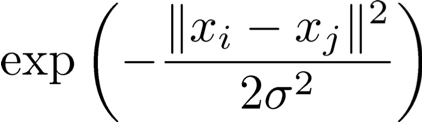Bài đọc tham khảo
Machine Learning 10-701 (Semi-supervised learning in SVMs-Principal Component Analysis)
Machine Learning 10-701 (EM for Bayes Nets-Co-Training for semi-supervised learning)
Thuật Toán Self-Training Và Co-Training Ứng Dụng Trong Phân Lớp Văn Bản (Trần Thị Oanh)
Bài đọc:
- Học bán giám sát. Bách khoa toàn thư về học máy. Jerry Zhu, 2010
- Kết hợp dữ liệu được gắn nhãn và không được gắn nhãn với đồng đào tạo. Avrim Blum, Tom Mitchell. COLT 1998.
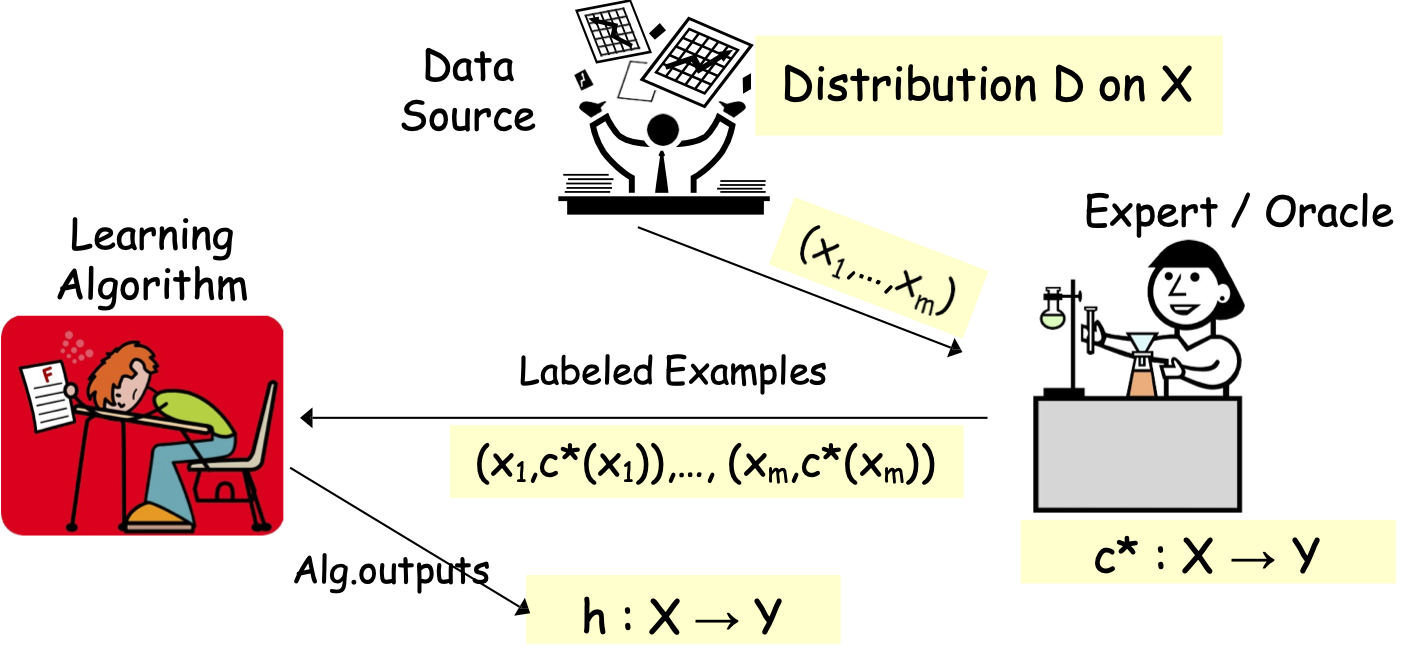
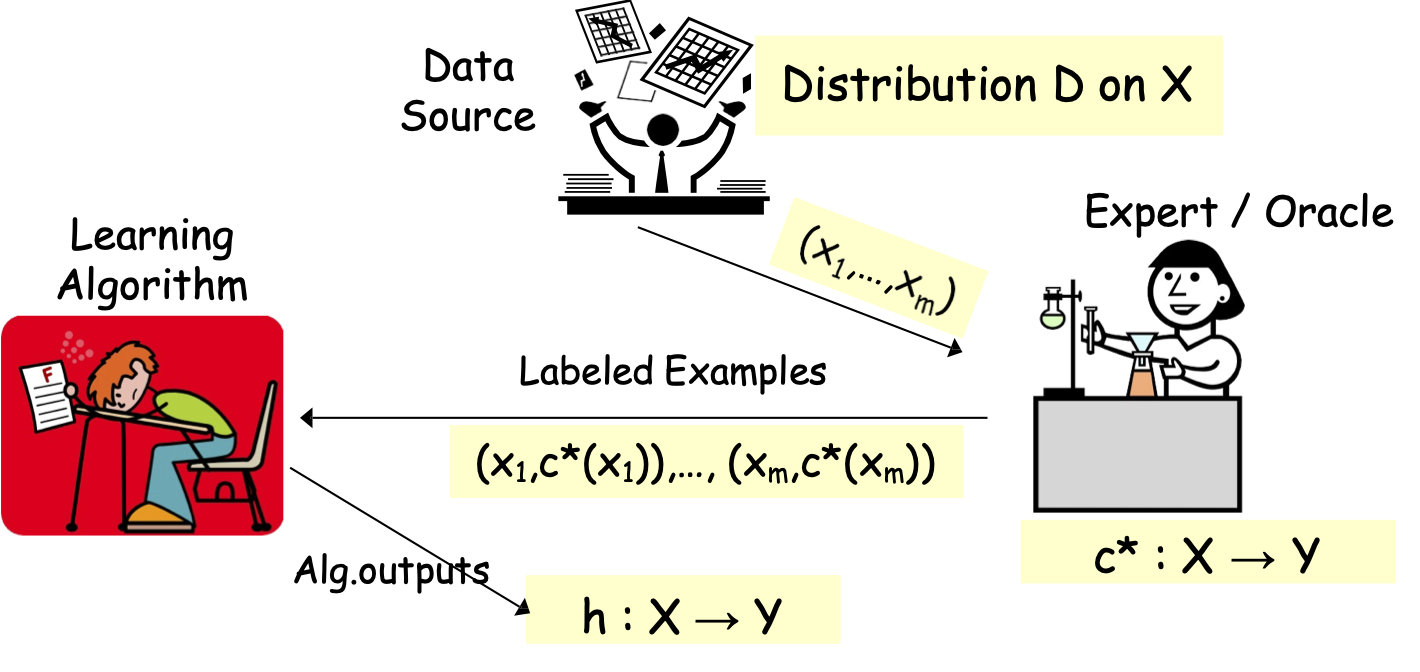
Học tập được giám sát đầy đủ
Thuật toán học tập
Chuyên gia / Oracle
Nguồn dữ liệu
Đầu ra Alg.
