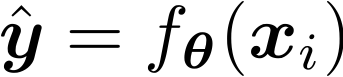
– Hàm mất mát
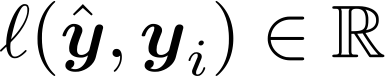

Ví dụ: Hồi quy tuyến tính, Hồi quy logistic, Mạng nơ-ron
Ví dụ: Lỗi bình phương trung bình, Entropy chéo
Công thức cho Học máy
Kiến thức nền
1. Cho dữ liệu đào tạo:
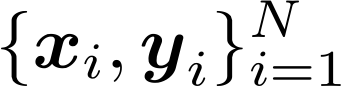
2. Chọn các thành phần sau:
– Hàm quyết định
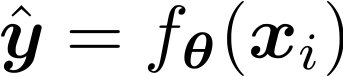
– Hàm mất mát
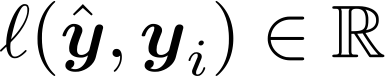
3. Xác định mục tiêu:
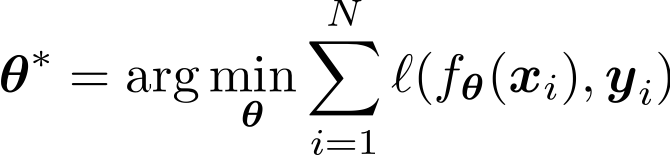
4. Đào tạo với SGD:
(đi những bước nhỏ ngược với độ dốc)
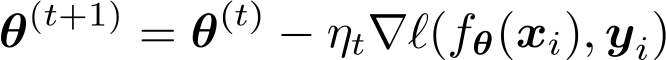
Công thức cho Học máy
Kiến thức nền
1. Cho dữ liệu đào tạo:
2. Chọn các thành phần sau:
– Hàm quyết định
– Hàm mất mát
3. Xác định mục tiêu:
4. Đào tạo với SGD:
(đi những bước nhỏ ngược với độ dốc)

Độ dốc
Backpropagation có thể tính toán độ dốc này!
Và đây là trường hợp đặc biệt của thuật toán tổng quát hơn được gọi là phép tính vi phân tự động chế độ ngược có thể tính toán độ dốc của bất kỳ hàm khả vi nào một cách hiệu quả!
Công thức cho Học máy
Kiến thức nền
1. Cho dữ liệu đào tạo:
2. Chọn các thành phần sau:
– Hàm quyết định
– Hàm mất mát
3. Xác định mục tiêu:
4. Đào tạo với SGD:
(đi những bước nhỏ ngược với độ dốc)

Mục tiêu cho bài giảng hôm nay
1. Khám phá một lớp hàm quyết định mới (Mạng nơ-ron)
2. Xem xét các biến thể của công thức này để đào tạo
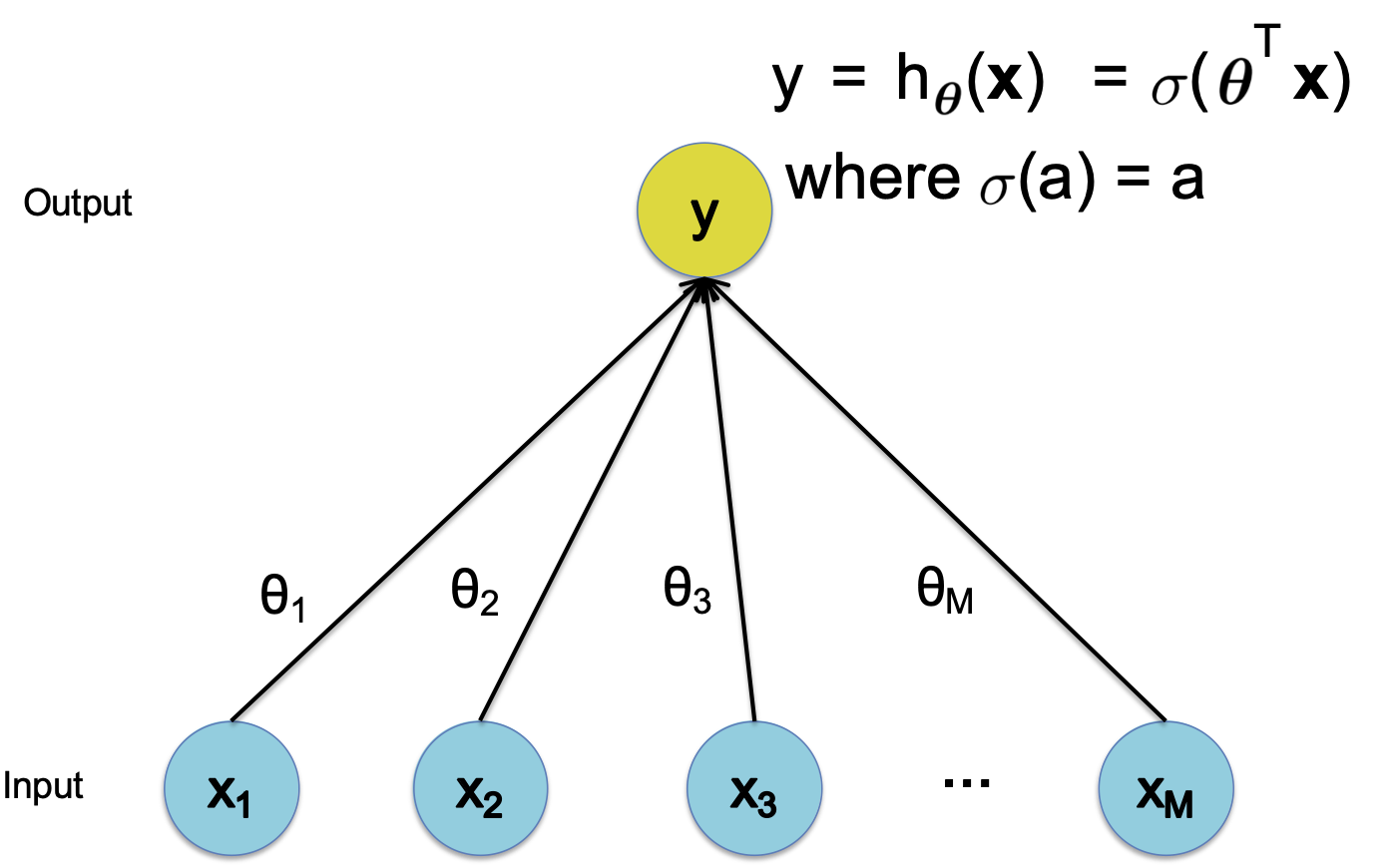
Hồi quy tuyến tính
Hàm quyết định
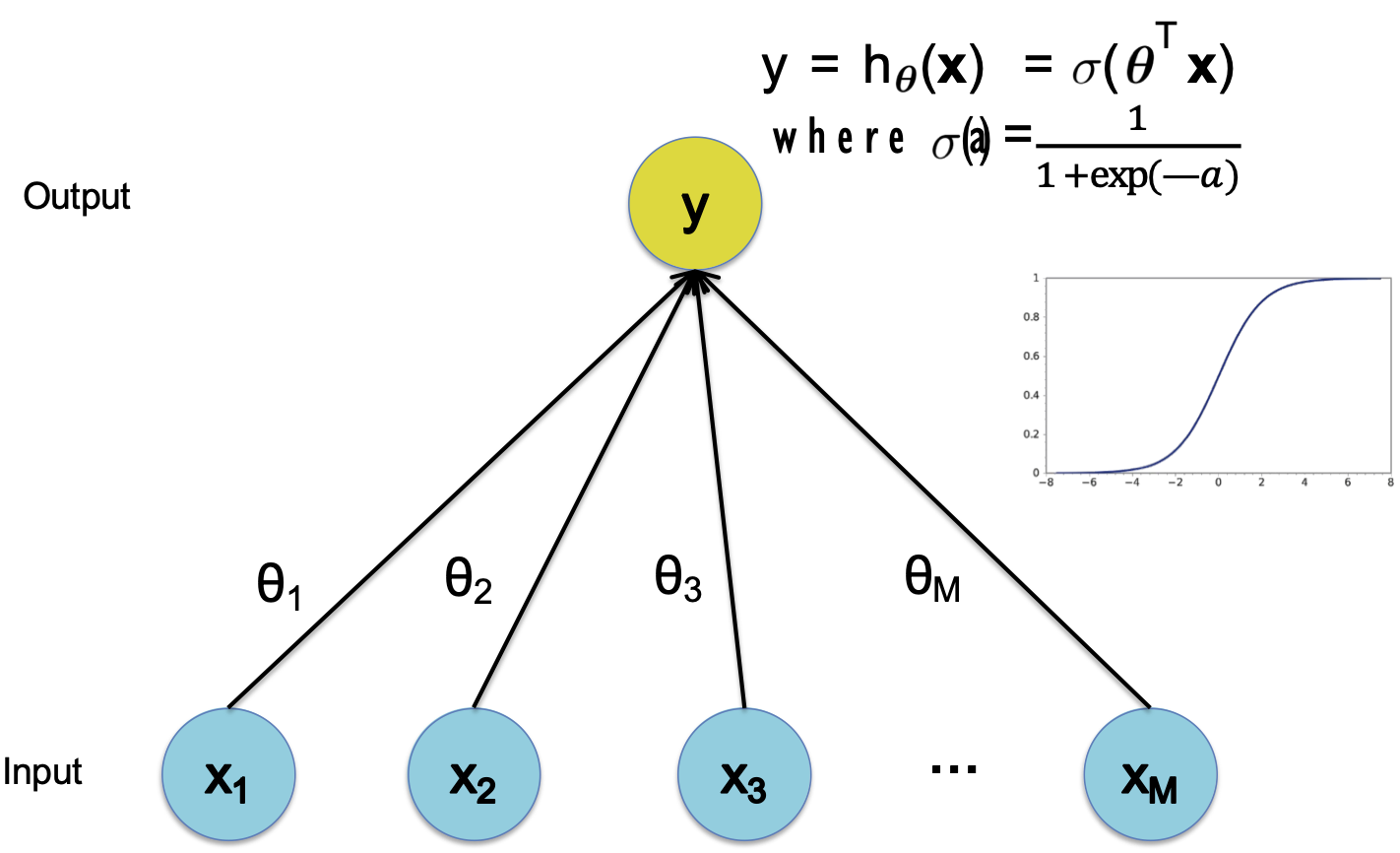
Hồi quy logistic
Hàm quyết định
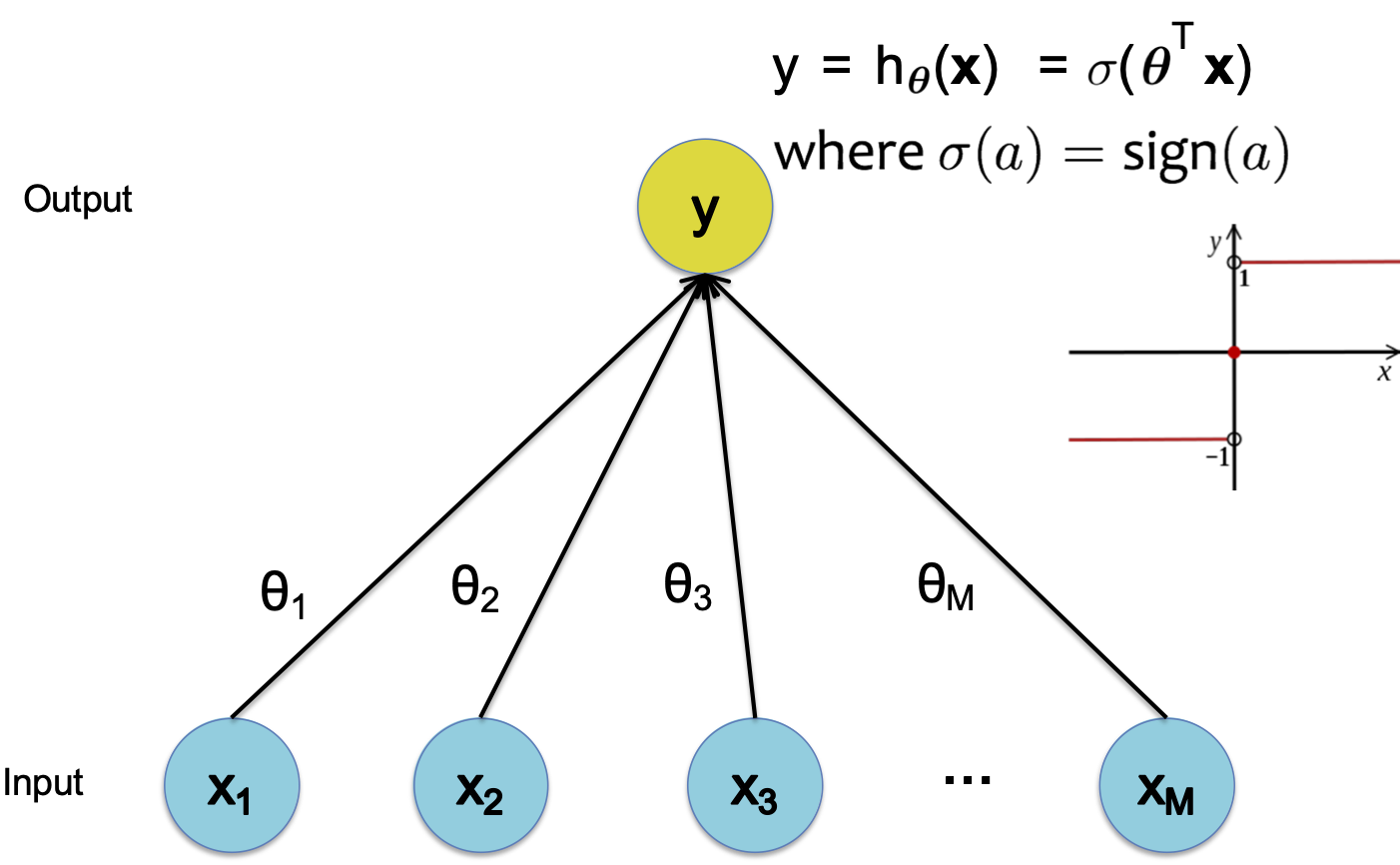
Perceptron
Hàm quyết định
Mạng nơ-ron
Hàm quyết định
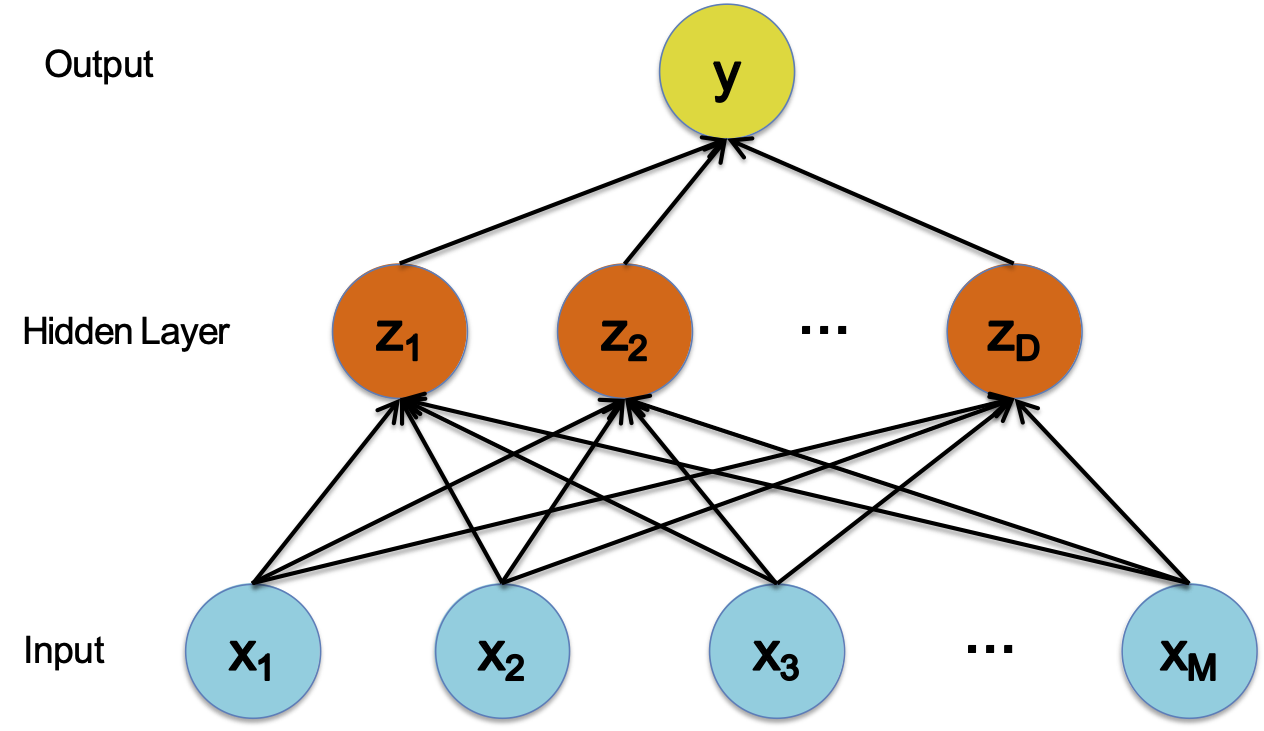
CÁC THÀNH PHẦN CỦA MỘT MẠNG NƠ-RON
Mạng nơ-ron
Hàm quyết định
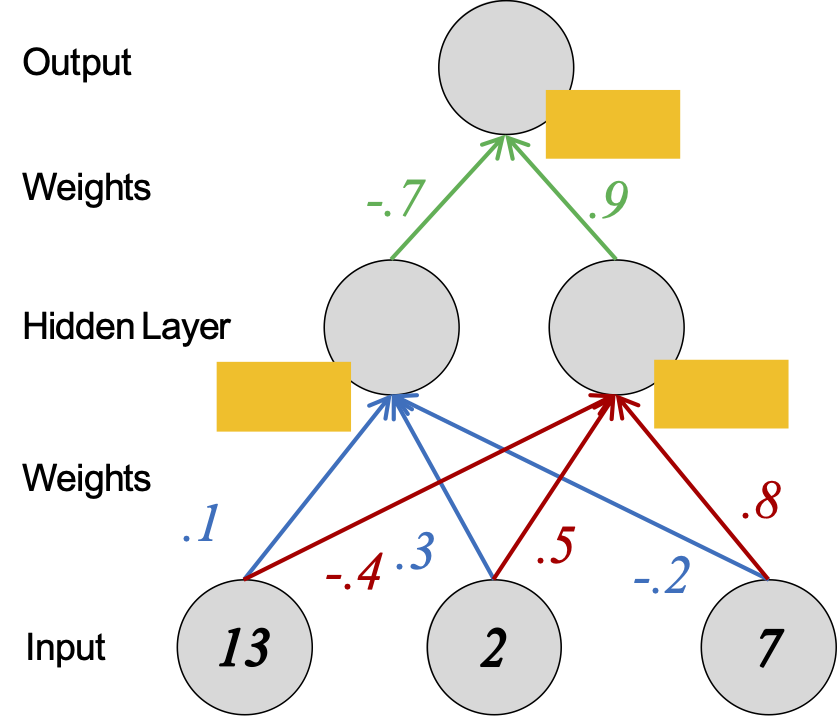
Giả sử chúng ta đã học trọng lượng của mạng thần kinh.
Để đưa ra một dự đoán mới, chúng ta tiếp nhận một số tính năng mới (còn gọi là lớp đầu vào) và thực hiện tính toán chuyển tiếp.
Mạng nơ-ron
Hàm quyết định
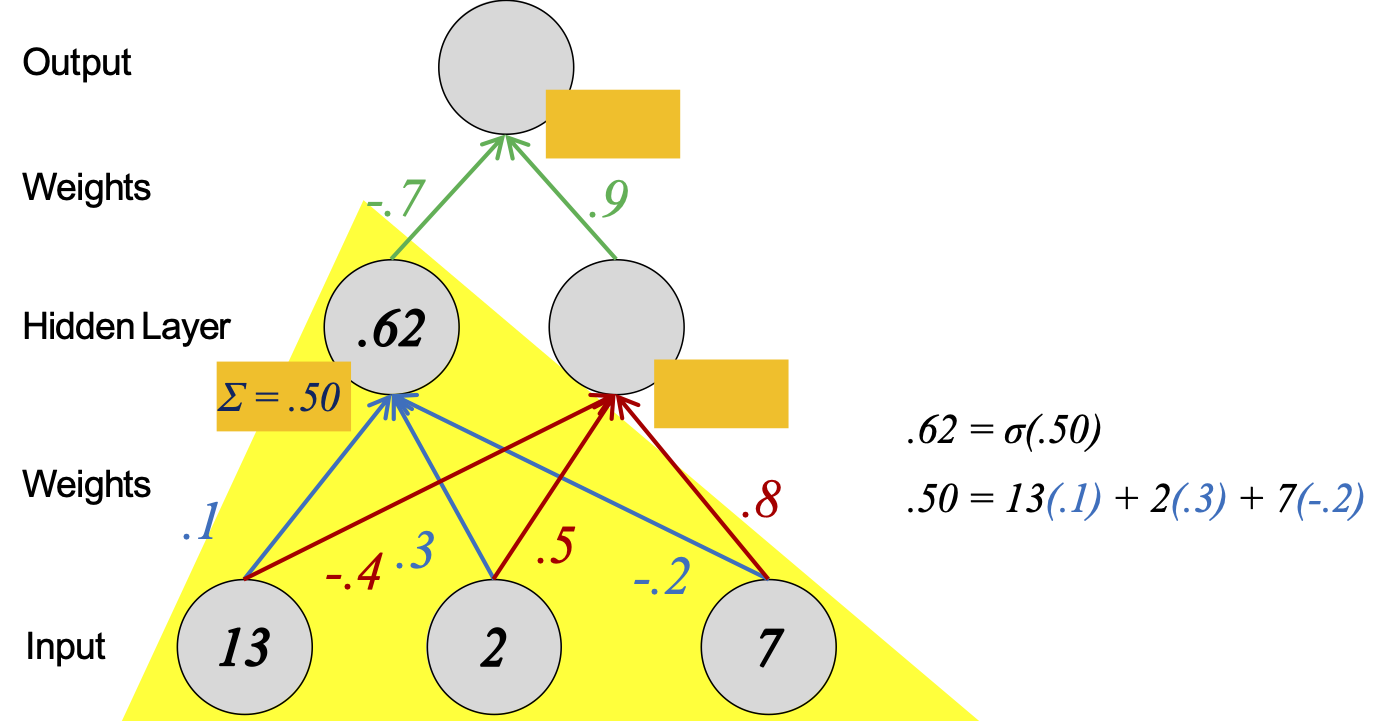
Tính toán của mỗi đơn vị mạng nơ-ron giống như hồi quy logistic nhị phân.
Mạng nơ-ron
Hàm quyết định
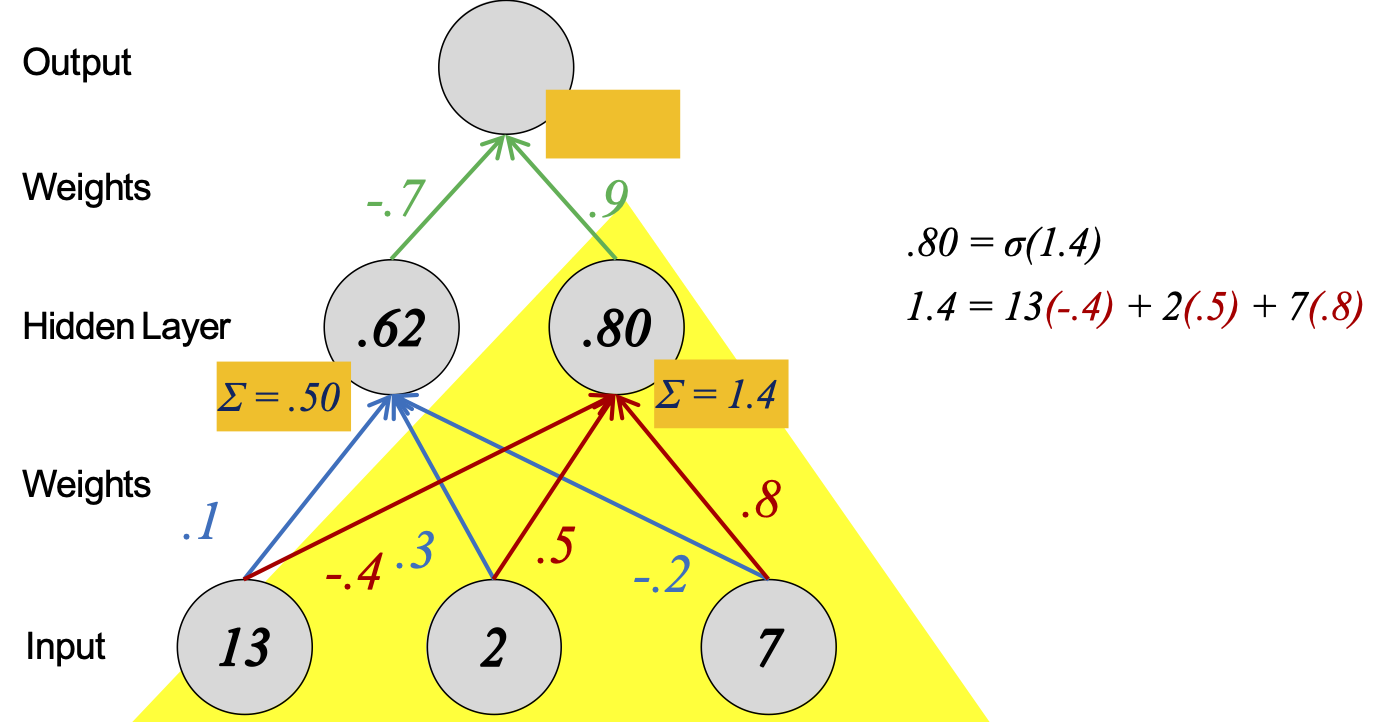
Tính toán của mỗi đơn vị mạng nơ-ron giống như hồi quy logistic nhị phân.
Mạng nơ-ron
Hàm quyết định
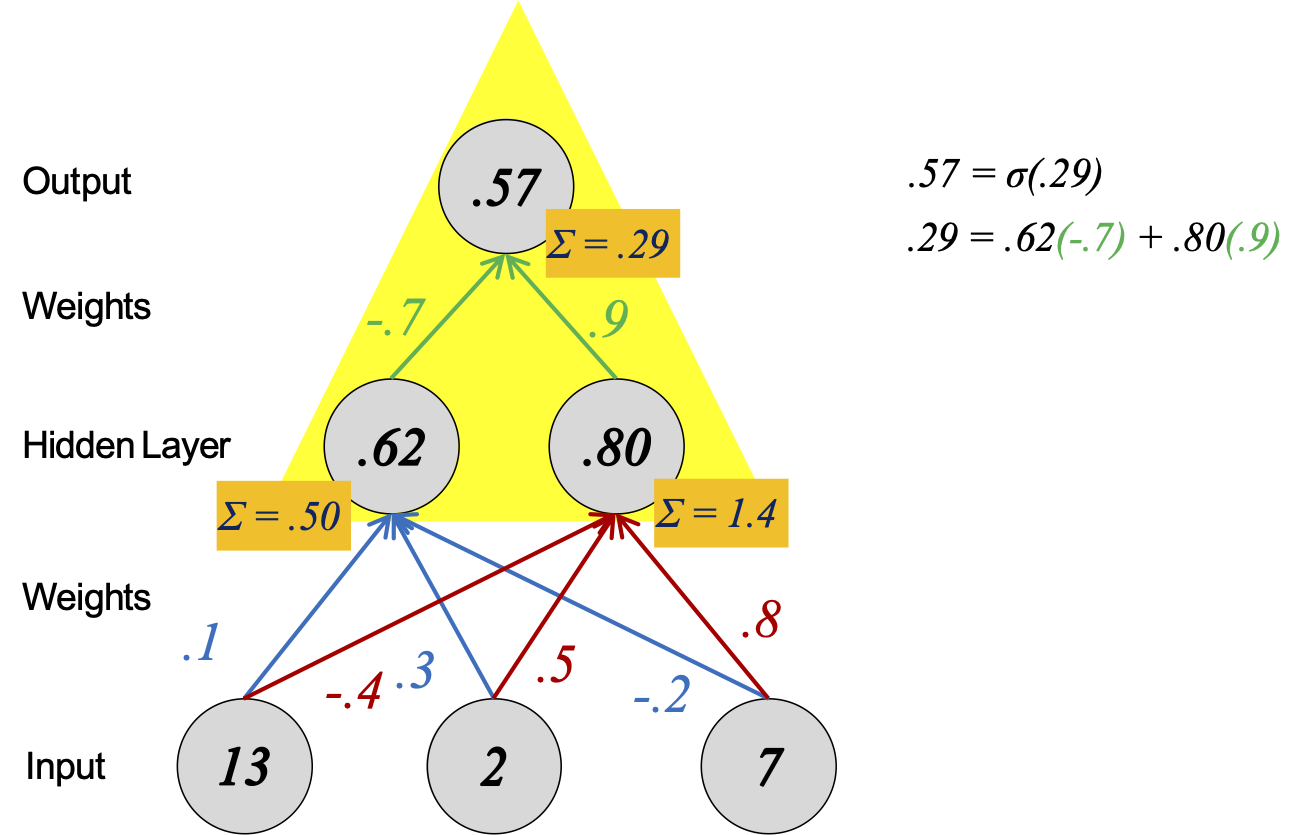
Tính toán của mỗi đơn vị mạng nơ-ron giống như hồi quy logistic nhị phân.
Mạng nơ-ron
Hàm quyết định

