Đọc:
- Chương 14.3: Hastie, Tibshirani, Friedman.
Các nguồn bổ sung:
- Phân cụm dựa trên trung tâm: Quan điểm nền tảng. Awathi, Balcan. Sổ tay phân tích cụm. 2015.
Hậu cần
- Dự án:
- Đánh giá Midway đến hạn hôm nay.
- Báo cáo cuối kỳ, ngày 8 tháng 5.
- Trình bày áp phích, ngày 11 tháng 5.
- Giao tiếp với cố vấn TA của bạn!
- Kỳ thi số 2 vào ngày 29 tháng 4.
Phân cụm, Mục tiêu không chính thức
Mục tiêu: Tự động phân vùng dữ liệu chưa được gắn nhãn thành các nhóm của các điểm dữ liệu tương tự.
Câu hỏi: Khi nào và tại sao chúng ta muốn làm điều này?
Hữu ích cho:
- Tự động tổ chức dữ liệu.
- Tìm hiểu cấu trúc ẩn trong dữ liệu.
- Tiền xử lý để phân tích thêm.
- Biểu diễn dữ liệu nhiều chiều trong không gian ít chiều (ví dụ: cho mục đích trực quan hóa).
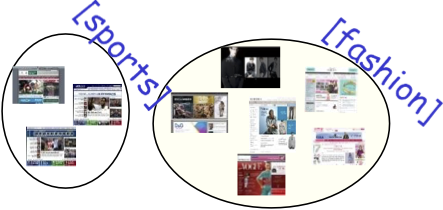
Các ứng dụng (Clustering xuất hiện ở mọi nơi…)
- Cụm tin bài hoặc trang web hoặc kết quả tìm kiếm theo chủ đề.

- Cụm chuỗi protein theo chức năng hoặc gen theo hồ sơ biểu hiện.

- Nhóm người dùng mạng xã hội theo sở thích (dò tìm cộng đồng).

Các ứng dụng (Clustering xuất hiện ở mọi nơi…)
- Phân cụm khách hàng theo lịch sử mua hàng.
- Cụm thiên hà hoặc các ngôi sao gần đó (ví dụ: Khảo sát bầu trời kỹ thuật số Sloan)

- Và còn rất nhiều ứng dụng khác….
Phân cụm
Hôm nay:
- Phân cụm dựa trên mục tiêu
- Phân cụm theo thứ bậc
- Đề cập đến các cụm chồng chéo
[Ngày 4 tháng 3: Thuật toán phân cụm kiểu EM để phân cụm cho hỗn hợp Gaussian (mô hình xác suất cụ thể).]
Phân cụm dựa trên mục tiêu
Đầu vào: Một tập hợp S gồm n điểm, cũng là thước đo khoảng cách/độ khác nhau xác định khoảng cách d(x,y) giữa các cặp (x,y).
Ví dụ: # từ khóa chung, chỉnh sửa khoảng cách, wavelet coef., v.v.
Mục tiêu: xuất ra một phân vùng dữ liệu.
– k-means: tìm điểm tâm 𝒄𝟏, 𝒄𝟐, … , 𝒄𝒌 để cực tiểu ∑i=1n minj∈ {1,…,k} d2(𝐱𝐢, 𝐜𝐣)
– k-median: tìm điểm trung tâm 𝐜𝟏, 𝐜𝟐, … , 𝐜𝐤 để giảm thiểu ∑i=1n minj∈ {1,…,k} d(𝐱𝐢, 𝐜𝐣)
– K-center: tìm phân vùng để cực tiểu hóa bán kính cực đại
Phân cụm Euclidean k-means
Đầu vào: Một bộ n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝒏 in Rd Mục tiêu #clusters k
Đầu ra: k đại diện 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd
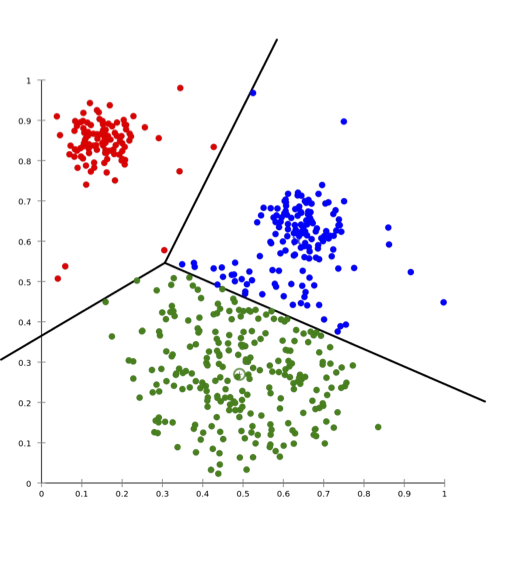
Mục tiêu: chọn 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd để giảm thiểu
∑i=1n minj∈ {1,…,k} ||𝐱𝐢 − 𝐜𝐣|| 2
Phân cụm Euclidean k-means
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝒏 trong Rd Mục tiêu #cluster k
Đầu ra: k đại diện 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd
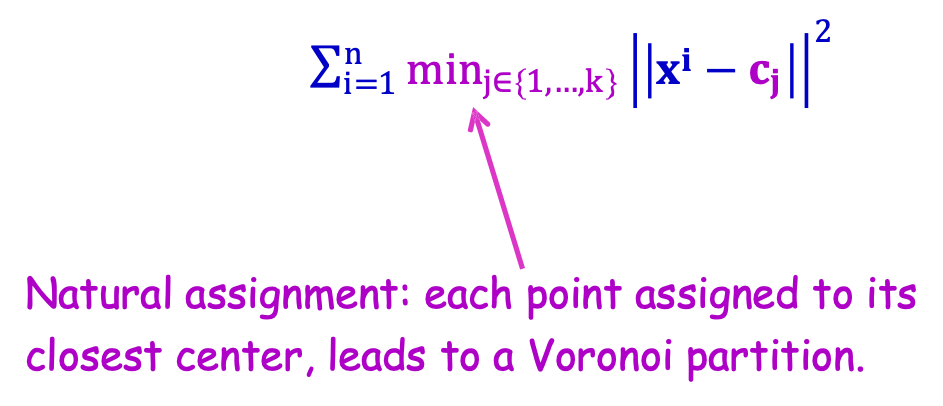
Mục tiêu: chọn 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd để giảm thiểu
∑i=1n minj∈ {1,…,k} ||𝐱𝐢 − 𝐜𝐣|| 2
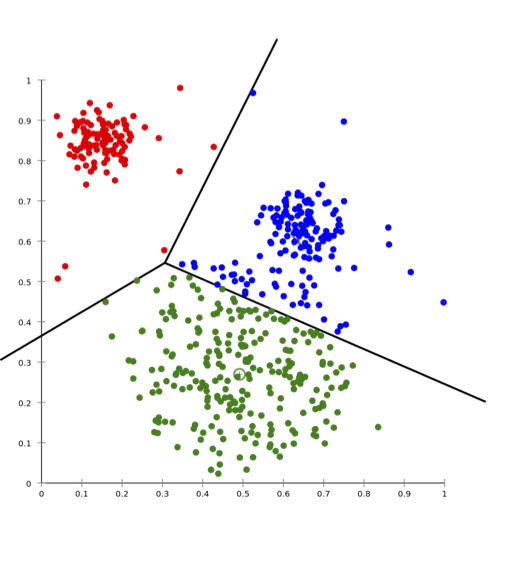
Phép gán tự nhiên: mỗi điểm được gán cho tâm gần nhất của nó, dẫn đến một phân vùng Voronoi.
Phân cụm Euclidean k-means
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝒏 trong Rd Mục tiêu #cluster k
Đầu ra: k đại diện 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd
Mục tiêu: chọn 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd để giảm thiểu
∑i=1n minj∈ {1,…,k} ||𝐱𝐢 − 𝐜𝐣|| 2
Độ phức tạp tính toán:
NP khó: ngay cả với k = 2 [Dagupta’08] hoặc d = 2 [Mahajan-Nimbhorkar-Varadarajan09]
Có một số trường hợp dễ…
Trường hợp dễ cho k-means: k=1
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝒏 trong Rd
Kết quả: 𝒄 ∈ Rd để giảm thiểu ∑i=1n ||𝐱𝐢 − 𝐜|| 2
Giải: Lựa chọn tối ưu là 𝛍 = 1⁄n ∑i=1n 𝐱𝐢
Ý tưởng: độ lệch/phương sai như phân tách
1⁄n ∑i=1n ||𝐱𝐢 − 𝐜|| 2 = ||𝛍 − 𝐜|| 2 + 1⁄n ∑i=1n ||𝐱𝐢 − 𝛍|| 2
Chi phí k-mean trung bình wrt c
Chi phí k-mean trung bình wrt μ
Vì vậy, lựa chọn tối ưu cho 𝐜 là 𝛍.
