
Bài đọc tham khảo
Active Learning from Theory to Practice (Steve Hanneke-Robert Nowak)
Hậu cần
- HWK #6 sẽ đến hạn vào Thứ Sáu.
- Đánh giá Dự án Midway vào thứ Hai.
Hãy chắc chắn nói chuyện với người cố vấn TA của bạn!
Mô hình học tập được giám sát hoàn toàn cổ điển Không đủ Ngày nay
Các ứng dụng hiện đại: lượng dữ liệu thô khổng lồ.
Chỉ một phần rất nhỏ có thể được chú thích bởi các chuyên gia con người.
Trình tự protein

Hàng tỷ trang web

Hình ảnh
ML hiện đại: Tiếp cận học tập mới
Ứng dụng hiện đại: lượng lớn dữ liệu thô.
Các kỹ thuật sử dụng dữ liệu tốt nhất, giảm thiểu nhu cầu can thiệp của chuyên gia/con người.
Các mô hình nơi đã có sự tiến bộ lớn.
- Học bán giám sát, Học tập tích cực (tương tác).

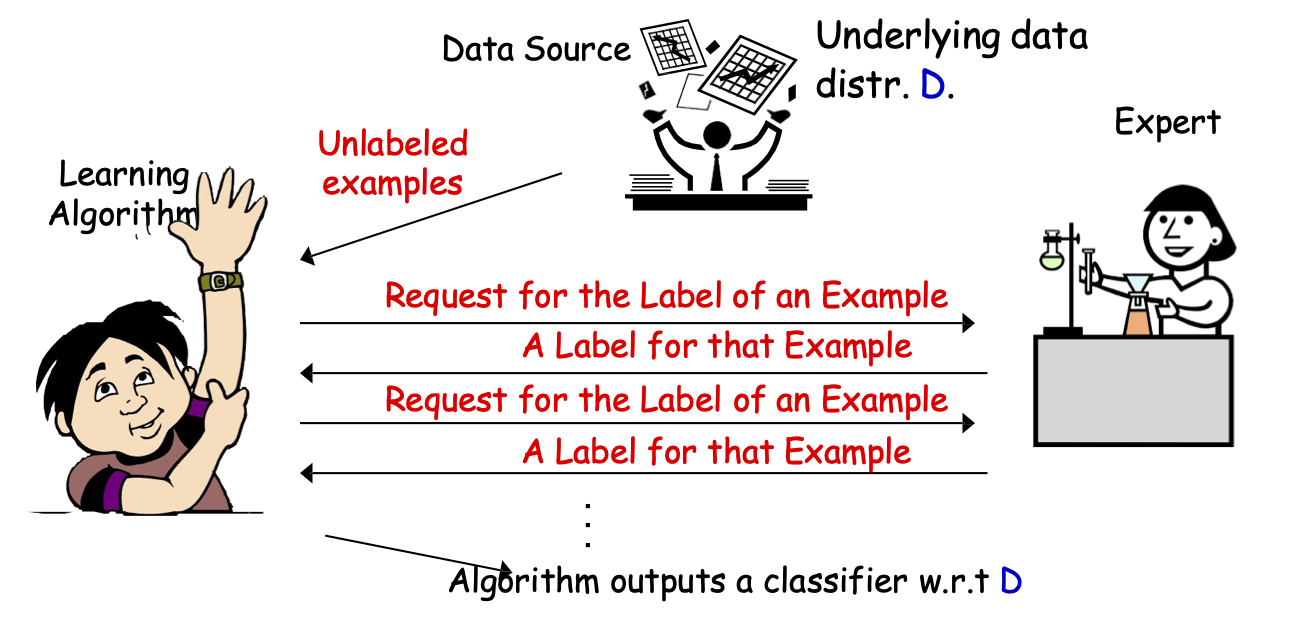
Học bán giám sát

Thuật toán học tập
Chuyên gia / Oracle
Nguồn dữ liệu
Các mẫu không được gắn nhãn
Thuật toán đưa ra một bộ phân loại
Các mẫu không được gắn nhãn
Các mẫu được gắn nhãn
Sl={(x1, y1), …,(xml , yml)}
xi rút ra i.i.d từ D, yi = c∗(xi)
Su={x1, …,xmu} i.i.d được rút ra từ D
Mục tiêu: h có lỗi nhỏ trên D.
errD (h) = Prx~ D (h(x) ≠ c∗(x))
Học bán giám sát
Thông tin chi tiết chính/Nguyên tắc cơ bản ở dưới
Dữ liệu chưa được gắn nhãn sẽ hữu ích nếu chúng ta có thiên vị/niềm tin không chỉ về hình thức của mục tiêu, mà còn về mối quan hệ của nó với phân phối dữ liệu cơ bản.

Ví dụ: “dấu tách lề lớn” [Joachims ’99]
Dựa trên sự tương đồng (“cắt nhỏ”) [B&C01], [ZGL03]
“các quy tắc tự nhất quán” [Blum & Mitchell ’98]
x = ⟨ x1, x2 ⟩ h1(x1)=h2(x2)
x1- Thông tin văn bản x2- Thông tin liên kết
- Dữ liệu chưa được gắn nhãn có thể giúp giảm không gian tìm kiếm hoặc sắp xếp lại thứ tự các fns trong không gian tìm kiếm theo niềm tin của chúng ta, hướng việc tìm kiếm về các fns thỏa mãn niềm tin (điều này trở nên cụ thể khi chúng ta thấy dữ liệu chưa được gắn nhãn).
Một mô hình phân biệt đối xử chung cho SSL
[BalcanBlum, COLT 2005; JACM 2010]
Như trong PAC/SLT, hãy thảo luận các vấn đề phức tạp về thuật toán và mẫu.
Phân tích các khía cạnh phức tạp của mẫu cơ bản:
- Cần bao nhiêu dữ liệu chưa được gắn nhãn.
- phụ thuộc cả vào độ phức tạp của H và khái niệm tương thích.
- Khả năng của dữ liệu chưa được gắn nhãn để giảm #of các mẫu được gắn nhãn.
- tính tương thích của mục tiêu, tính hữu ích của phân phối.
- Khảo sát về “Học bán giám sát” (Jerry Zhu, 2010) giải thích các kỹ thuật SSL từ quan điểm này.
- Lưu ý: phương pháp hỗn hợp mà Tom đã nói vào ngày 25 tháng 2 cũng có thể được giải thích từ quan điểm này. Xem khảo sát của Zhu.
Học chủ động
Tài nguyên bổ sung:
- Hai mặt của học tập tích cực. Sanjoy Dasgupta. 2011.
- Học Tích cực. Bur Settles. 2012.
- Học Tích cực. Balcan-Urner. Bách khoa toàn thư về thuật toán. 2015
Học tích cực theo lô
Thuật toán Học tập
Chuyên gia
Nguồn dữ liệu
mẫu chưa gắn nhãn
Thuật toán đưa ra một bộ phân loại w.r.t D
Phân phối dữ liệu cơ bản D.
Yêu cầu nhãn của một mẫu
Nhãn cho mẫu đó
Yêu cầu nhãn của một mẫu
Nhãn cho mẫu đó
- Thuật toán học có thể chọn các mẫu cụ thể để dán nhãn.
- Mục tiêu: sử dụng ít mẫu được dán nhãn hơn [chọn các mẫu có nhiều thông tin để được dán nhãn].