Phân phối D trên X
c* : X → Y
(x1,c*(x1)),…, (xm,c*(xm))
h : X → Y
Các mẫu được gắn nhãn
Học có giám sát hoàn toàn
Thuật toán học
Chuyên gia / Oracle
Nguồn dữ liệu
Alg.outputs
Phân phối D trên X
c* : X → Y
(x1,c*(x1)),…, (xm,c*(xm))
h : X → Y
Các mẫu được gắn nhãn
Sl={(x1, y1), …,(xml , yml)}
xi được lấy i.i.d từ D, yi = c∗(xi)
Mục tiêu: h có lỗi nhỏ hơn D.
errD (h) = Prx~ D (h(x) ≠ c∗(x))
Hai khía cạnh cốt lõi của học có giám sát
Tính toán
Thiết kế thuật toán. Làm thế nào để tối ưu hóa?
Tự động tạo các quy tắc hoạt động tốt trên dữ liệu được quan sát.
- Ví dụ: Naïve Bayes, hồi quy logistic, SVM, Adaboost, v.v.
Dữ liệu (Được gắn nhãn)
Giới hạn tin cậy, khái quát hóa
Độ tin cậy cho hiệu quả của quy tắc đối với dữ liệu trong tương lai.
- Thứ nguyên VC, độ phức tạp của Rademacher, giới hạn dựa trên lề, v.v.
Mô hình cổ điển Ngày nay Không đủ
Các ứng dụng hiện đại: lượng lớn dữ liệu thô.
Chỉ một phần rất nhỏ có thể được chú thích bởi các chuyên gia con người.
Trình tự protein

Hàng tỷ trang web

Hình ảnh
ML hiện đại: tiếp cận học tập mới
Ứng dụng hiện đại: lượng lớn dữ liệu thô.
Các kỹ thuật sử dụng dữ liệu tốt nhất, giảm thiểu nhu cầu can thiệp của chuyên gia/con người.
Các mô hình nơi đã có sự tiến bộ lớn.
- Học bán giám sát, Học tập tích cực (tương tác).

Học bán giám sát
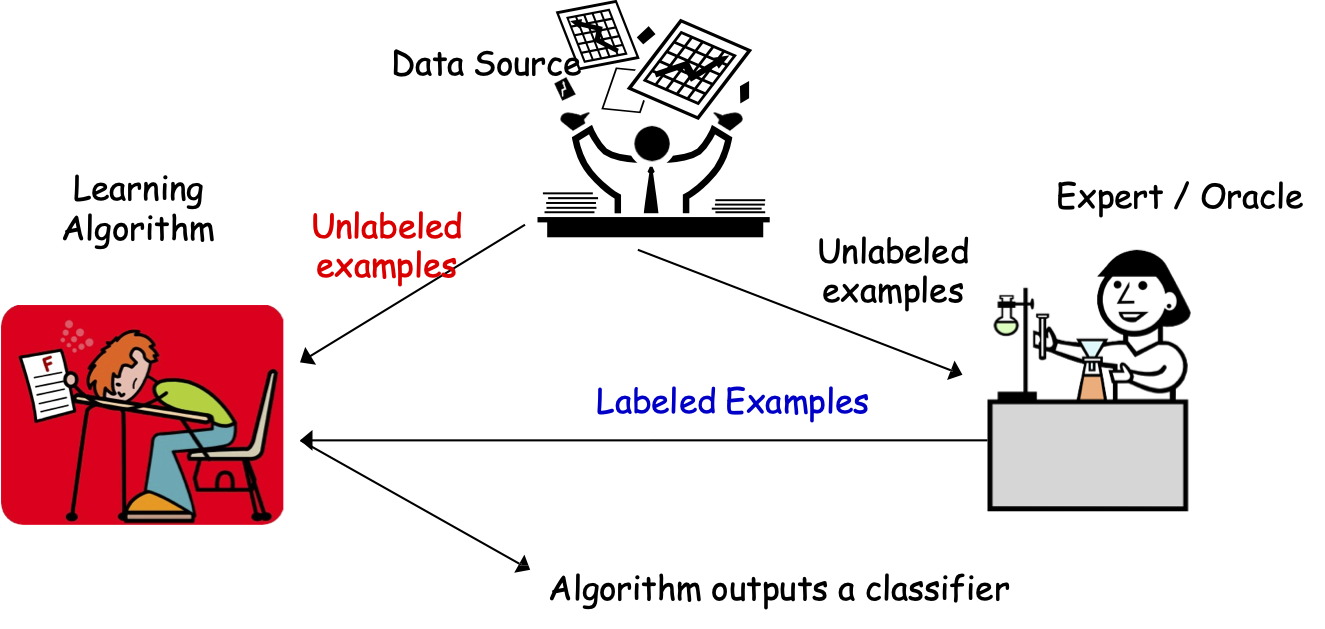
Thuật toán học
Chuyên gia / Oracle
Nguồn dữ liệu
Các mẫu chưa được gắn nhãn
Thuật toán đưa ra một bộ phân loại
Các mẫu chưa được gắn nhãn
Các mẫu được gắn nhãn
Sl={(x1, y1), …,(xml , yml)}
xi được lấy i.i.d từ D, yi = c∗(xi)
Su={x1, …,xmu} được lấy i.i.d từ D
Mục tiêu: h có sai số nhỏ hơn D.
errD (h) = Prx~ D (h(x) ≠ c∗(x))
Học tập bán giám sát
- Chủ đề nghiên cứu chính trong ML.
- Một số phương pháp đã được phát triển để cố gắng sử dụng dữ liệu chưa được gắn nhãn nhằm cải thiện hiệu suất, ví dụ:
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]
Bài kiểm tra về giải thưởng thời gian tại ICML!
Hội thảo [ICML ’03, ICML’ 05, …]
Sách:
- Học bán giám sát, MIT 2006 O. Chapelle, B. Scholkopf và A. Zien (eds)
- Giới thiệu về học bán giám sát, Morgan & Claypool, 2009 Zhu & Goldberg
Học bán giám sát
- Chủ đề nghiên cứu chính trong ML.
- Một số phương pháp đã được phát triển để cố gắng sử dụng dữ liệu chưa được gắn nhãn nhằm cải thiện hiệu suất, ví dụ:
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]
Kiểm tra thời gian đạt giải thưởng tại ICML!
Vừa có ứng dụng rộng rãi vừa có kiến thức nền tảng vững chắc!!!