Trường hợp dễ dàng khác cho k-means: d=1
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝒏 trong Rd
Đầu ra: 𝒄 ∈ Rd để giảm thiểu ∑i=1n ||𝐱𝐢 − 𝐜|| 2
Câu hỏi bài tập về nhà lấy thêm tín chỉ
Gợi ý: quy hoạch động trong thời gian O(n2k).
Phương pháp chẩn đoán phổ biến trong thực tế: Phương pháp của Lloyd
[Lượng tử hóa bình phương nhỏ nhất trong PCM, Lloyd, IEEE Giao dịch trên lý thuyết thông tin, 1982]
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐧 trong Rd
Khởi tạo các tâm 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd và các cụm C1, C2, … , Ck theo bất kỳ cách nào.
Lặp lại cho đến khi không có thay đổi nào nữa về chi phí.
- Với mỗi j: Cj ←{𝑥 ∈ 𝑆 có tâm gần nhất là 𝐜𝐣}
- Với mỗi j: 𝐜𝐣 ←trung bình của Cj
Common Heuristic in Practice: Phương pháp của Lloyd
[Lượng tử hóa bình phương nhỏ nhất trong PCM, Lloyd, IEEE Giao dịch trên Lý thuyết thông tin, 1982]
Đầu vào: Một tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐧 trong Rd
Khởi tạo các tâm 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 ∈ Rd và các cụm C1, C2, … , Ck theo bất kỳ cách nào.
Lặp lại cho đến khi không có thay đổi nào nữa về chi phí.
- Với mỗi j: Cj ←{𝑥 ∈ 𝑆 có tâm gần nhất là 𝐜𝐣}
- Với mỗi j: 𝐜𝐣 ←trung bình của Cj

Giữ 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌 cố định, chọn tối ưu C1, C2, … , Ck
Giữ C1, C2, … , Ck cố định, chọn tối ưu 𝒄𝟏, 𝐜𝟐, … , 𝒄𝒌
Common Heuristic: Phương pháp của Lloyd
Đầu vào: Tập hợp n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐧 trong Rd
Khởi tạo các tâm 𝐜𝟏, 𝐜𝟐, … , 𝐜𝐤 ∈ Rd và các cụm C1, C2, … , Ck theo bất kỳ cách nào.
Lặp lại cho đến khi không có thay đổi nào nữa về chi phí.
- Với mỗi j: Cj ←{𝑥 ∈ 𝑆 có tâm gần nhất là 𝐜𝐣}
- Với mỗi j: 𝐜𝐣 ←trung bình của Cj
Lưu ý: nó luôn hội tụ.
- chi phí luôn giảm xuống và
- chỉ có một số hữu hạn các phân vùng Voronoi (do đó, một số hữu hạn các giá trị mà chi phí có thể lấy)
Khởi tạo cho phương thức của Lloyd
Đầu vào: Một bộ n điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐧 trong Rd
Khởi tạo các tâm 𝐜𝟏, 𝐜𝟐, … , 𝐜𝐤 ∈ Rd và các cụm C1, C2, … , Ck theo một cách bất kỳ.