Lấy mẫu chọn lọc Active Learning
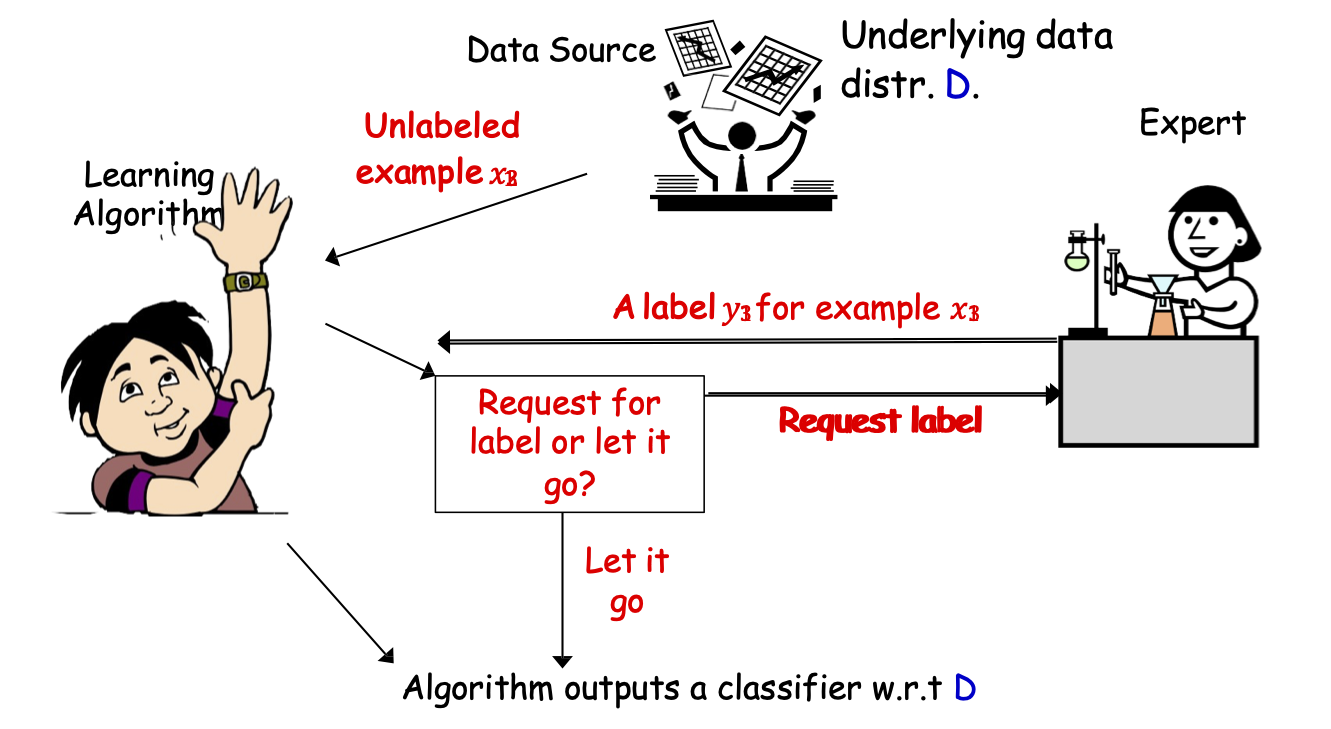
Thuật toán Học tập
Chuyên gia
Nguồn dữ liệu
Thuật toán xuất ra một bộ phân loại w.r.t D
Phân phối dữ liệu cơ bản D.
Mẫu chưa gán nhãn 𝑥3 12
Yêu cầu gán nhãn hay bỏ qua?
Yêu cầu nhãn
Một nhãn 𝑦1 cho mẫu 𝑥1
Bỏ qua
- Lấy mẫu chọn lọc AL (AL trực tuyến): luồng các mẫu chưa được gắn nhãn, khi mỗi mẫu đến sẽ đưa ra quyết định có yêu cầu nhãn hay không.
- Mục tiêu: sử dụng ít mẫu được dán nhãn hơn [chọn các mẫu có nhiều thông tin để được dán nhãn].
Điều gì tạo nên một thuật toán học tích cực tốt?
- Đảm bảo cho ra bộ phân loại tương đối tốt cho hầu hết các bài toán học.
- Không yêu cầu quá nhiều nhãn.
- Hy vọng là ít hơn nhiều so với học thụ động và SSL.
- Cần lựa chọn cẩn thận các nhãn yêu cầu, để có được các nhãn có nhiều thông tin.
Truy vấn thích ứng có thực sự làm tốt hơn lấy mẫu thụ động/ngẫu nhiên không?
- VÂNG! (thỉnh thoảng)
- Chúng ta thường cần ít nhãn hiệu hơn cho việc học chủ động hơn là học thụ động.
- Điều này đã được dự đoán bởi lý thuyết và đã được quan sát thấy trong thực tế.
Truy vấn thích ứng có thể trợ giúp không? [CAL92, Dasgupta04]
- Các hàm ngưỡng trên đường thực: hw(x) = 1(x ≥ w), C = {hw: w ∈ R}
![HÌNH 20.7. Truy vấn thích ứng có thể trợ giúp không? [CAL92, Dasgupta04].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig07a.png)
Thuật toán tích cực
![HÌNH 20.7. Truy vấn thích ứng có thể trợ giúp không? [CAL92, Dasgupta04].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig07b.png)
- N = O(1/ϵ) chúng ta được đảm bảo nhận được phân loại lỗi ≤ ϵ.
Được giám sát thụ động: dán Ω(1/ϵ) nhãn để tìm ngưỡng ε chính xác.
Tích cực: chỉ O(log 1/ϵ) nhãn. – Cải thiện theo cấp số nhân.![HÌNH 20.7. Truy vấn thích ứng có thể trợ giúp không? [CAL92, Dasgupta04].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig07c.png)
Kỹ thuật phổ biến trong thực tế
Lấy mẫu độ không đảm bảo trong SVM phổ biến và khá hữu ích trong thực tế.
Ví dụ, [Tong & Koller, ICML 2000; Jain, Vijayanarasimhan & Grauman, NIPS 2010; Schohon Cohn, ICML 2000]
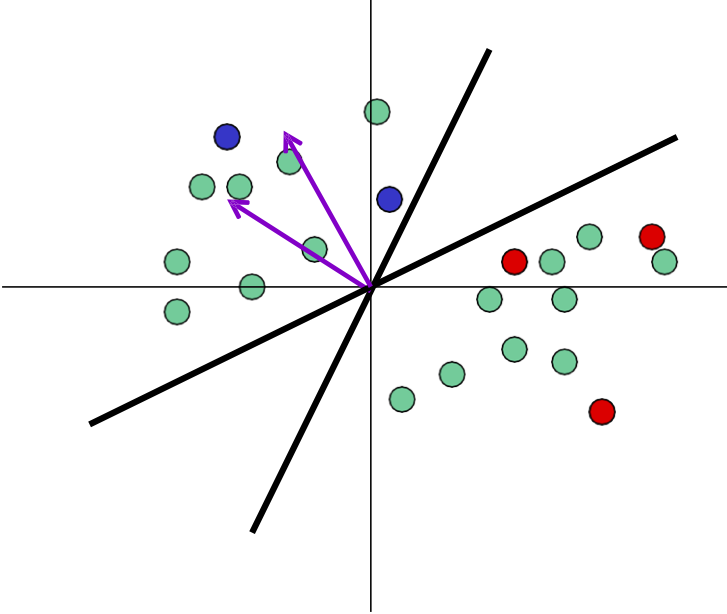
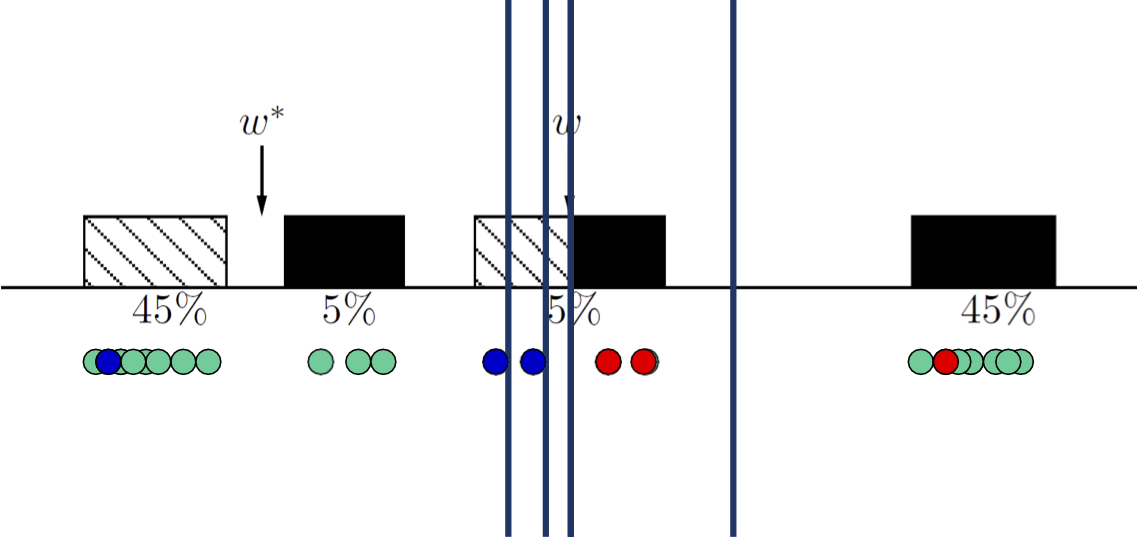
Active SVM Algorithm
- Tại bất kỳ thời điểm nào trong thuật toán, chúng ta có một “dự đoán hiện tại” wt của dấu tách: dấu tách có lề tối đa của tất cả các điểm được dán nhãn cho đến nay.
