
- Máy Vectơ hỗ trợ (SVM).
- Học bán giám sát.
- SVM bán giám sát.
Máy Vectơ hỗ trợ (SVM).
Một trong những thuật toán phân loại có động lực tốt nhất về mặt lý thuyết và thực tế hiệu quả nhất trong học máy.
Được thúc đẩy trực tiếp bởi Margins và Kernels!
Lề hình học
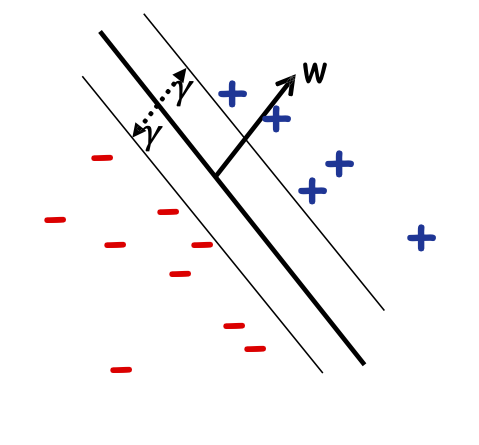
Bộ tách tuyến tính đồng nhất WLOG [w0 = 0].
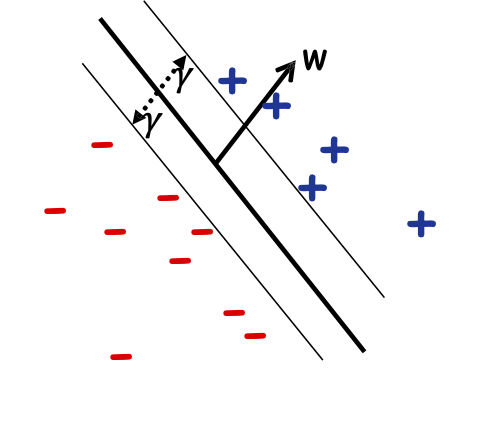
Định nghĩa: Lề của mẫu 𝑥 w.r.t. một sep. tuyến tính 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0.
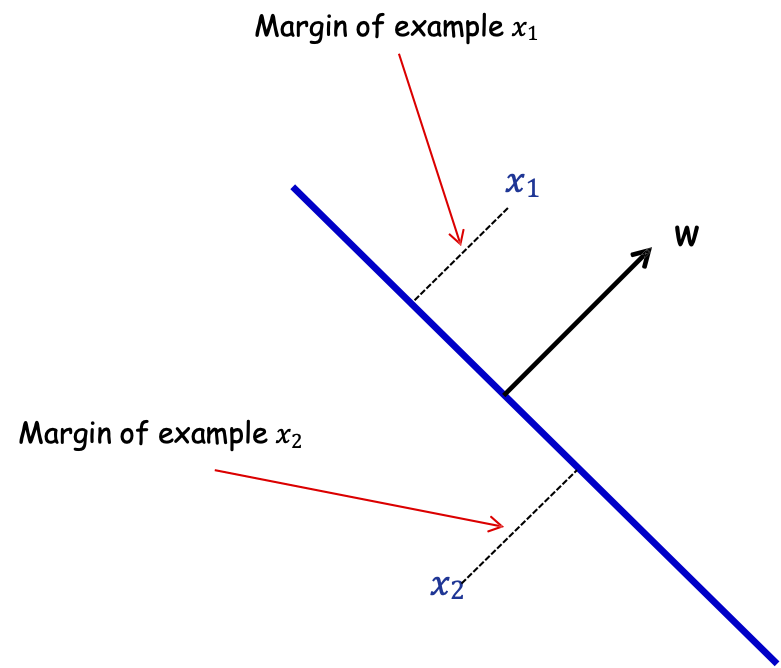
Lề của mẫu 𝑥1
Lề của mẫu 𝑥2
Nếu ||𝑤|| = 1, lề của x w.r.t. w là |𝑥 ⋅ 𝑤|.
Lề hình học
Định nghĩa: Lề của mẫu 𝑥 w.r.t. một sep. tuyến tính 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0.
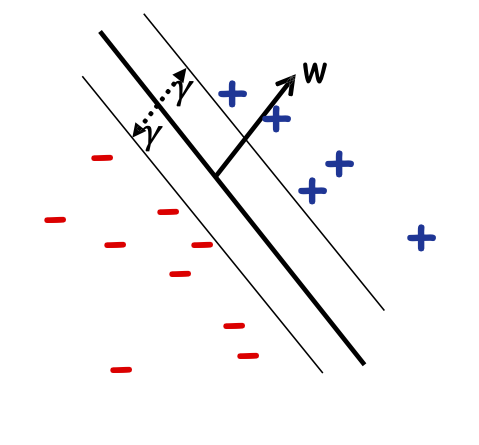
Định nghĩa: Lề 𝛾𝑤 của một tập mẫu 𝑆 wrt một dấu phân cách tuyến tính 𝑤 là lề nhỏ nhất trên các điểm 𝑥 ∈ 𝑆.
Định nghĩa: Lề 𝛾 của một tập hợp các mẫu 𝑆 là 𝛾𝑤 lớn nhất trên tất cả các dấu phân cách tuyến tính 𝑤.
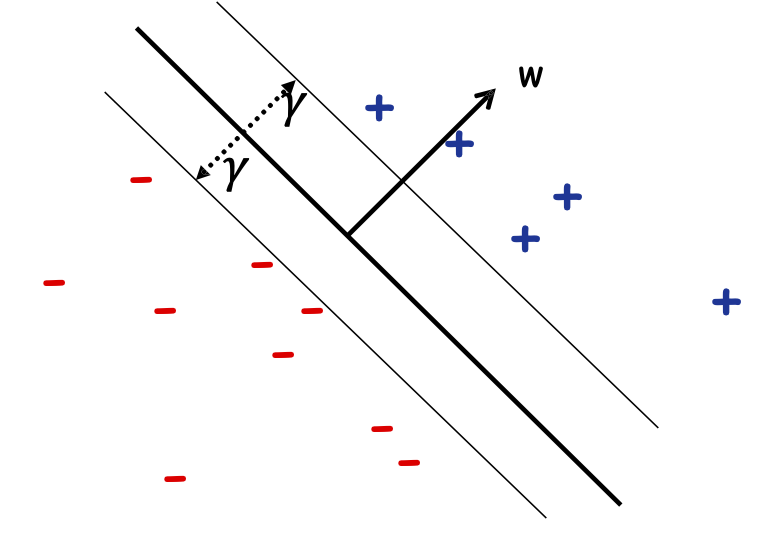
Chủ đề quan trọng lề trong ML
Cả độ phức tạp mẫu và hàm ý thuật toán.