Học tập bán giám sát
- Chủ đề nghiên cứu chính trong ML.
- Một số phương pháp đã được phát triển để cố gắng sử dụng dữ liệu chưa được gắn nhãn nhằm cải thiện hiệu suất, ví dụ:
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]
Phần thưởng Kiểm tra thời gian tại ICML!
Hôm nay: thảo luận về các phương pháp này.
Rất thú vị, tất cả đều khai thác dữ liệu chưa được gắn nhãn theo những cách khác nhau, rất thú vị và sáng tạo.
Học bán giám sát:
không truy vấn. Chỉ cần có nhiều dữ liệu bổ sung chưa được gắn nhãn.
Một chút khó hiểu; không rõ dữ liệu chưa được gắn nhãn có thể làm gì cho chúng ta…. Nó đang thiếu thông tin quan trọng nhất. Làm thế nào nó có thể giúp chúng ta trong những cách đáng kể?
Key Insight
Dữ liệu chưa được gắn nhãn hữu ích nếu chúng ta có niềm tin không chỉ về hình thức của mục tiêu mà còn về mối quan hệ của nó với phân phối cơ bản.
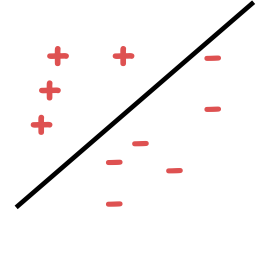
SVM bán giám sát [Joachims ’99]
Tính chính quy dựa trên lề
Hàm mục tiêu đi qua các vùng có mật độ thấp (lề lớn).
- giả sử chúng ta đang tìm kiếm dấu phân cách tuyến tính
- niềm tin: nên tồn tại một dấu phân cách lớn
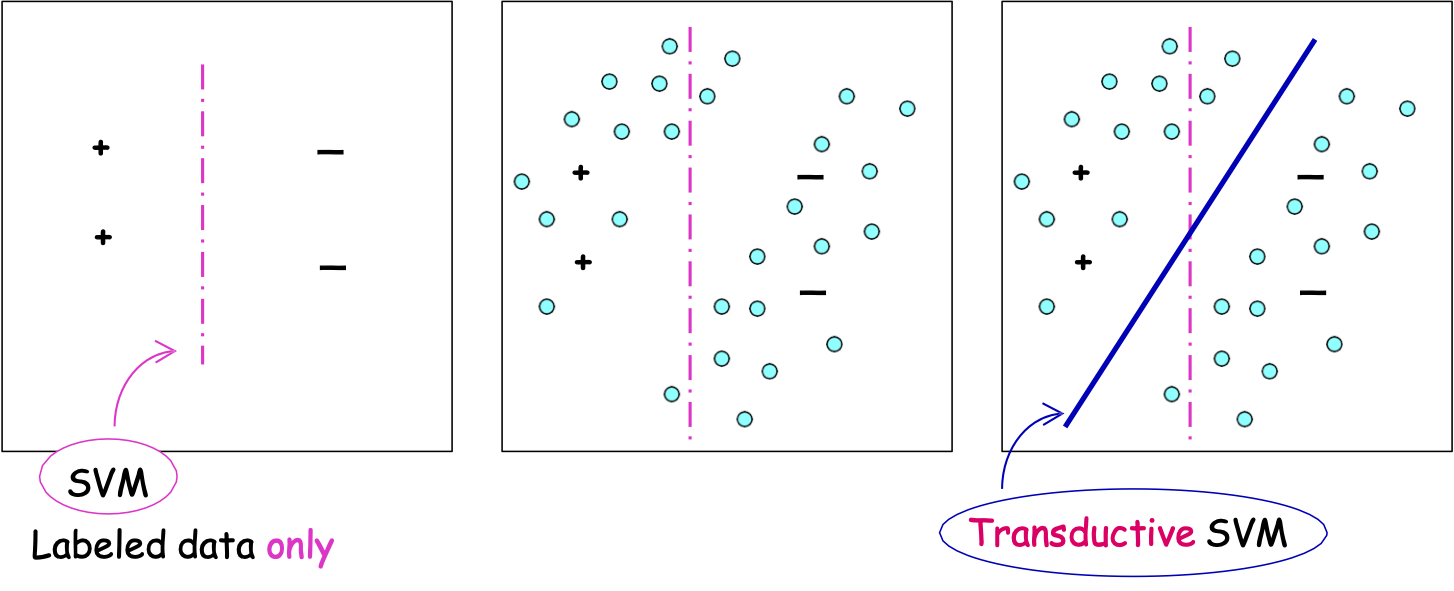
Chỉ dữ liệu được dán nhãn
SVM truyền dẫn
Máy Vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho dấu phân cách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn. [Joachims ‘99]
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 s.t.:
- yi w ⋅ xi ≥ 1, với mọi i ∈ {1, … ,ml}
- y^u w ⋅ xu ≥ 1, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
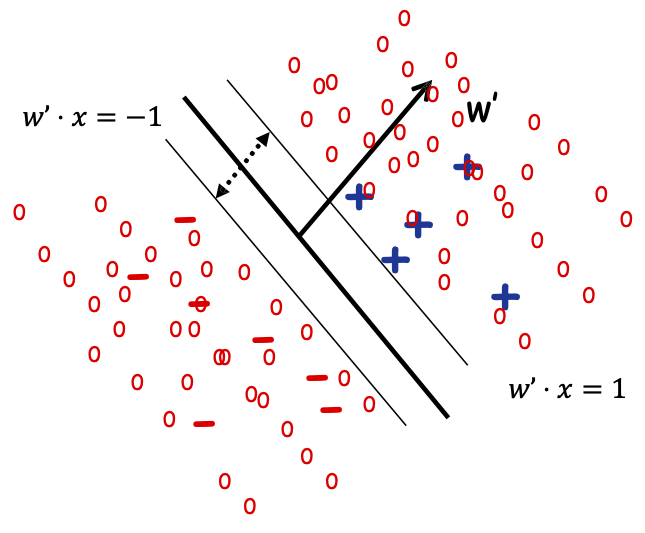
Tìm nhãn của mẫu không nhãn và 𝑤 s.t. 𝑤 phân tách cả mẫu có nhãn và không nhãn dữ liệu với lề tối đa.