- Yêu cầu nhãn của mẫu gần nhất với dấu phân cách hiện tại.
Kỹ thuật phổ biến trong thực tế
Active SVM dường như khá hữu ích trong thực tế.
[Tong & Koller, ICML 2000; Jain, Vijayanarasimhan & Grauman, NIPS 2010]
Thuật toán (phiên bản theo lô)
Đầu vào Su={x1, …,xmu} i.i.d được rút ra từ nguồn cơ bản D
Bắt đầu: truy vấn nhãn của một vài 𝑥𝑖 ngẫu nhiên.
Đối với 𝒕 = 𝟏, ….,
- Tìm 𝑤𝑡 dấu phân cách có lề tối đa của tất cả các điểm được gắn nhãn cho đến nay.
- Yêu cầu nhãn của mẫu gần nhất với dấu phân cách hiện tại: giảm thiểu |𝑥𝑖 ⋅ 𝑤𝑡|. (độ không chắc chắn cao nhất)
Kỹ thuật phổ biến trong thực tế
Active SVM dường như khá hữu ích trong thực tế.
Ví dụ: Jain, Vijayanarasimhan & Grauman, NIPS 2010
Newsgroups dataset (20.000 tài liệu từ 20 danh mục)
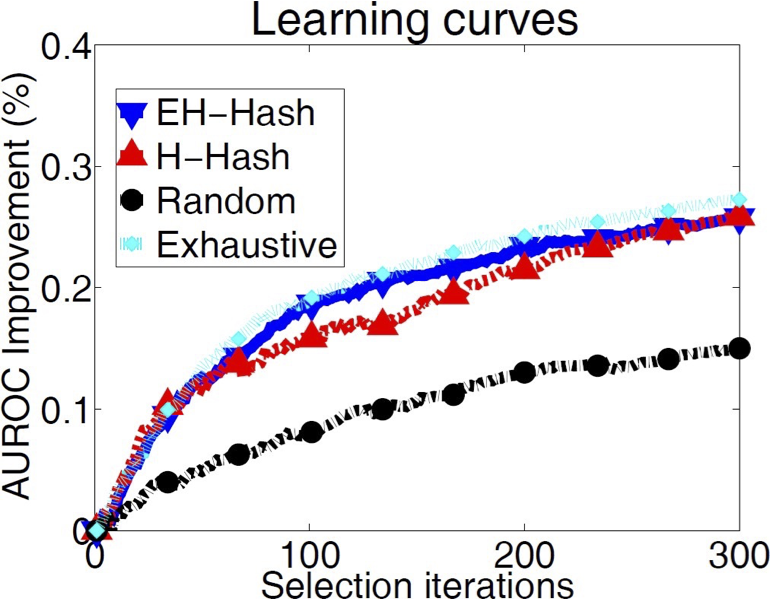
Kỹ thuật phổ biến trong thực tế
Active SVM dường như khá hữu ích trong thực tế.
Ví dụ: Jain, Vijayanarasimhan & Grauman, NIPS 2010
Bộ dữ liệu hình ảnh CIFAR-10 (60.000 hình ảnh từ 10 danh mục)
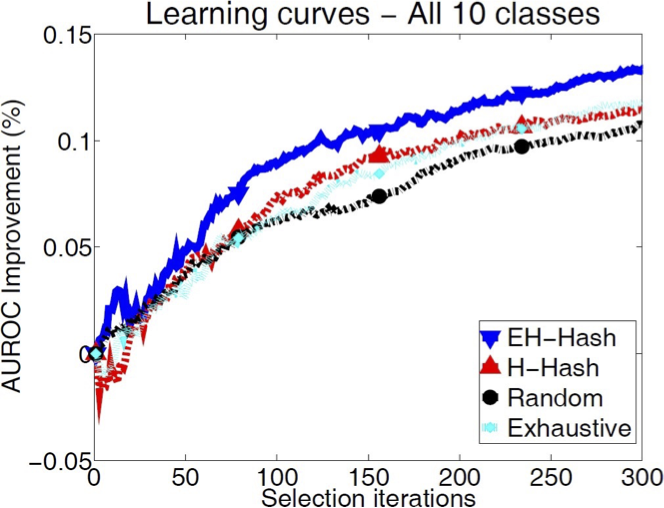
SVM Tích cực/Lấy mẫu Độ không đảm bảo
- Đôi khi hoạt động….
- Tuy nhiên, chúng ta cần phải rất rất rất cẩn thận!!!
- Kỹ thuật thiển cận, tham lam có thể bị sai lệch lấy mẫu.
- Sự thiên vị được tạo ra do chiến lược truy vấn; theo thời gian, mẫu ngày càng ít đại diện hơn cho nguồn dữ liệu thực.
[Dasgupta10]

SVM tích cực/Lấy mẫu độ không chắc chắn
- Đôi khi hoạt động….
- Tuy nhiên, chúng ta cần hết sức cẩn thận!!!
SVM tích cực/Lấy mẫu độ không đảm bảo
- Đôi khi hoạt động….
- Tuy nhiên, chúng ta cần hết sức cẩn thận!!!
- Căng thẳng chính: muốn chọn các điểm cung cấp thông tin, nhưng cũng muốn đảm bảo rằng trình phân loại mà chúng ta xuất ra hoạt động tốt trên các mẫu ngẫu nhiên thực sự từ phân phối cơ bản.


Kế hoạch học tập chủ động an toàn
Tìm kiếm không gian giả thuyết học tập chủ động dựa trên bất đồng
[CAL92] [BBL06]
[Hanneke’07, DHM’07, Wang’09 , Fridman’09, Kolt10, BHW’08, BHLZ’10, H’10, Ailon’12, …]
Không gian Phiên bản
- X – không gian đối tượng/thực thể; phân phối D trên X; 𝑐∗ hàm đích
- Cố định không gian giả thuyết H.
Định nghĩa (Mitchell’82) Giả sử trường hợp có thể thực hiện được: c∗ ∈ H.
Đưa ra một tập hợp các mẫu được gắn nhãn (x1, y1), …,(xml , yml), yi = c∗(xi)
Không gian phiên bản của H: một phần của H nhất quán với các nhãn cho đến nay.
Tức là, h ∈ VS(H) iff h(xi) = c∗(xi) ∀i ∈ {1, … ,ml}.
Không gian phiên bản
- X – không gian đối tượng/thực thể; phân phối D trên X; 𝑐∗ hàm đích
- Cố định không gian giả thuyết H.
Định nghĩa (Mitchell’82) Giả sử trường hợp khả thi: c∗ ∈ H.
Đưa ra một tập hợp các mẫu có nhãn (x1, y1), …,(xml , yml), yi = c∗(xi)
Không gian phiên bản của H: một phần của H nhất quán với các nhãn cho đến nay.