Tính toán của mỗi đơn vị mạng nơ-ron giống như hồi quy logistic nhị phân.
Mạng nơ-ron
Hàm quyết định
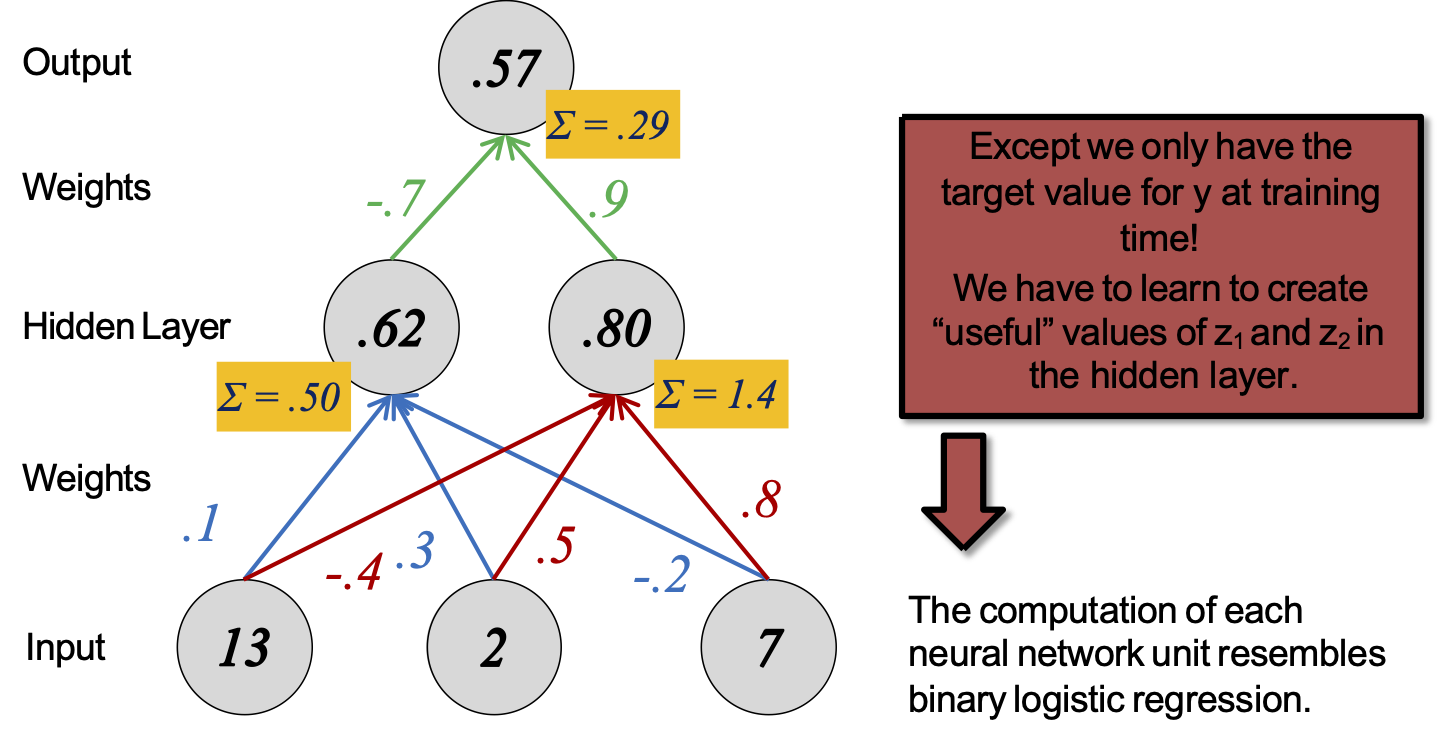
Tính toán của mỗi đơn vị mạng nơ-ron giống như hồi quy logistic nhị phân.
Ngoại trừ chúng ta chỉ có giá trị mục tiêu cho y tại thời điểm đào tạo!
Chúng ta phải học cách sáng tạo giá trị “hữu ích” của z1 và z2 trong lớp ẩn.
Từ sinh học đến nhân tạo
Động lực của Mạng nơ-ron nhân tạo xuất phát từ sinh học…
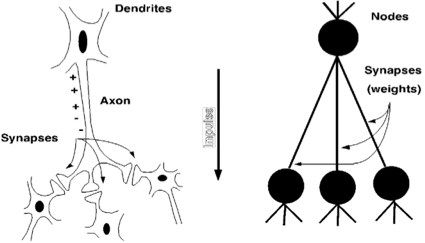
“Mô hình” sinh học
- Nơ-ron: tế bào dễ bị kích thích
- Synapse: kết nối giữa tế bào thần kinh
- Tế bào thần kinh gửi xung điện hóa dọc theo các khớp thần kinh của nó khi có sự thay đổi điện áp đủ lớn
- Mạng nơ-ron sinh học: tập hợp các tế bào thần kinh dọc theo một đường dẫn nào đó đi qua não
Mô hình nhân tạo
- Nơ-ron: nút trong đồ thị phi chu trình có hướng (DAG)
- Trọng số: hệ số nhân trên mỗi cạnh
- Hàm kích hoạt: hàm ngưỡng phi tuyến tính, cho phép một neuron sẽ “bắn” khi giá trị đầu vào đủ cao
- Mạng nơ-ron nhân tạo: tập hợp các tế bào thần kinh vào một DAG, định nghĩa nên một hàm số khả vi
“Tính toán” sinh học
- Thời gian chuyển mạch nơ-ron: ~ 0,001 giây
- Số lượng tế bào thần kinh: ~ 1010
- Kết nối trên mỗi nơ-ron: ~ 104-5
- Thời gian nhận dạng cảnh: ~ 0,1 giây
Tính toán nhân tạo
- Nhiều đơn vị chuyển mạch có ngưỡng giống như tế bào thần kinh
- Nhiều kết nối có trọng số giữa các đơn vị
- Các quy trình phân tán, song song cao
Slide được chuyển thể từ Eric Xing
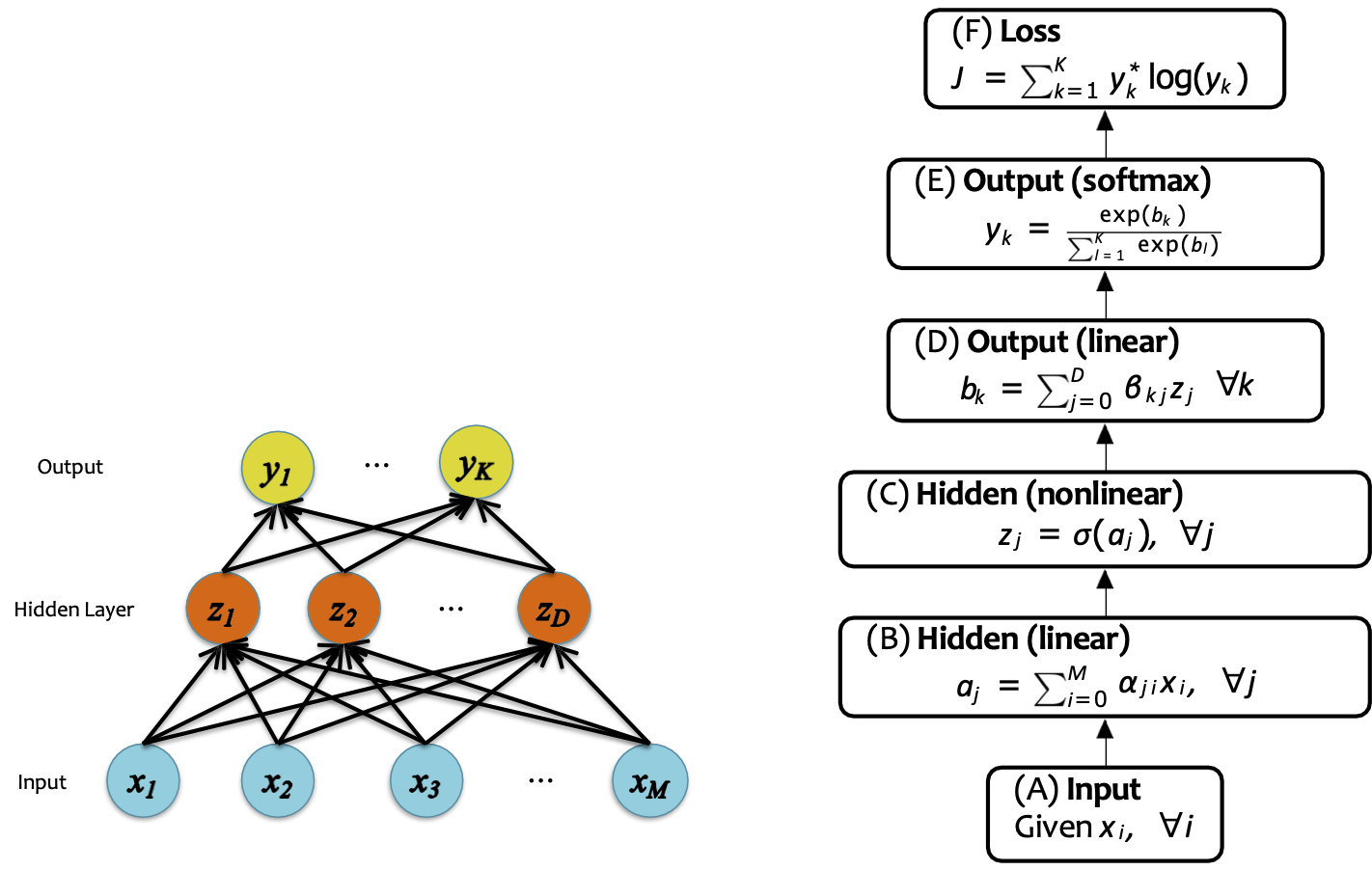
ĐỊNH NGHĨA MẠNG NEURAL 1-LỚP ẨN
Ví dụ: Mạng nơ-ron có một lớp ẩn