Độ phức tạp của giới hạn Mẫu/Sai lầm:
- Nếu lề lớn, # lỗi Peceptron mắc phải là nhỏ (không phụ thuộc vào dim của không gian)!
- Nếu lề lớn 𝛾 và nếu alg. tạo ra một bộ phân loại lề lớn, thì lượng dữ liệu cần thiết chỉ phụ thuộc vào R/𝛾 [Bartlett & Shawe-Taylor ’99].
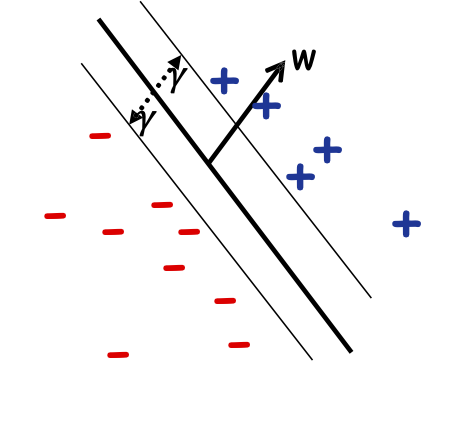
Ý nghĩa thuật toán
 Đề xuất tìm kiếm một bộ phân loại lề lớn … SVM
Đề xuất tìm kiếm một bộ phân loại lề lớn … SVMMáy vectơ hỗ trợ (SVM)
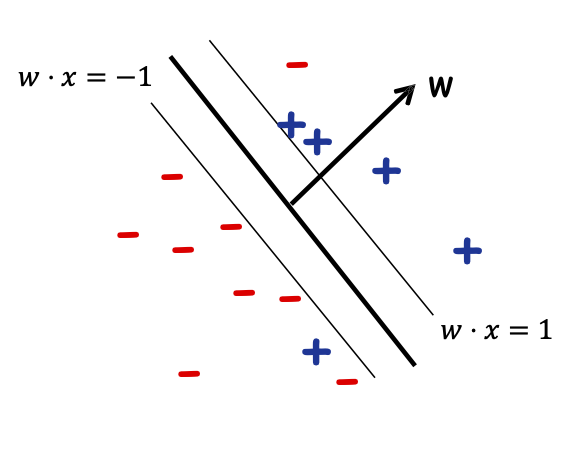
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
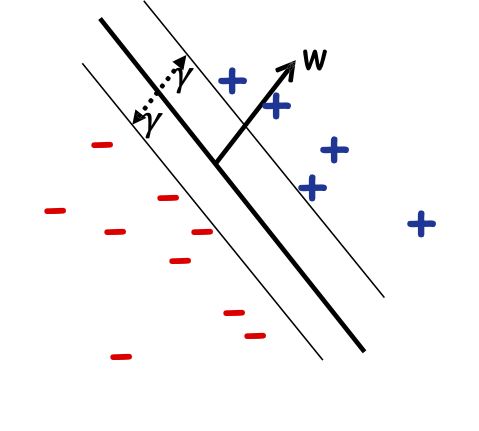
Đầu tiên, giả sử chúng ta biết cận dưới của lề 𝛾
Đầu vào: 𝛾, S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm: một số w trong đó:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾
Đầu ra: w, dấu tách lề 𝛾 trên S
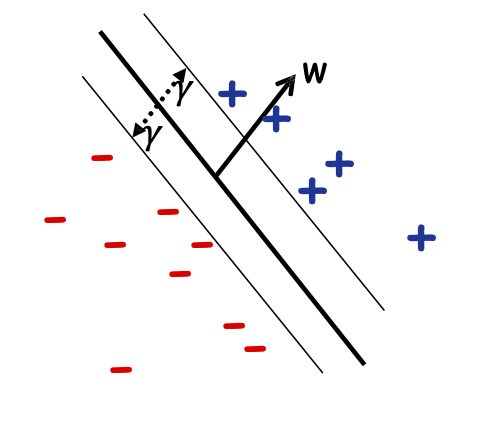
Trường hợp có thể thực hiện được, trong đó dữ liệu có thể phân tách tuyến tính bằng lề 𝛾
Máy vectơ hỗ trợ (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Ví dụ: tìm kiếm 𝛾 tốt nhất có thể
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm: một số w và tối đa 𝛾 trong đó:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾
Đầu ra: dấu tách lề tối đa trên S
Máy vectơ hỗ trợ (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Cực đại hóa 𝛾 theo ràng buộc:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾
Máy vectơ hỗ trợ (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Cực đại hóa 𝛾 dưới ràng buộc:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾

hàm mục tiêu
ràng buộc
Đây là bài toán tối ưu có ràng buộc
- Ví dụ nổi tiếng về tối ưu hóa có ràng buộc: lập trình tuyến tính, trong đó hàm mục tiêu là tuyến tính, các ràng buộc là (bất) đẳng thức tuyến tính
Support Vector Machines (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Dữ liệu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Cực đại hóa 𝛾 theo ràng buộc:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾

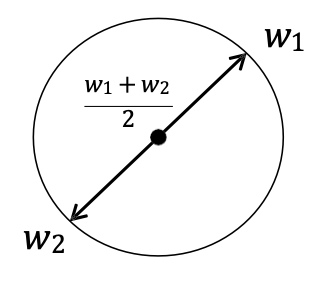
Ràng buộc này là phi tuyến.
Thực chất là không lồi
Máy vectơ hỗ trợ (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tối đa hóa 𝛾 dưới ràng buộc:
- ||w|| 2 = 1
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 𝛾
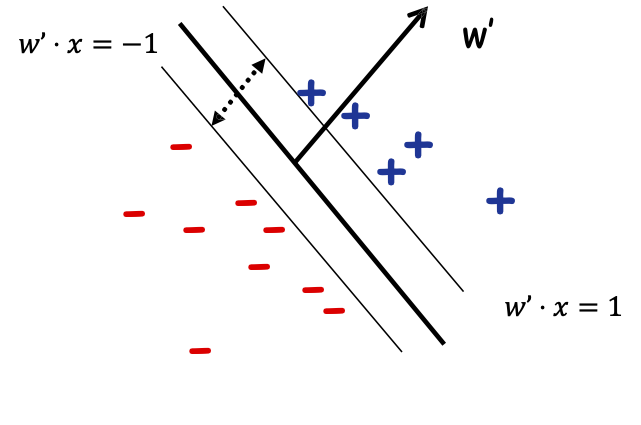
𝑤’ = 𝑤/𝛾 thì max 𝛾 tương đương. để giảm thiểu ||𝑤’||2 (vì ||𝑤’||2 = 1/𝛾2).
Vì vậy, chia cả hai vế cho 𝛾 và viết dưới dạng w’ ta được:
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Cực tiểu hóa ||𝑤′|| 2 theo ràng buộc:
- Với mọi i, 𝑦𝑖𝑤′ ⋅ 𝑥𝑖 ≥ 1
Máy vectơ hỗ trợ (SVM)
Tối ưu hóa trực tiếp cho dấu tách lề tối đa: SVM
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
argminw ||𝑤|| 2 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1
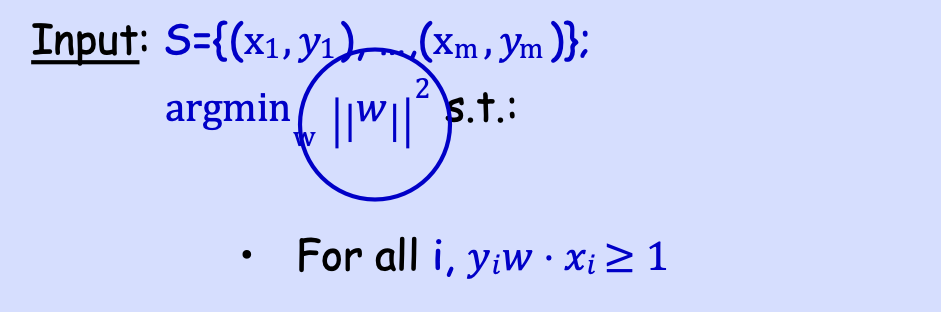
Đây là bài toán tối ưu có ràng buộc
- Mục tiêu là lồi (bậc hai)
- Tất cả các ràng buộc là tuyến tính
- Có thể giải quyết hiệu quả (trong thời gian đa thức) bằng cách sử dụng phần mềm quy hoạch toàn phương tiêu chuẩn (QP)
Máy vectơ hỗ trợ (SVM)
Câu hỏi: nếu dữ liệu không thể phân tách tuyến tính một cách hoàn hảo thì sao?
Vấn đề 1: hiện có hai mục tiêu
- tối đa hóa lề
- giảm thiểu # phân loại sai.
Trả lời 1: Hãy tối ưu hóa tổng của chúng: giảm thiểu ||𝑤|| 2 + 𝐶(# phân loại sai)
trong đó 𝐶 là một số hằng số đánh đổi.
Vấn đề 2: Đây là vấn đề khó tính toán (NP-hard).
[ngay cả khi không quan tâm đến lề và giảm thiểu # sai lầm]
NP-hard [Guruswami-Raghavendra’06]
Máy vectơ hỗ trợ (SVM)
Câu hỏi: nếu dữ liệu không thể phân tách tuyến tính một cách hoàn hảo thì sao?
Thay “#sai lầm” bằng cận trên gọi là “hàm mất bản lề”
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Cực tiểu hóa ||𝑤′|| 2 với điều kiện:
- Với mọi i, 𝑦𝑖𝑤′ ⋅ 𝑥𝑖 ≥ 1
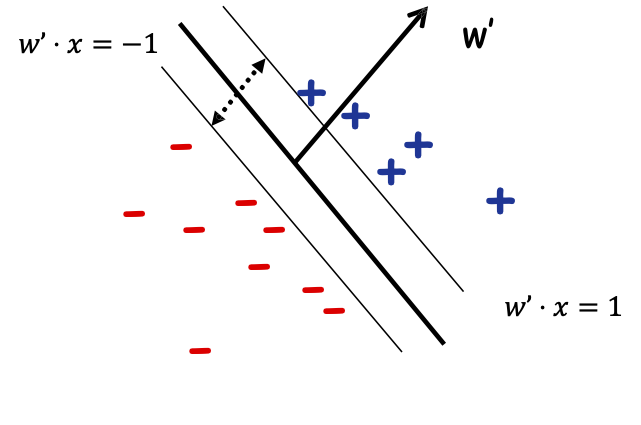
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm argminw,𝜉1,…,𝜉𝑚 ||𝑤|| 2 + 𝐶 ∑𝑖 𝜉𝑖 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
𝜉𝑖 là “biến bù”
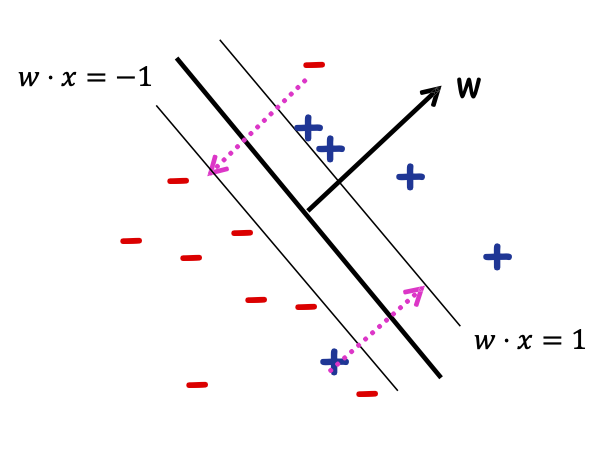
Máy vectơ hỗ trợ (SVM)
Câu hỏi: nếu dữ liệu không thể phân tách tuyến tính một cách hoàn hảo thì sao?
Thay “#sai lầm” bằng cận trên gọi là “hàm mất bản lề”
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm argminw,𝜉1,…,𝜉𝑚 ||𝑤|| 2 + 𝐶 ∑𝑖 𝜉𝑖 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
𝜉𝑖 là “biến bù”
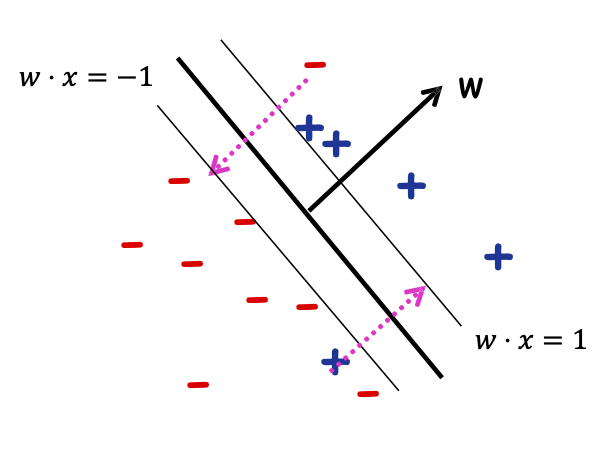
C kiểm soát trọng số tương đối giữa hai mục tiêu là làm cho ||𝑤|| 2 nhỏ (lề lớn) và đảm bảo rằng hầu hết các mẫu đều có biên hàm ≥ 1.