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho dấu phân cách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn. [Joachims ’99]
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 + 𝐶 ∑𝑖 𝜉𝑖 + 𝐶 ∑𝑢 𝜉^𝑢
- yi w ⋅ xi ≥ 1-𝜉𝑖, với mọi i ∈ {1, … ,ml}
- y^u w ⋅ xu ≥ 1 − 𝜉⌃𝑢, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
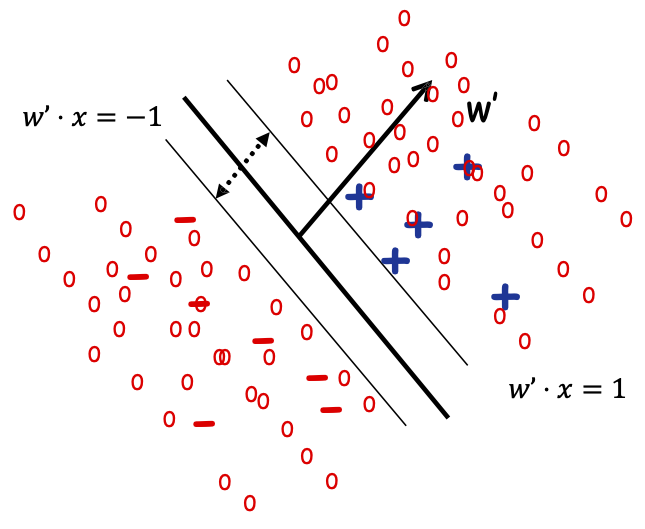
Tìm nhãn của mẫu không nhãn và 𝑤 s.t. 𝑤 phân tách cả mẫu có nhãn và không nhãn dữ liệu với lề tối đa.
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho bộ phân tách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn.
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 + 𝐶 ∑𝑖 𝜉𝑖 + 𝐶 ∑𝑢 𝜉^𝑢
- yi w ⋅ xi ≥ 1-𝜉𝑖, với mọi i ∈ {1, … ,ml}
- y^u w ⋅ xu ≥ 1 − 𝜉⌃𝑢, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
NP-hard… .. Chỉ lồi sau khi bạn đoán nhãn… có quá nhiều khả năng đoán…
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho bộ phân tách với dữ liệu được dán nhãn và không được dán nhãn lề lớn.
Ý tưởng cấp cao Heuristic (Joachims):
- Đầu tiên tối đa hóa lề trên các điểm được gắn nhãn
- Sử dụng điều này để gán nhãn ban đầu cho các điểm chưa được gắn nhãn dựa trên dấu tách này.
- Hãy thử lật nhãn của các điểm chưa được gắn nhãn để xem liệu làm như vậy có thể tăng lề hay không
Tiếp tục cho đến khi không còn cải tiến nào nữa. Tìm một giải pháp tối ưu cục bộ.
Thử nghiệm [Joachims99]
![HÌNH 19.10. Thử nghiệm [Joachims99].](https://cdn.jsdelivr.net/gh/vtgcdn/iml19.viettechgroup.com@latest/19_sslfig10.png)
Máy vectơ hỗ trợ truyền dẫn
Phân phối hữu ích

Tương thích cao
Phân phối không hữu ích

Lề không thỏa mãn

Lề thỏa mãn
Các cụm 1/𝛾2, tất cả các phân vùng có thể phân tách bằng lề lớn
Đồng đào tạo [Blum & Mitchell ’98]
Loại giả định tính chính quy cơ bản khác nhau:
Tính nhất quán hoặc Thỏa thuận giữa các bộ phận
Đồng đào tạo: Tự nhất quán
Thỏa thuận giữa hai phần: đồng đào tạo [Blum-Mitchell98].
– các mẫu chứa hai bộ tính năng đầy đủ, x = ⟨ x1, x2 ⟩
– niềm tin: các phần nhất quán, tức là ∃ c1, c2 s.t. c1(x1)=c2(x2)=c*(x)
Ví dụ: nếu chúng ta muốn phân loại các trang web: x = ⟨ x1, x2 ⟩ là trang chủ của giảng viên hay không phải

x – Thông tin liên kết & Thông tin văn bản
x1– Thông tin văn bản
x2– Thông tin liên kết
Đồng đào tạo lặp lại
Ý tưởng: Sử dụng mẫu nhỏ được dán nhãn để học các quy tắc ban đầu.
- Ví dụ: “cố vấn của tôi” trỏ đến một trang là một dấu hiệu tốt cho thấy đó là trang chủ của khoa.
- Ví dụ: “Tôi đang giảng dạy” trên một trang là một dấu hiệu tốt cho thấy đó là trang chủ của khoa.
Ý tưởng: Sử dụng dữ liệu chưa được gắn nhãn để lan truyền thông tin đã học.
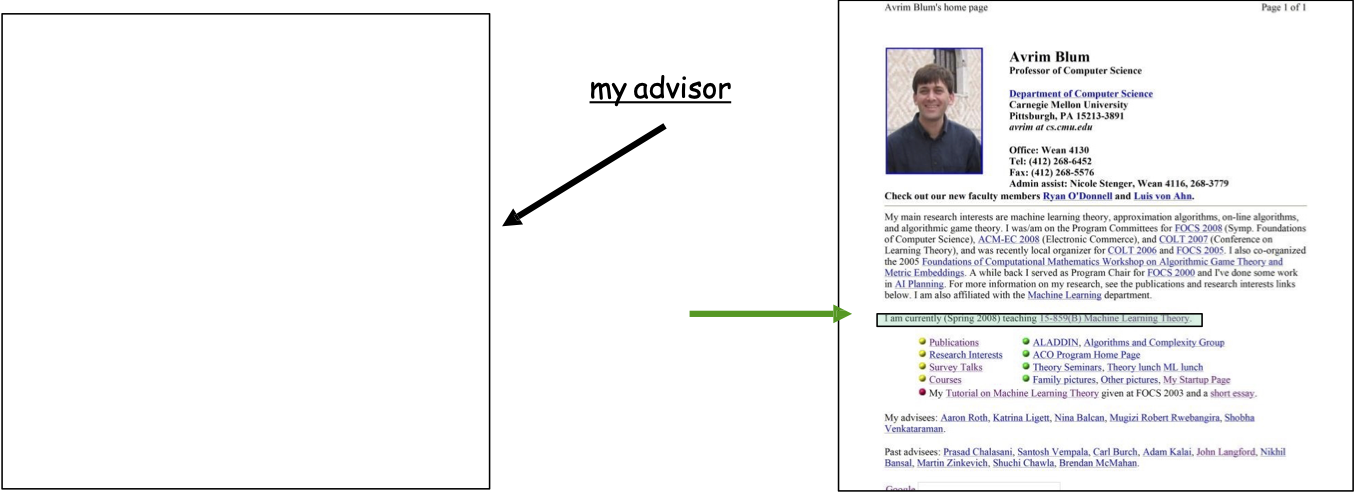
Đồng đào tạo lặp đi lặp lại
Ý tưởng: Sử dụng mẫu nhỏ được dán nhãn để học các quy tắc ban đầu.
- Ví dụ: “cố vấn của tôi” trỏ đến một trang là một dấu hiệu tốt cho thấy đó là trang chủ của khoa.
- Ví dụ: “Tôi đang giảng dạy” trên một trang là một dấu hiệu tốt cho thấy đó là trang chủ của khoa.