Lặp lại cho đến khi không có thay đổi nào nữa về chi phí.
- Với mỗi j: Cj ←{𝑥 ∈ 𝑆 có tâm gần nhất là 𝐜𝐣}
- Với mỗi j: 𝐜𝐣 ←trung bình của Cj
- Khởi tạo là rất quan trọng (tốc độ hội tụ, chất lượng của giải pháp đầu ra)
- Thảo luận về các kỹ thuật thường được sử dụng trong thực tế
- Các trung tâm ngẫu nhiên từ các điểm dữ liệu (lặp lại một vài lần)
- Truyền tải xa nhất
- K-means ++ (hoạt động tốt và có các đảm bảo có thể chứng minh được)
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Ví dụ: Cho một tập hợp các điểm dữ liệu

Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Chọn các tâm ban đầu một cách ngẫu nhiên

Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Gán mỗi điểm cho tâm gần nhất của nó
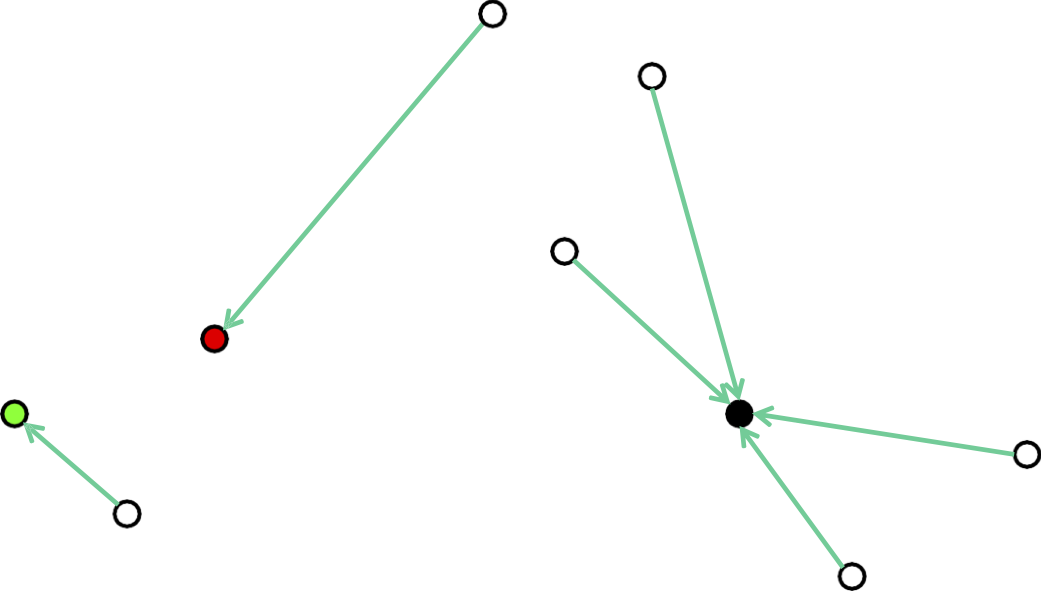
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Tính toán lại các trung tâm tối ưu cho một cụm cố định
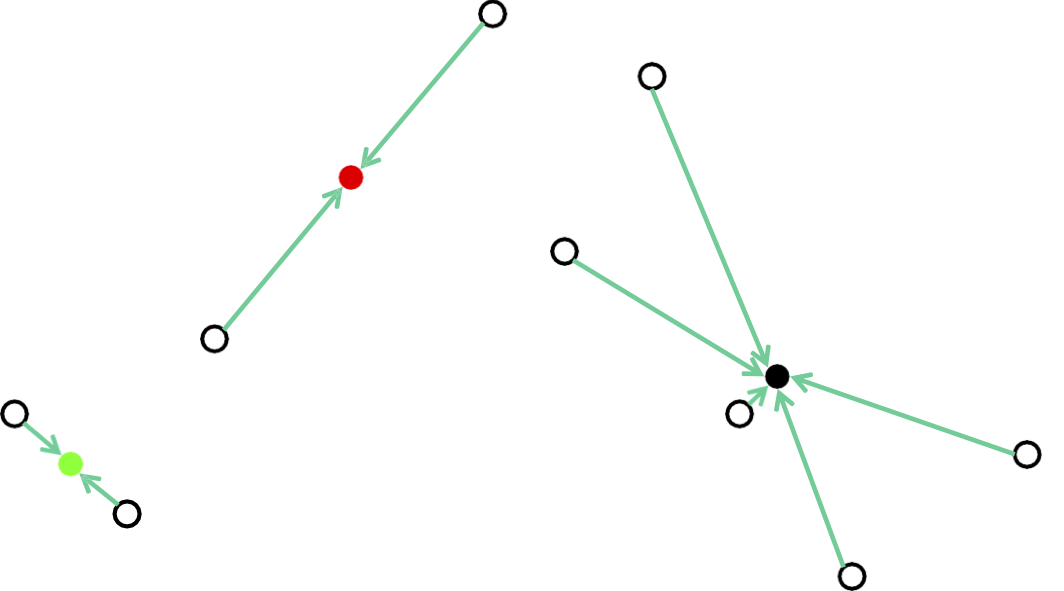
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Gán mỗi điểm cho tâm gần nhất của nó
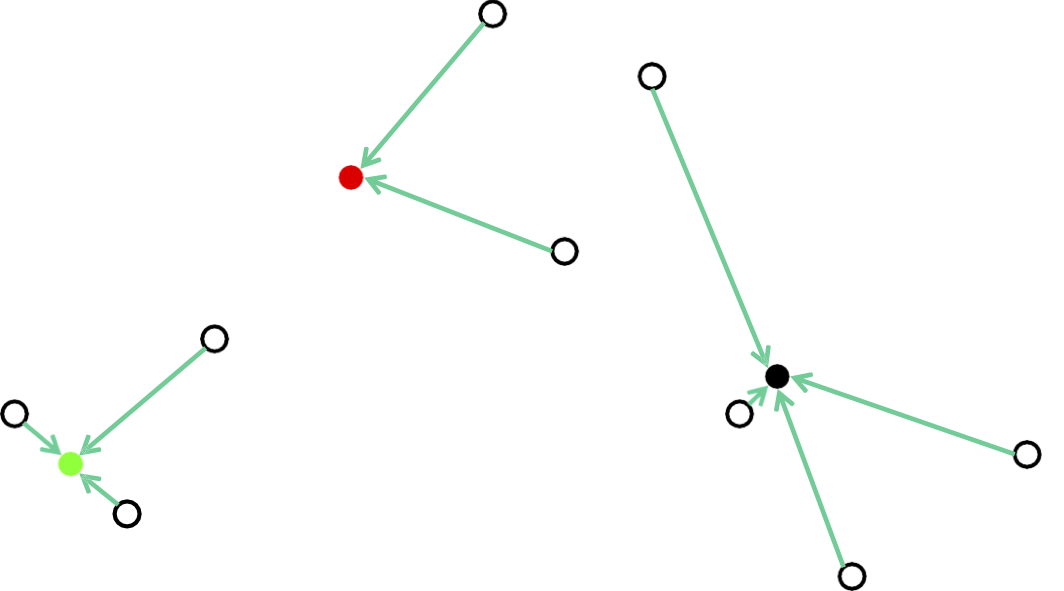
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Tính toán lại các trung tâm tối ưu được cung cấp một cụm cố định
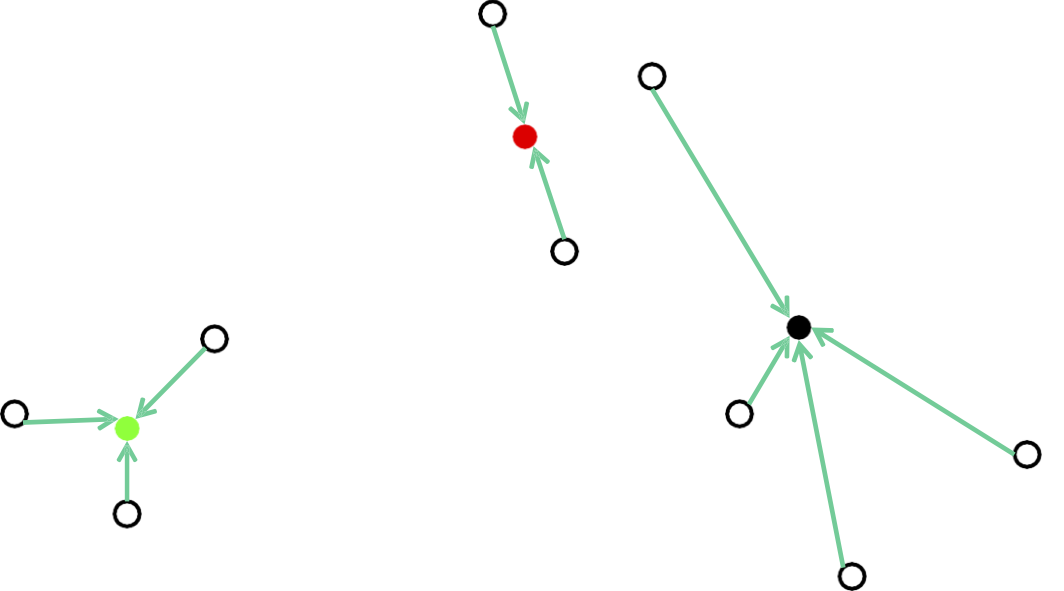
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Gán mỗi điểm cho tâm gần nhất của nó
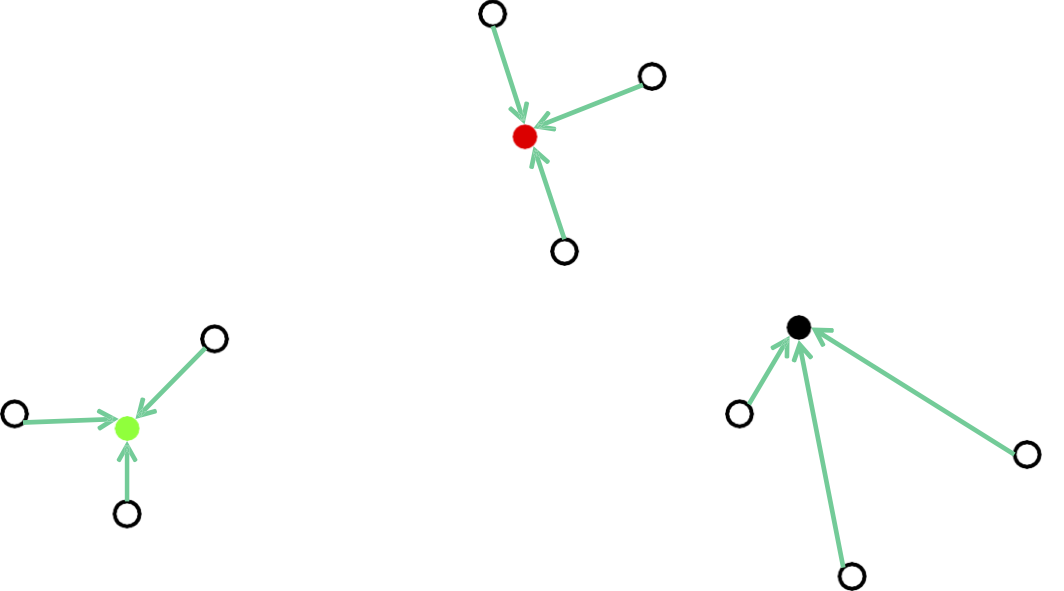
Phương pháp của Lloyd: Khởi tạo ngẫu nhiên
Tính toán lại các trung tâm tối ưu cho trước một cụm cố định
Lấy một giải pháp chất lượng tốt trong ví dụ này.
Phương pháp của Lloyd: Hiệu suất
Nó luôn hội tụ, nhưng nó có thể hội tụ ở mức tối ưu cục bộ khác với mức tối ưu toàn cục và trên thực tế có thể kém hơn tùy ý về điểm số của nó.
Phương pháp của Lloyd: Hiệu suất
Tối ưu cục bộ: mọi điểm được gán cho tâm gần nhất của nó và mọi tâm là giá trị trung bình của các điểm của nó.
Phương pháp của Lloyd: Hiệu suất
Nó tùy ý tệ hơn giải pháp tối ưu….
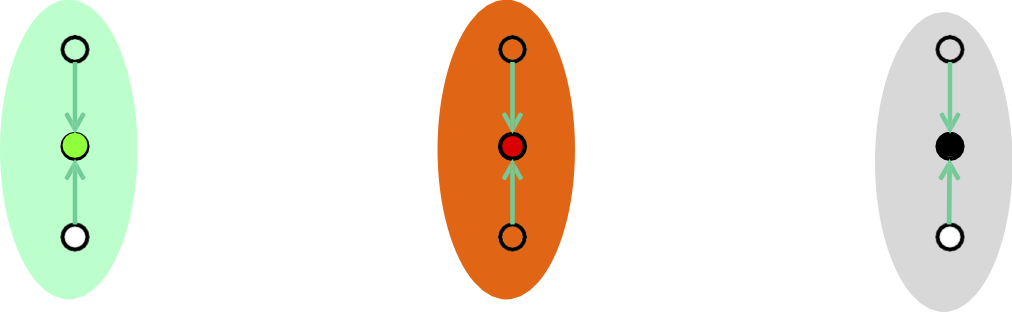
Phương pháp của Lloyd: Hiệu suất

Hiệu suất kém này có thể xảy ra ngay cả với các cụm Gaussian được phân tách rõ ràng.