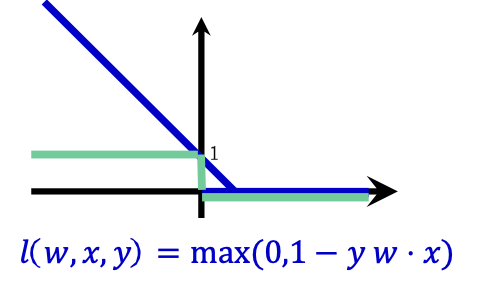
Support Vector Machines (SVM)
Câu hỏi: nếu dữ liệu không thể phân tách tuyến tính một cách hoàn hảo thì sao?
Thay “# lỗi” bằng cận trên gọi là “hàm mất bản lề”
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm argminw,𝜉1,…,𝜉𝑚 ||𝑤|| 2 + 𝐶 ∑𝑖 𝜉𝑖 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
Thay số lỗi bằng hàm mất bản lề
||𝑤|| 2 + 𝐶(# phân loại sai)
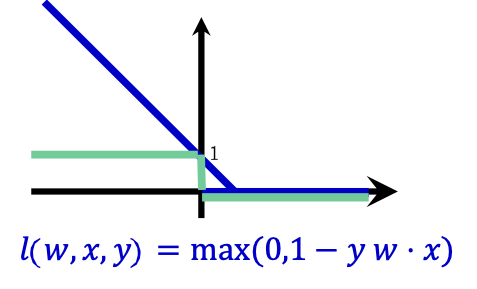
Máy vectơ hỗ trợ (SVM)
Câu hỏi: nếu dữ liệu không thể phân tách tuyến tính hoàn toàn thì sao?
Thay “# lỗi” bằng cận trên gọi là “hàm mất bản lề”
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm argminw,𝜉1,…,𝜉𝑚 ||𝑤|| 2 + 𝐶 ∑𝑖 𝜉𝑖 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
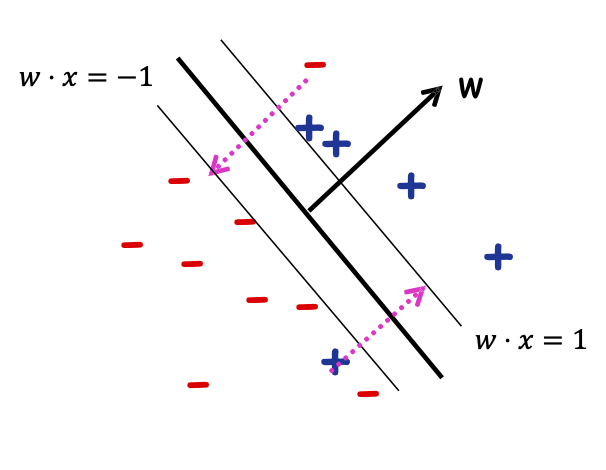
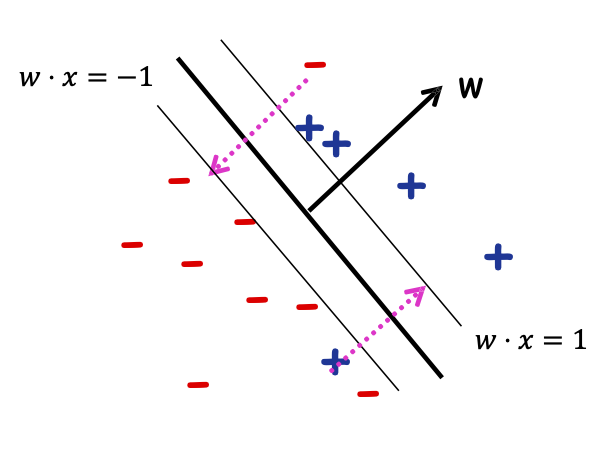
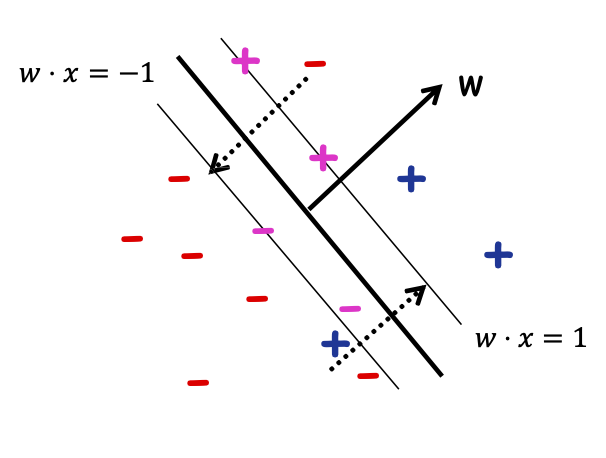
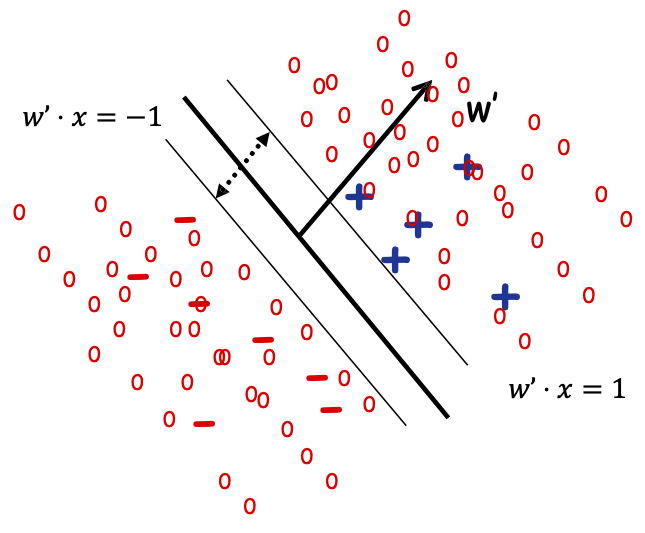
Tổng số lượng phải di chuyển các điểm để đưa chúng về đúng phía của các đường 𝑤 ⋅ 𝑥 = +1/−1, trong đó khoảng cách giữa các đường 𝑤 ⋅ 𝑥 = 0 và 𝑤 ⋅ 𝑥 = 1 được tính là “1 đơn vị”.
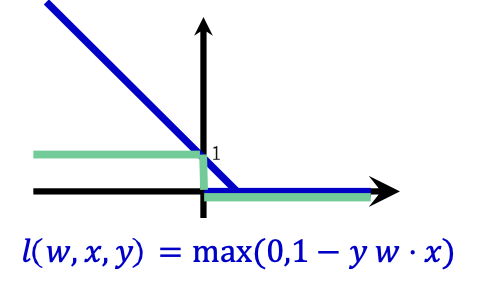
Điều gì xảy ra nếu dữ liệu không thể phân tách tuyến tính?

Không có dấu tách tuyến tính tốt trong biểu diễn pixel
Triết lý SVM: “Sử dụng hàm nhân”
Máy vectơ hỗ trợ (SVM)
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)};
Tìm argminw,𝜉1,…,𝜉𝑚 ||𝑤|| 2 + 𝐶 ∑𝑖 𝜉𝑖 s.t.:
- Với mọi i, 𝑦𝑖𝑤 ⋅ 𝑥𝑖 ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
Dạng nguyên hàm
Tương đương với:
Đầu vào: S={(x1, y1), …,(xm, ym)};
Tìm argminα 1⁄2 ∑i∑j yiyj αiαjxi ⋅ xj − ∑i αi s.t.:
- Với mọi i, 0 ≤ αi ≤ Ci
∑i yiαi = 0
Lagrangian Dual
SVM (Lagrangian Dual)
Đầu vào: S={(x1, y1), …,(xm, ym)};
Tìm argminα 1⁄2 ∑i∑j yiyj αiαjxi ⋅ xj − ∑i αi s.t.:
- Với mọi i, 0 ≤ αi ≤ Ci
∑i yiαi = 0
- Bộ phân loại cuối cùng là: w = ∑i αiyixi
- Các điểm xi mà αi ≠ 0 được gọi là “vectơ hỗ trợ”
Kernelizing Dual SVM
Dữ liệu vào: S={(x1, y1), …,(xm, ym)};
Tìm argminα 1⁄2 ∑i∑j yiyj αiαjxi ⋅ xj − ∑i αi s.t.:
- Với mọi i, 0 ≤ αi ≤ Ci
∑i yiαi = 0
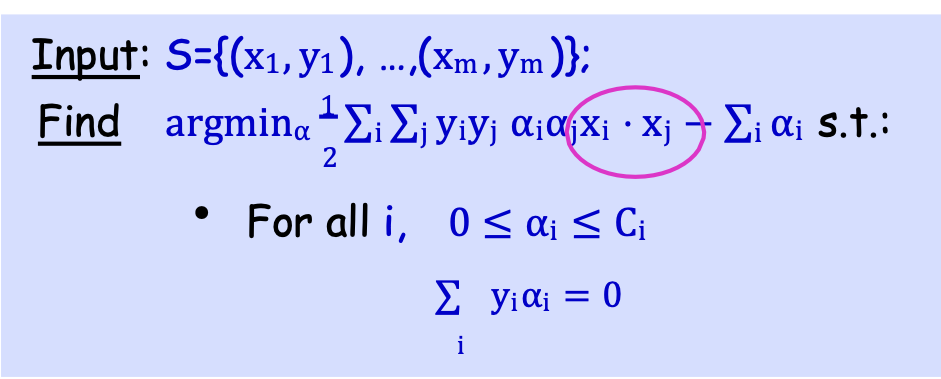
Thay xi ⋅ xj bằng K(xi, xj).
- Bộ phân loại cuối cùng là: w = ∑i αiyixi
- Các điểm xi mà αi ≠ 0 được gọi là “vectơ hỗ trợ”
- Với kernel, phân loại x bằng cách sử dụng ∑i αiyiK(x, xi)
Máy Vectơ hỗ trợ (SVM).
Một trong những thuật toán phân loại có động lực tốt nhất về mặt lý thuyết và thực tế hiệu quả nhất trong học máy.
Được thúc đẩy trực tiếp bởi Margins và Kernels!
Những điều bạn nên biết
- Tầm quan trọng của lề trong học máy.
- Dạng nguyên sơ của bài toán tối ưu SVM
- Dạng đối ngẫu của bài toán tối ưu SVM.
- Nhân hóa SVM.
- Nghĩ xem nó liên quan như thế nào đến Hồi quy Logistic Chính quy.
Học máy được giám sát (một phần) hiện đại
- Sử dụng dữ liệu chưa được gắn nhãn và tương tác để học
Mô hình cổ điển Ngày nay không đủ
Các ứng dụng hiện đại: số lượng lớn dữ liệu thô.
Chỉ một phần rất nhỏ có thể được chú thích bởi các chuyên gia con người.
Trình tự protein

Hàng tỷ trang web

Hình ảnh
Học bán giám sát
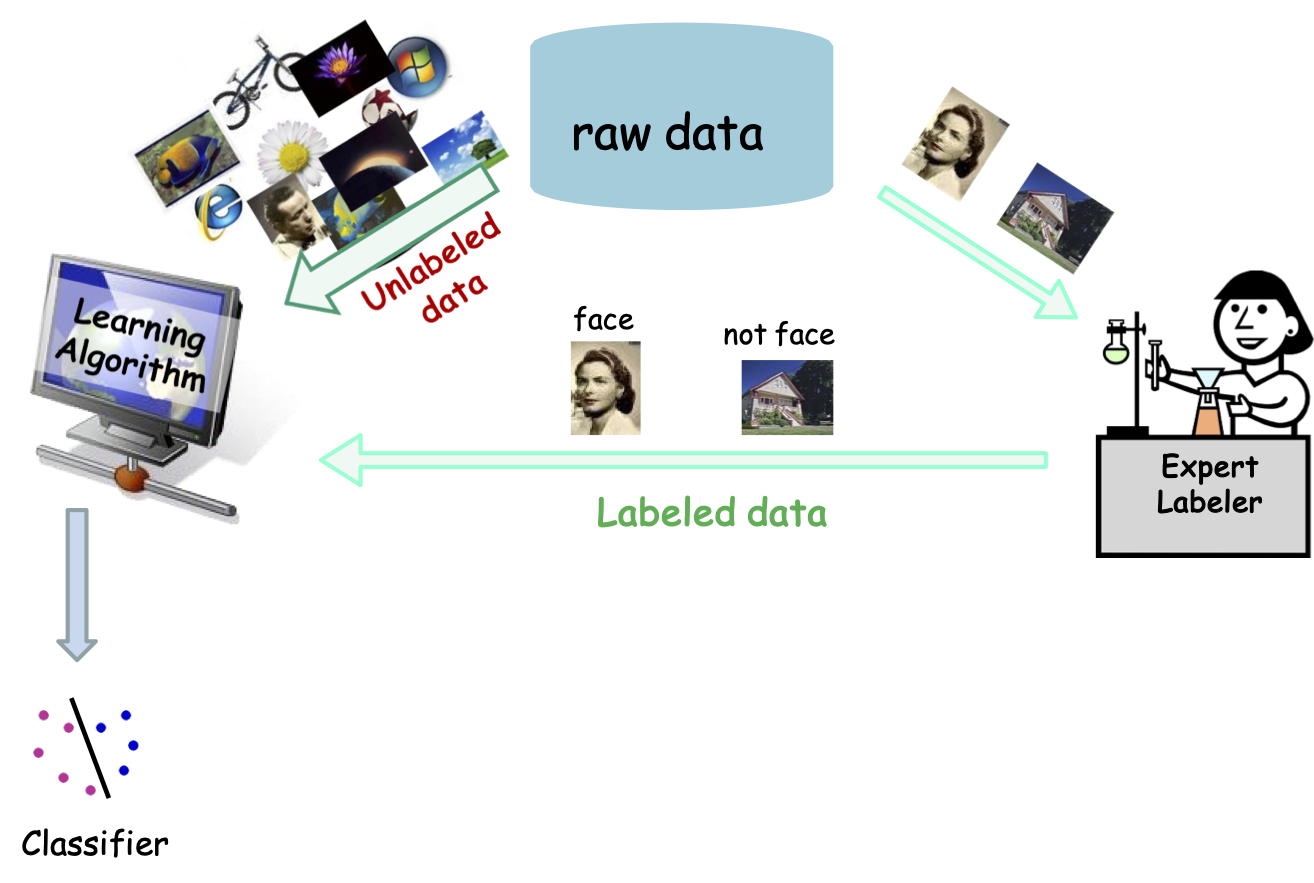
Chuyên gia Dán nhãn
Dữ liệu thô
Dữ liệu được gắn nhãn
Bộ phân loại
Học tập tích cực
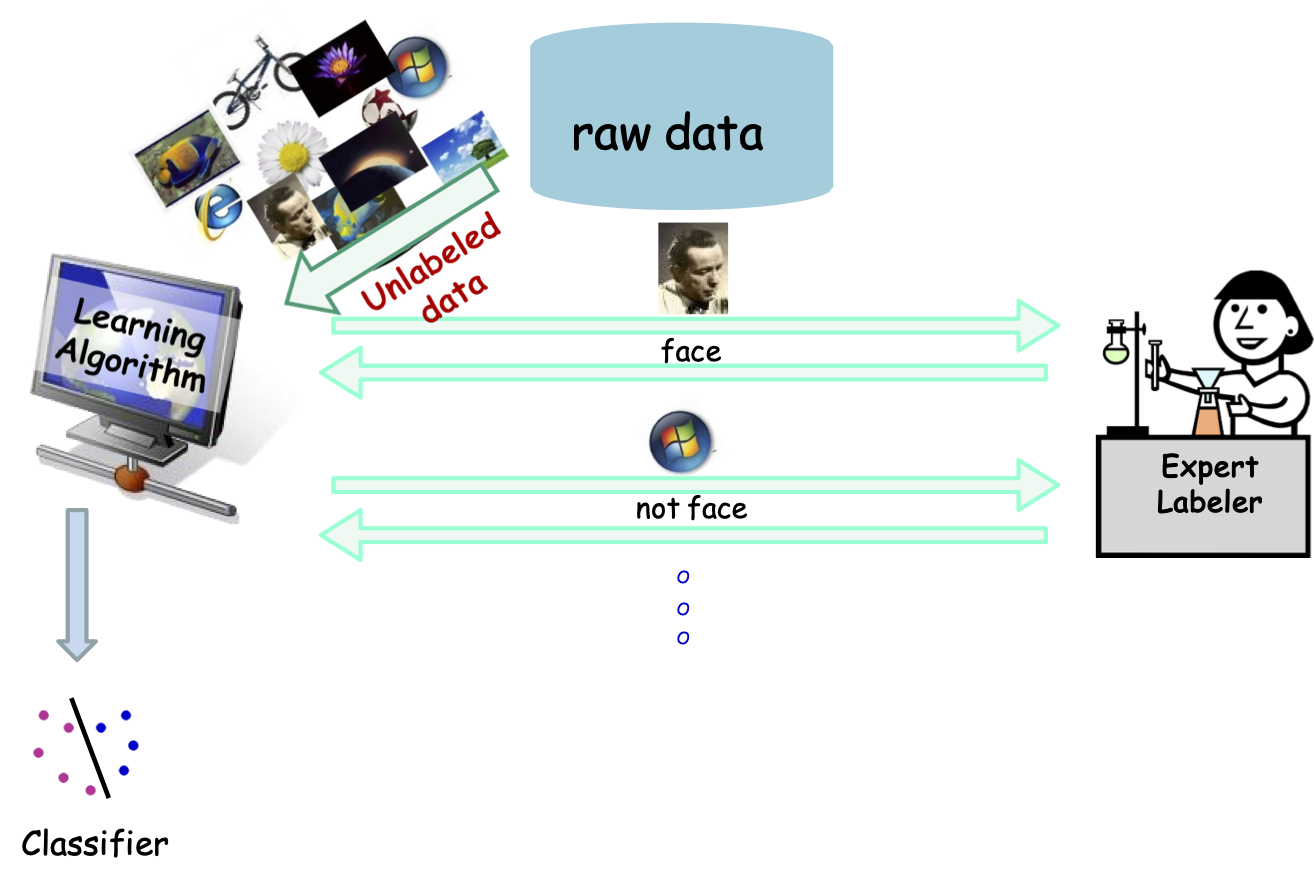
chuyên gia dán nhãn
Dữ liệu thô
Bộ phân loại
Học bán giám sát
Mô hình nổi bật trong 15 năm qua trong Học máy.
- Hầu hết các ứng dụng có nhiều dữ liệu không được gắn nhãn, nhưng dữ liệu được gắn nhãn rất hiếm hoặc đắt tiền:
- Phân loại trang web, tài liệu
- Thị giác máy tính
- Sinh học tính toán,
- ….
Học bán giám sát
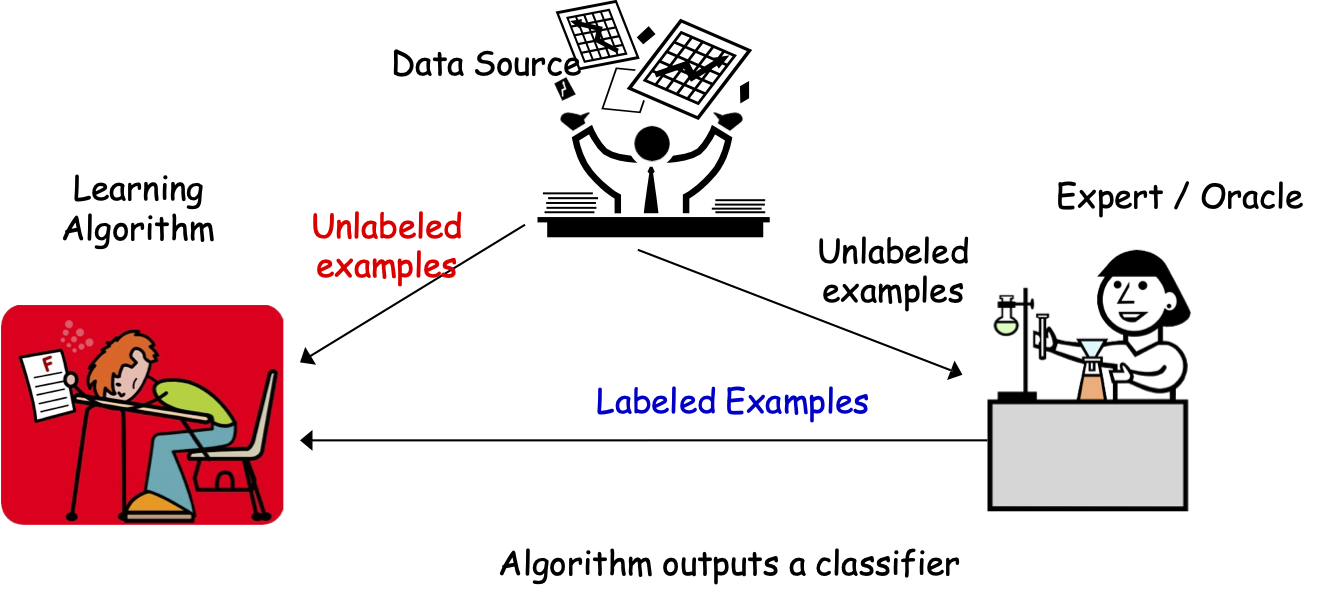
Thuật toán học tập
Chuyên gia / Oracle
Nguồn dữ liệu
Các mẫu không được gắn nhãn
Thuật toán đưa ra một bộ phân loại
Các mẫu không được gắn nhãn
Các mẫu được gắn nhãn
Sl={(x1, y1), …,(xml , yml)}
xi rút ra i.i.d từ D, yi = c∗ (xi)
Su={x1, …,xmu} i.i.d được rút ra từ D
Mục tiêu: h có lỗi nhỏ hơn D.
errD (h) = Prx~ D (h(x) ≠ c∗(x))
Học bán giám sát:
không truy vấn. Chỉ cần có nhiều dữ liệu bổ sung chưa được gắn nhãn.
Một chút bối rối vì không rõ dữ liệu chưa được gắn nhãn có thể làm gì cho bạn….

Dữ liệu chưa được gán nhãn hữu ích nếu chúng ta có niềm tin không chỉ về hình thức của mục tiêu, mà còn về mối quan hệ của nó với phân phối cơ bản.
Kết hợp dữ liệu được gắn nhãn và không được gắn nhãn
- Một số phương pháp đã được phát triển để cố gắng sử dụng dữ liệu không được gắn nhãn để cải thiện hiệu suất, ví dụ:
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]
Kiểm tra thời gian trao thưởng tại ICML!
Hội thảo [ICML ’03, ICML’ 05, …]
Sách:
- Học bán giám sát, MIT 2006 O. Chapelle, B. Scholkopf và A. Zien (eds)
- Giới thiệu về học bán giám sát, Morgan & Claypool, 2009 Zhu & Goldberg
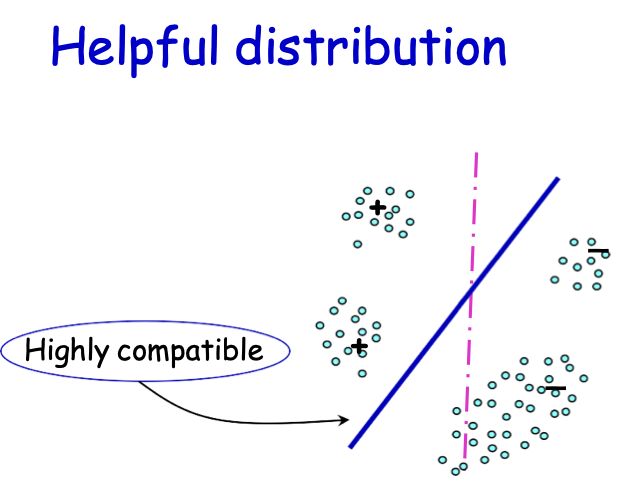
Ví dụ về giả định “điển hình”: Lề
- Dải phân cách đi qua các vùng có mật độ thấp của không gian/lề lớn.
– giả sử chúng ta đang tìm kiếm dấu phân cách tuyến tính
– niềm tin: nên tồn tại một dấu phân cách lớn
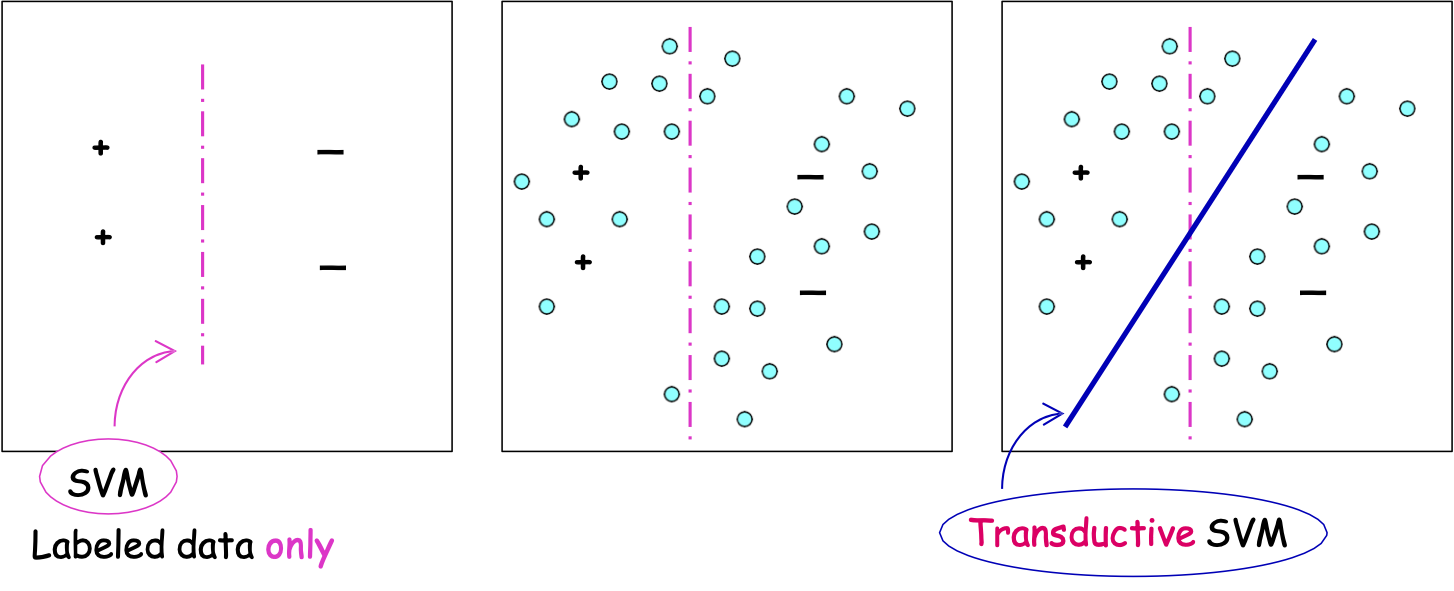
Chỉ dữ liệu được dán nhãn
SVM truyền dẫn
Máy Vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho dấu phân cách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn. [Joachims ‘99]
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 s.t.:
- yi w ⋅ xi ≥ 1, với mọi i ∈ {1, … ,ml}
- y^u w ⋅ xu ≥ 1, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
Tìm nhãn của mẫu không nhãn và 𝑤 s.t. 𝑤 phân tách cả mẫu có nhãn và không nhãn dữ liệu với lề tối đa.
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho dấu phân cách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn. [Joachims ’99]
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 + 𝐶 ∑𝑖 𝜉𝑖 + 𝐶 ∑𝑢 𝜉^𝑢
- yi w ⋅ xi ≥ 1-𝜉𝑖, với mọi i ∈ {1, … ,ml}
- y^i w ⋅ xu ≥ 1 − 𝜉⌃𝑢, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
Tìm nhãn của mẫu không nhãn và 𝑤 s.t. 𝑤 phân tách cả mẫu có nhãn và không nhãn dữ liệu với lề tối đa.
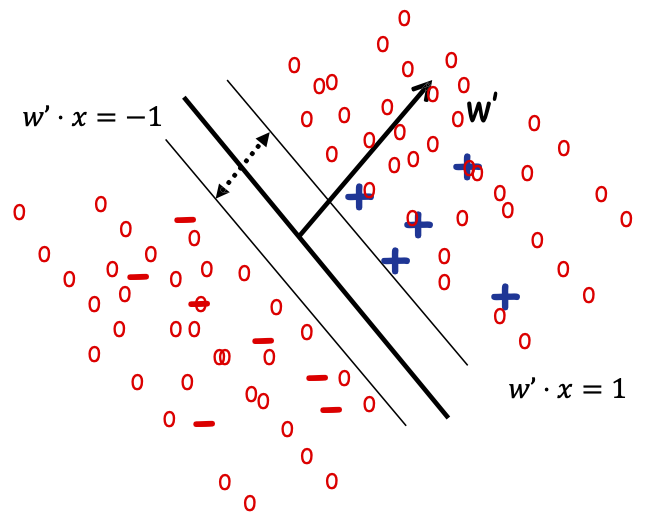
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho bộ phân tách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn.
Đầu vào: Sl={(x1, y1), …,(xml , yml)}
Su={x1, …,xmu}
argminw ||w|| 2 + 𝐶 ∑𝑖 𝜉𝑖 + 𝐶 ∑𝑢 𝜉^𝑢
- yi w ⋅ xi ≥ 1-𝜉𝑖, với mọi i ∈ {1, … ,ml}
- y^i w ⋅ xu ≥ 1 − 𝜉⌃𝑢, với mọi u ∈ {1,… ,mu}
- y^u ∈ {−1, 1} với mọi u ∈ {1,… ,mu}
NP-hard…. .Chỉ lồi sau khi bạn đoán các nhãn… có thể đoán quá nhiều…
Máy vectơ hỗ trợ truyền dẫn
Tối ưu hóa cho bộ phân tách với dữ liệu được gắn nhãn và không được gắn nhãn có lề lớn.
Ý tưởng cấp cao Heuristic (Joachims):
- Đầu tiên tối đa hóa lề trên các điểm được gắn nhãn
- Sử dụng điều này để gán nhãn ban đầu cho các điểm chưa được gắn nhãn dựa trên dấu tách này.
- Hãy thử lật nhãn của các điểm chưa được gắn nhãn để xem liệu làm như vậy có thể tăng lề hay không
Tiếp tục cho đến khi không còn cải tiến nào nữa. Tìm một giải pháp tối ưu cục bộ.
Thử nghiệm [Joachims99]
![HÌNH 18.27. Thử nghiệm [Joachims99].](https://cdn.jsdelivr.net/gh/vtgcdn/iml18.viettechgroup.com@latest/18_svm-sslfig27.png)
Máy vectơ hỗ trợ truyền dẫn
Phân phối hữu ích
Phân phối không hữu ích
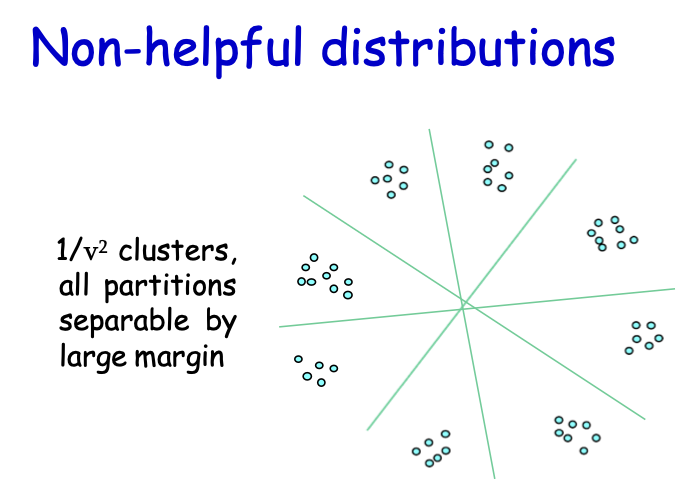

Tương thích cao
1⁄𝛾2 cụm, tất cả các phân vùng có thể phân tách bằng lề lớn
Học bán giám sát
Mô hình nổi bật trong 15 năm qua về Học máy.

Dữ liệu chưa được gắn nhãn hữu ích nếu chúng ta có niềm tin không chỉ về hình thức của mục tiêu mà còn về mối quan hệ của nó với phân phối cơ bản.
Các kỹ thuật nổi bật
– SVM truyền dẫn [Joachims ’99]
– Đồng đào tạo [Blum & Mitchell ’98]
– Các phương pháp dựa trên đồ thị [B&C01], [ZGL03]