Mạng nơ-ron
Hàm quyết định

Mạng nơ-ron
Hàm quyết định

Mạng nơ-ron
Hàm quyết định

Mạng nơ-ron
Hàm quyết định
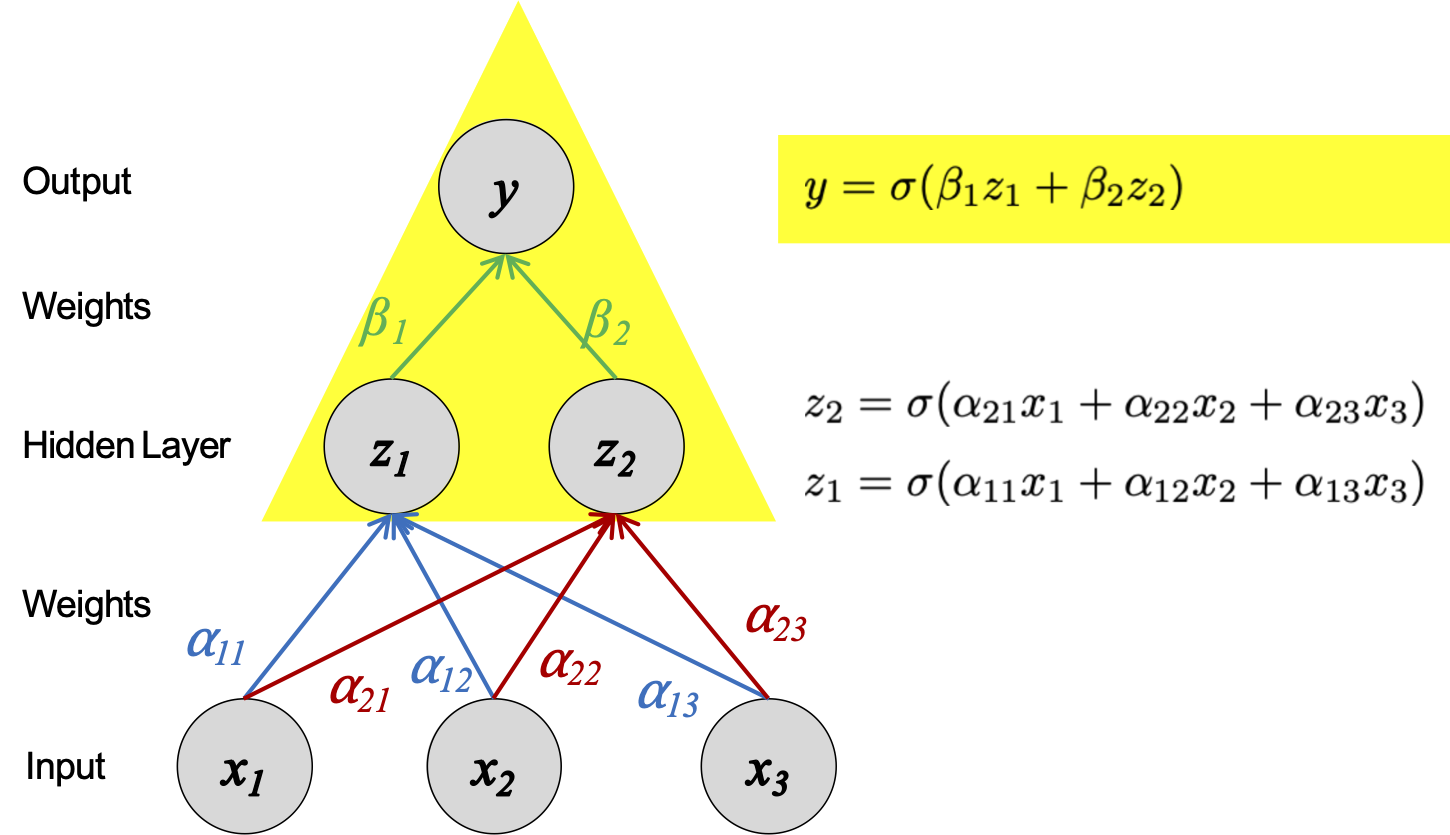
Mạng nơ-ron
Hàm quyết định

BIÊN QUYẾT ĐỊNH PHI TUYẾN TÍNH VÀ MẠNG NƠ-RON
Hồi quy logistic
Hàm quyết định
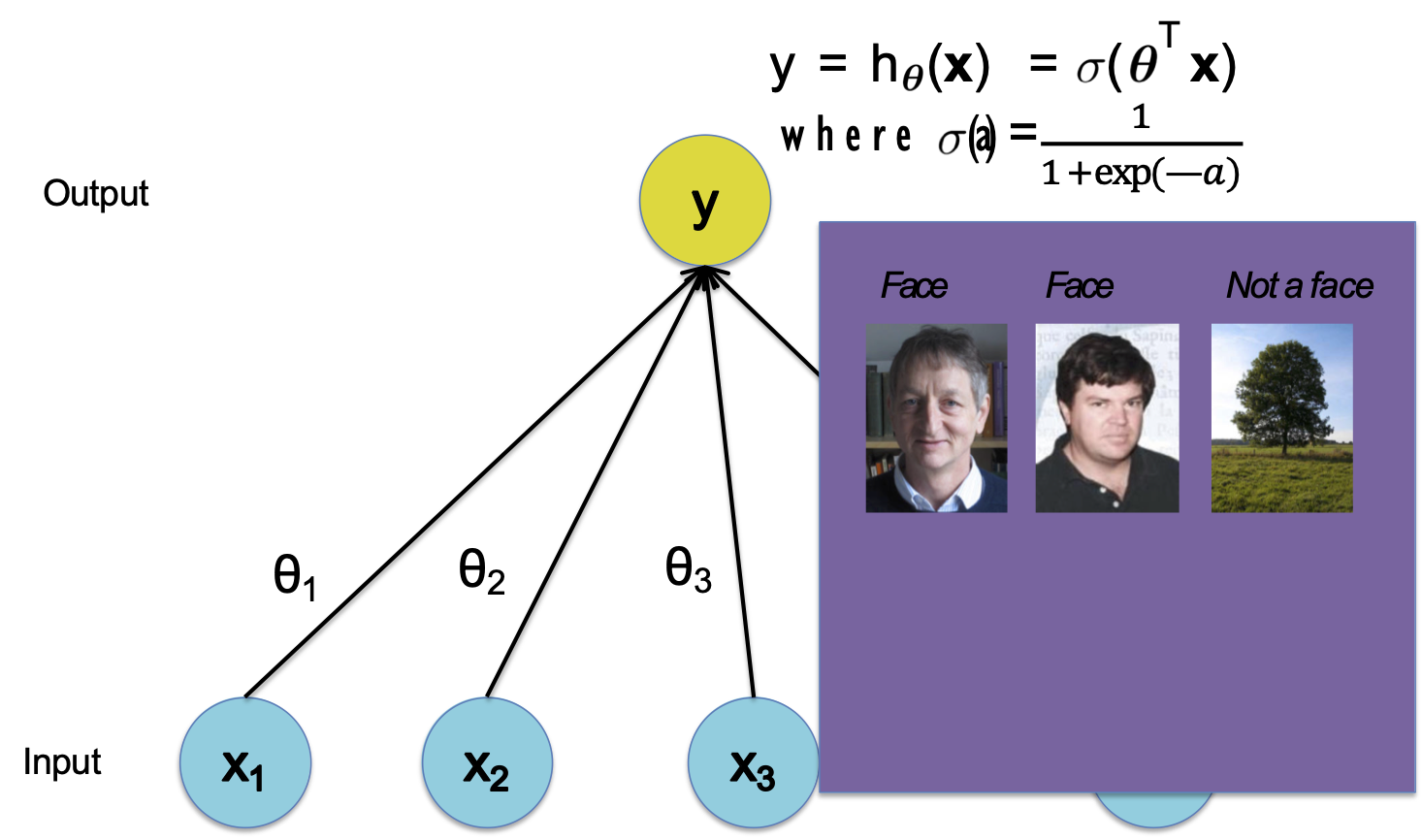
Hồi quy logistic
Hàm quyết định
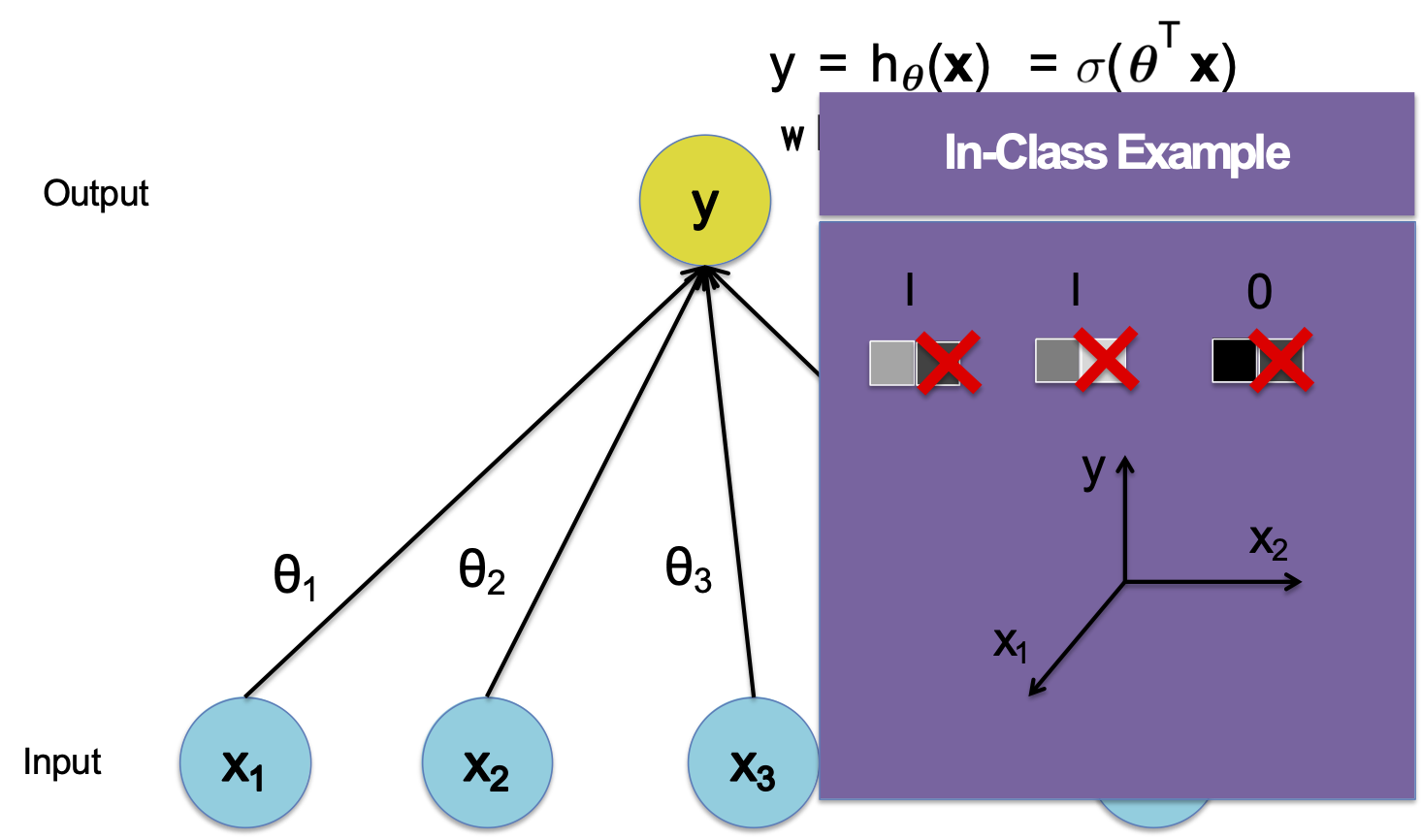
Nhận dạng khuôn mặt 1D

Hồi quy logistic
Hàm quyết định

Hồi quy logistic
Hàm quyết định

Các tham số mạng nơ-ron
Câu hỏi:
Giả sử bạn đang đào tạo một mạng thần kinh một lớp ẩn với kích hoạt sigmoid để phân loại nhị phân.

Đúng hay Sai: Có một bộ tham số duy nhất để tối đa hóa khả năng của tập dữ liệu bên trên.
Kiến trúc mạng nơ-ron
Ngay cả đối với một Mạng nơ-ron cơ bản, vẫn có nhiều quyết định thiết kế cần đưa ra:
- # lớp ẩn (độ sâu)
- # đơn vị trên mỗi lớp ẩn (chiều rộng)
- Loại hàm kích hoạt (phi tuyến tính)
- Dạng hàm mục tiêu
- Cách khởi tạo các tham số
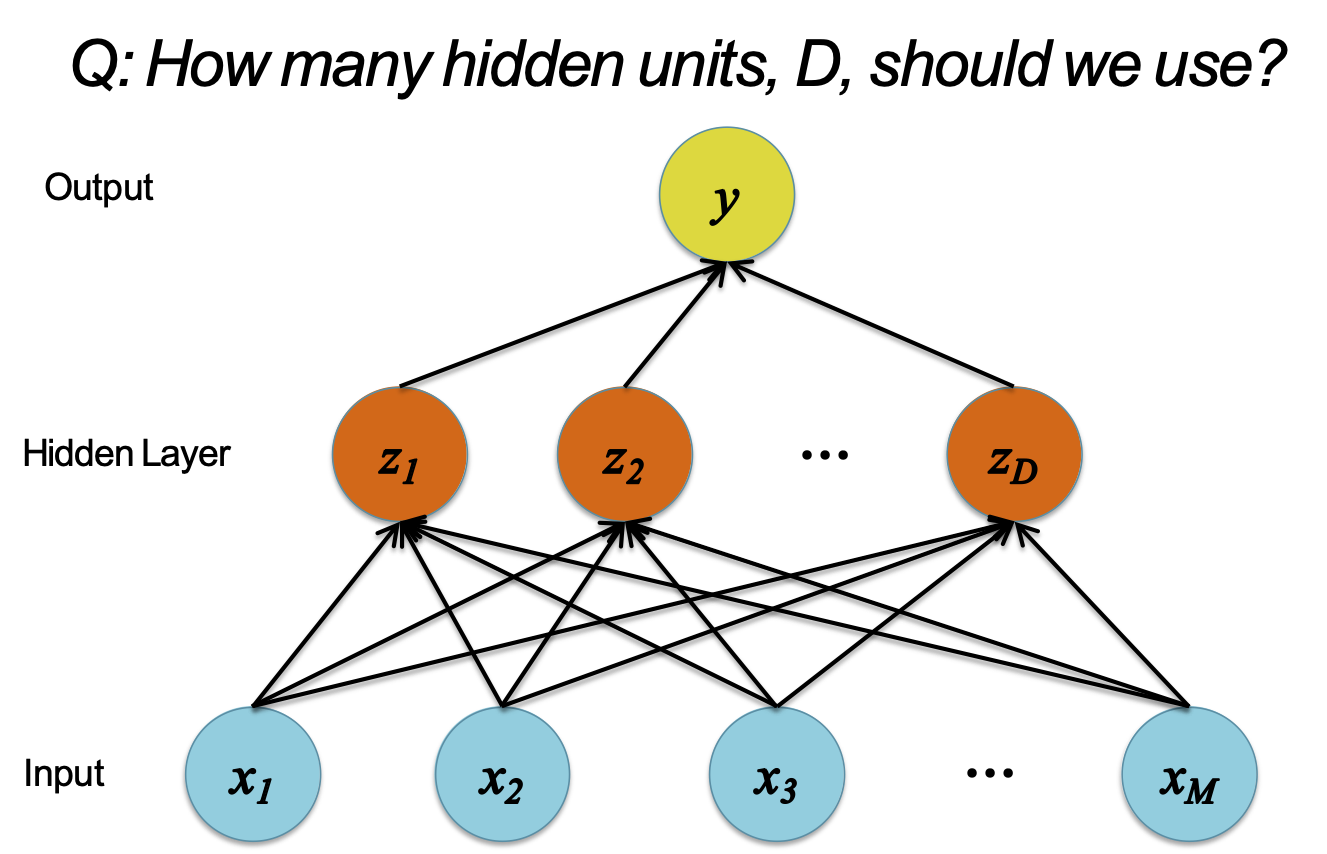
XÂY DỰNG MẠNG RỘNG HƠN
D = M
Xây dựng một mạng nơ-ron
H: Chúng ta nên sử dụng bao nhiêu đơn vị ẩn D?