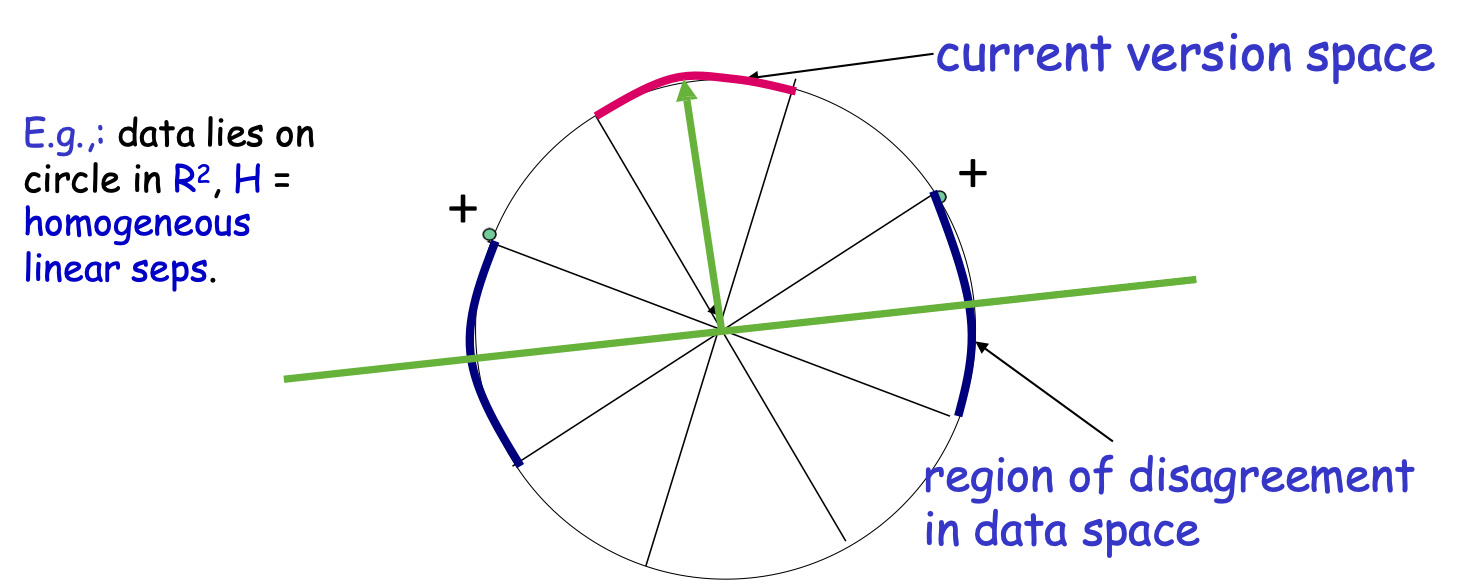
VD: dữ liệu nằm trên đường tròn trong R2, H = thuần nhất vách ngăn tuyến tính.
không gian phiên bản hiện tại
khu vực bất đồng trong không gian dữ liệu
Không gian phiên bản. Khu vực bất đồng
Định nghĩa (CAL’92)
Không gian phiên bản: một phần của H phù hợp với các nhãn cho đến nay.
Vùng bất đồng = một phần của không gian dữ liệu mà có vẫn còn một số điều không chắc chắn (tức là có sự bất đồng trong không gian phiên bản)
x ∈ X, x ∈ DIS(VS(H)) iff ∃h1, h2 ∈ VS(H), h1(x) ≠ h2(x)
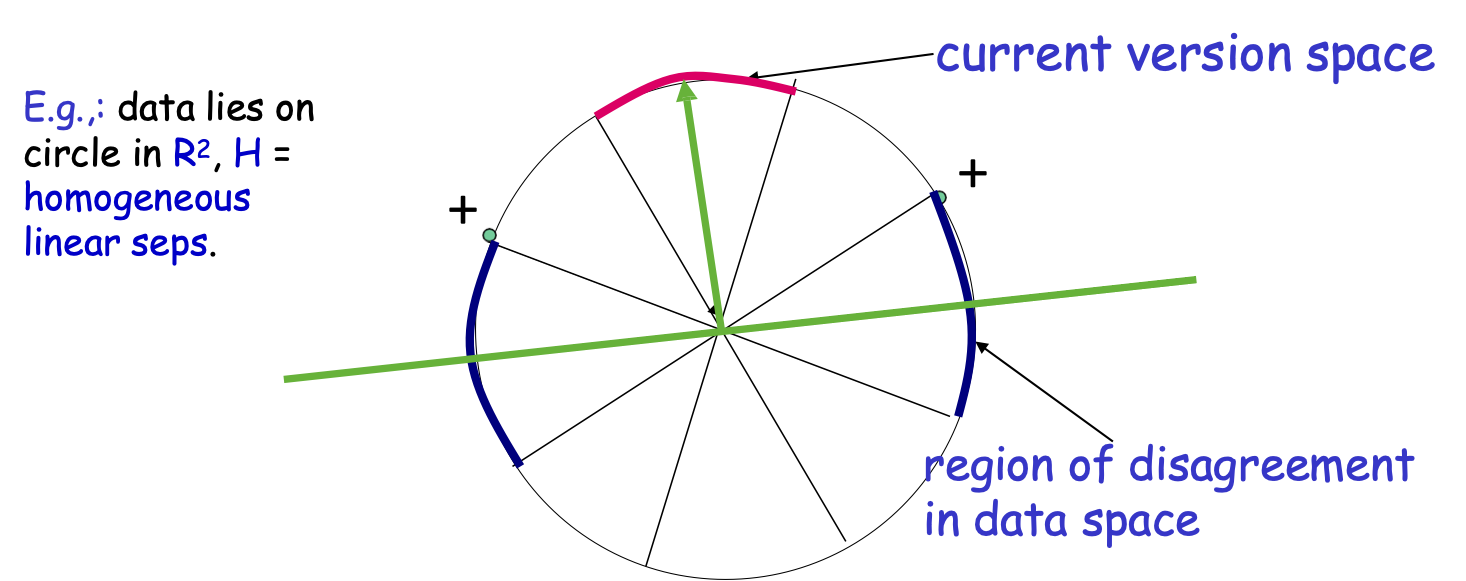
Ví dụ: dữ liệu nằm trên đường tròn trong R2, H = đồng nhất vách ngăn tuyến tính.
Không gian phiên bản hiện tại
khu vực bất đồng trong không gian dữ liệu
Học chủ động dựa trên sự bất đồng [CAL92]
![HÌNH 20.16. Học chủ động dựa trên sự bất đồng [CAL92].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig16.png)
không gian phiên bản hiện tại
khu vực của sự không chắc chắn
Thuật toán:
Chọn một vài điểm ngẫu nhiên từ vùng không chắc chắn hiện tại và truy vấn nhãn của chúng.
Dừng lại khi vùng không chắc chắn là nhỏ.
Lưu ý: nó đang hoạt động vì chúng ta không lãng phí nhãn bằng cách truy vấn trong các vùng không gian mà chúng ta chắc chắn về các nhãn.
Học chủ động dựa trên sự bất đồng [CAL92]
![HÌNH 20.17. Học chủ động dựa trên sự bất đồng [CAL92].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig17.png)
không gian phiên bản hiện tại
khu vực của sự không chắc chắn
Thuật toán:
Truy vấn nhãn của một vài 𝑥𝑖 ngẫu nhiên.
Đặt H1 là không gian phiên bản hiện tại.
Với 𝒕 = 𝟏, ….,
Chọn một vài điểm ngẫu nhiên từ khu vực hiện tại của bất đồng DIS(Ht) và truy vấn nhãn của chúng.
Gọi Ht+1 là không gian phiên bản mới.
Vùng không chắc chắn [CAL92]
- Không gian phiên bản hiện tại: một phần của C phù hợp với các nhãn cho đến nay.
- “Vùng không chắc chắn” = phần không gian dữ liệu mà vẫn còn một số điều không chắc chắn (tức là sự bất đồng trong không gian phiên bản)
![HÌNH 20.18. Vùng không chắc chắn [CAL92].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig18.png)
không gian phiên bản hiện tại
vùng không chắc chắn trong không gian dữ liệu
Vùng không chắc chắn [CAL92]
- Không gian phiên bản hiện tại: một phần của C phù hợp với các nhãn cho đến nay.
- “Vùng không chắc chắn” = phần không gian dữ liệu mà vẫn còn một số điều không chắc chắn (tức là sự bất đồng trong không gian phiên bản)
![HÌNH 20.19. Vùng không chắc chắn [CAL92].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig19.png)
không gian phiên bản mới
vùng mới của bất đồng trong không gian dữ liệu
 Làm thế nào về trường hợp bất khả tri nơi mục tiêu có thể không thuộc H?
Làm thế nào về trường hợp bất khả tri nơi mục tiêu có thể không thuộc H?
A2 Agnostic Active Learner [BBL’06]
![HÌNH 20.21. A2 Agnostic Active Learner [BBL’06].](https://cdn.jsdelivr.net/gh/vtgcdn/iml20.viettechgroup.com@latest/20_alfig21.png)
không gian phiên bản hiện tại
khu vực của bất đồng
Thuật toán:
Cho H1 = H.
Với 𝒕 = 𝟏, ….,
- Chọn ngẫu nhiên một vài điểm từ khu vực hiện tại bất đồng DIS(Ht) và truy vấn nhãn của chúng.
- Vứt bỏ giả thuyết nếu bạn thống kê tự tin rằng chúng không tối ưu.←
Sử dụng cẩn thận các giới hạn tổng quát hóa;
Tránh sai lệch lấy mẫu!!!!