Phương pháp của Lloyd: Hiệu suất
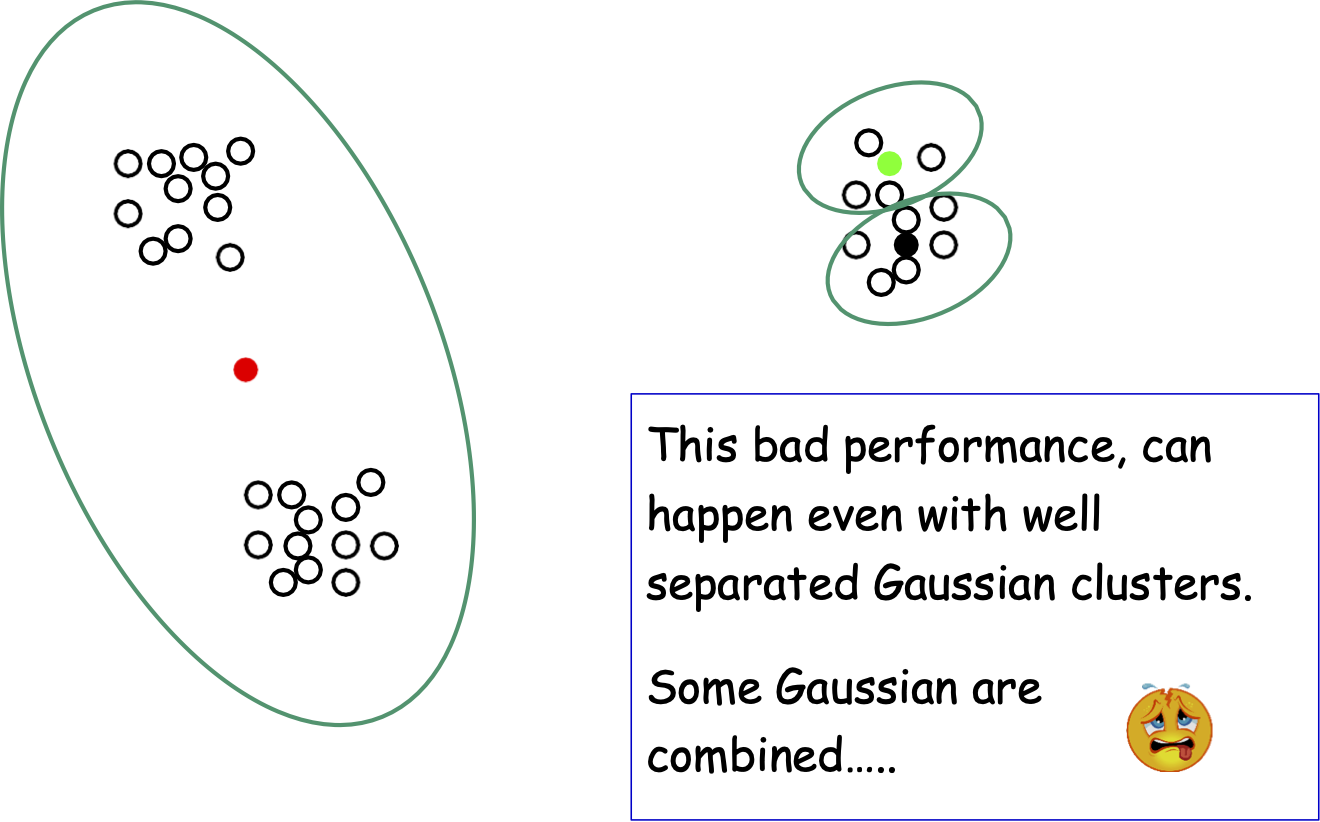
Hiệu suất kém này có thể xảy ra ngay cả với các cụm Gaussian được phân tách rõ ràng.
Một số Gaussian được kết hợp…..
Phương pháp của Lloyd: Hiệu suất
- Nếu chúng ta thực hiện khởi tạo ngẫu nhiên, khi k tăng lên, có nhiều khả năng chúng ta sẽ không chọn được một tâm hoàn hảo cho mỗi Gaussian trong quá trình khởi tạo của mình (vì vậy phương thức của Lloyd sẽ xuất ra một giải pháp tồi).
- Với k Gaussian có kích thước bằng nhau, Pr[mỗi tâm ban đầu nằm trong một Gaussian khác nhau] ≈ 𝑘!⁄𝑘𝑘 ≈ 1⁄𝑒𝑘
- Khó xảy ra khi k lớn.
Một ý tưởng khởi tạo khác: Heuristic điểm xa nhất
Chọn 𝐜𝟏 tùy ý (hoặc ngẫu nhiên).
- Với j = 2, … , k
- Chọn 𝐜𝐣 trong số các điểm dữ liệu 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐝 xa nhất so với các điểm đã chọn trước đó 𝐜𝟏, 𝐜𝟐, … , 𝐜𝒋−𝟏
Khắc phục sự cố Gaussian. Nhưng nó có thể bị loại bỏ bởi các ngoại lệ….
Heuristic điểm xa nhất hoạt động tốt trong ví dụ trước
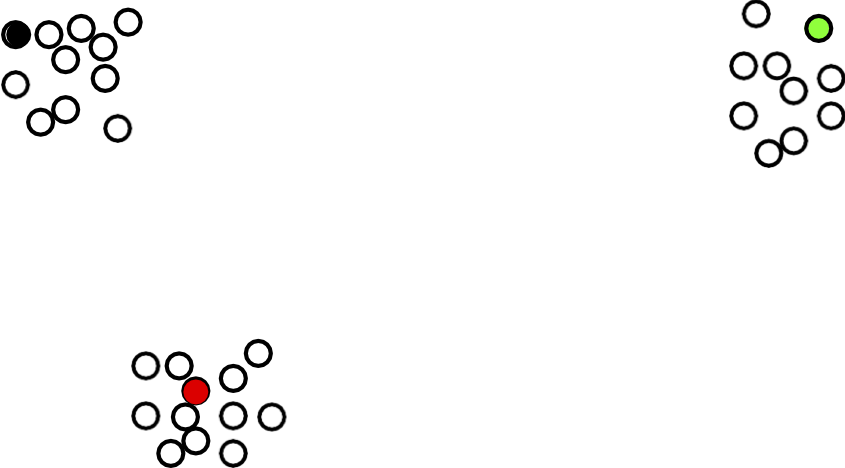
Heuristic khởi tạo điểm xa nhất nhạy cảm với các ngoại lệ
Giả sử k=3
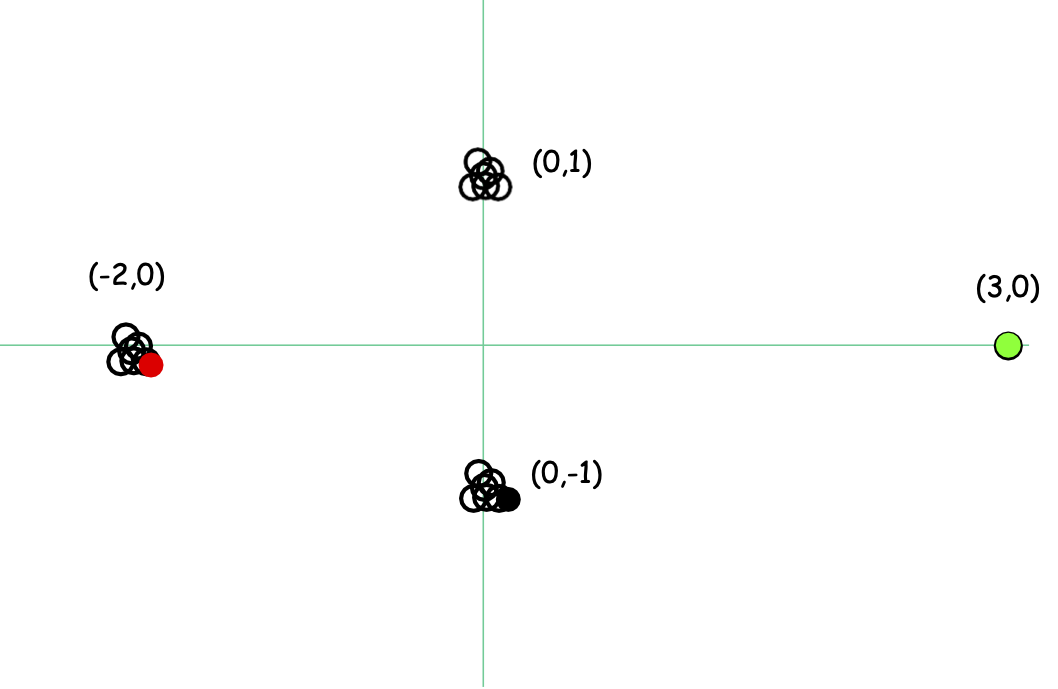
Heuristic khởi tạo điểm xa nhất nhạy cảm với các ngoại lệ
Giả sử k=3