Ý tưởng: Sử dụng dữ liệu chưa được gắn nhãn để lan truyền thông tin đã học.
Hãy tìm các mẫu không được gắn nhãn trong đó một quy tắc là chắc chắn còn quy tắc kia thì không. Có nó gắn nhãn mẫu, và huấn luyện cho quy tắc còn lại.
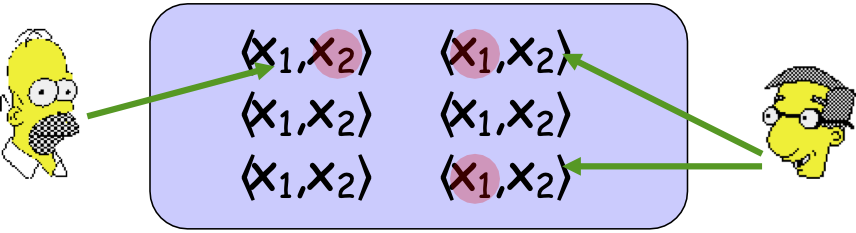
Đào tạo 2 bộ phân loại, một bộ phân loại trên mỗi loại thông tin. Sử dụng cái này để giúp đào tạo cái kia.
Đồng đào tạo lặp lại
Hoạt động bằng cách sử dụng dữ liệu chưa được gắn nhãn để lan truyền thông tin đã học.
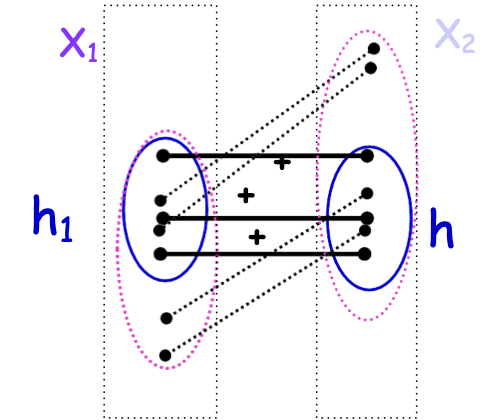
- Có thuật toán học A1, A2 trên mỗi một trong hai khung nhìn.
- Sử dụng dữ liệu được dán nhãn để học hai hyp. ban đầu. h1, h2.
Lặp lại
- Xem qua dữ liệu chưa được gắn nhãn để tìm các mẫu trong đó một trong số hi là tự tin nhưng khác thì không.
- Tự tin đặt nhãn hi cho thuật toán A3-i.
Ứng dụng gốc: Phân loại trang web