Khi học tập tích cực giúp ích. trường hợp bất khả tri
A2 thuật toán đầu tiên chống nhiễu mạnh.
[Balcan, Beygelzimer, Langford, ICML’06] [Balcan, Beygelzimer, Langford, JCSS’08]
Phong cách “Khu vực bất đồng”: Chọn ngẫu nhiên một vài điểm từ khu vực bất đồng hiện tại, truy vấn nhãn của chúng, ném ra ngoài giả thuyết nếu bạn tự tin về mặt thống kê thì chúng không tối ưu.
Đảm bảo cho A2 [BBL’06,’08]:
- Nó an toàn (không bao giờ tệ hơn học thụ động) & cải thiện theo cấp số nhân.
- C – ngưỡng, nhiễu thấp, cải thiện theo cấp số nhân.
- C – dải phân cách tuyến tính đồng nhất trong Rd, D – đồng nhất, ít nhiễu, chỉ d2 log (1/ε) nhãn.
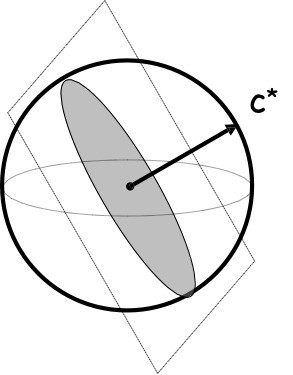
Rất nhiều công việc tiếp theo.
[Hanneke’07, DHM’07, Wang’09 , Fridman’09, Kolt10, BHW’08, BHLZ’10, H’10, Ailon’12, …]
Đảm bảo chung cho A2 Agnostic Active Learner
“Dựa trên sự bất đồng”: Chọn ngẫu nhiên một vài điểm từ khu vực hiện tại của sự không chắc chắn, truy vấn nhãn của chúng, ném ra giả thuyết nếu bạn thống kê tự tin rằng chúng không tối ưu. [BBL’06]
Đảm bảo cho A2 [Hanneke’07]:

Bao mau vùng bất đồng sụp đổ khi chúng ta ngày càng đến gần hơn phân loại tối ưu

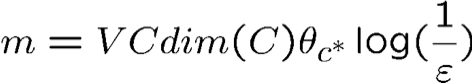
Máy phân tách tuyến tính, phân bố đều:
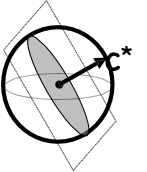
Học chủ động dựa trên bất đồng
Thuật toán “dựa trên sự bất đồng”: truy vấn các điểm từ khu vực bất đồng hiện tại, ném ra các giả thuyết khi tự tin về mặt thống kê rằng chúng không tối ưu.
- Chung (bất kỳ lớp nào), nhiễu nhãn đối nghịch.
- Hiệu quả về mặt tính toán đối với các lớp có kích thước VC nhỏ
Tuy nhiên, có thể là dưới mức tối ưu trong phức hợp nhãn & tính toán không hiệu quả nói chung.
Rất nhiều công việc tiếp theo đang cố gắng thực hiện hiệu quả hơn về mặt tính toán và hung hãn hơn nữa: [Hanneke07, DasguptaHsuMontleoni’07, Wang’09 , Fridman’09, Koltchinskii10, BHW’08, BeygelzimerHsuLangfordZhang’10, Hsu’10, Ailon’12, …]
Các kỹ thuật AL thú vị khác được sử dụng trong Thực hành
Câu hỏi mở thú vị để phân tích chúng thành công trong những điều kiện nào.
Lấy mẫu dựa trên mật độ
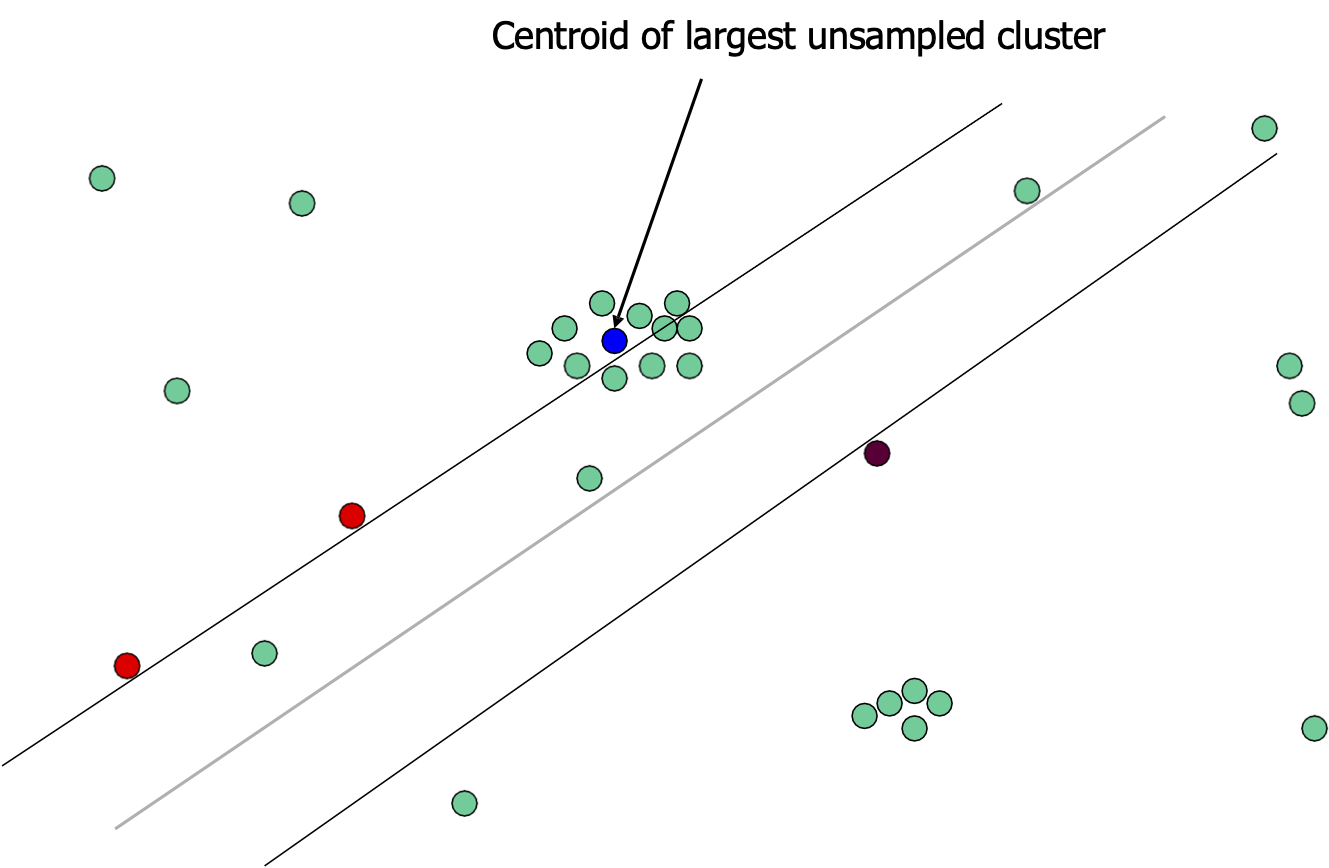
Trọng tâm của cụm chưa được lấy mẫu lớn nhất
[Jaime G. Carbonell]
Lấy mẫu về độ không chắc chắn
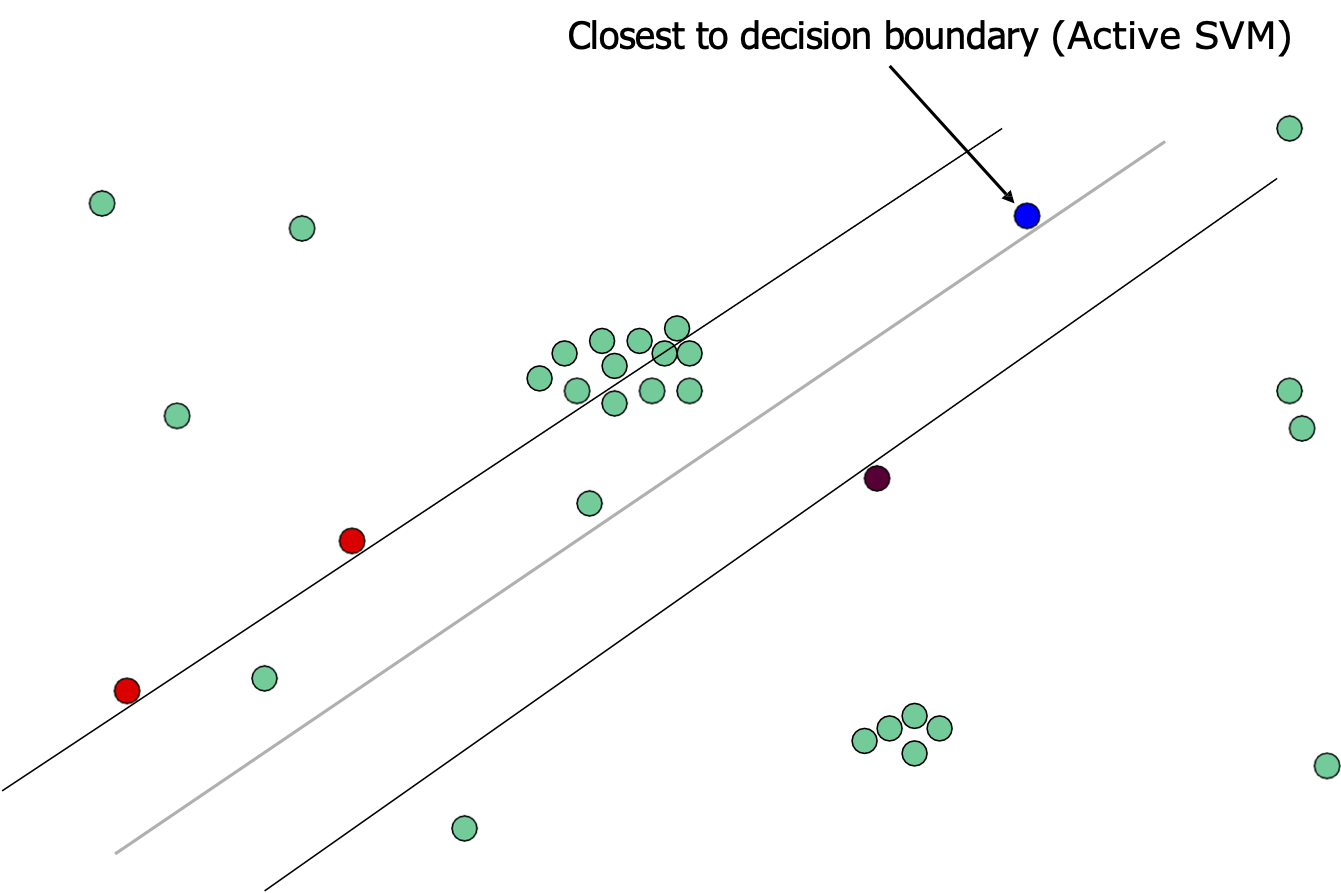
Gần ranh giới quyết định nhất (SVM tích cực)
[Jaime G. Carbonell]
Lấy mẫu đa dạng tối đa
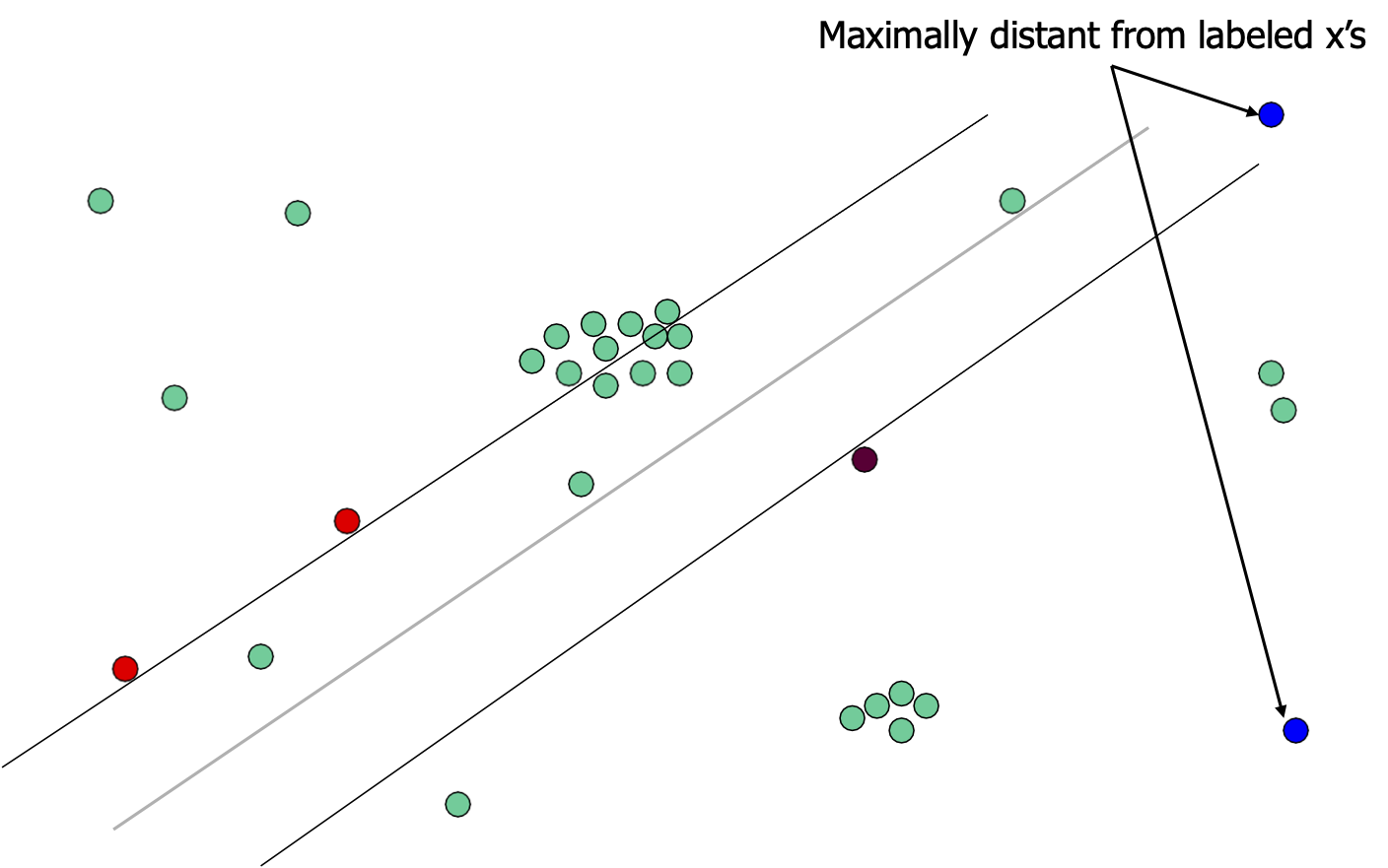
Cách xa cực đại so với x được dán nhãn
[Jaime G. Carbonell]
Khả năng dựa trên tập hợp
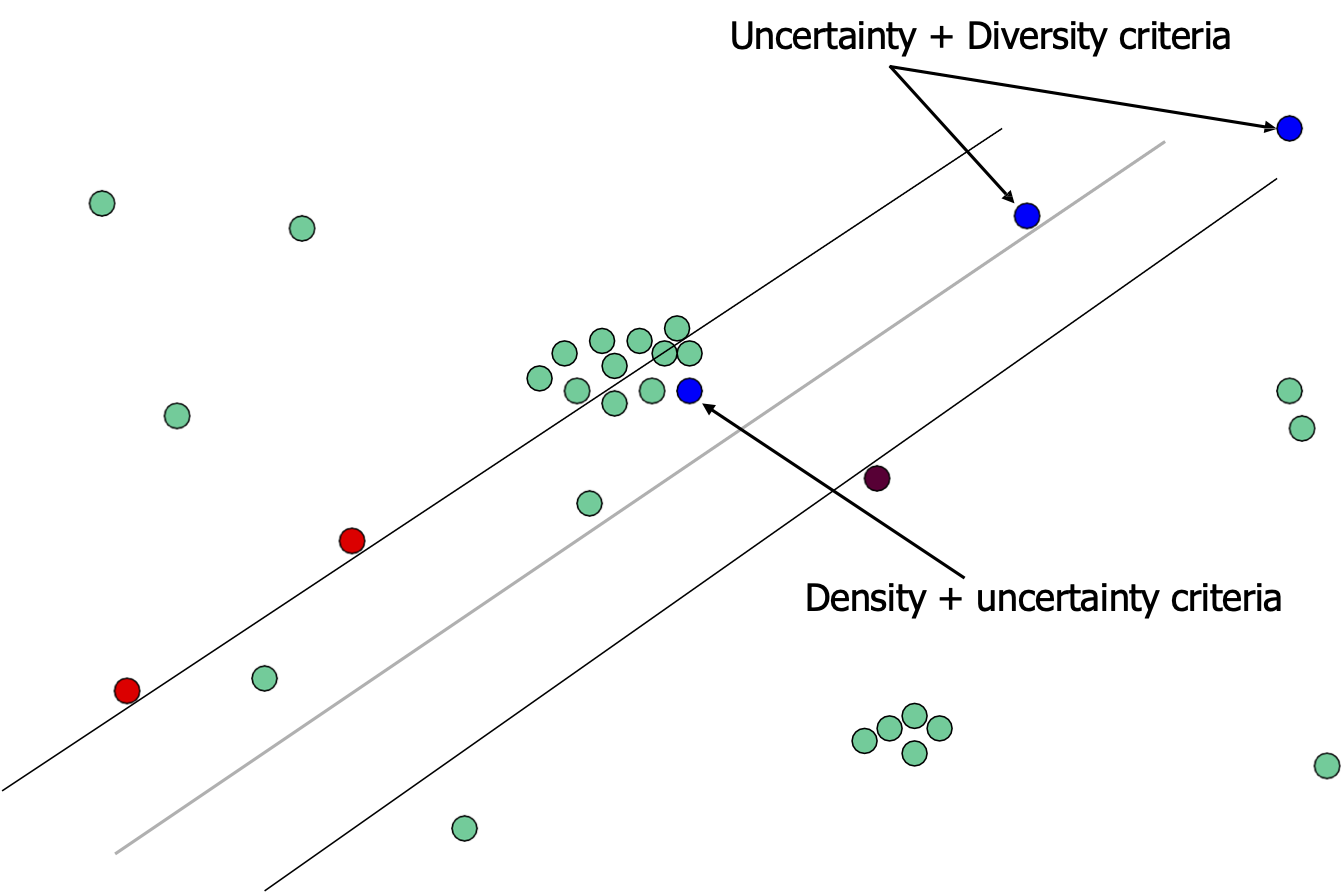
Độ không chắc chắn + Tiêu chí đa dạng
Mật độ + tiêu chí không chắc chắn
[Jaime G. Carbonell]
Phương pháp chủ động và bán giám sát dựa trên đồ thị
Các phương pháp dựa trên đồ thị
- Giả sử chúng ta được cung cấp một fnc tương tự theo cặp và các mẫu rất giống nhau có thể có cùng nhãn.
