
Tóm tắt nhanh về Perceptron và Margins
Mô hình Học tập Trực tuyến
- Mẫu đến tuần tự.
- Chúng ta cần đưa ra dự đoán.
Sau đó quan sát kết quả.
Với i=1, 2, …, :

Mô hình ràng buộc sai lầm
- Phân tích khôn ngoan, không đưa ra giả định phân phối.
- Mục tiêu: Giảm thiểu số lần mắc lỗi.
Thuật toán Perceptron trong mô hình trực tuyến
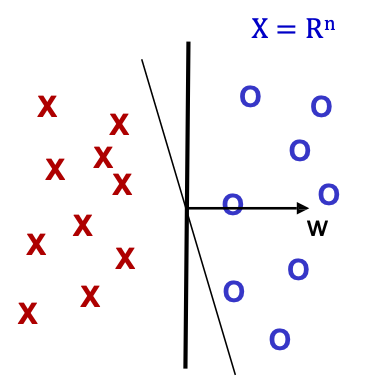
Bộ tách tuyến tính đồng nhất WLOG [w0 = 0].
- Đặt t=1, bắt đầu với véc tơ toàn 0 𝑤1.
- Cho mẫu 𝑥, dự đoán + iff 𝑤𝑡 ⋅ 𝑥 ≥ 0
- Nếu sai, cập nhật như sau:
- Sai về dương, 𝑤𝑡+1 ← 𝑤𝑡 + 𝑥
- Sai về âm, 𝑤𝑡+1 ← 𝑤𝑡 − 𝑥
Lưu ý 1: wt là tổng trọng số của các mẫu được phân loại không chính xác 𝑤𝑡 = 𝑎𝑖1𝑥𝑖1 +⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘
Vì vậy, 𝑤𝑡 ⋅ 𝑥 = 𝑎𝑖1𝑥𝑖1 ⋅ 𝑥 + ⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘 ⋅ 𝑥
Lưu ý 2: Số lần mắc lỗi chỉ phụ thuộc vào lề hình học của các mẫu đã thấy.
- Bất kể dãy dài bao nhiêu hoặc chiều n cao như thế nào!
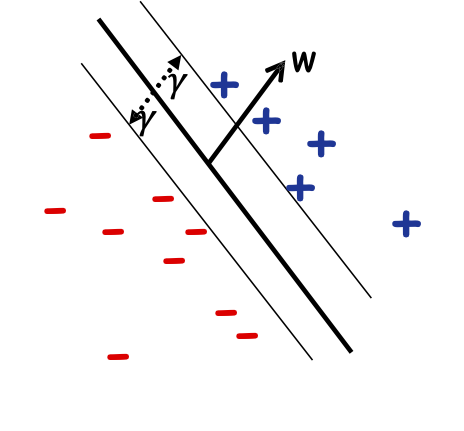
Lề hình học
Định nghĩa: Lề của mẫu 𝑥 w.r.t. một sep. tuyến tính 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0.
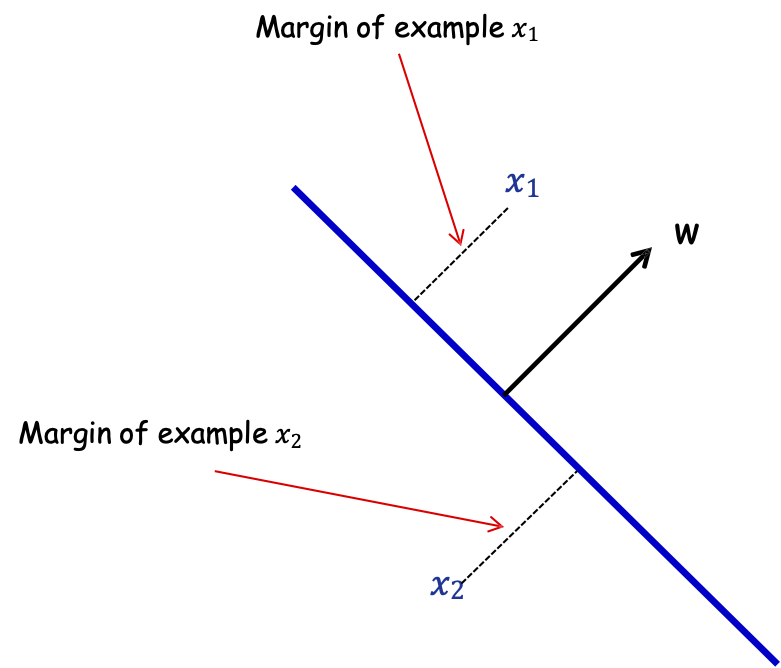
Lề của mẫu 𝑥1
Lề của mẫu 𝑥2
Nếu ||𝑤|| = 1, lề của x w.r.t. w là |𝑥 ⋅ 𝑤|.
Lề hình học
Định nghĩa: Lề của mẫu 𝑥 w.r.t. một sep. tuyến tính 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0.
Định nghĩa: Lề 𝛾𝑤 của một tập mẫu 𝑆 wrt một dấu phân cách tuyến tính 𝑤 là lề nhỏ nhất trên các điểm 𝑥 ∈ 𝑆.
Định nghĩa: Lề 𝛾 của một tập hợp các mẫu 𝑆 là 𝛾𝑤 lớn nhất trên tất cả các dấu phân cách tuyến tính 𝑤.
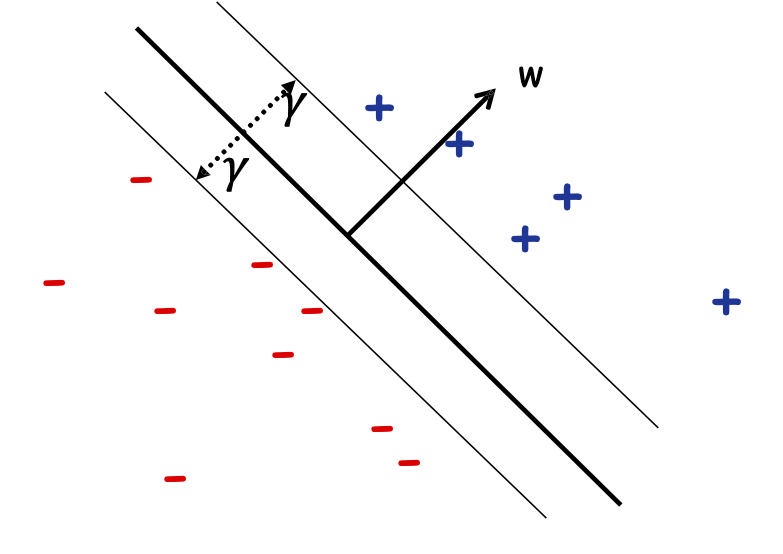
Perceptron: Giới hạn sai lầm
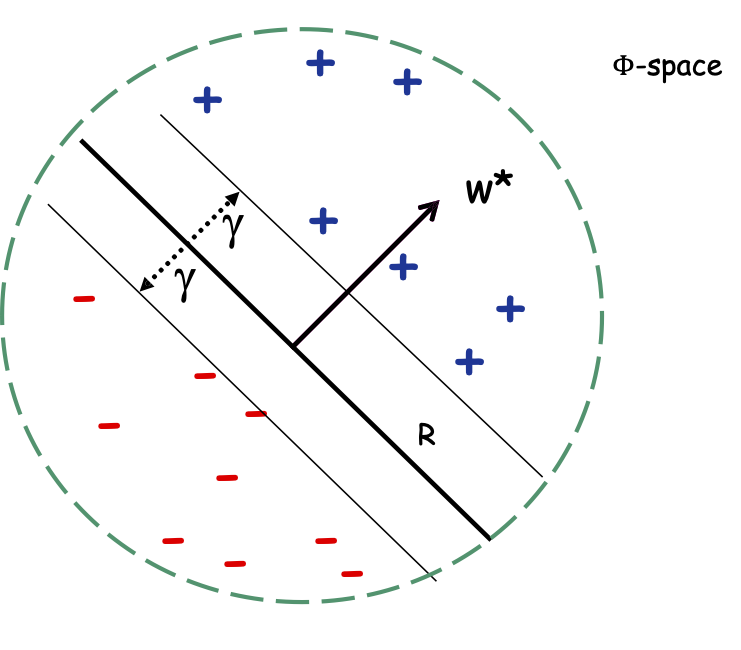
Định lý: Nếu dữ liệu có thể phân tách tuyến tính theo lề 𝛾 và chỉ bên trong một quả cầu có bán kính 𝑅, thì Perceptron mắc ≤ (𝑅/𝛾)2 sai lầm.
- Cho dù dãy n có chiều dài bao nhiêu đi chăng nữa!
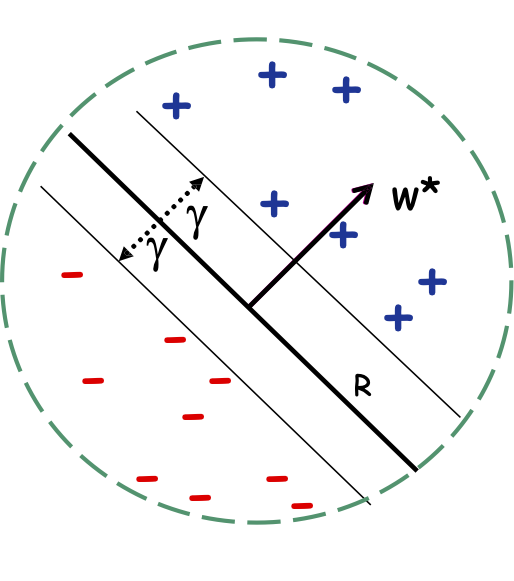
Margin: khoảng trống khả dụng cho một giải pháp.
(Lề chuẩn hóa: nhân tất cả các điểm với 100 hoặc chia tất cả các điểm cho 100, không làm thay đổi số lượng lỗi; thuật toán là bất biến đối với tỷ lệ.)
Phần mở rộng của Perceptron
- Có thể sử dụng nó để tìm một dấu phân cách nhất quán với một tập S đã cho có thể phân tách tuyến tính theo lề 𝛾 (bằng cách quay vòng dữ liệu).
- Cũng có thể chuyển đổi bảo đảm ràng buộc sai lầm thành bảo đảm phân phối (đối với trường hợp các 𝑥𝑖 đến từ một phân phối cố định).
- Có thể thích ứng với trường hợp không có dải phân cách hoàn hảo miễn là cái gọi là suy hao bản lề (nghĩa là tổng khoảng cách cần thiết để di chuyển các điểm để phân loại chúng theo lề lớn một cách chính xác) là nhỏ.
- Có thể được nhân hóa để xử lý các ranh giới quyết định phi tuyến tính!
Định lý: Nếu dữ liệu có thể phân tách tuyến tính theo lề 𝛾 và chỉ vào bên trong một quả cầu có bán kính 𝑅, thì Perceptron mắc ≤ (𝑅/𝛾)2 sai lầm.
Ngụ ý rằng các bộ phân loại lề lớn có độ phức tạp nhỏ hơn!
Độ phức tạp của Sep. tuyến tính lề lớn
- Biết rằng trong Rn chúng ta có thể phá vỡ n+1 điểm bằng các dấu phân cách tuyến tính, nhưng không phải là n+2 điểm (VC-dim của sep tuyến tính là n+1).
- Vì vậy, các bộ phân loại lề lớn có độ phức tạp nhỏ hơn!
- Ý nghĩa tốt đẹp cho môi trường học tập phân bổ thông thường.
- Các bộ phân loại ít phải lo lắng về điều đó sẽ trông tốt đối với mẫu, nhưng lại xấu đối với tất cả….
- Ít bị khớp quá mức!!!!
 Điều gì sẽ xảy ra nếu chúng ta yêu cầu các điểm được phân tách tuyến tính bằng lề 𝛾?
Điều gì sẽ xảy ra nếu chúng ta yêu cầu các điểm được phân tách tuyến tính bằng lề 𝛾?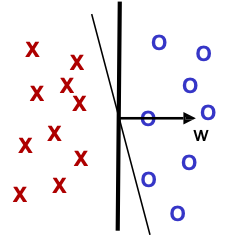
 Có thể có tối đa (𝑅⁄𝛾)2 điểm bên trong quả cầu bán kính R có thể bị phá vỡ ở lề 𝛾 (có nghĩa là mọi cách ghi nhãn đều có thể đạt được bằng dấu phân cách có lề 𝛾).
Có thể có tối đa (𝑅⁄𝛾)2 điểm bên trong quả cầu bán kính R có thể bị phá vỡ ở lề 𝛾 (có nghĩa là mọi cách ghi nhãn đều có thể đạt được bằng dấu phân cách có lề 𝛾).Chủ đề quan trọng lề trong ML.
Cả độ phức tạp mẫu và hàm ý thuật toán.
Độ phức tạp của giới hạn mẫu/lỗi:
- Nếu lề lớn, # lỗi mà Peceptron mắc phải là nhỏ (không phụ thuộc vào dim của không gian)!
- Nếu lề lớn 𝛾 và nếu alg. tạo ra một bộ phân loại lề lớn, thì lượng dữ liệu cần thiết chỉ phụ thuộc vào R/𝛾 [Bartlett & Shawe-Taylor ’99].
- Đề xuất tìm kiếm một bộ phân loại lề lớn…
Ý nghĩa của thuật toán:
- Perceptron, Kernels, SVMs…
Cho đến nay, chúng ta đã nói về lề trong ngữ cảnh của (gần như) bộ dữ liệu có thể phân tách tuyến tính
Điều gì xảy ra nếu không thể phân tách tuyến tính
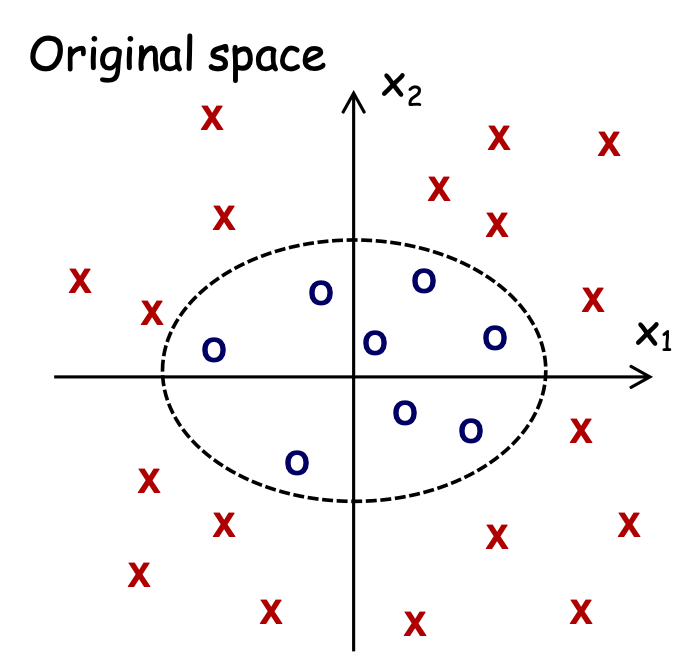
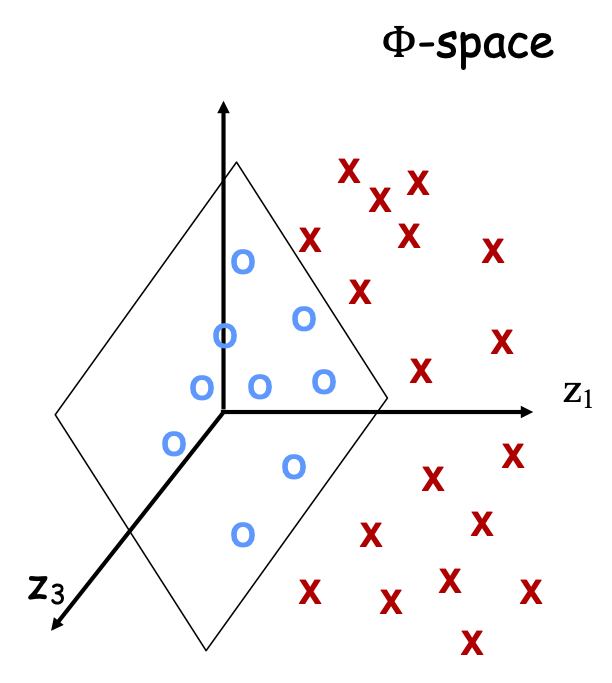
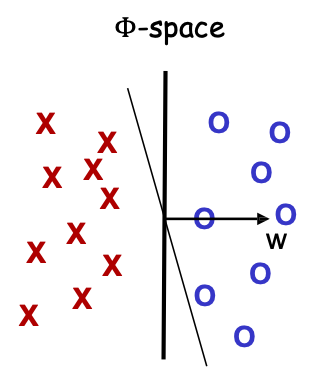
Vấn đề: dữ liệu không thể phân tách tuyến tính trong biểu diễn đối tượng tự nhiên nhất

Không có dấu tách tuyến tính tốt trong biểu diễn pixel
Giải pháp:
- “Tìm hiểu một lớp hàm phức tạp hơn”
- (ví dụ: cây quyết định, mạng thần kinh, tăng tốc).
- “Sử dụng hàm nhân” (một giải pháp gọn gàng thu hút nhiều sự chú ý)
- “Sử dụng mạng sâu”
- “Kết hợp hàm nhân và mạng sâu”
Tổng quan về các phương pháp hàm nhân
Hàm nhân là gì?
Kernel K là một def hợp pháp của tích vô hướng: tức là tồn tại một ánh xạ ẩn Φ s.t. K( ,
,  ) =Φ( )⋅ Φ( )
) =Φ( )⋅ Φ( )
Chẳng hạn, K(x,y) = (x ⋅ y + 1)d
Φ: (không gian n chiều) → nd-không gian thứ nguyên
Tại sao Kernel lại quan trọng?
- Nhiều thuật toán chỉ tương tác với dữ liệu thông qua tích.
- Vì vậy, nếu thay x ⋅ z bằng K(x, z) thì chúng hoạt động hoàn toàn như thể dữ liệu ở trong không gian Φ chiều cao hơn.
- Nếu dữ liệu có thể phân tách tuyến tính bằng lề lớn trong không gian Φ, thì độ phức tạp của mẫu tốt.
[Hoặc các thuộc tính chính quy khác để kiểm soát dung lượng.]
Hàm nhân
Định nghĩa
K(⋅,⋅) là một hàm nhân nếu có thể xem nó như một định nghĩa hợp pháp của tích trong:
- ∃ ϕ: X → RN s.t. K(x, z) = ϕ(x) ⋅ ϕ(z)
- Phạm vi của ϕ được gọi là Không gian Φ.
- N có thể rất lớn.
- Nhưng hãy coi ϕ là hàm ý, không rõ ràng!!!!
Ví dụ
Với n=2, d=2, nhân K(x, z) = (x ⋅ z)d tương ứng với
(𝑥1, 𝑥2) → Φ(𝑥) = (𝑥1 2, 𝑥2 2, √2𝑥1𝑥2)
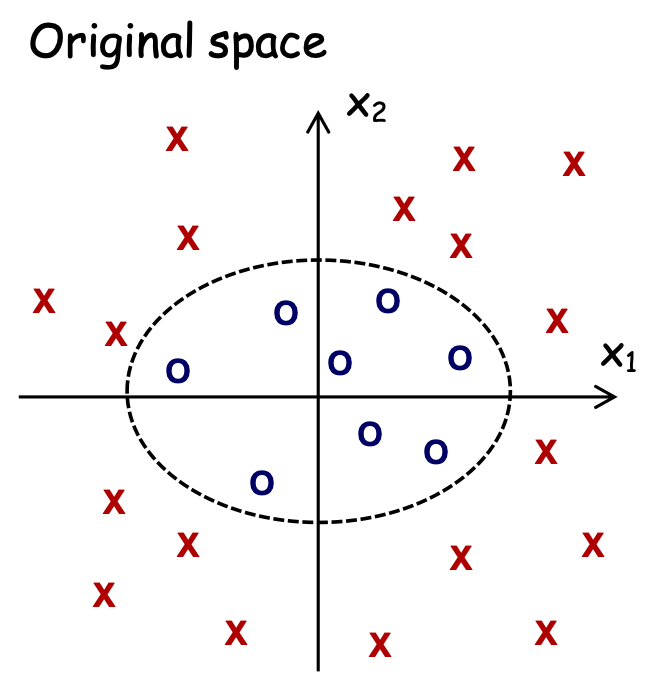
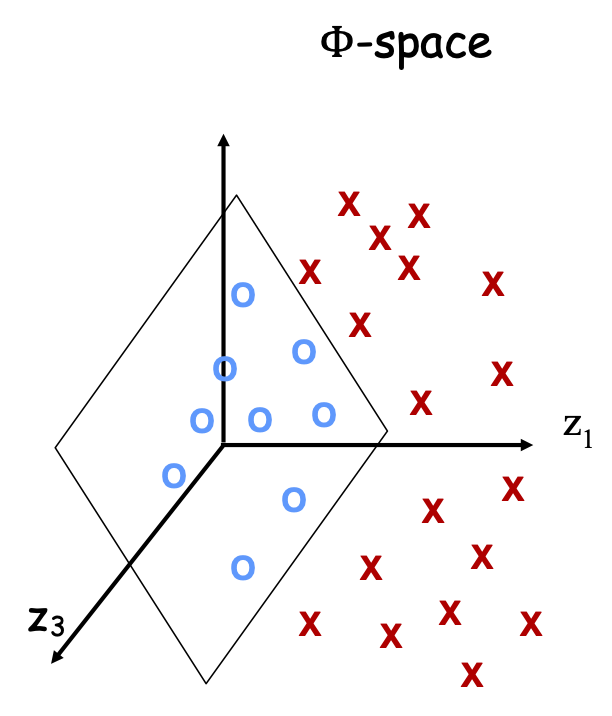
Ví dụ
ϕ:R2 → R3, (x1, x2) → Φ(x) = (x1 2, x2 2, √2x1x2)
ϕ(x) ⋅ ϕ(𝑧) = (x1 2, x2 2, √2x1x2) ⋅ (𝑧1 2, 𝑧2 2, √2𝑧1𝑧2)
= (x1𝑧1 + x2𝑧2) 2 = (x ⋅ 𝑧) 2 = K(x, z)
Hàm nhân
Định nghĩa
K(⋅,⋅) là hàm nhân nếu có thể xem nó như một định nghĩa hợp pháp của tích trong:
- ∃ ϕ: X → RN s.t. K(x, z) = ϕ(x) ⋅ ϕ(z)
- Phạm vi của ϕ được gọi là không gian Φ.
- N có thể rất lớn.
- Nhưng hãy coi ϕ là hàm ý, không rõ ràng!!!!
Ví dụ
Lưu ý: không gian đặc trưng có thể không phải là duy nhất.
ϕ:R2 → R3, (x1, x2) → Φ(x) = (x1 2, x2 2, √2x1x2)
ϕ(x) ⋅ ϕ(𝑧) = (x1 2, x2 2, √2x1x2) ⋅ (𝑧1 2, 𝑧2 2, √2𝑧1𝑧2)
= (x1𝑧1 + x2𝑧2) 2 = (x ⋅ 𝑧) 2 = K(x, z)
ϕ:R2 → R4, (x1, x2) → Φ(x) = (x1 2, x2 2, x1x2, x2x1)
ϕ(x) ⋅ ϕ(𝑧) = (x1 2, x2 2, x1x2, x2x1) ⋅ (z1 2, z2 2, z1z2, z2z1)
= (x ⋅ 𝑧) 2 = K(x, z)
Tránh mở rộng rõ ràng các tính năng
Không gian tính năng có thể phát triển rất lớn và rất nhanh….
Điều quan trọng là phải coi ϕ là ẩn chứ không phải rõ ràng!!!!
- Hàm nhân đa thức bậc 𝑑, 𝑘(𝑥, 𝑧) = (𝑥⊤𝑧) 𝑑 = 𝜙(𝑥) ⋅ 𝜙(𝑧)
– 𝑥1 𝑑 , 𝑥1𝑥2…𝑥𝑑 , 𝑥1 2𝑥2…𝑥𝑑−1
– Tổng số đặc trưng đó là (𝑑 + 𝑛 − 1 𝑑) = (𝑑 + 𝑛 − 1) !⁄ 𝑑! (𝑛 − 1) !
– 𝑑 = 6, 𝑛 = 100, có 1,6 tỷ số hạng
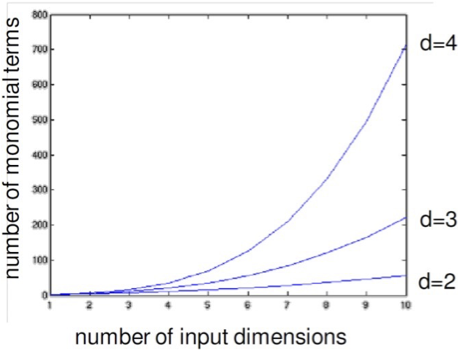
𝑘(𝑥, 𝑧) = (𝑥⊤𝑧) 𝑑 = 𝜙(𝑥) ⋅ 𝜙(𝑧)
𝑂(𝑛) 𝑐𝑜𝑚𝑝𝑢𝑡𝑎𝑡𝑖𝑜𝑛!
Hàm nhân hóa một thuật toán học
- Nếu tất cả các tính toán liên quan đến các thể hiện là về các tích bên trong thì:
- Về mặt khái niệm, hoạt động trong một không gian diml rất cao và hiệu suất của thuật toán chỉ phụ thuộc vào khả năng phân tách tuyến tính trong không gian mở rộng đó.
- Về mặt tính toán, chỉ cần sửa thuật toán bằng cách thay mỗi x ⋅ z bằng K(x, z).
- Ví dụ về các thuật toán có thể nhân:
- phân loại: Perceptron, SVM.
- hồi quy: tuyến tính, hồi quy sườn núi.
- phân cụm: k-means.
Hàm nhân hóa thuật toán Perceptron
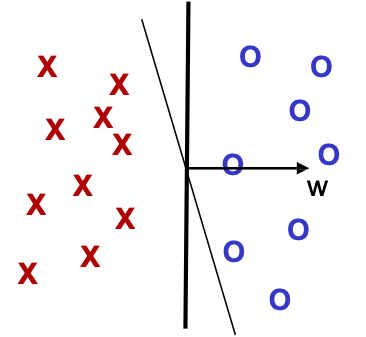
- Đặt t=1, bắt đầu với vectơ 0 𝑤1.
- Cho mẫu 𝑥, dự đoán + iff 𝑤𝑡 ⋅ 𝑥 ≥ 0
- Khi có lỗi, cập nhật như sau:
- Lỗi ở giá trị dương, 𝑤𝑡+1 ← 𝑤𝑡 + 𝑥
- Lỗi ở giá trị âm, 𝑤𝑡+1 ← 𝑤𝑡 − 𝑥
Dễ dàng để hàm nhân vì 𝑤𝑡 tổng trọng số của các mẫu được phân loại không chính xác 𝑤𝑡 = 𝑎𝑖1𝑥𝑖1 +⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘
Thay thế 𝑤𝑡 ⋅ 𝑥 = 𝑎𝑖1𝑥𝑖1 ⋅ 𝑥 + ⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘 ⋅ 𝑥 bằng
𝑎𝑖1 𝐾(𝑥𝑖1 , 𝑥) + ⋯+ 𝑎𝑖𝑘𝐾(𝑥𝑖𝑘 , 𝑥)
Lưu ý: cần lưu trữ tất cả các sai lầm cho đến nay.
Hàm nhân hóa thuật toán Perceptron
- Cho trước 𝑥, dự đoán + iff
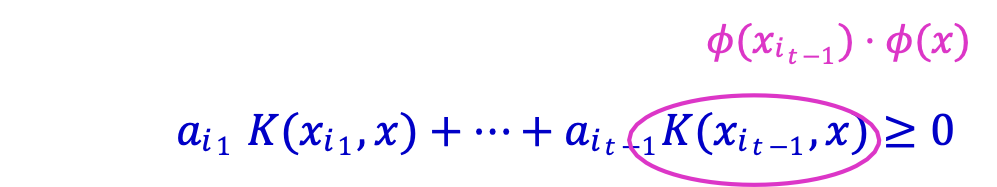
𝑎𝑖1 𝐾(𝑥𝑖1 , 𝑥) + ⋯+ 𝑎𝑖𝑡−1𝐾(𝑥𝑖𝑡−1 , 𝑥) ≥ 0
- Ở lỗi thứ 𝑡, cập nhật như sau:
- Lỗi về dương, đặt 𝑎𝑖𝑡 ← 1; trữ 𝑥𝑖𝑡
- Sai về âm, 𝑎𝑖𝑡 ← −1; Lưu trữ 𝑥𝑖𝑡
Perceptron 𝑤𝑡 = 𝑎𝑖1𝑥𝑖1 +⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘
𝑤𝑡 ⋅ 𝑥 = 𝑎𝑖1𝑥𝑖1 ⋅ 𝑥 + ⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘 ⋅ 𝑥 → 𝑎𝑖1 𝐾(𝑥𝑖1 , 𝑥) + ⋯+ 𝑎𝑖𝑘𝐾(𝑥𝑖𝑘 , 𝑥)
Hành vi/quy tắc dự đoán giống hệt như thể ánh xạ dữ liệu trong không gian 𝜙 và chạy Perceptron ở đó!
Làm điều này ngầm, vì vậy tiết kiệm tính toán!!!!!
Tổng quát hóa tốt nếu lề tốt
- Nếu dữ liệu có thể phân tách tuyến tính theo lề trong không gian 𝜙, thì ràng buộc lỗi nhỏ.
- Nếu lề 𝛾 trong không gian 𝜙 thì Perceptron mắc (𝑅⁄𝛾)2 sai lầm.
Hàm nhân: Thêm ví dụ
- Tuyến tính: K(x, z) = x ⋅ 𝑧
- Đa thức: K(x, 𝑧) = (x ⋅ 𝑧) d hoặc K(x, 𝑧) = (1 + x ⋅ 𝑧) d
- Gaussian: K(x, 𝑧) = exp[ − ||𝑥−𝑧|| 2⁄ 2 𝜎2]
- Nhân Laplace: K(x, 𝑧) = exp[ − ||𝑥−𝑧||⁄ 2 𝜎2]
- Hàm nhân cho dữ liệu phi véc tơ, ví dụ: đo độ tương tự giữa các chuỗi.
Tính chất của hàm nhân
Định lý (Mercer)
K là hàm nhân khi và chỉ khi:
- K đối xứng
- Với mọi tập điểm huấn luyện 𝑥1, 𝑥2, … , 𝑥𝑚 và với mọi 𝑎1, 𝑎2, … , 𝑎𝑚 ∈ 𝑅, ta có:
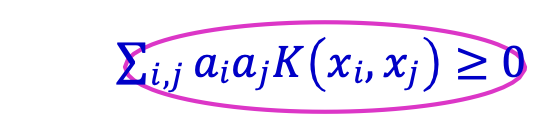
∑𝑖,𝑗 𝑎𝑖𝑎𝑗𝐾(𝑥𝑖, 𝑥𝑗) ≥ 0
𝑎𝑇𝐾𝑎 ≥ 0
Tức là, 𝐾 = (𝐾 (𝑥𝑖 , 𝑥𝑗) )𝑖,𝑗=1,…,𝑛 là nửa xác định dương.
Kernel Methods
- Cung cấp mô-đun tuyệt vời.

- Không cần phải thay đổi thuật toán học cơ bản để phù hợp với một lựa chọn hàm nhân cụ thể.
- Ngoài ra, chúng ta có thể thay thế một thuật toán khác trong khi vẫn duy trì cùng một kernel.
Hàm nhân, Thuộc tính đóng
Dễ dàng tạo hàm nhân mới bằng cách sử dụng các hàm nhân cơ bản!
Dữ kiện: Nếu K1 (⋅,⋅) và K2 (⋅,⋅) là các hàm nhân c1 ≥ 0, 𝑐2 ≥ 0,
thì K(x, z) = c1K1(x, z) + c2K2(x, z) là nhân.
Ý tưởng chính: nối các khoảng cách 𝜙.
ϕ(x) = (√c1 ϕ1(x) , √c2 ϕ2(x))
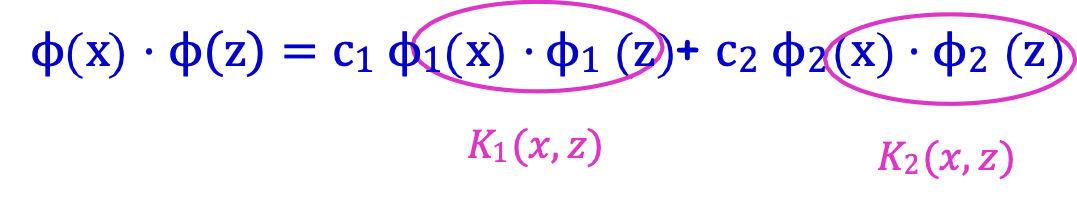
ϕ(x) ⋅ ϕ(z) = c1 ϕ1(x) ⋅ ϕ1(z) + c2 ϕ2(x) ⋅ ϕ2(z)
Hàm nhân, Thuộc tính đóng
Dễ dàng tạo nhân mới bằng các nhân cơ bản!
Dữ kiện: Nếu K1 (⋅,⋅) và K2 (⋅,⋅) là hàm nhân,
khi đó K(x, z) = K1(x, z) K2(x, z) là một nhân.
Ý chính: ϕ(x) = (ϕ1,i(x) ϕ2,j(x)) 𝑖∈{1,…,𝑛},𝑗∈{1,…,𝑚}
ϕ(x) ⋅ ϕ(z) = ∑𝑖,𝑗 ϕ1,i(x) ϕ2,j(x) ϕ1,i(z) ϕ2,j(z)
= ∑𝑖 ϕ1,i(x) ϕ1,𝑖(z) (∑𝑗 ϕ2,𝑗(x) ϕ2,j(z))
= ∑𝑖 ϕ1,i(x) ϕ1,𝑖(z) K2(x, z) = K1(x, z) K2(x, z)
Kernels, Discussion
- Nếu tất cả các tính toán liên quan đến các thể hiện là về các tích bên trong thì:
- Về mặt khái niệm, hoạt động trong không gian diml rất cao và hiệu suất của thuật toán chỉ phụ thuộc vào khả năng phân tách tuyến tính trong không gian mở rộng đó.
- Về mặt tính toán, chỉ cần sửa thuật toán bằng cách thay mỗi x ⋅ z bằng K(x, z).
- Rất nhiều thuật toán Machine Learning có thể kernel hóa được:
- phân loại: Perceptron, SVM.
- hồi quy: hồi quy tuyến tính.
- phân cụm: k-means.
Kernels, Discussion
- Nếu tất cả các tính toán liên quan đến thể hiện đều là tích bên trong thì:
- Về mặt khái niệm, làm việc trong không gian có diml rất cao và hiệu suất của thuật toán chỉ phụ thuộc vào khả năng phân tách tuyến tính trong không gian mở rộng đó.
- Về mặt tính toán, chỉ cần sửa thuật toán bằng cách thay mỗi x ⋅ z bằng K(x, z).
Cách chọn kernel:
- Nhân thường mã hóa kiến thức miền (ví dụ: nhân chuỗi)
- Sử dụng Cross-Validation để chọn tham số, ví dụ: 𝜎 cho Gaussian Kernel K(x, 𝑧) = exp[ − ||𝑥−𝑧|| 2⁄ 2 𝜎2]
- Học một hàm nhân tốt; ví dụ: [Lanckriet-Cristianini-Bartlett-El Ghaoui- Jordan’04]