12 mẫu được gắn nhãn, 1000 mẫu không được gắn nhãn

(chạy mẫu)
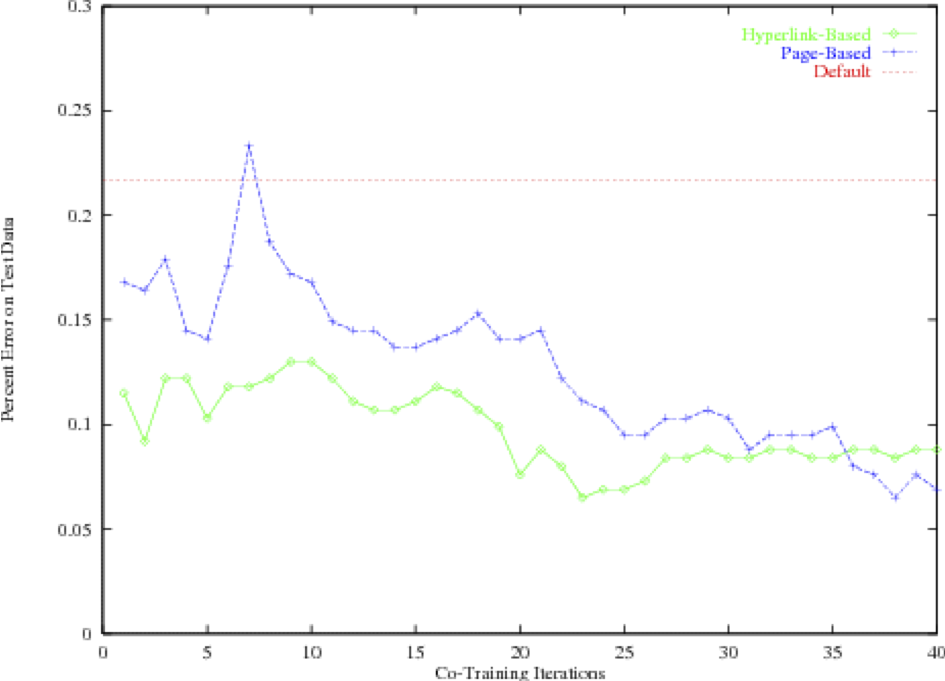
Đồng đào tạo lặp lại
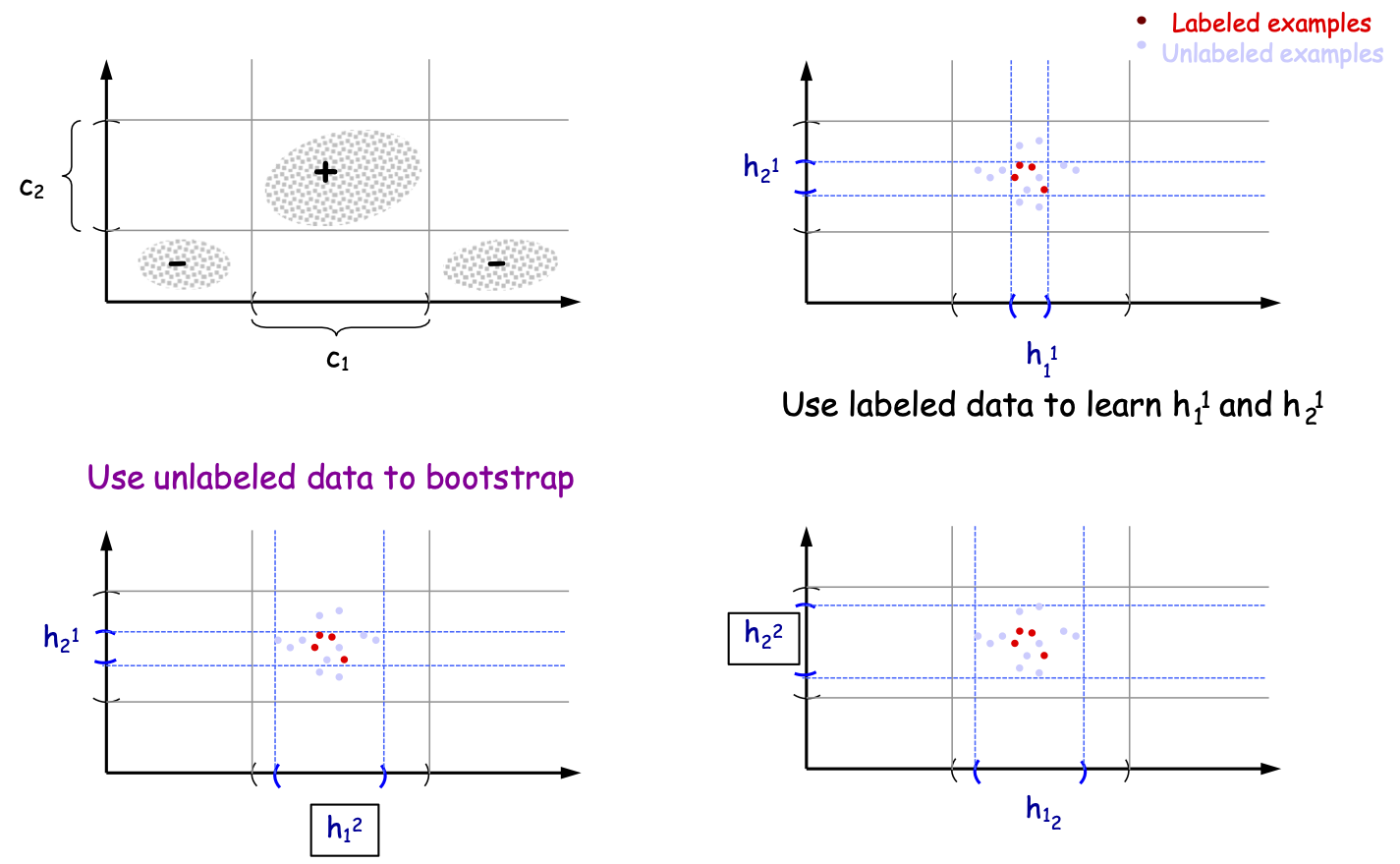
Một ví dụ đơn giản: Khoảng thời gian học
Mẫu được gắn nhãn
Các mẫu chưa được gắn nhãn
Sử dụng dữ liệu được gắn nhãn để học h11 và h21
Sử dụng dữ liệu chưa được gắn nhãn để khởi động
Mở rộng, Ví dụ: Khoảng thời gian học tập
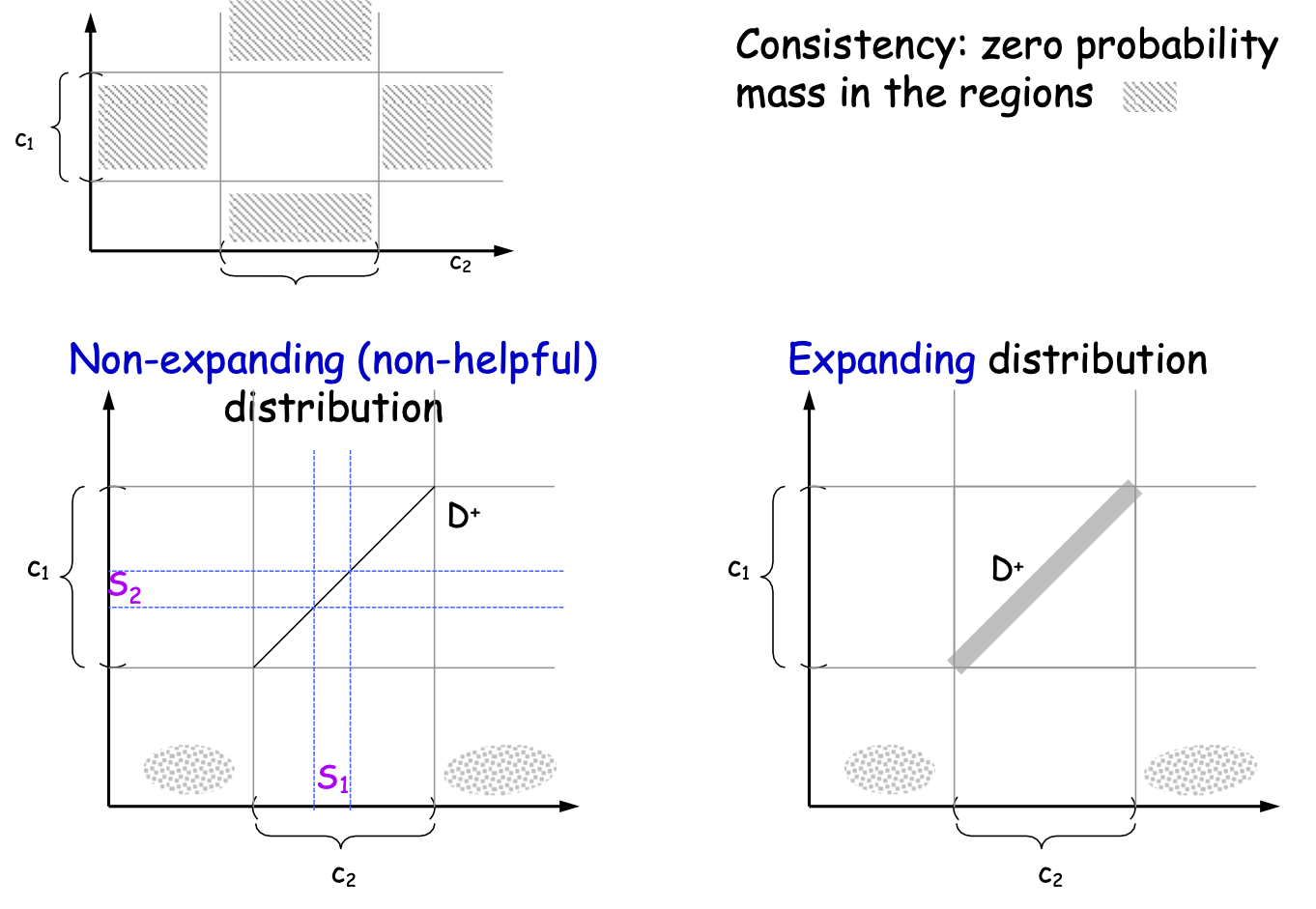
Tính nhất quán: khối lượng xác suất bằng không trong các vùng
Phân phối không mở rộng (không hữu ích)
Phân phối mở rộng
Đồng đào tạo: Đảm bảo về mặt lý thuyết
Chúng ta cần những thuộc tính nào để đồng đào tạo hoạt động tốt?
Chúng ta cần các giả định về:
- phân phối dữ liệu cơ bản
- các thuật toán học tập ở cả hai phía
[Blum & Mitchell, COLT ’98]
- Độc lập được gắn nhãn
- Alg. để học từ nhiễu ngẫu nhiên.
[Balcan, Blum, Yang, NIPS 2004]
- Mở rộng phân phối.