- Nếu chúng ta có nhiều dữ liệu được dán nhãn, điều này gợi ý loại thuật toán Hàng xóm gần nhất.
- Nếu bạn có nhiều dữ liệu chưa được gắn nhãn, có lẽ bạn có thể sử dụng chúng làm “bàn đạp”.
Ví dụ: các chữ số viết tay [Zhu07]:

Phương pháp dựa trên đồ thị
Ý tưởng: xây dựng một đồ thị với các cạnh giữa các mẫu rất giống nhau.
Dữ liệu chưa được gắn nhãn có thể giúp “dính” các đối tượng của cùng một lớp lại với nhau.
Các phương pháp dựa trên đồ thị
Thông thường, cách tiếp cận dẫn truyền. (Cho trước L + U, đưa ra dự đoán trên U). Được phép xuất bất kỳ nhãn nào của 𝐿 ∪ 𝑈.
Ý tưởng chính:
- Xây dựng đồ thị G với các cạnh giữa các mẫu rất giống nhau.
- Cũng có thể đã được dán lại với nhau trong các mẫu G của các lớp khác nhau.
- Chạy thuật toán phân vùng đồ thị để tách đồ thị thành nhiều phần.
Một số phương pháp:
– Cắt tối thiểu/Nhiều đường [Blum&Chawla01]
– “Cắt mềm” tối thiểu [ZhuGhahramaniLafferty’03]
– Phân vùng quang phổ
– …
SSL sử dụng các đường cắt mềm
[ZhuGhahramaniLafferty’03]
Giải hàm nhãn 𝑓(𝑥) ∈ [0,1] để giảm thiểu:
𝐽(𝑓) = ∑𝑒𝑑𝑔𝑒𝑠 (𝑖,𝑗) 𝑤𝑖𝑗 (𝑓(𝑥𝑖) − 𝑓(𝑥𝑗))2 + ∑𝑥𝑖∈𝐿 𝜆 (𝑓(𝑥𝑖) − 𝑦𝑖)2

Các nút tương tự nhận các nhãn tương tự (độ tương tự có trọng số)
Thỏa thuận với các nhãn (thỏa thuận không được thực thi nghiêm ngặt)
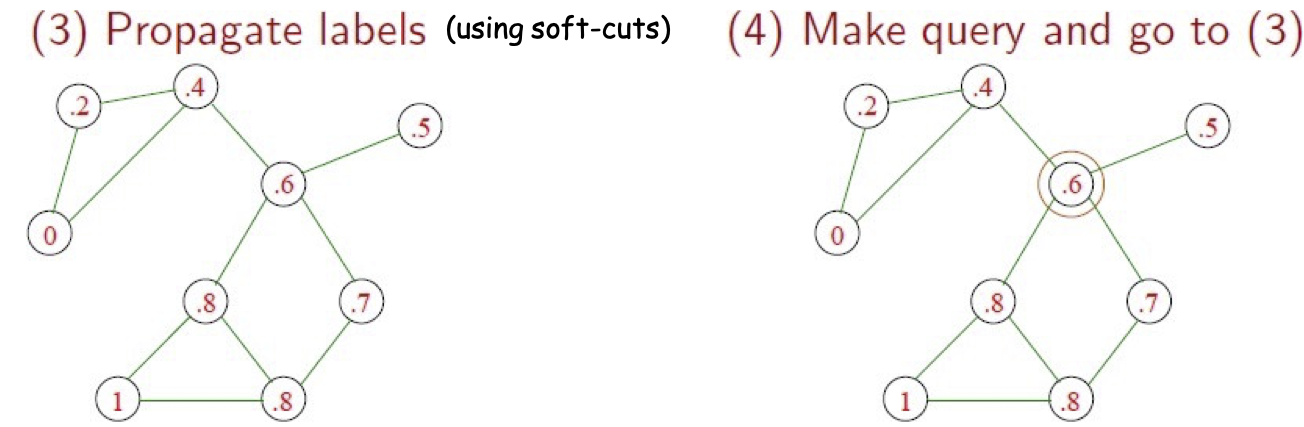
Học tích cực với lan truyền nhãn
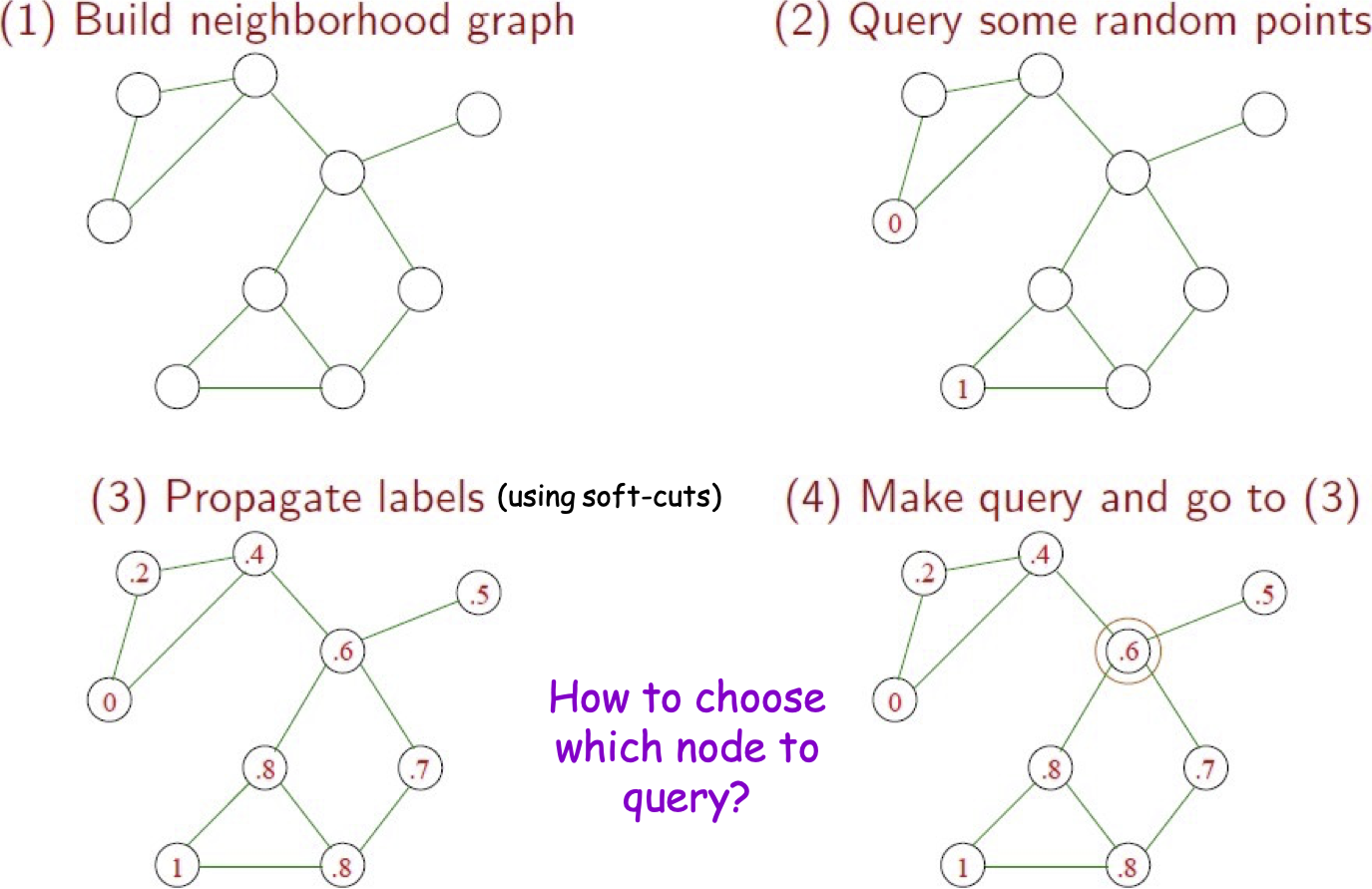
(sử dụng soft-cut)
Làm thế nào để chọn nút nào để truy vấn?
Học tích cực với lan truyền nhãn
Một ý tưởng tự nhiên: truy vấn điểm không chắc chắn nhất.
Nhưng điểm này chỉ có một cạnh. Truy vấn sẽ không có nhiều tác động!
(thậm chí tệ hơn: một nút bị cô lập hoàn toàn)
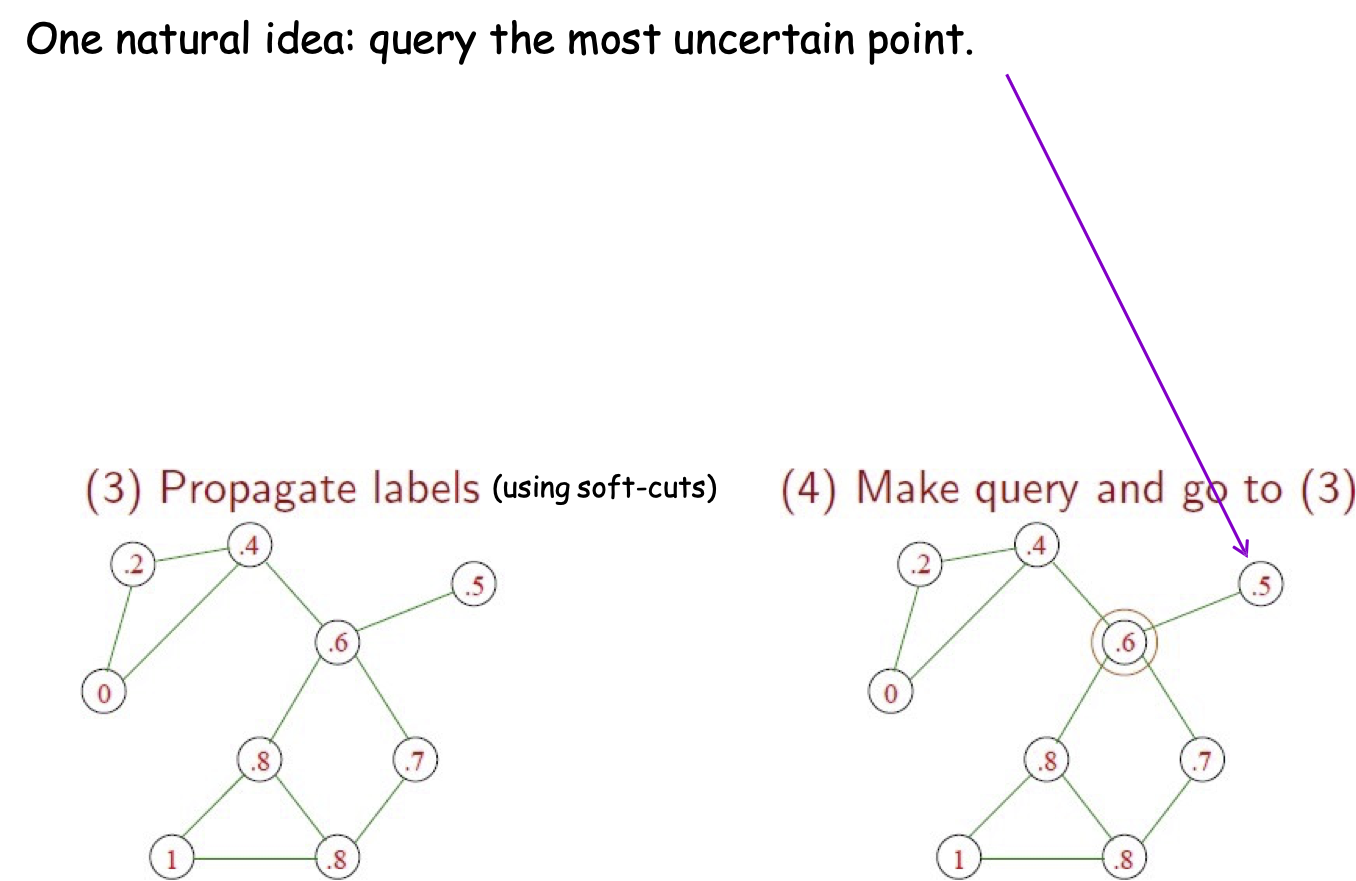
(sử dụng soft-cut)
Học tích cực với truyền nhãn
Thay vào đó, hãy sử dụng phương pháp heuristic 1-step-lookahead:
- Đối với một nút có nhãn 𝑝, giả sử rằng truy vấn sẽ có xác suất 𝑝 câu trả lời trả về là 1, 1 − 𝑝 của câu trả lời trả về 0.
- Tính “độ tin cậy trung bình” sau khi chạy soft-cut trong từng trường hợp: 𝑝 1⁄𝑛 ∑𝑥𝑖 max (𝑓1(𝑥𝑖) , 1 − 𝑓1(𝑥𝑖)) + (1 − 𝑝) 1⁄𝑛 ∑𝑥𝑖 max (𝑓0(𝑥𝑖) , 1 − 𝑓0(𝑥𝑖))
- Truy vấn Nút s.t. số lượng này là cao nhất (bạn muốn tự tin hơn về trung bình).
(sử dụng các phép cắt mềm)
Thực hành Học tích cực với Lan truyền Nhãn
- Hoạt động tốt cho Phân đoạn Video (Fathi-Balcan-Ren-Regh, BMVC 11).

Những điều bạn nên biết
- Học tích cực có thể thực sự hữu ích, có thể mang lại những cải tiến theo cấp số nhân về độ phức tạp của nhãn (cả về mặt lý thuyết và thực tế)!
- Các phương pháp phỏng đoán phổ biến (ví dụ: phương pháp dựa trên lấy mẫu độ không đảm bảo). Cần phải rất cẩn thận do sai lệch lấy mẫu.
- Chương trình học tập tích cực dựa trên bất đồng an toàn.
- Hiểu cách chúng hoạt động chính xác trong các tình huống không có nhiễu.