Các đơn vị ẩn có thể học để trở thành…
- một lựa chọn các đặc trưng hữu ích nhất
- các kết hợp phi tuyến tính của các đặc trưng
- phép chiếu chiều thấp hơn của các đặc trưng
- phép chiếu chiều cao hơn của các đặc trưng
- một bản sao của các đặc trưng đầu vào
- một sự kết hợp của các đặc trưng bên trên
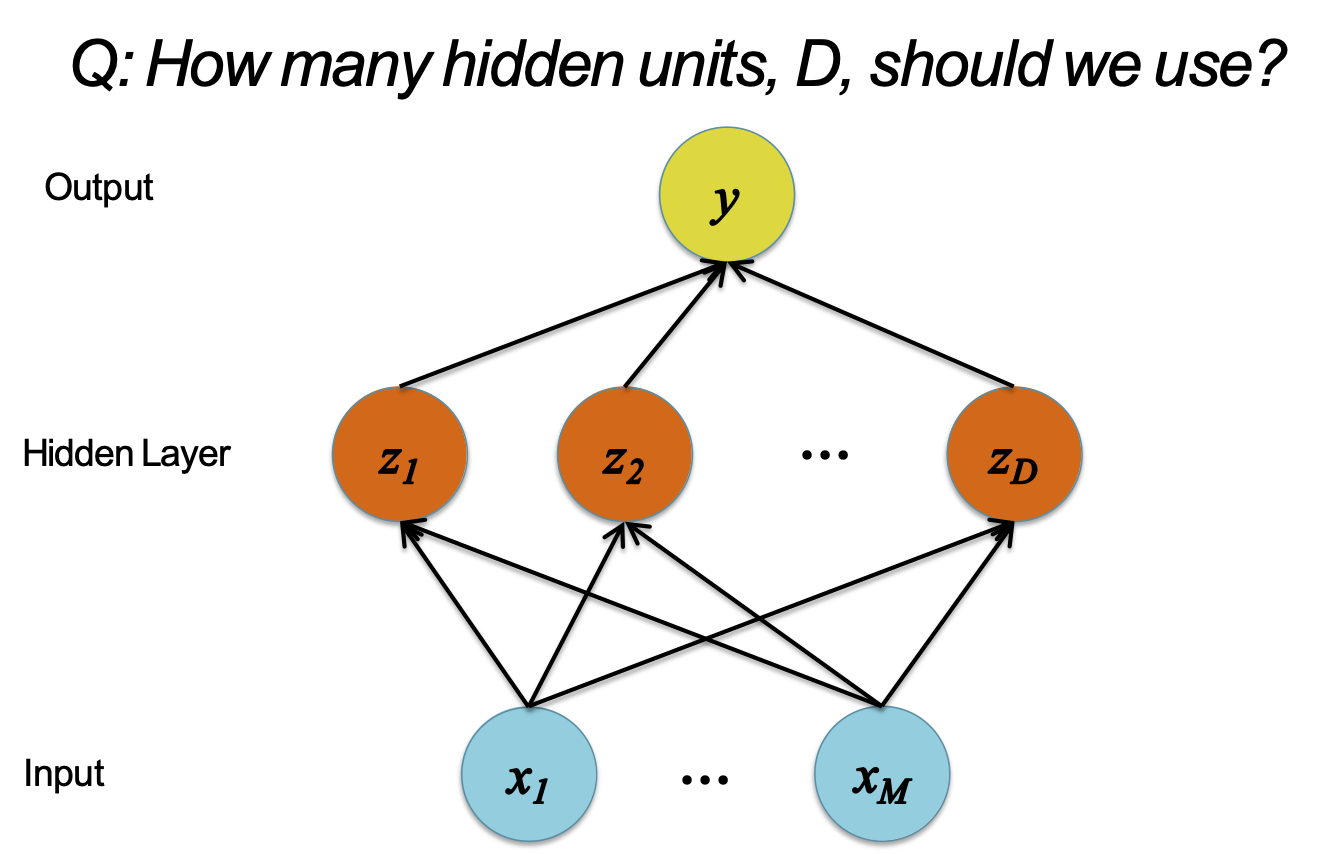
D < M
Xây dựng một mạng nơ-ron
H: Chúng ta nên sử dụng bao nhiêu đơn vị ẩn D?
Các đơn vị ẩn có thể học để trở thành…
- một lựa chọn các đặc trưng hữu ích nhất
- các kết hợp phi tuyến tính của các đặc trưng
- phép chiếu chiều thấp hơn của các đặc trưng
- phép chiếu chiều cao hơn của các đặc trưng
- một bản sao của các đặc trưng đầu vào
- một sự kết hợp của các đặc trưng bên trên
D > M
Xây dựng một mạng nơ-ron
H: Chúng ta nên sử dụng bao nhiêu đơn vị ẩn D?
Các đơn vị ẩn có thể học để trở thành…
- một lựa chọn các đặc trưng hữu ích nhất
- các kết hợp phi tuyến tính của các đặc trưng
- phép chiếu chiều thấp hơn của các đặc trưng
- phép chiếu chiều cao hơn của các đặc trưng
- một bản sao của các đặc trưng đầu vào
- một sự kết hợp của các đặc trưng bên trên
D ≥ M
Xây dựng một mạng nơ-ron
Trong các ví dụ sau, chúng ta có hai tính năng đầu vào, M=2, và chúng ta thay đổi số lượng các đơn vị ẩn, D.

Các đơn vị ẩn có thể học để trở thành…
- một lựa chọn các đặc trưng hữu ích nhất
- các kết hợp phi tuyến tính của các đặc trưng
- phép chiếu chiều thấp hơn của các đặc trưng
- phép chiếu chiều cao hơn của các đặc trưng
- một bản sao của các đặc trưng đầu vào
- một sự kết hợp của các đặc trưng bên trên
VÍ DỤ BIÊN QUYẾT ĐỊNH
Ví dụ 1 và 2
Ví dụ 1 và 2
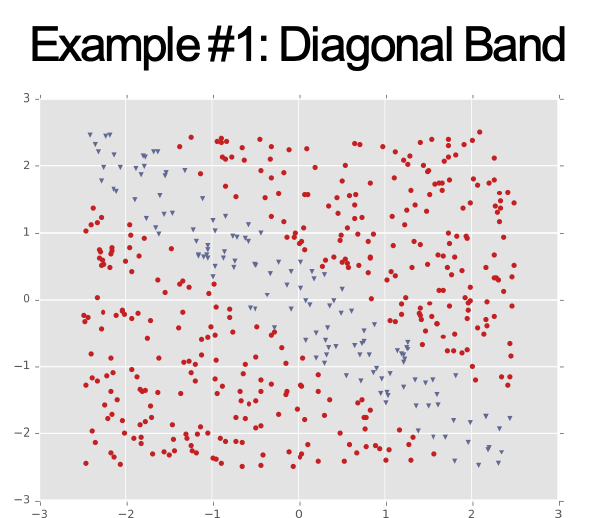
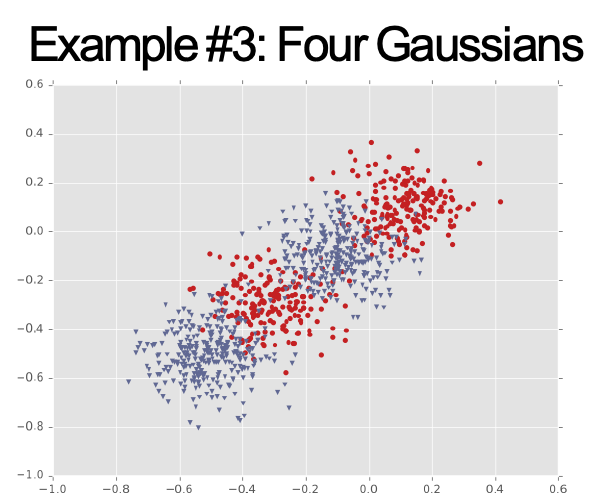
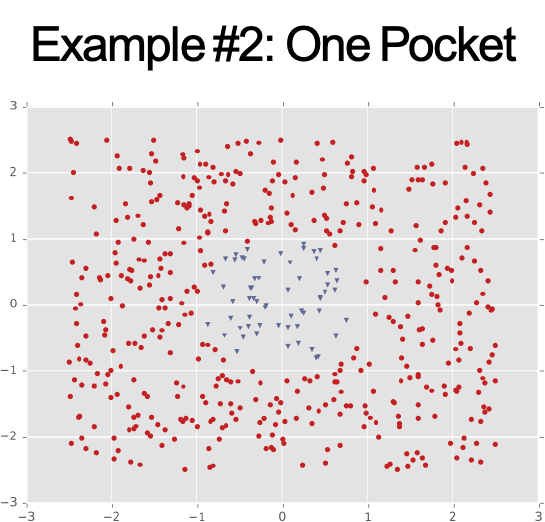
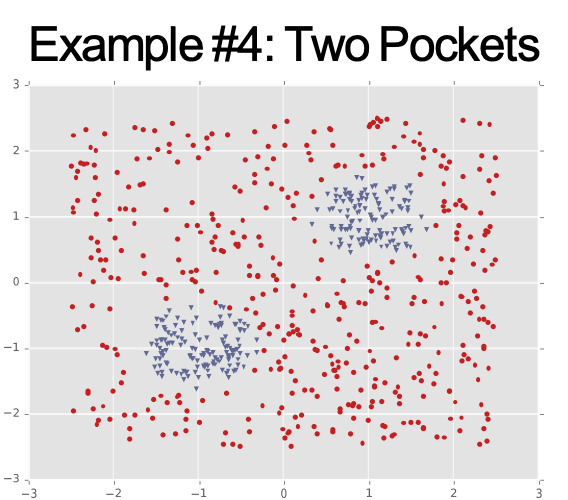
Ví dụ #1: Dải chéo
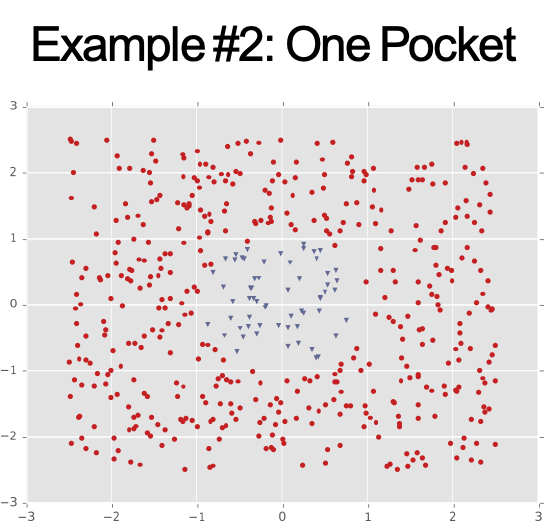
Ví dụ #2: Một cụm biệt lập
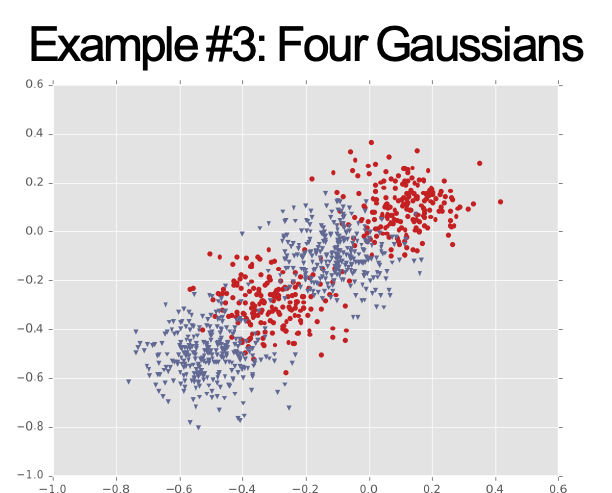
Ví dụ #3: Bốn cụm Gaussian
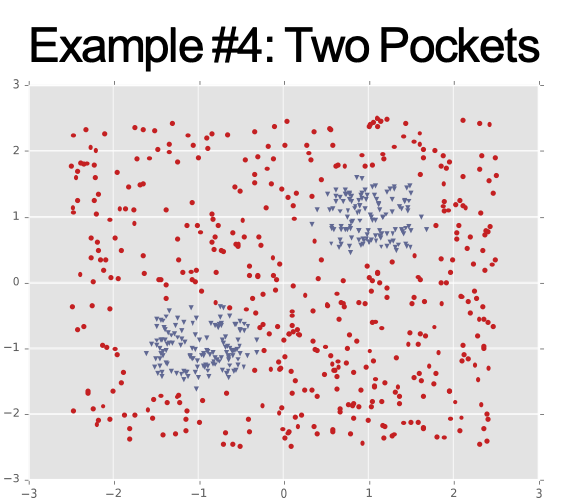
Ví dụ #4: Hai cụm biệt lập
Ví dụ #1: Dải chéo

Ví dụ #1: Dải chéo

Ví dụ #1: Dải chéo
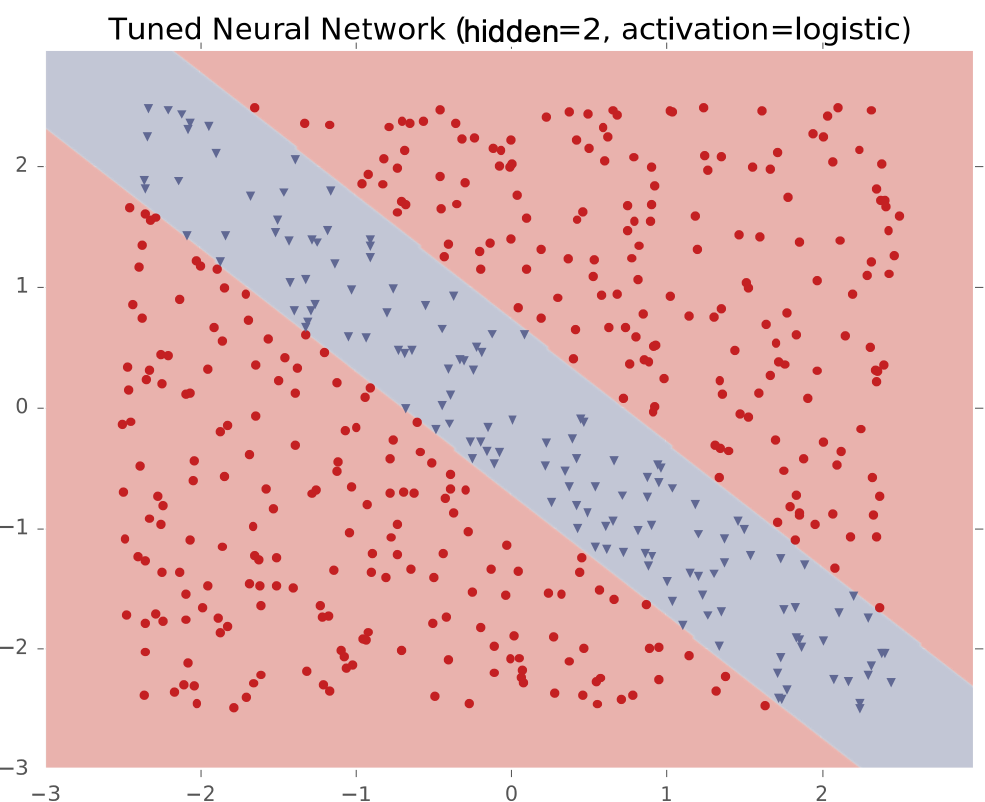
Ví dụ #1: Dải chéo

Ví dụ #1: Dải chéo
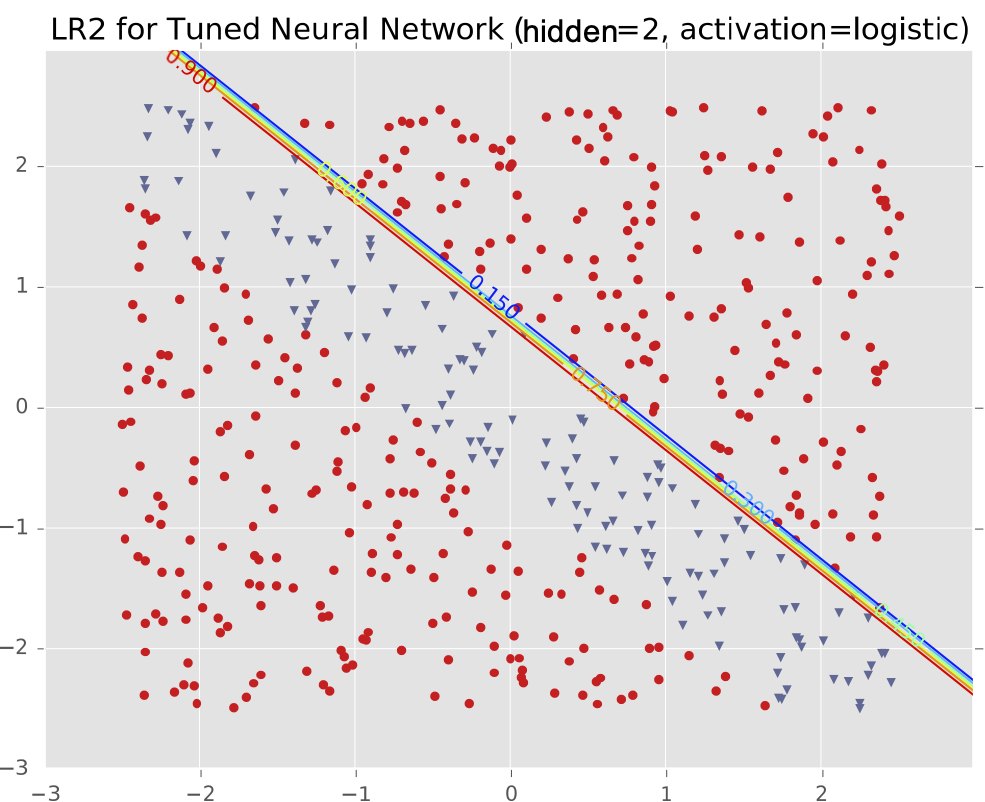
Ví dụ #1: Dải chéo

Ví dụ #1: Dải chéo

Ví dụ #2: Một cụm biệt lập
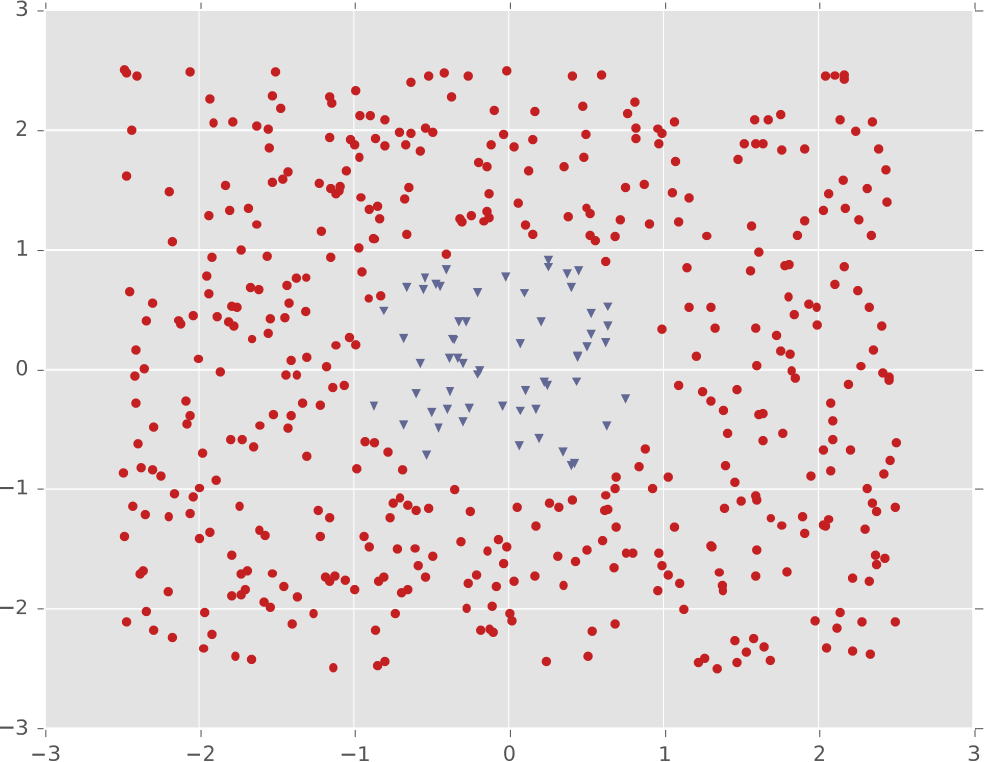
Ví dụ #2: Một cụm biệt lập
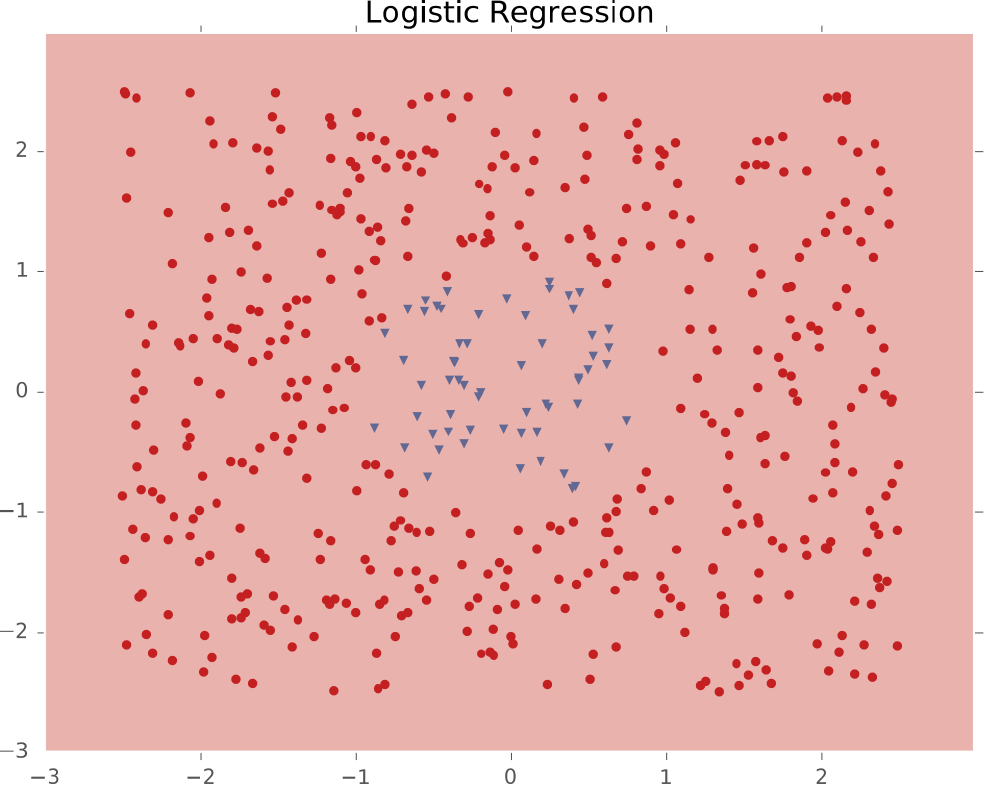
Ví dụ #2: Một cụm biệt lập
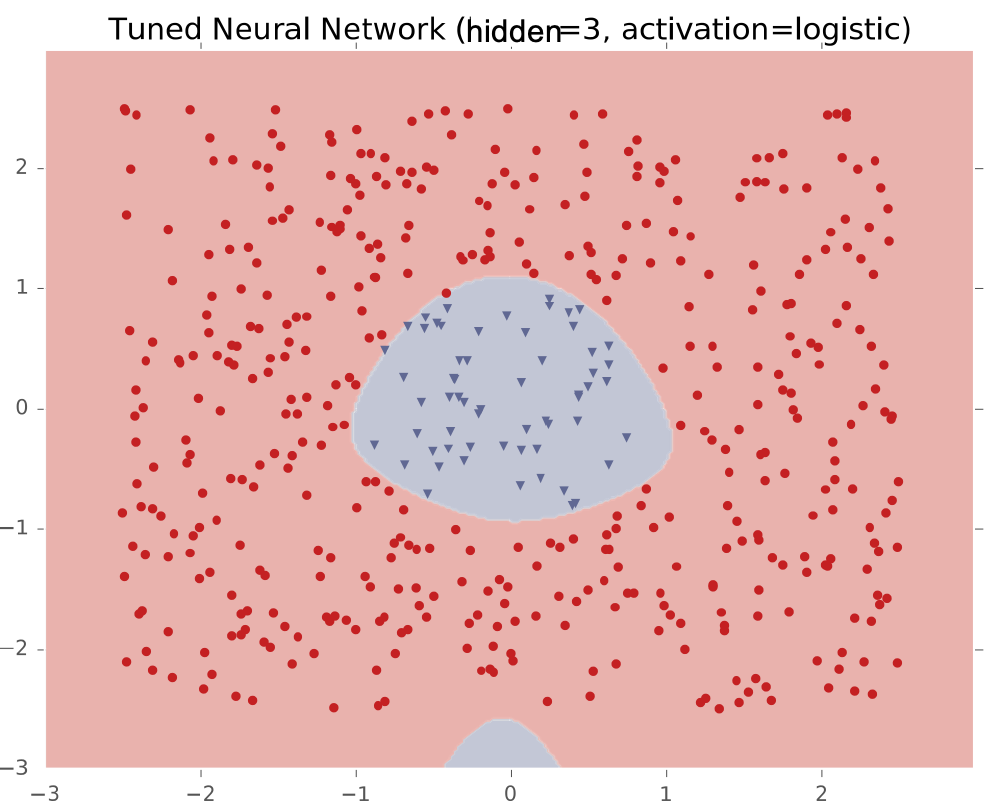
Ví dụ #2: Một cụm biệt lập
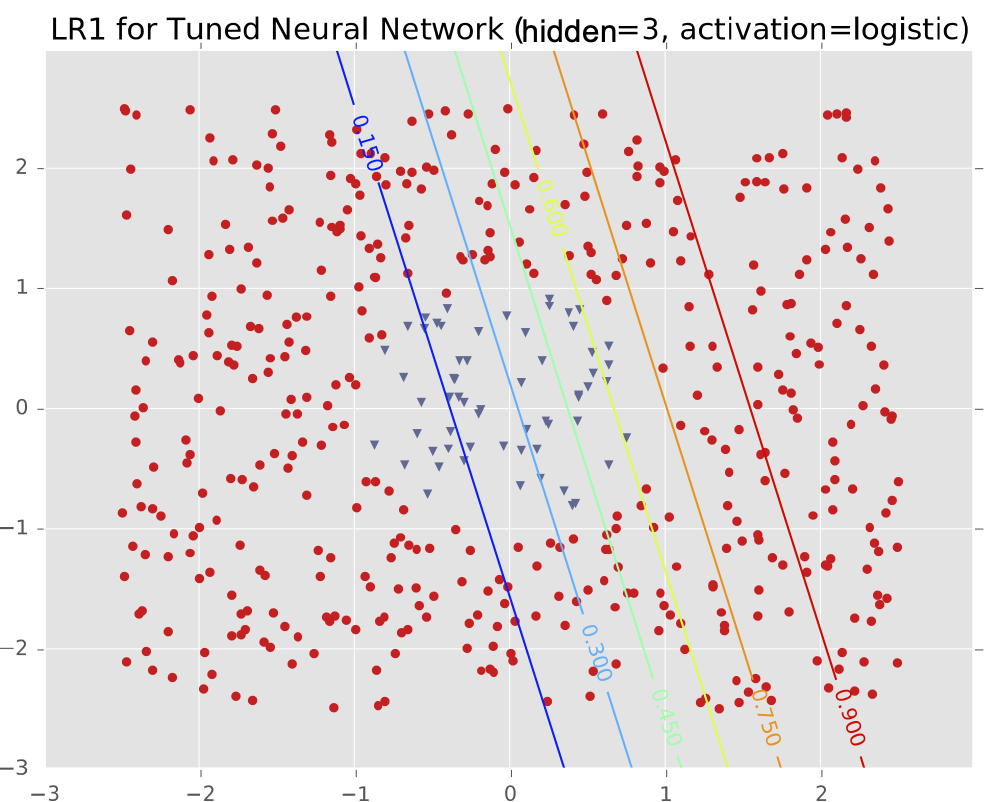
Ví dụ #2: Một cụm biệt lập

Ví dụ #2: Một cụm biệt lập

Ví dụ #2: Một cụm biệt lập
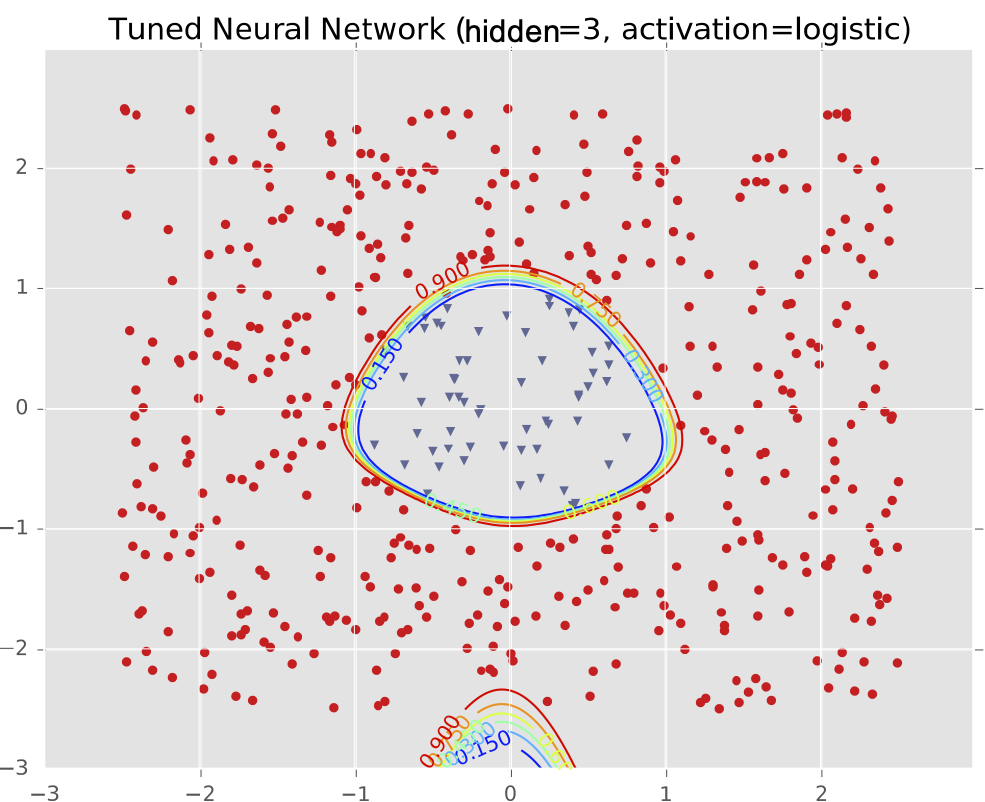
Ví dụ #2: Một cụm biệt lập

VÍ DỤ BIÊN QUYẾT ĐỊNH
Ví dụ 3 và 4
Ví dụ 3 và 4
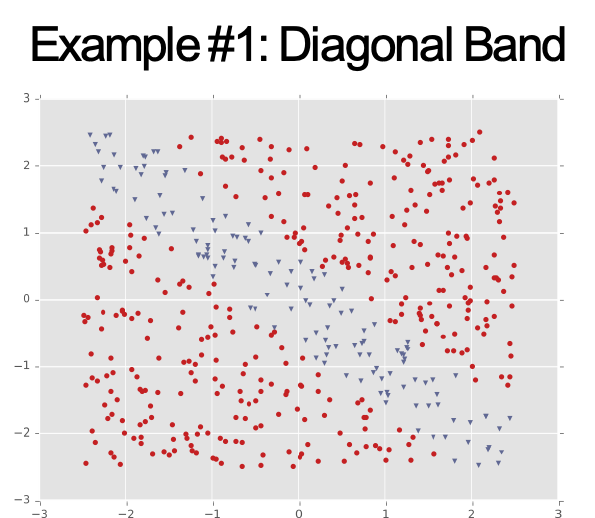
Ví dụ #1: Dải chéo
Ví dụ #2: Một cụm biệt lập
Ví dụ #3: Bốn cụm Gaussian
Ví dụ #4: Hai cụm biệt lập
Ví dụ #3: Bốn cụm Gaussian
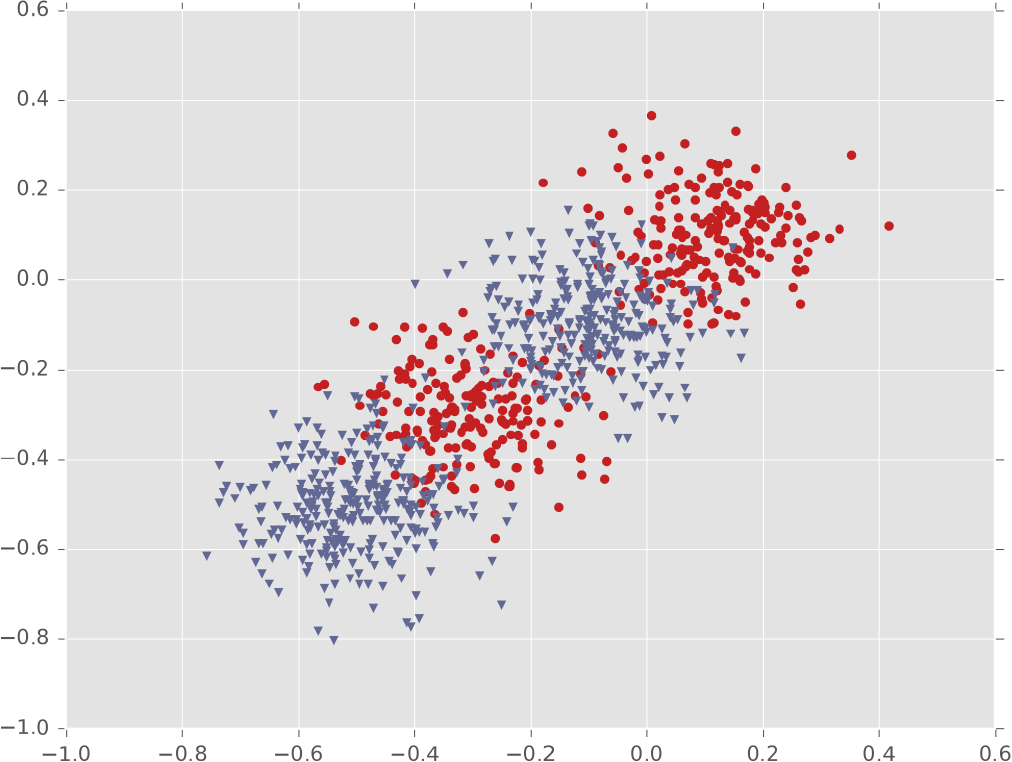
Ví dụ #3: Bốn cụm Gaussian

Ví dụ #3: Bốn cụm Gaussian
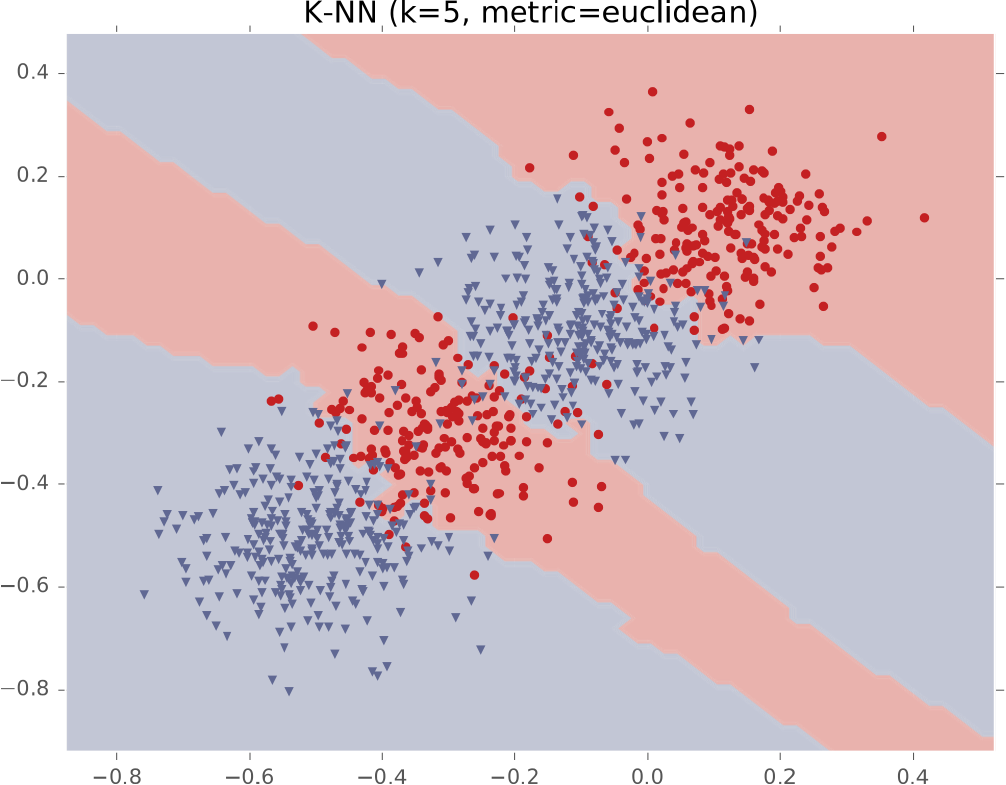
Ví dụ #3: Bốn cụm Gaussian
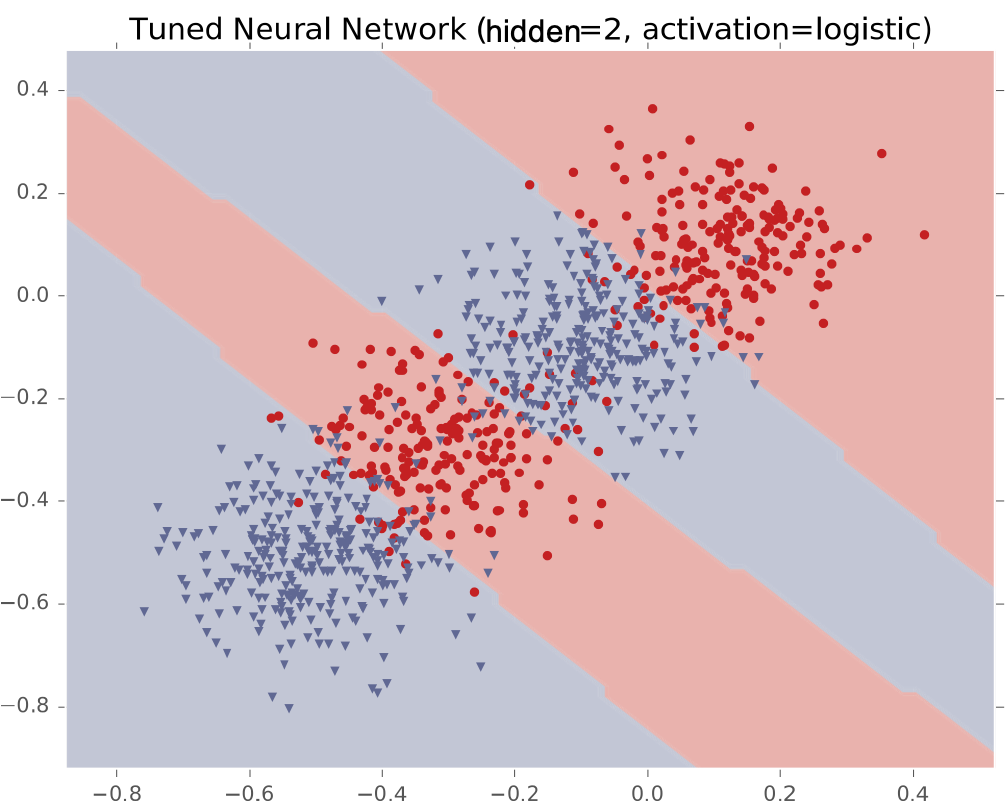
Ví dụ #3: Bốn cụm Gaussian

Ví dụ #3: Bốn cụm Gaussian

Ví dụ #3: Bốn cụm Gaussian

Ví dụ #4: Hai cụm biệt lập

Ví dụ #4: Hai cụm biệt lập
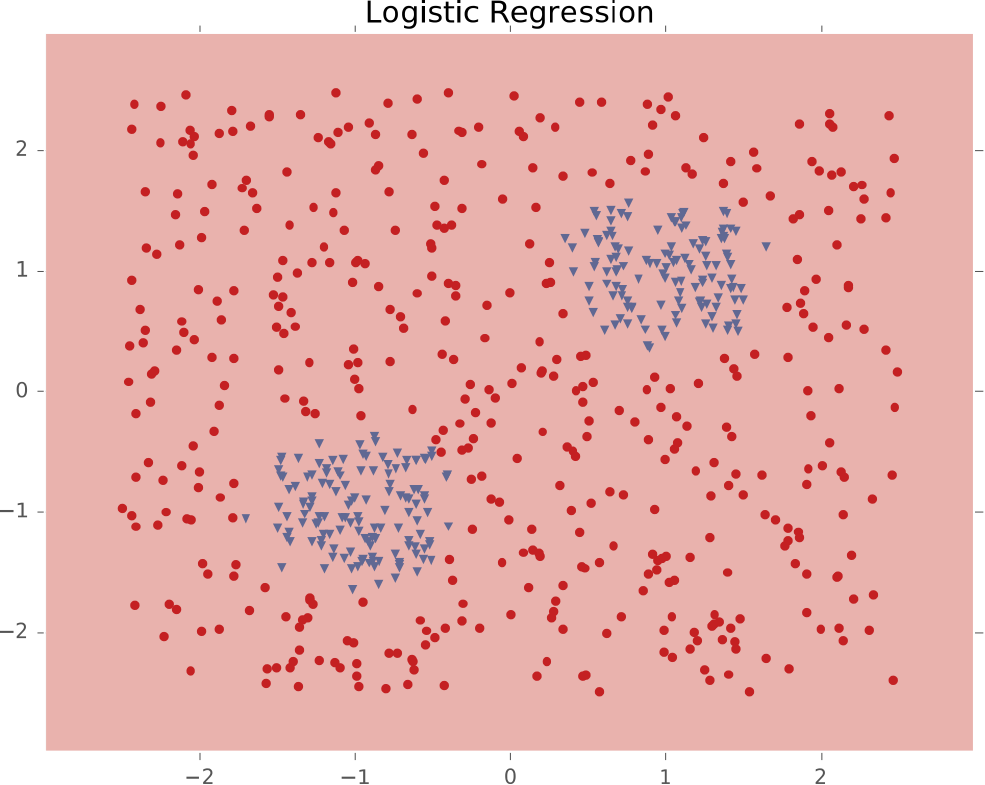
Ví dụ #4: Hai cụm biệt lập
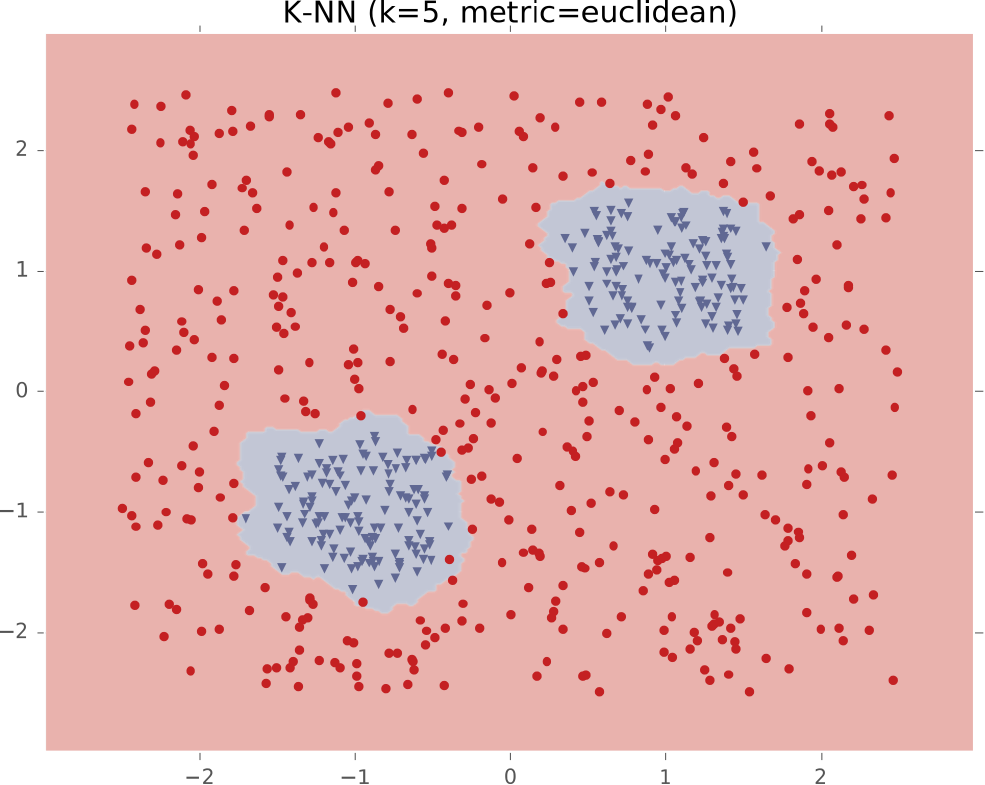
Ví dụ #4: Hai cụm biệt lập
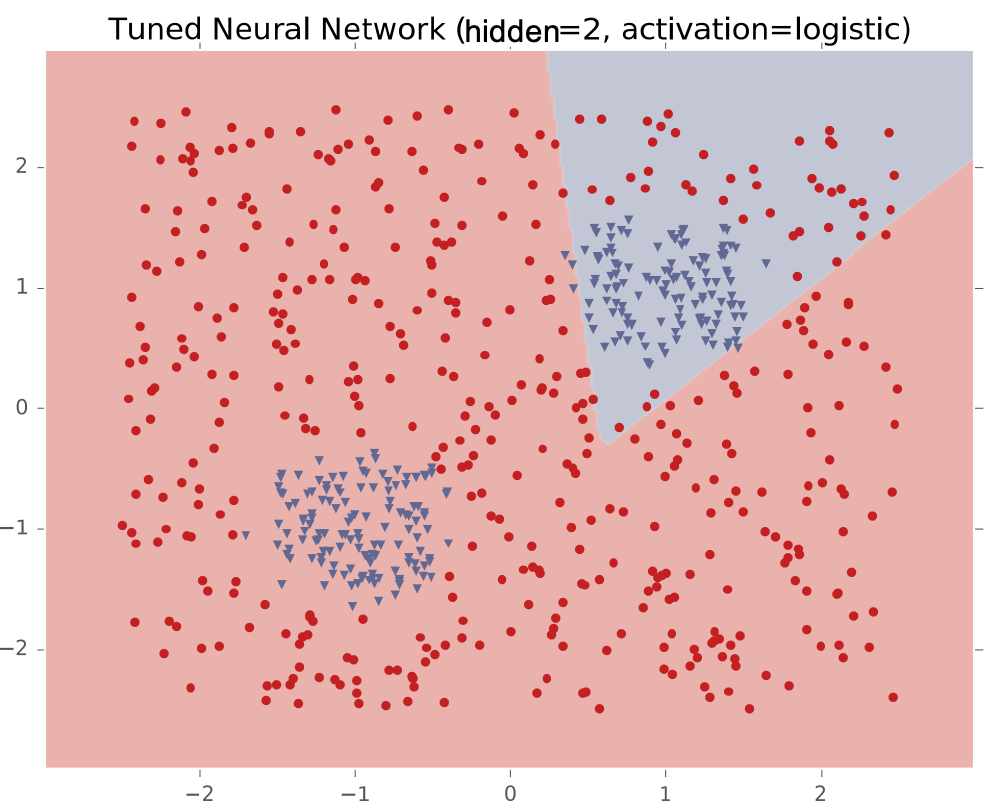
Ví dụ #4: Hai cụm biệt lập

Ví dụ #4: Hai cụm biệt lập

Ví dụ #4: Hai cụm biệt lập

XÂY DỰNG MẠNG SÂU HƠN
Mạng nơ-ron
Ví dụ: Mạng nơ-ron với 2 Lớp ẩn và 2 đơn vị ẩn

Mạng nơ-ron (Dạng ma trận)
Ví dụ: Mạng nơ-ron truyền thẳng tùy ý
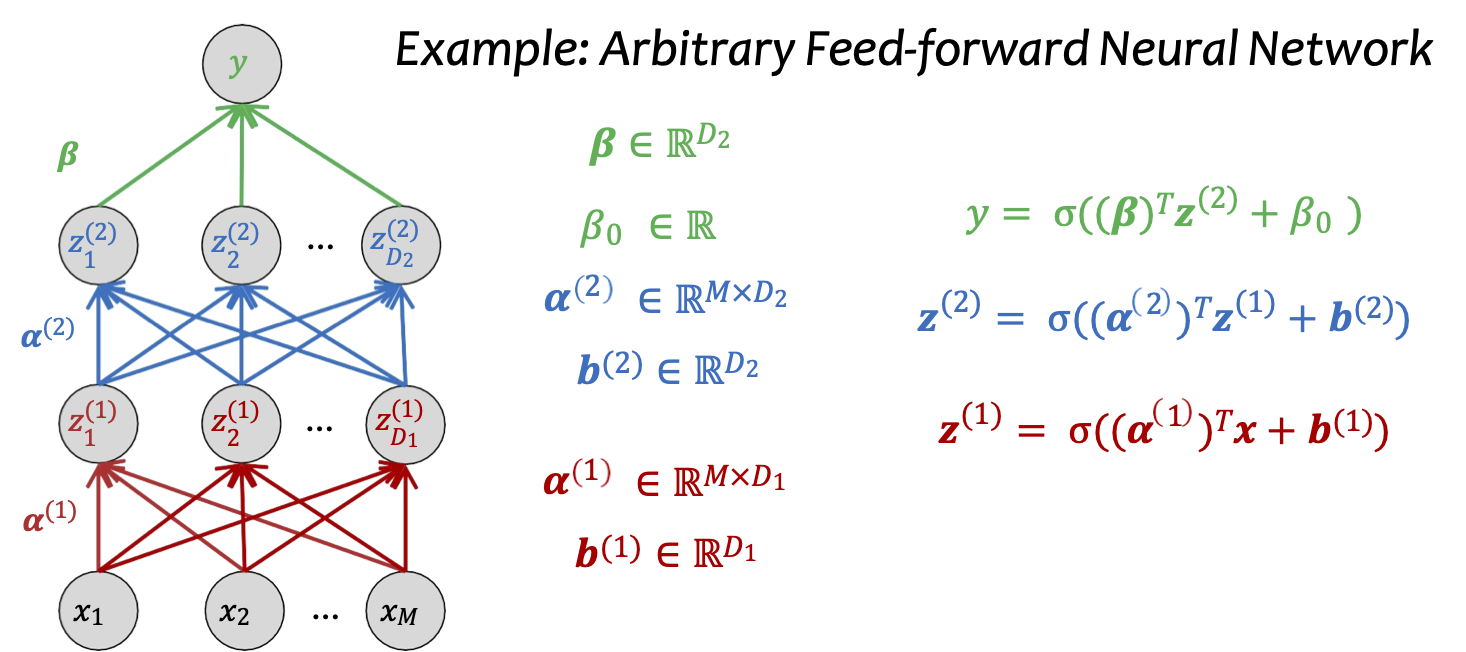
Mạng nơ-ron (Dạng vectơ)
Mạng nơ-ron với 1 lớp ẩn và 2 Đơn vị ẩn (Dạng Ma trận)
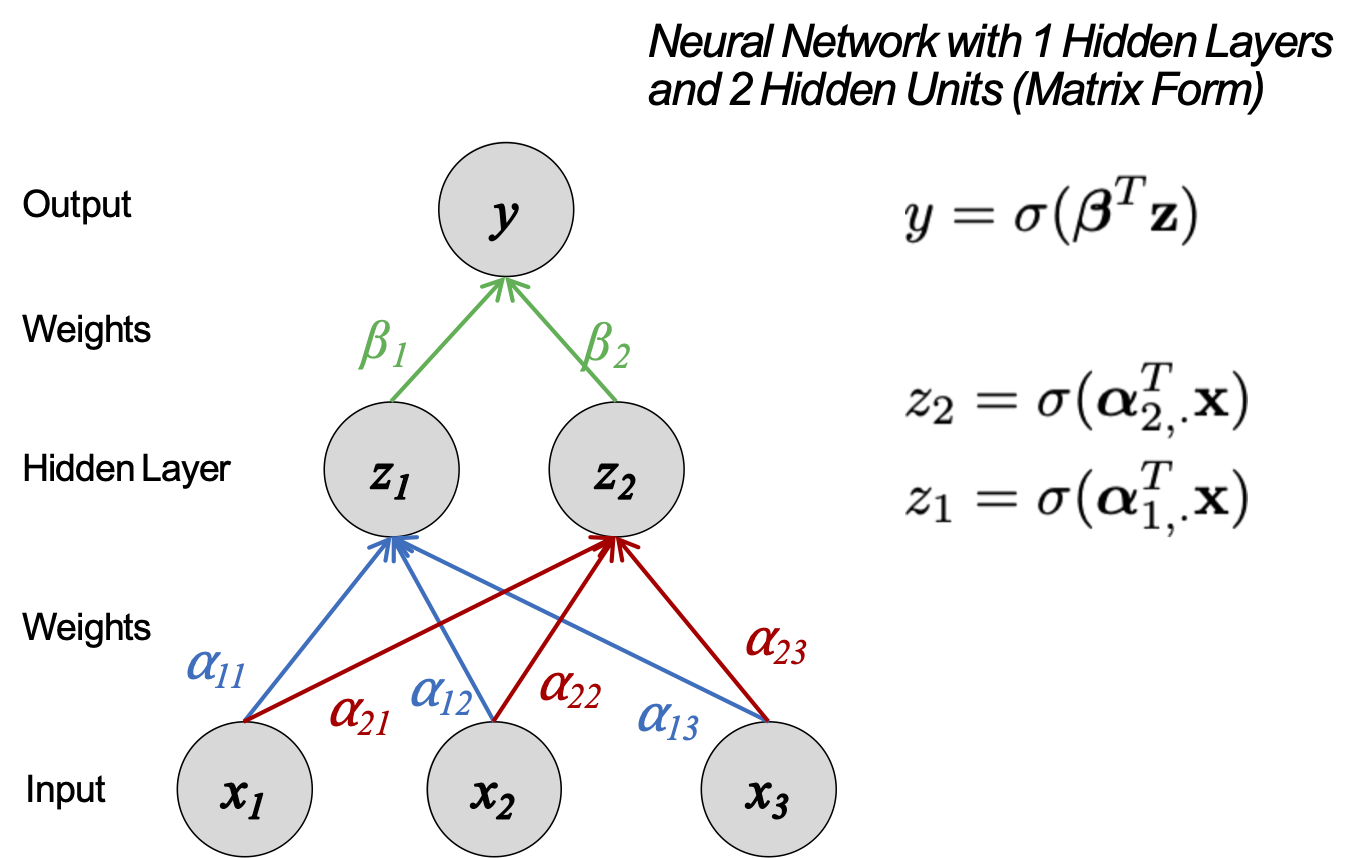
Mạng sâu hơn
H: Chúng ta nên sử dụng bao nhiêu lớp?

Mạng sâu hơn
H: Chúng ta nên sử dụng bao nhiêu lớp?
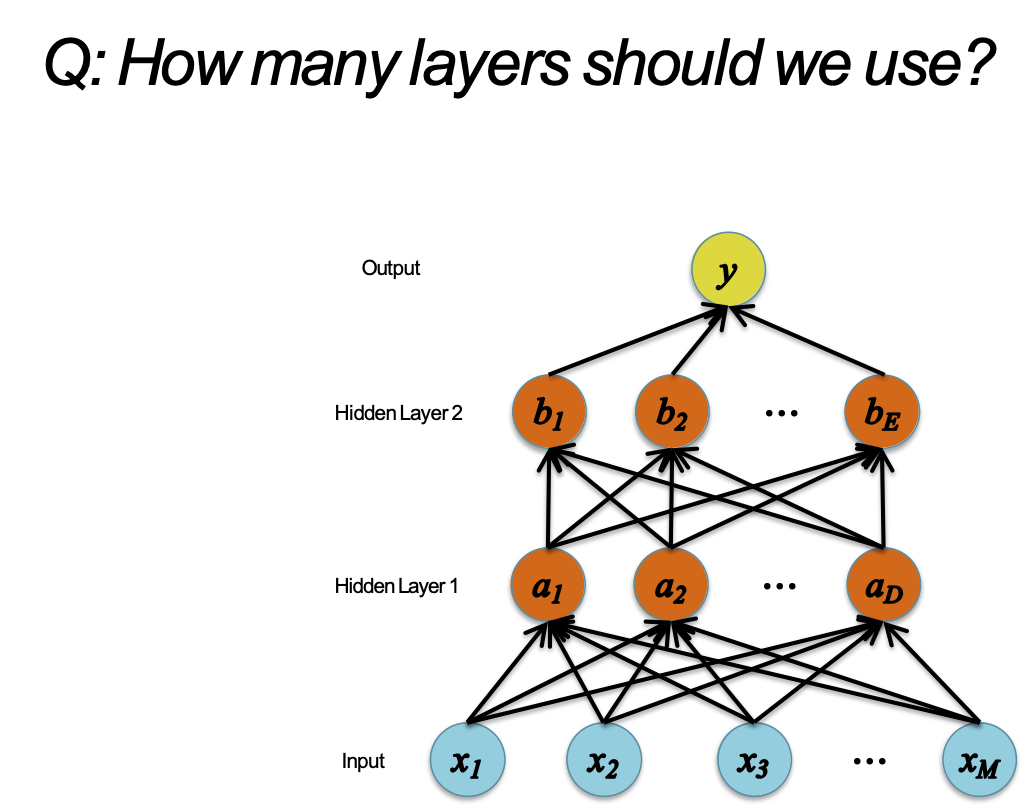
Mạng sâu hơn
H: Chúng ta nên sử dụng bao nhiêu lớp?

Mạng sâu hơn
H: Chúng ta nên sử dụng bao nhiêu lớp?
- Đáp án lý thuyết:
– Mạng nơ-ron có 1 lớp ẩn là một bộ xấp xỉ hàm phổ quát
– Cybenko (1989): Đối với bất kỳ hàm liên tục g(x), thì tồn tại một mạng nơ-ron 1 lớp ẩn hθ(x) s.t. | hθ(x) – g(x) | < ϵ cho mọi x, giả sử hàm kích hoạt sigmoid
- Câu trả lời thực nghiệm:
– Trước năm 2006: “Mạng sâu (ví dụ 3 hoặc nhiều lớp ẩn) quá khó để đào tạo”
– Sau năm 2006: “Mạng sâu dễ đào tạo hơn mạng nông (ví dụ 2 lớp hoặc ít hơn) cho nhiều bài toán”
Lưu ý quan trọng: Bạn cần biết và sử dụng đúng thủ thuật.
Học đặc trưng
- Kỹ thuật trích chọn đặc trưng truyền thống: xây dựng các cấp độ trừu tượng bằng tay
- Mạng sâu (ví dụ mạng tích chập): học các cấp độ trừu tượng ngày càng cao hơn từ dữ liệu
– mỗi lớp là một biểu diễn đặc trưng đã học
– sự tinh tế tăng lớp cao hơn

Số liệu từ Lee et al. (ICML 2009)
Học đặc trưng
- Kỹ thuật trích chọn đặc trưng truyền thống: xây dựng các cấp độ trừu tượng bằng tay
- Mạng sâu (ví dụ mạng tích chập): học các cấp độ trừu tượng ngày càng cao hơn từ dữ liệu
– mỗi lớp là một biểu diễn đặc trưng đã học
– sự tinh tế tăng lớp cao hơn

Số liệu từ Lee et al. (ICML 2009)
Học đặc trưng
- Kỹ thuật trích chọn đặc trưng truyền thống: xây dựng các cấp độ trừu tượng bằng tay
- Mạng sâu (ví dụ mạng tích chập): học các cấp độ trừu tượng ngày càng cao hơn từ dữ liệu
– mỗi lớp là một biểu diễn đặc trưng đã học
– sự tinh tế tăng lớp cao hơn
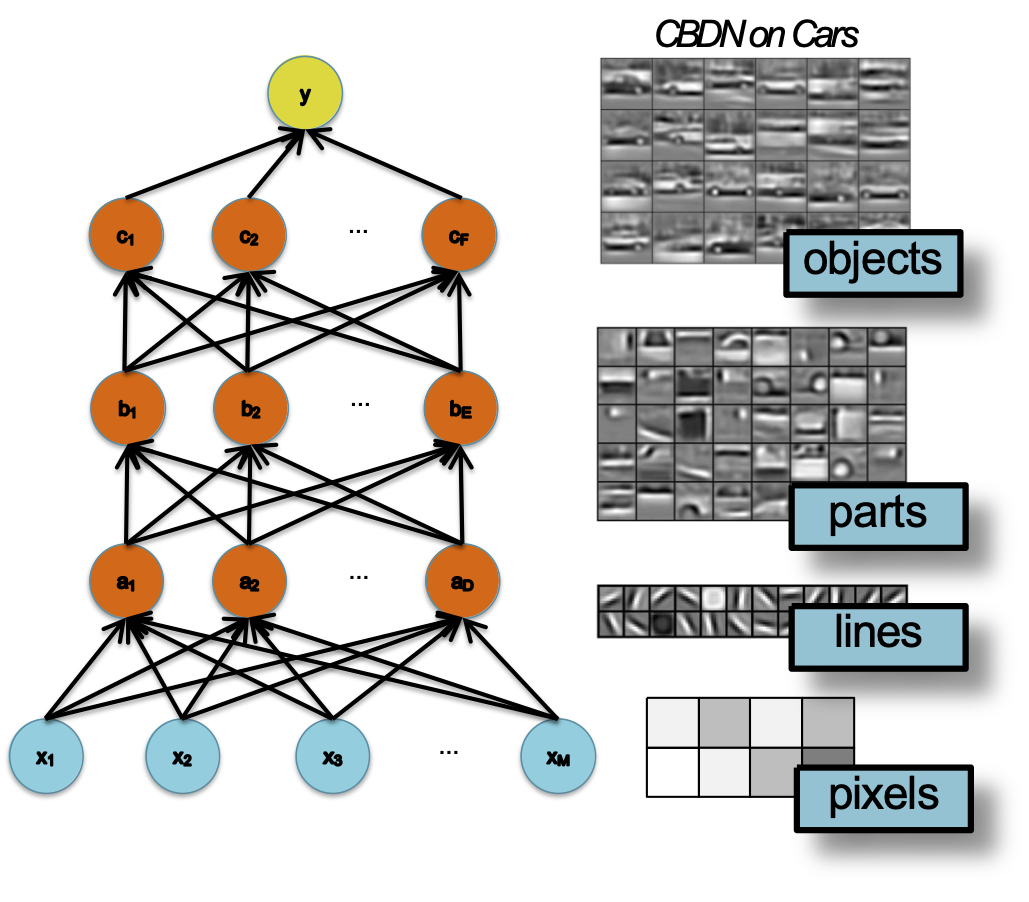
Số liệu từ Lee et al. (ICML 2009)
Lỗi mạng nơ-ron
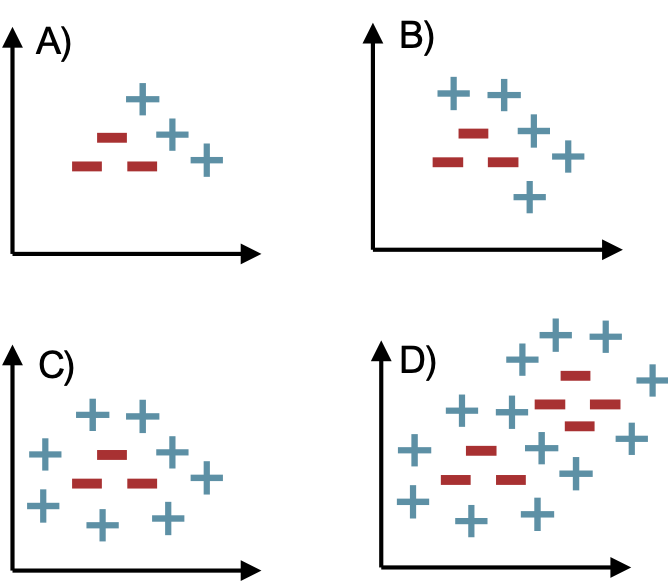
Câu hỏi X: Đối với tập dữ liệu nào dưới đây có tồn tại mạng thần kinh một lớp ẩn đạt được lỗi phân loại bằng không? Chọn tất cả các đáp án đúng.
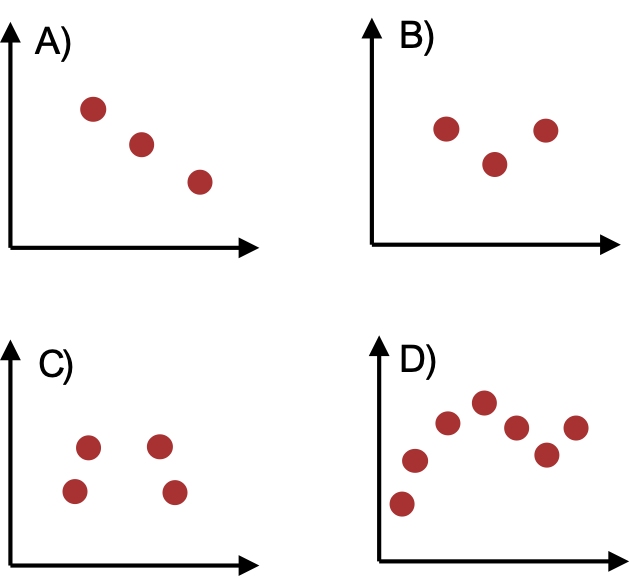
Câu hỏi Y: Đối với tập dữ liệu nào bên dưới có tồn tại mạng thần kinh một lớp ẩn để hồi quy đạt được MSE gần bằng không? Chọn tất cả các đáp án đúng.
Kiến trúc mạng nơ-ron
Ngay cả đối với một Mạng nơ-ron cơ bản, vẫn có nhiều quyết định thiết kế cần đưa ra:
- # lớp ẩn (độ sâu)
- # đơn vị trên mỗi lớp ẩn (chiều rộng)
- Loại hàm kích hoạt (phi tuyến tính)
- Dạng hàm mục tiêu
- Cách khởi tạo các tham số
HÀM KÍCH HOẠT
Hàm kích hoạt
Mạng nơ-ron với hàm kích hoạt sigmoid
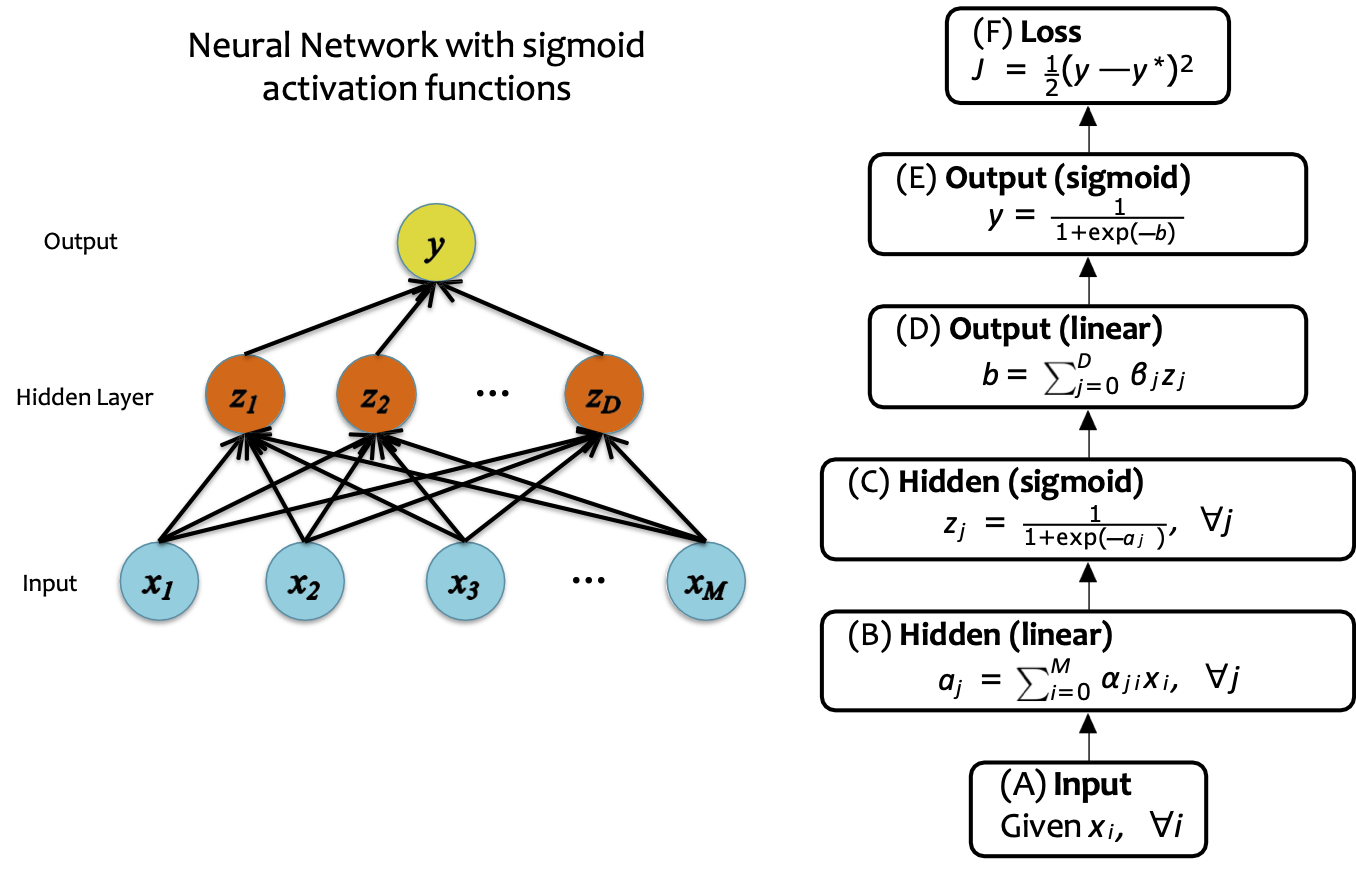
Hàm kích hoạt
Mạng nơ-ron với hàm kích hoạt phi tuyến tính tùy ý

Hàm kích hoạt
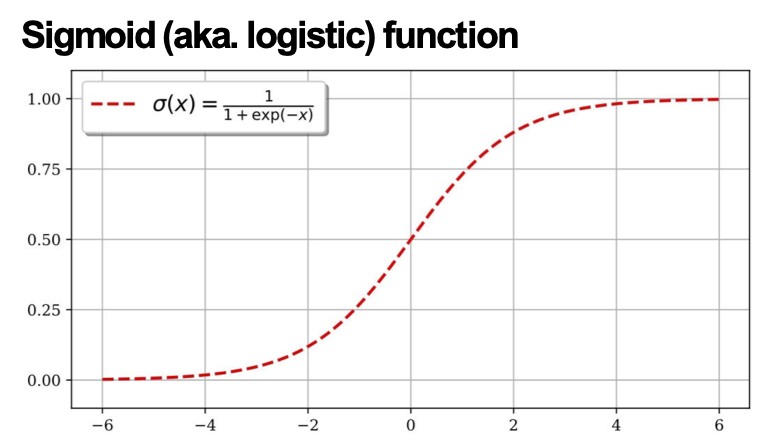
Cho đến nay, chúng ta đã giả định rằng hàm kích hoạt (phi tuyến tính) luôn là hàm sigmoid…
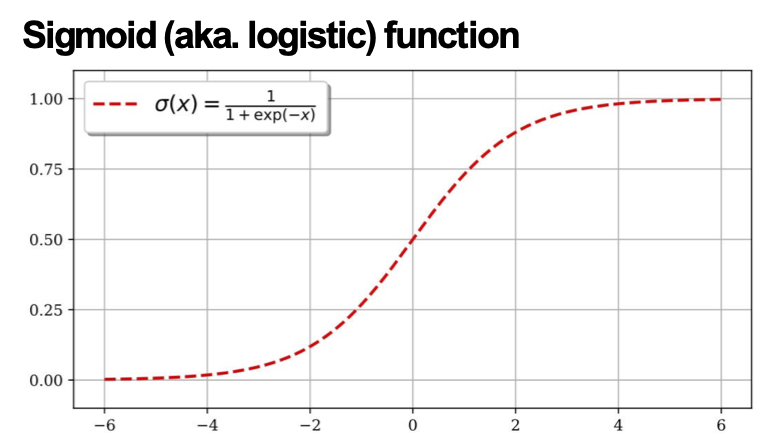
…nhưng hàm sigmoid không được sử dụng rộng rãi trong mạng thần kinh hiện đại
Hàm kích hoạt
- sigmoid, σ(x)
– đầu ra trong phạm vi (0,1)
– tốt cho đầu ra xác suất
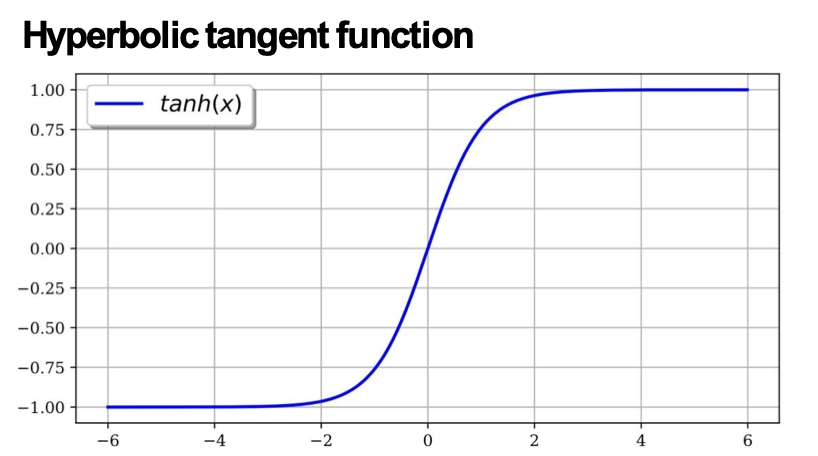
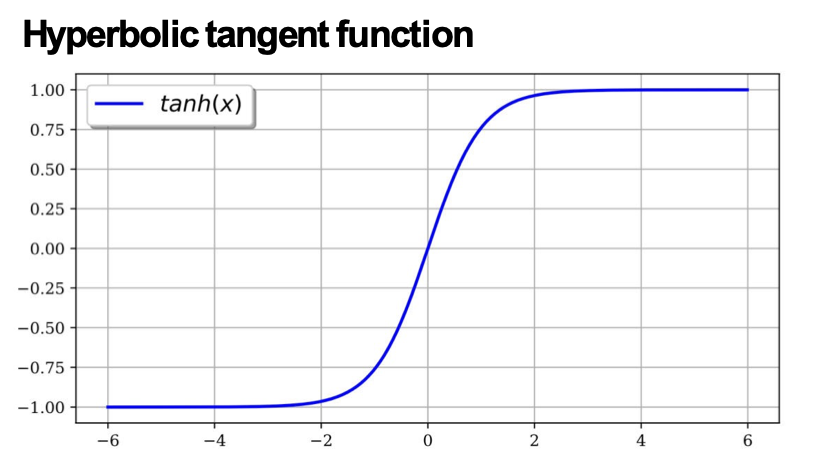
- hyperbolic tangent, tanh(x)
– hình dạng tương tự như sigmoid, nhưng đầu ra trong phạm vi (- 1,+1)
Thống kê AI năm 2010
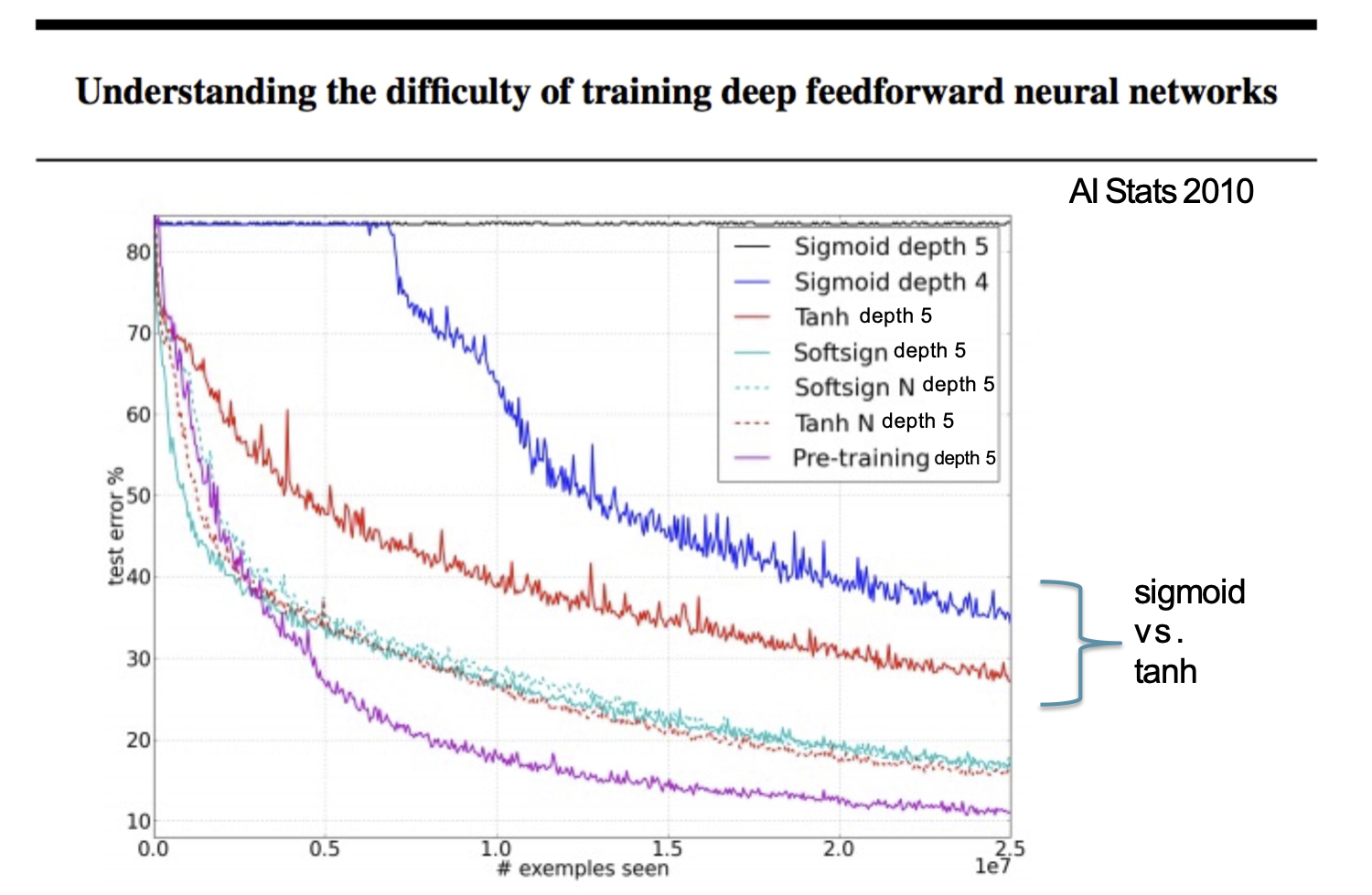
Hình từ Glorot & Bentio (2010)
Hàm kích hoạt
- Đơn vị tuyến tính chỉnh lưu (ReLU)
– tránh được vấn đề độ dốc biến mất
– Đạo hàm được tính toán nhanh
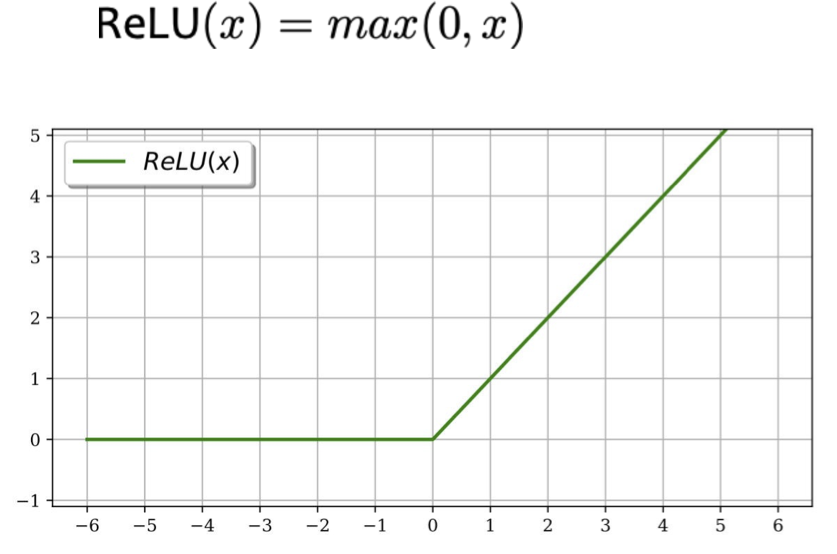
Hàm kích hoạt
- Đơn vị tuyến tính chỉnh lưu (ReLU)
– tránh được vấn đề độ dốc biến mất
– Đạo hàm được tính toán nhanh
- Đơn vị Tuyến tính hàm mũ (ELU)
– giống như ReLU khi đầu vào dương
– khác ReLU, cho phép đầu ra âm và chuyển tiếp trơn tru khi x < 0
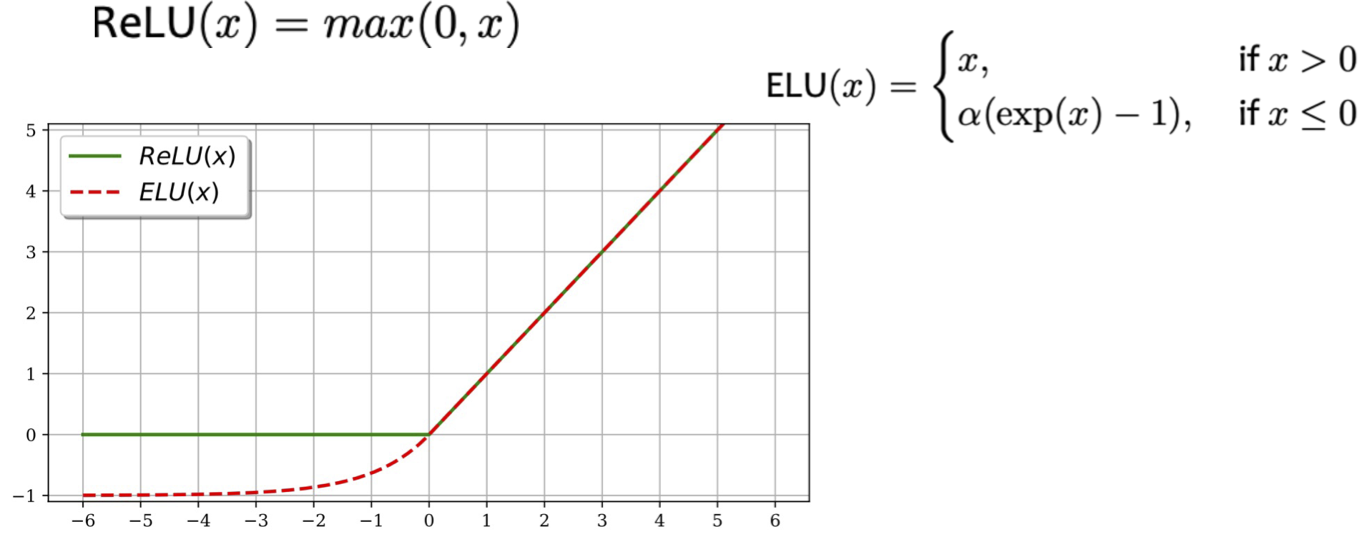
Hàm kích hoạt
- Hàm mất mát trong quá trình đào tạo hội tụ nhanh nhất với ELU
- ELU(x) tạo ra lỗi kiểm tra thấp hơn ReLU(x) trên CIFAR-10
Chuẩn đánh giá phân loại hình ảnh (CIFAR-10)

Hình ảnh từ Clevert et al. (2016)
HÀM MẤT MÁT & LỚP ĐẦU RA
Mạng nơ-ron để phân loại

Mạng nơ-ron cho hồi quy
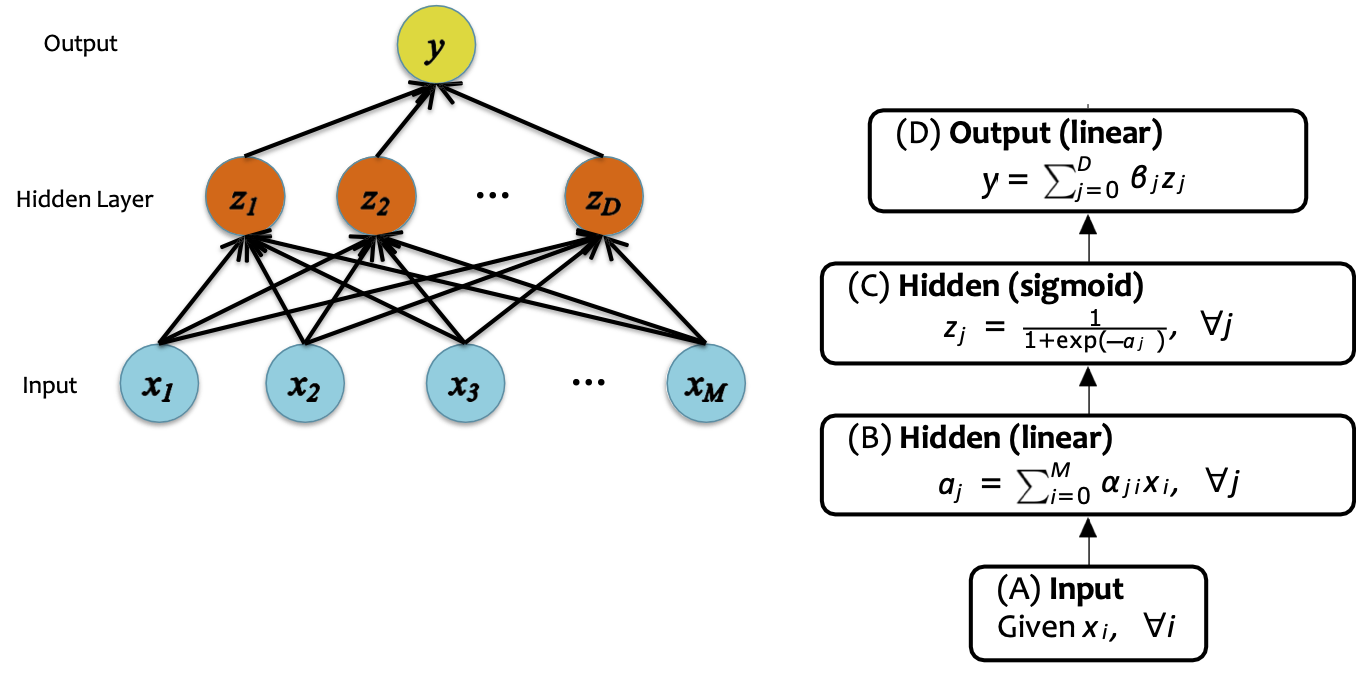
Các hàm mục tiêu cho NN
1. Mất mát bậc hai:
– cùng mục tiêu với Hồi quy tuyến tính
– tức là lỗi bình phương trung bình
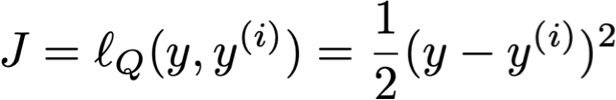
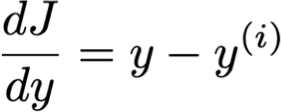
2. Entropy chéo nhị phân:
– cùng mục tiêu như hồi quy logistic nhị phân
– tức là logarit có khả năng âm
– Điều này yêu cầu đầu ra y của chúng ta phải là một xác suất trong [0,1]
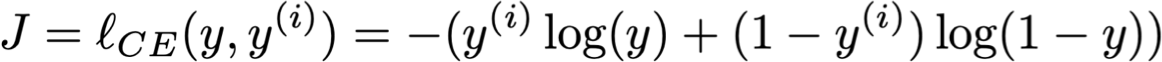
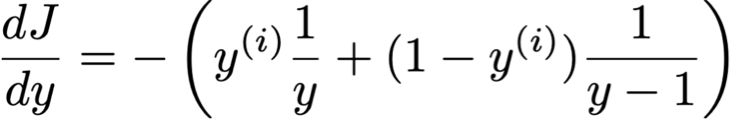
Các hàm mục tiêu cho NN
Entropy chéo so với mất mát bậc hai
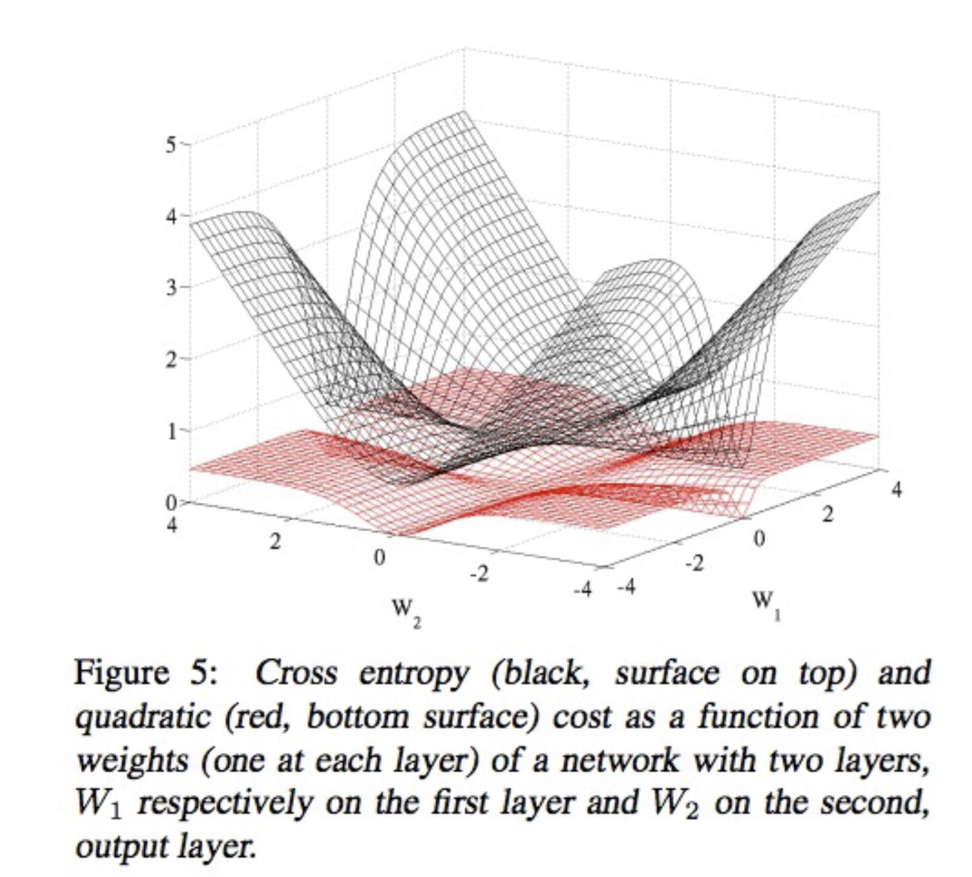
Hình từ Glorot & Bentio (2010)
Đầu ra đa lớp

Đầu ra đa lớp
Softmax:
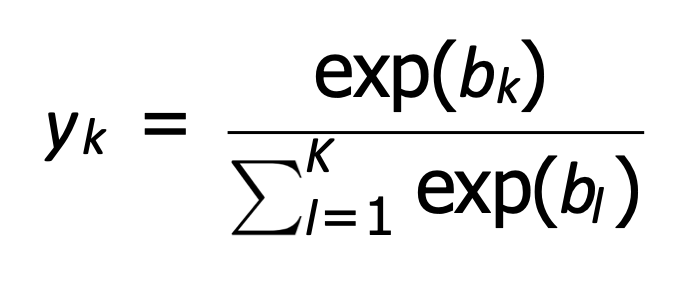
Các hàm mục tiêu cho NN
3. Entropy chéo cho đầu ra đa lớp:
– tức là logarit có khả năng âm cho đầu ra đa lớp
– Giả sử đầu ra là một biến ngẫu nhiên Y lấy một trong K giá trị
– Giả sử y(i) biểu diễn nhãn thực của chúng ta dưới dạng vector one-hot:

– Giả sử mô hình của chúng ta đưa ra một vectơ xác suất có độ dài K:
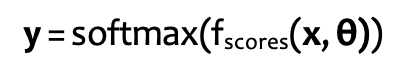
– Khi đó, chúng ta có thể viết log-likelihood của một mẫu huấn luyện đơn (x(i), y(i)) như sau:
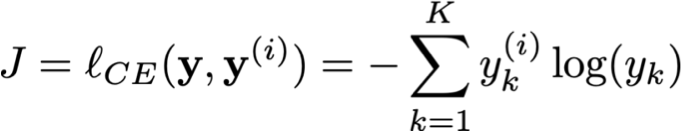
Mục tiêu của mạng nơ-ron
Bạn sẽ có thể…
- Giải thích động cơ sinh học cho mạng nơ-ron
- Kết hợp các mô hình đơn giản hơn (ví dụ hồi quy tuyến tính, hồi quy logistic nhị phân, hồi quy logistic đa thức) như các thành phần để xây dựng kiến trúc mạng nơ-ron truyền thẳng
- Giải thích lý do tại sao mạng nơ-ron có thể mô hình hóa biên quyết định phi tuyến tính cho phân loại
- So sánh và đối chiếu kỹ thuật trích chọn đặc trưng với học đặc trưng
- Xác định (một số) các tùy chọn có sẵn khi thiết kế kiến trúc của mạng nơ-ron
- Triển khai mạng nơ-ron truyền thẳng