- Alg. chỉ để học từ dữ liệu tích cực.
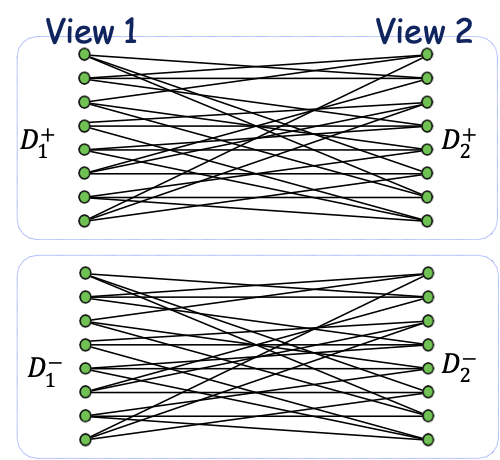
Đồng huấn luyện [BM’98]
Giả sử ℎ1 là một biến dự báo ít hữu ích nếu
Pr [ℎ1 (𝑥) = 1 |𝑐1 (𝑥) = 1] > Pr [ℎ1 (𝑥) = 1 |𝑐1 (𝑥) = 0] + 𝛾.
Có xác suất nói tích cực đối với kết quả tích cực thực sự cao hơn so với kết quả tiêu cực thực sự, ít nhất là ở một khoảng cách 𝛾 nào đó
Giả sử chúng ta có đủ dữ liệu được dán nhãn để tạo ra một điểm xuất phát như vậy.
Định lý: nếu 𝐶 có thể học được từ nhiễu phân loại ngẫu nhiên, chúng ta có thể sử dụng ℎ1 hữu ích yếu cộng với dữ liệu không được gắn nhãn để tạo ra một bộ học mạnh dưới sự độc lập được gán nhãn.
Đồng đào tạo: Lợi ích về nguyên tắc
[BB’05]: Dưới sự độc lập được gán nhãn, bất kỳ cặp 〈ℎ1, ℎ2〉 nào có độ đồng thuận cao đối với dữ liệu không được gắn nhãn phải gần với:
- 〈𝑐1, 𝑐2〉, 〈¬𝑐1, ¬𝑐2〉, 〈𝑡𝑟𝑢𝑒, 𝑡𝑟𝑢𝑒〉, or 〈𝑓𝑎𝑙𝑠𝑒, 𝑓𝑎𝑙𝑠𝑒〉
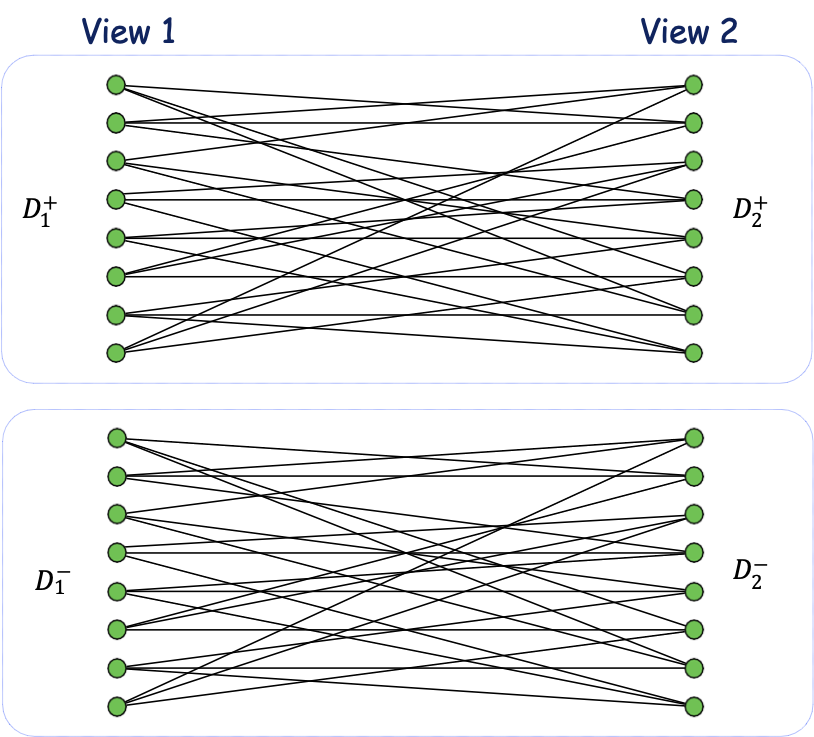
Đồng đào tạo: Lợi ích về nguyên tắc
[BB’05]: Dưới sự độc lập được gán nhãn, bất kỳ cặp 〈ℎ1, ℎ2〉 nào có độ đồng thuận cao đối với dữ liệu không được gán nhãn phải gần với:
- 〈𝑐1, 𝑐2〉 , 〈¬𝑐1, ¬𝑐2〉, 〈𝑡𝑟𝑢𝑒, 𝑡𝑟𝑢𝑒〉, or 〈𝑓𝑎𝑙𝑠𝑒, 𝑓𝑎𝑙𝑠𝑒〉
Ví dụ:
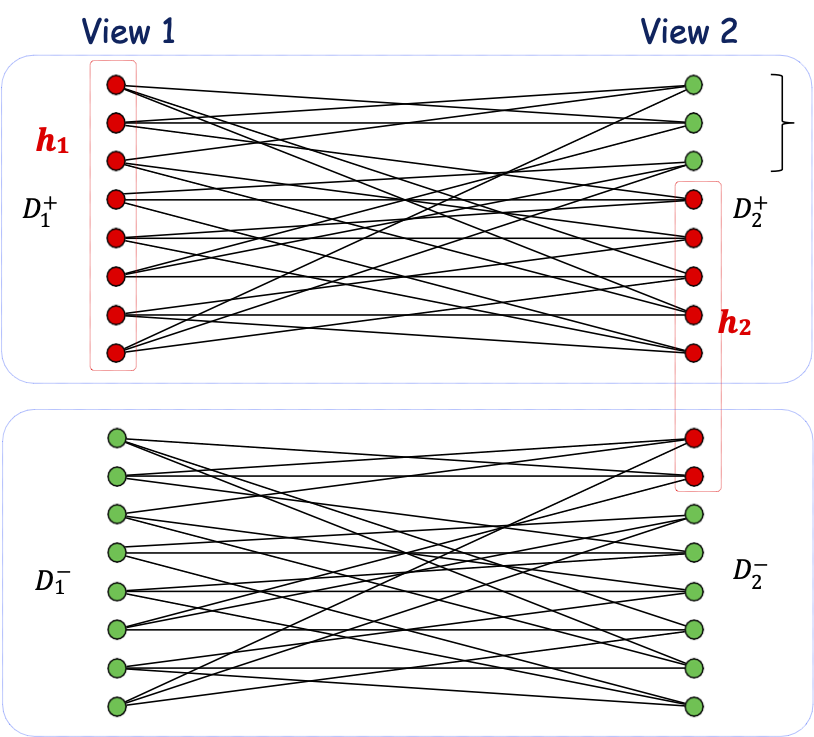
Vì độc lập mà ta sẽ thấy rất nhiều sự bất đồng….,
Đồng đào tạo/SSL nhiều chế độ xem: Thỏa thuận tối ưu hóa trực tiếp
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminh1,h2 ∑l=12 ∑i=1ml l(hl(xi) , yi) + C∑i=1mu agreement(h1(xi) , h2(xi))

Mỗi người trong số chúng có lỗi được dán nhãn nhỏ
Bộ điều chỉnh thành khuyến khích thỏa thuận về dữ liệu không được gắn nhãn
Ví dụ:
P. Bartlett, D. Rosenberg, AISTATS 2007; K. Sridharan, S. Kakade, COLT 2008
Đồng đào tạo/SSL nhiều chế độ xem: Tối ưu hóa trực tiếp thỏa thuận
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminh1,h2 ∑l=12 ∑i=1ml l(hl(xi) , yi) + C∑i=1mu agreement(h1(xi) , h2(xi))
- Hàm mất l(h(xi) , yi)
- Ví dụ: mất bình phương l(h(xi) , yi) = (yi − ℎ(xl)) 2
- Ví dụ: mất 0/1 l(h(xi) , yi) = 1𝑦𝑖≠ℎ(𝑥𝑖)
Ví dụ:
P. Bartlett, D. Rosenberg, AISTATS 2007; K. Sridharan, S. Kakade, COLT 2008
Ứng dụng gốc: Phân loại trang web
12 mẫu được gắn nhãn, 1000 mẫu không được gắn nhãn

(chạy mẫu)
Nhiều ứng dụng khác
, ví dụ: [Levin-Viola-Freund03] xác định các đối tượng trong hình ảnh.