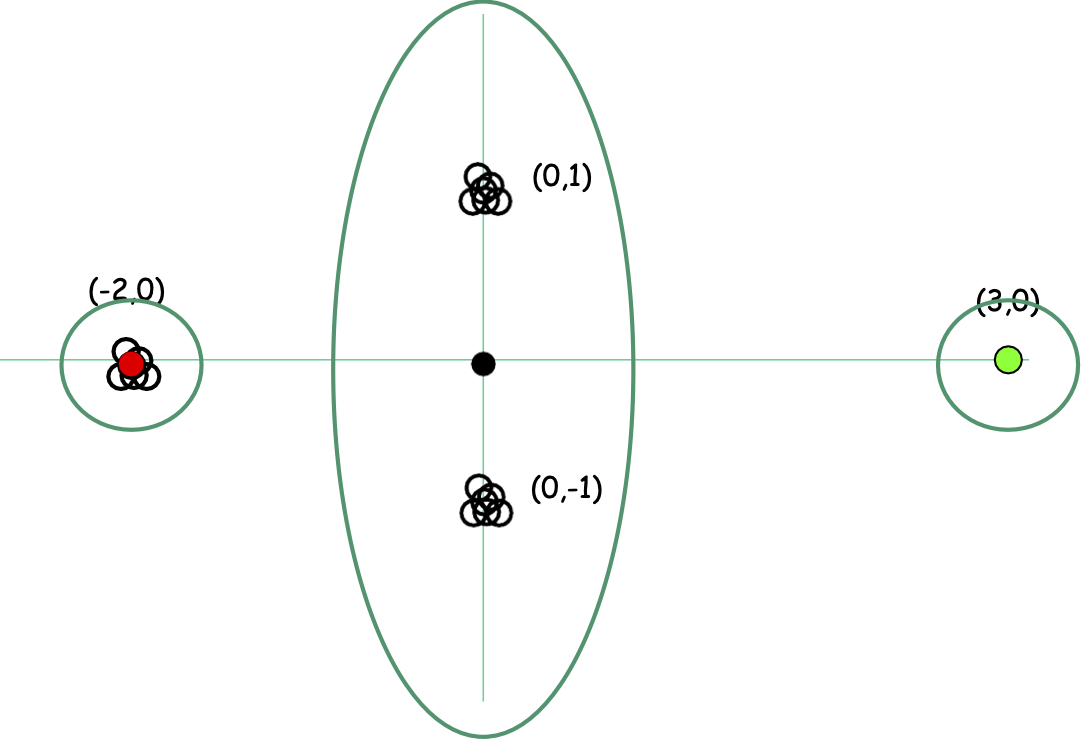
Khởi tạo K-means++: lấy mẫu D2 [AV07]
- Nội suy giữa khởi tạo điểm ngẫu nhiên và xa nhất
- Gọi D(x) là khoảng cách giữa một điểm 𝑥 và tâm gần nhất của nó. Chọn tâm tiếp theo tỷ lệ với D2(𝐱).
- Chọn ngẫu nhiên 𝐜𝟏.
- với j = 2, … , k
- Chọn 𝐜𝐣 trong số 𝐱𝟏, 𝐱𝟐, … , 𝐱𝐝 theo phân phối
𝐏𝐫(𝐜𝐣 = 𝐱𝐢) ∝ 𝐦𝐢𝐧𝐣′<𝐣 ||𝐱𝐢 − 𝐜𝐣′|| 𝟐 D2(𝐱𝐢)
![HÌNH 21.24. Khởi tạo K-means++: lấy mẫu D2 [AV07].](https://cdn.jsdelivr.net/gh/vtgcdn/iml21.viettechgroup.com@latest/21_clusteringfig24.png)
Định lý: K-means++ luôn đạt xấp xỉ O(log k) với nghiệm k-means tối ưu trong kỳ vọng.
Điều hành Lloyd’s chỉ có thể cải thiện hơn nữa chi phí.
K-means++ Ý tưởng: Lấy mẫu D2
- Nội suy giữa khởi tạo điểm ngẫu nhiên và điểm xa nhất
- Gọi D(x) là khoảng cách giữa một điểm 𝑥 và tâm gần nhất của nó. Chọn tâm tiếp theo tỷ lệ với D𝛼(𝐱).
- 𝛼 = 0, lấy mẫu ngẫu nhiên
- 𝛼 = ∞, điểm xa nhất (Lưu ý bên lề: nó thực sự hoạt động tốt cho k-trung tâm)
- 𝛼 = 2, k-means++
Lưu ý bên lề: 𝛼 = 1, hoạt động tốt cho k-trung vị
K-means ++ Fix
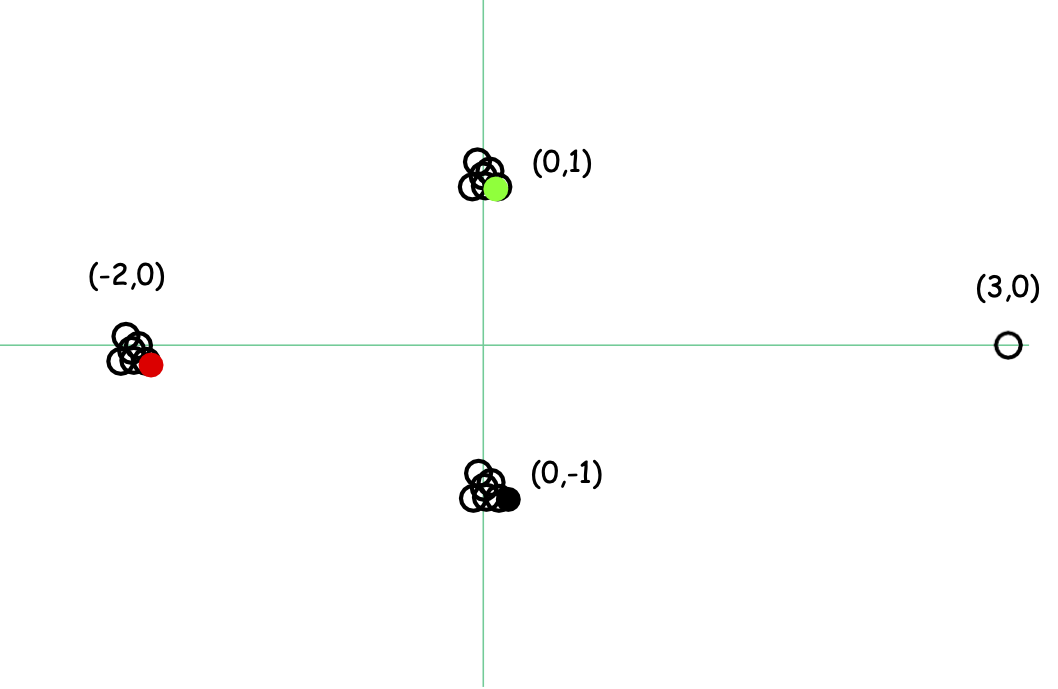
K-means++/ Lloyd’s Running Time
- Khởi tạo K-means ++: O(nd) và một lần truyền dữ liệu để chọn trung tâm tiếp theo. Vì vậy, tổng thời gian là O(nkd).
- Phương pháp của Lloyd
Lặp lại cho đến khi không có thay đổi về chi phí.
- Với mỗi j: Cj ←{𝑥 ∈ 𝑆 có tâm gần nhất là 𝐜𝐣}
- Với mỗi j: 𝐜𝐣 ←trung bình của Cj
Mỗi vòng mất thời gian O(nkd).
- Số mũ của vòng trong trường hợp xấu nhất [AV07].
- Dự kiến thời gian đa thức trong mô hình phân tích trơn!
K-means++/ Tóm tắt của Lloyd
- K-mean++ luôn đạt xấp xỉ O(log k) đối với giải pháp k-means tối ưu trong kỳ vọng.
- Hoạt động của Lloyd’s chỉ có thể cải thiện hơn nữa chi phí.
- Số mũ của vòng trong trường hợp xấu nhất [AV07].
- Dự kiến thời gian đa thức trong mô hình phân tích trơn!
- Hoạt động tốt trong thực tế.
Giá trị nào của k???
- Heuristic: Tìm khoảng cách lớn giữa k -1-means cost và k-means cost.
- Xác thực tạm dừng/xác thực chéo đối với nhiệm vụ phụ trợ (ví dụ: nhiệm vụ học tập có giám sát).
- Thử phân cụm theo thứ bậc.
Phân cụm theo cấp bậc
- Một hệ thống phân cấp có thể tự nhiên hơn.
- Những người dùng khác nhau có thể quan tâm đến các mức độ chi tiết hoặc thậm chí là cắt tỉa khác nhau.
Phân cụm theo cấp bậc
Từ trên xuống (phân chia)
- Phân vùng dữ liệu thành 2 nhóm (ví dụ: 2 phương tiện)
- Phân cụm đệ quy từng nhóm.
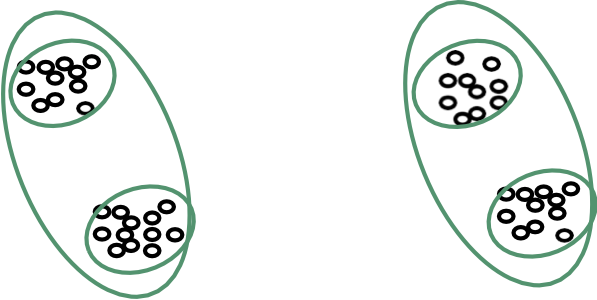
Từ dưới lên (kết tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
- Các def khác nhau của “gần nhất” đưa ra các thuật toán khác nhau.
Từ dưới lên (kết tụ)
Có thước đo khoảng cách trên các cặp đối tượng.
d(x,y) – khoảng cách giữa x và y
Ví dụ: # từ khóa chung, chỉnh sửa khoảng cách, v.v.
- Liên kết đơn: dist (A, 𝐵) = minx∈A,x′∈B′ dist(x, x′)
- Liên kết hoàn chỉnh: dist (A, B) = maxx∈A,x′∈B′ dist(x, x′)
- Liên kết trung bình: dist (A, B) = avgx∈A,x′∈B′ dist(x, x′)
- Phương pháp của Wards
Liên kết đơn
Từ dưới lên (kết tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
Liên kết đơn: dist (A, 𝐵) = minx∈A,x′∈𝐵 dist(x, x′)
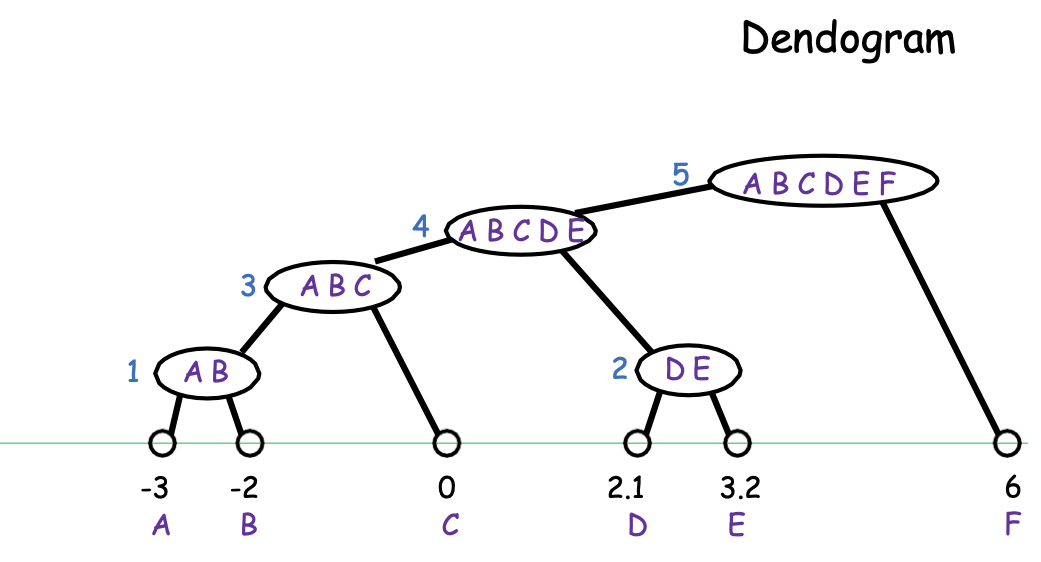
Biểu đồ hình cây
Liên kết đơn
Từ dưới lên (kết tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
Liên kết đơn: dist (A, 𝐵) = minx∈A,x′∈𝐵 dist(x, x′)
Một cách để nghĩ về nó: tại bất kỳ thời điểm nào, chúng ta thấy các thành phần được kết nối của biểu đồ nơi kết nối hai điểm bất kỳ của khoảng cách < r.
Theo dõi khi r tăng lên (chỉ n-1 giá trị liên quan vì chỉ có chúng ta hợp nhất tại giá trị của r tương ứng với giá trị của r trong các cụm khác nhau).
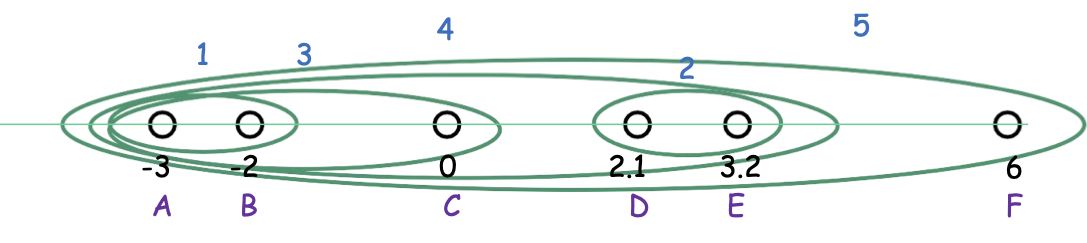
Liên kết hoàn chỉnh
Từ dưới lên (kết tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
Liên kết hoàn chỉnh: dist (A, B) = maxx∈A,x′∈B dist(x, x′)
Một cách để nghĩ về nó: giữ cho đường kính tối đa càng nhỏ càng tốt ở mọi cấp độ.
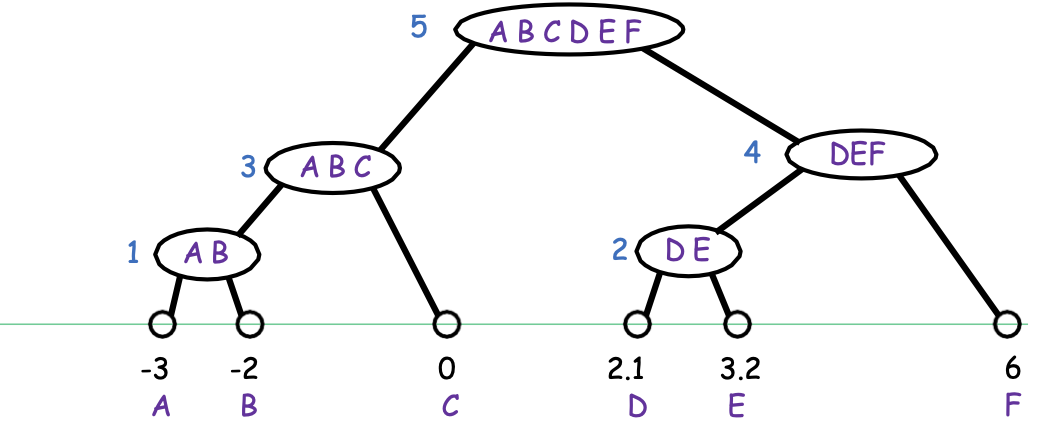
Liên kết hoàn chỉnh
Từ dưới lên (kết tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
Liên kết hoàn chỉnh: dist (A, B) = maxx∈A,x′∈B dist(x, x′)
Một cách để nghĩ về nó: giữ đường kính tối đa càng nhỏ càng tốt.
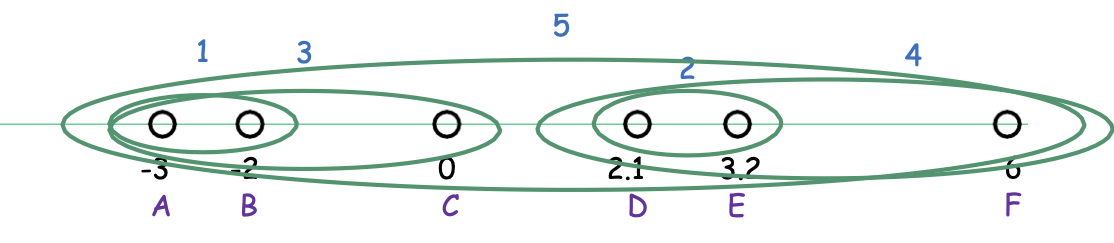
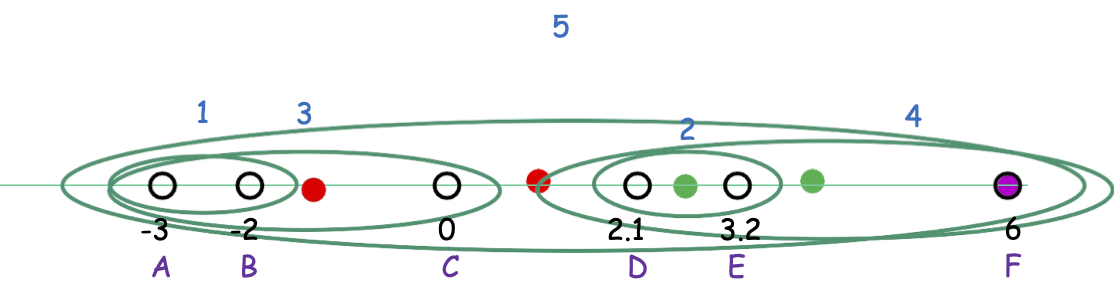
Phương pháp Ward
Từ dưới lên (tích tụ)
- Bắt đầu với mọi điểm trong cụm riêng của nó.
- Liên tục hợp nhất hai cụm “gần nhất”.
Phương pháp của Ward: dist (C, C′) = |C| ⋅ |C′|⁄ |C| + |C′| ||mean(C) − mean(C′)|| 2
Hợp nhất hai cụm sao cho mức tăng chi phí k-means càng nhỏ càng tốt.
Hoạt động tốt trong thực tế.
Thời gian chạy
- Mỗi thuật toán bắt đầu với N cụm và thực hiện hợp nhất N-1.
- Đối với mỗi thuật toán, việc tính toán 𝑑𝑖𝑠𝑡(𝐶, 𝐶′) có thể được thực hiện trong thời gian 𝑂( |𝐶| ⋅ |𝐶′| ). (ví dụ: kiểm tra 𝑑𝑖𝑠𝑡(𝑥, 𝑥′) với mọi 𝑥 ∈ 𝐶, 𝑥′ ∈ 𝐶′)
- Thời gian để tính tất cả các khoảng cách theo cặp và lấy nhỏ nhất là 𝑂(𝑁2).
- Tổng thời gian là 𝑂(𝑁3).
Trên thực tế, có thể chạy tất cả các thuật toán này trong thời gian 𝑂(𝑁2 log 𝑁).
Xem: Christopher D. Manning, Prabhakar Raghavan và Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008. http://www-nlp.stanford.edu/IR-book/
Thí nghiệm phân cụm theo thứ bậc
[BLG, JMLR’15]
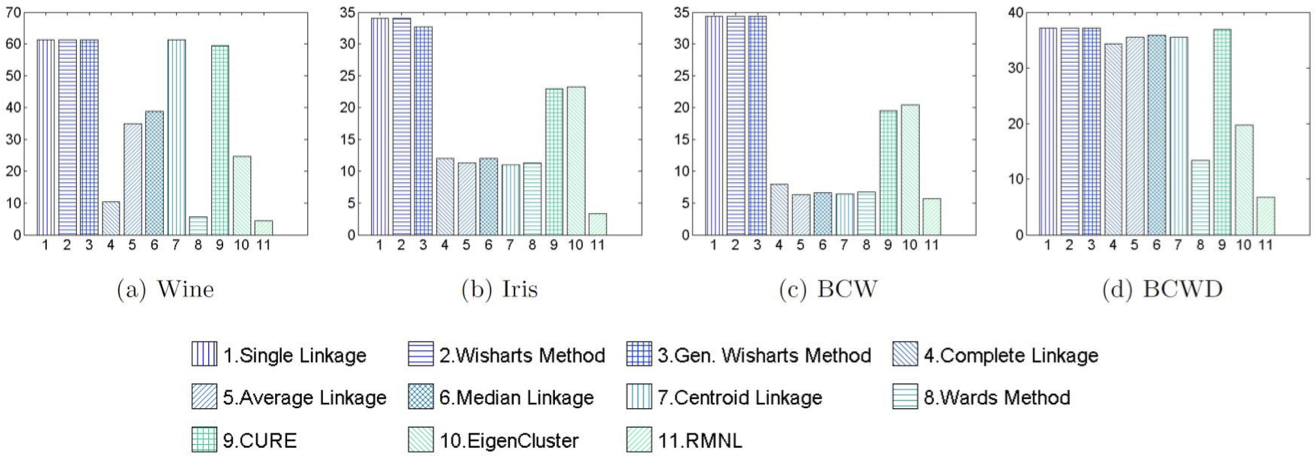
Phương pháp của Ward thực hiện tốt nhất trong số các kỹ thuật cổ điển.
Thí nghiệm phân cụm theo thứ bậc
[BLG, JMLR’15]
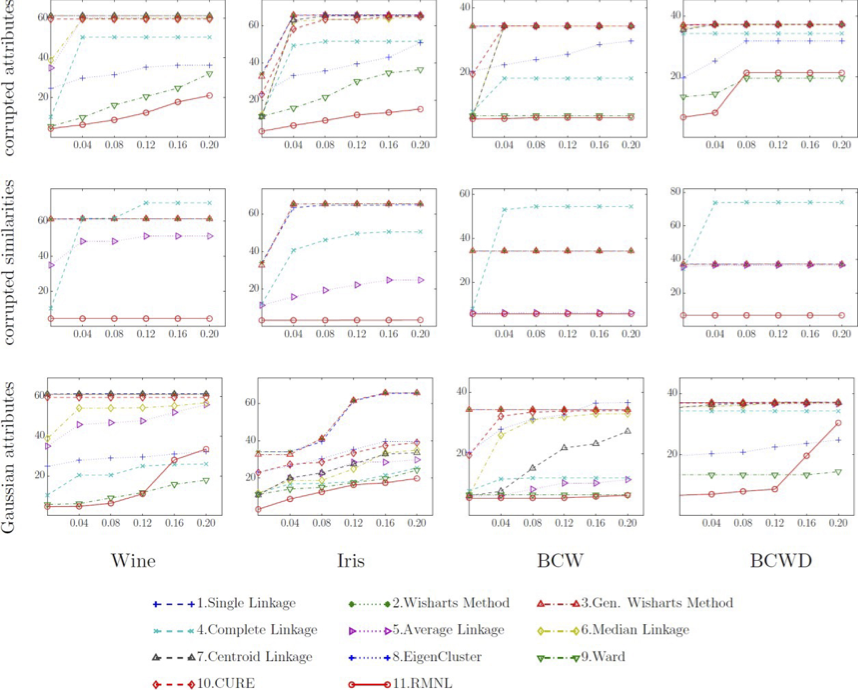
Phương pháp của Ward thực hiện tốt nhất trong số các kỹ thuật cổ điển.
Những điều bạn nên biết
- Partitional Clustering. k-mean và k-mean ++
- Phương pháp của Lloyd
- Các kỹ thuật khởi tạo (ngẫu nhiên, truyền tải xa nhất, k-means++)
- Phân cụm theo cấp bậc.
- Liên kết đơn, Liên kết hoàn chỉnh, Phương pháp của Ward
Các trang trình bày bổ sung
Mô hình phân tích được làm mịn
- Tưởng tượng đầu vào trong trường hợp xấu nhất.
- Nhưng sau đó thêm nhiễu Gaussian nhỏ vào từng điểm dữ liệu.
Mô hình phân tích trơn tru
- Hãy tưởng tượng một đầu vào trong trường hợp xấu nhất.
- Nhưng sau đó thêm nhiễu Gaussian nhỏ vào từng điểm dữ liệu.
- Định lý [Arthur-Manthey-Roglin 2009]:
- E[số vòng cho đến khi Lloyd’s hội tụ] nếu thêm nhiễu Gauss với phương sai 𝜎2 là đa thức trong 𝑛, 1/𝜎.
- Giới hạn thực tế là: 𝑂 (𝑛34𝑘34𝑑8⁄ 𝜎6)
- Vẫn có thể tìm thấy tối ưu cục bộ khác xa với tối ưu toàn cục.
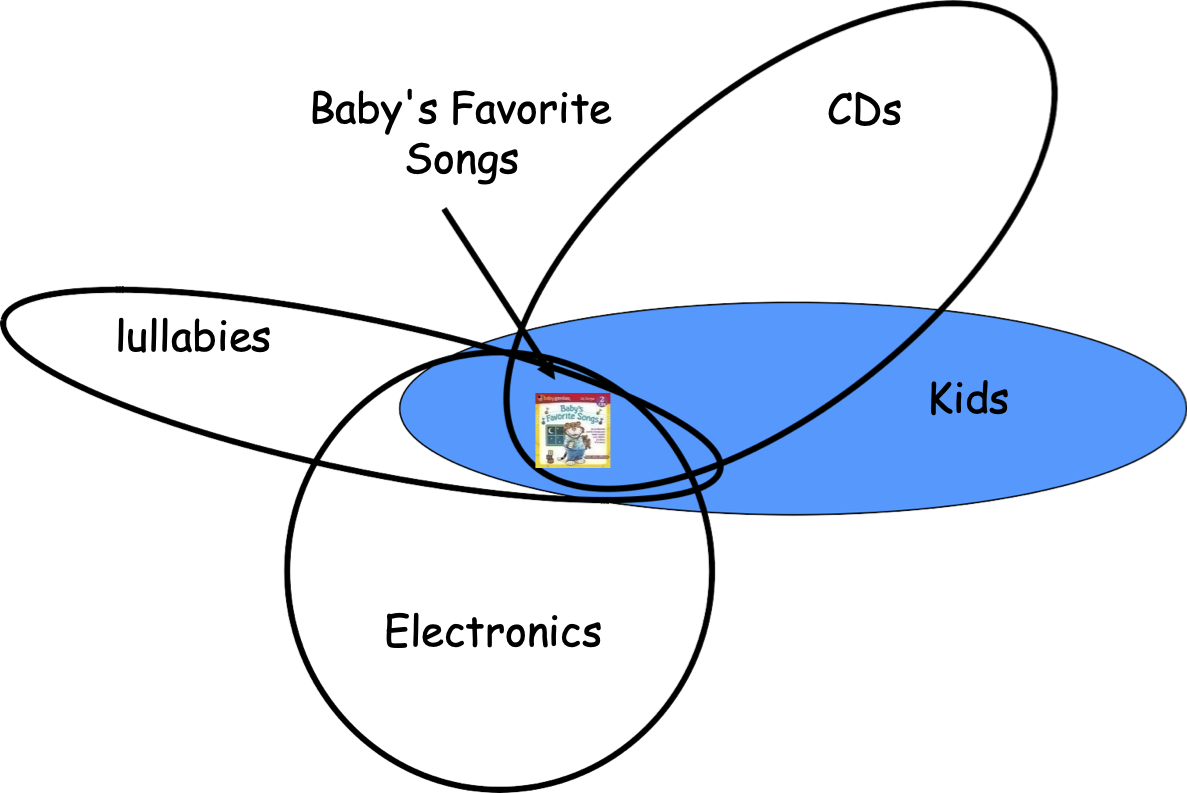
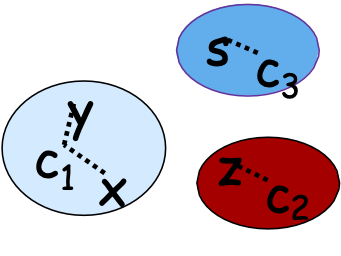
Các cụm chồng chéo: Cộng đồng
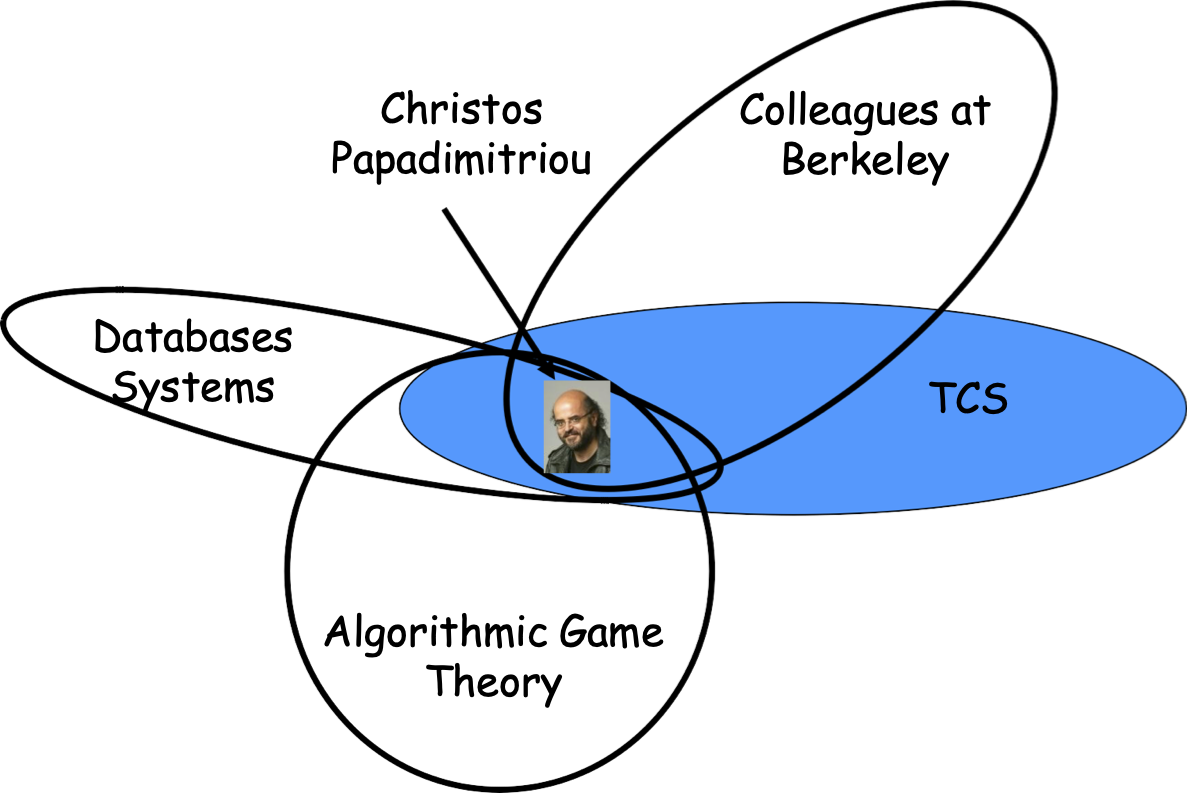
Các cụm chồng chéo: Cộng đồng


- Product Purchasing Networks, Citation Networks, Biological Networks, etc
Mạng xã hội
Mạng chuyên nghiệp
Mạng mua sản phẩm, Mạng trích dẫn, Mạng sinh học, v.v.