Hai loại tiền xử lý khác nhau.

Ví dụ: trích xuất thực thể có tên [Collins&Singer99].
– “Tôi đã đến London ngày hôm qua”
…
Trung tâm của NELL!!!
…
Tính chính quy dựa trên tính tương tự
[Blum&Chwala01], [ZhuGhahramaniLafferty03]
Phương pháp dựa trên đồ thị
- Giả sử chúng ta được cung cấp một fnc tương tự theo cặp và các mẫu rất giống nhau có thể có cùng nhãn.
- Nếu chúng ta có nhiều dữ liệu được dán nhãn, điều này cho thấy một Loại thuật toán Nearest-Neighbor.
- Nếu bạn có nhiều dữ liệu chưa được gắn nhãn, có lẽ bạn có thể sử dụng chúng làm “bàn đạp”.
Ví dụ: các chữ số viết tay [Zhu07]:

Phương pháp dựa trên đồ thị
Ý tưởng: xây dựng một đồ thị với các cạnh giữa các mẫu rất giống nhau.
Dữ liệu chưa được gắn nhãn có thể giúp “dính” các đối tượng của cùng một lớp lại với nhau.
Phương pháp dựa trên đồ thị
Ý tưởng: xây dựng một đồ thị với các cạnh giữa các mẫu rất giống nhau. Dữ liệu chưa được gắn nhãn có thể giúp “dính” các đối tượng của cùng một lớp lại với nhau.

Nhận dạng người trong hình ảnh webcam: Ứng dụng học bán giám sát. [Balcan,Blum,Choi, Lafferty, Pantano, Rwebangira, Xiaojin Zhu], Hội thảo ICML 2005 về Học với Dữ liệu Huấn luyện được Phân loại Một phần.
Các phương pháp dựa trên đồ thị
Thông thường, cách tiếp cận dẫn truyền. (Cho trước L + U, đưa ra dự đoán trên U). Được phép xuất bất kỳ nhãn nào của 𝐿 ∪ 𝑈.
Ý tưởng chính:
- Xây dựng đồ thị G với các cạnh giữa các mẫu rất giống nhau.
- Cũng có thể được dán lại với nhau trong các mẫu G của các lớp khác nhau.
- Chạy thuật toán phân vùng đồ thị để tách đồ thị thành từng phần.
Một số phương pháp:
– Cắt tối thiểu/Multiway [Blum&Chawla01]
– Cắt “mềm” tối thiểu [ZhuGhahramaniLafferty’03]
– Phân vùng quang phổ
– …
Những điều bạn nên biết
- Dữ liệu không được gắn nhãn hữu ích nếu chúng ta có niềm tin không chỉ về hình thức của mục tiêu mà còn về mối quan hệ của nó với phân phối cơ bản.
- Các loại thuật toán khác nhau (dựa trên niềm tin khác nhau).
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]
Tài liệu bổ sung về các phương pháp dựa trên đồ thị
Cắt tối thiểu/Nhiều đường [Blum&Chawla01]
Mục tiêu: Giải quyết các nhãn trên các điểm không được gắn nhãn để giảm thiểu tổng trọng lượng của các cạnh có các điểm cuối có các nhãn khác nhau. (tức là tổng trọng số của các cạnh xấu)
- Nếu chỉ có hai nhãn, có thể được giải quyết hiệu quả bằng cách sử dụng thuật toán cắt tối thiểu luồng tối đa
– Tạo siêu nguồn 𝑠 được kết nối bởi các cạnh có trọng số ∞ với tất cả + các điểm có nhãn.
– Tạo siêu chìm 𝑡 được kết nối bởi các cạnh có trọng số ∞ cho tất cả các điểm được gắn nhãn −.
– Tìm vết cắt 𝑠-𝑡 có trọng lượng tối thiểu
![HÌNH 19.29. Cắt tối thiểu/Nhiều đường [Blum&Chawla01].](https://cdn.jsdelivr.net/gh/vtgcdn/iml19.viettechgroup.com@latest/19_sslfig29.png)
“Cắt mềm” tối thiểu
[ZhuGhahramaniLafferty’03]
Mục tiêu Giải vectơ xác suất trên các nhãn 𝑓𝑖 trên mỗi điểm không được gắn nhãn 𝑖.
(các điểm được gắn nhãn nhận các vectơ tọa độ theo hướng của nhãn đã biết của chúng)
- Giảm thiểu ∑𝑒=(𝑖,𝑗) 𝑤𝑒 ‖𝑓𝑖 − 𝑓𝑗‖ 2 trong đó ‖𝑓𝑖 − 𝑓𝑗‖ là khoảng cách Euclide.
- Có thể được thực hiện hiệu quả bằng cách giải một tập hợp các phương trình tuyến tính.
Cách tạo biểu đồ
- Theo kinh nghiệm, cách sau hoạt động tốt: