
Tóm tắt từ lần trước: Boosting
- Phương pháp chung để cải thiện độ chính xác của bất kỳ thuật toán học cụ thể nào.
- Hoạt động bằng cách tạo một loạt các bộ dữ liệu thách thức mà ngay cả hiệu suất khiêm tốn trên những bộ này cũng có thể được sử dụng để tạo ra một công cụ dự đoán tổng thể có độ chính xác cao.
- Adaboost là một trong 10 thuật toán ML hàng đầu.
- Hoạt động rất tốt trong thực tế.
- Được hỗ trợ bởi nền móng vững chắc.
Adaboost (Boosting thích ứng)
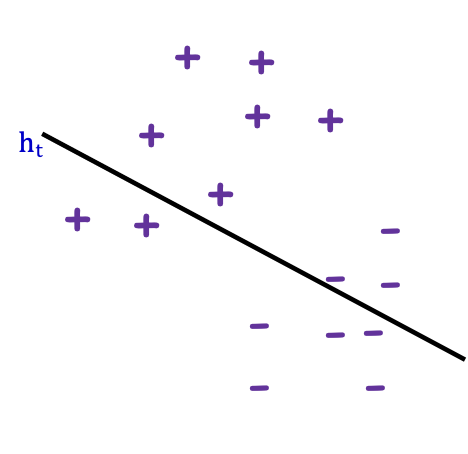
Đầu vào: S={(x1, 𝑦1), …,(xm, 𝑦m)}; xi ∈ 𝑋, 𝑦𝑖 ∈ 𝑌 = {−1,1}
thuật toán học yếu A (ví dụ: Naïve Bayes, các gốc quyết định)
- Với t=1,2, … ,T
- Xây dựng Dt trên {x1, …, xm}
- Chạy A trên Dt tạo ra ht: 𝑋 → {−1,1}
Đầu ra Hfinal(𝑥) = sign(∑𝑡=1 𝛼𝑡ℎ𝑡(𝑥))
- D1 đồng nhất trên {x1, …, xm} [nghĩa là D1(𝑖) = 1⁄𝑚]
- Cho Dt và ht đặt
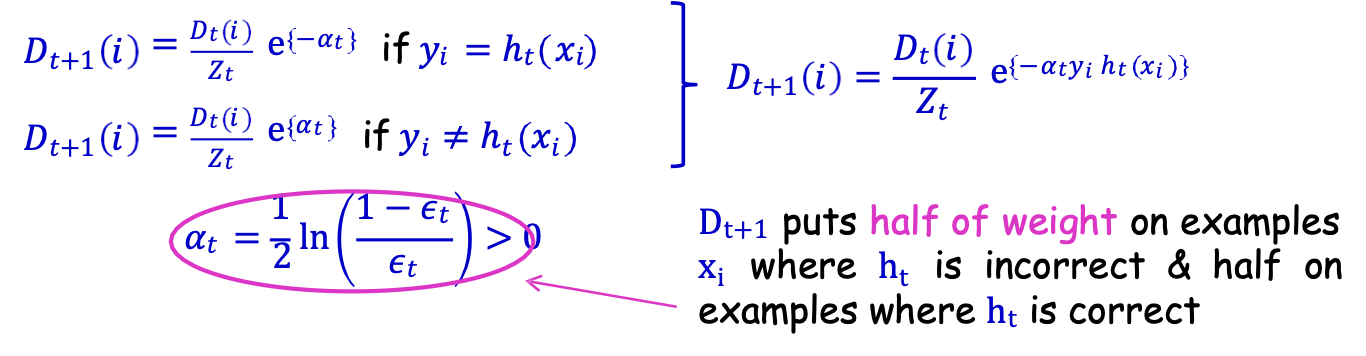
Dt+1 đặt một nửa trọng số cho các mẫu xi khi ht sai & một nửa cho các mẫu ht đúng
Các tính năng hay của Adaboost
- Rất tổng quát: một siêu thủ tục, nó có thể sử dụng bất kỳ thuật toán học yếu nào!!! (ví dụ: Naïve Bayes, các gốc quyết định)
- Rất nhanh (dữ liệu đi qua một lần trong mỗi vòng) & viết mã đơn giản, không cần điều chỉnh tham số.
- Dựa trên lý thuyết phong phú.
Phân tích Lỗi Huấn luyện
Định lý 𝜖𝑡 = 1/2 − 𝛾𝑡 (lỗi của ℎ𝑡 trên 𝐷𝑡)
𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2]
Vì vậy, nếu ∀𝑡, 𝛾𝑡 ≥ 𝛾 > 0 thì 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp[ −2 𝛾2𝑇]
Sai số giảm hàm mũ!!!
Để nhận 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ 𝜖, chỉ cần 𝑇 = 𝑂 (1⁄𝛾2 log (1⁄𝜖)) Vòng
Adaboost là thích ứng
- Không cần biết 𝛾 hoặc T tiên nghiệm
- Có thể khai thác 𝛾𝑡 ≫ 𝛾
Bảo đảm tổng quát
Định lý 𝑒𝑟𝑟𝑆(𝐻𝑓𝑖𝑛𝑎𝑙) ≤ exp [ −2 ∑𝑡𝛾𝑡2] trong đó 𝜖𝑡 = 1/2 − 𝛾𝑡
Làm thế nào về đảm bảo tổng quát?
Giải tích ban đầu [Freund&Schapire’97]
- Không gian H của các giả thuyết yếu; d=VCdim(H)
𝐻𝑓𝑖𝑛𝑎𝑙 là một phiếu bầu có trọng số, vì vậy lớp giả thuyết là:
G = {tất cả các fns của dấu hiệu biểu mẫu sign(∑𝑇𝑡=1 𝛼𝑡ℎ𝑡(𝑥))}
Định lý [Freund & Schapire’97]
∀ 𝑔 ∈ 𝐺, 𝑒𝑟𝑟(𝑔) ≤ 𝑒𝑟𝑟𝑆(𝑔) + 𝑂 (√𝑇𝑑⁄𝑚) T= # vòng
Lý do chính: VCd𝑖𝑚(𝐺) = 𝑂(𝑑𝑇) cộng với các giới hạn VC điển hình.
Đảm bảo tổng quát hóa
Định lý [Freund&Schapire’97]
∀ 𝑔 ∈ 𝐺, 𝑒𝑟𝑟(𝑔) ≤ 𝑒𝑟𝑟𝑆(𝑔) + 𝑂 (√𝑇𝑑⁄𝑚) trong đó d=VCdim(H)
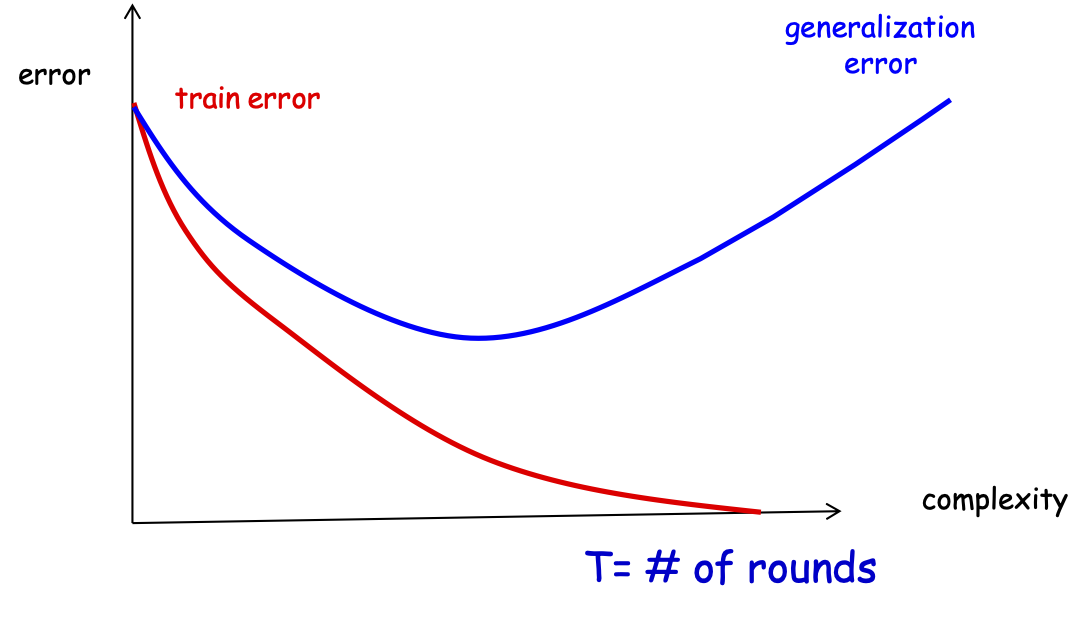
lỗi huấn luyện
lỗi tổng quát
T= # vòng
Đảm bảo tổng quát hóa
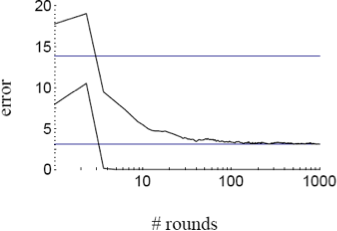
- Các thí nghiệm cho thấy lỗi kiểm tra của bộ phân loại được tạo ra thường không tăng khi kích thước của nó trở nên rất lớn.
- Các thử nghiệm cho thấy rằng việc tiếp tục thêm những học viên yếu mới sau khi đã đạt được phân loại chính xác của tập huấn luyện có thể cải thiện hơn nữa hiệu suất của tập kiểm tra!!!
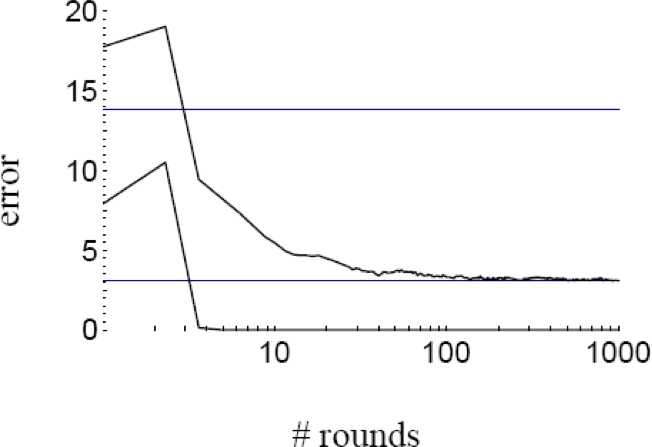
Đảm bảo tổng quát hóa
- Thực nghiệm cho thấy sai số kiểm tra của bộ phân loại được tạo ra thường không tăng khi kích thước của nó trở nên rất lớn.
- Các thử nghiệm cho thấy rằng việc tiếp tục bổ sung thêm các học viên yếu mới sau khi đã đạt được sự phân loại chính xác của tập huấn luyện có thể cải thiện hơn nữa hiệu suất của tập kiểm tra!!!
- Những kết quả này dường như mâu thuẫn với FS’97 bound và Occam’s razor (để đạt được lỗi kiểm tra tốt, bộ phân loại phải càng đơn giản càng tốt)!
∀ 𝑔 ∈ 𝐺, 𝑒𝑟𝑟(𝑔) ≤ 𝑒𝑟𝑟𝑆(𝑔) + 𝑂 (√𝑇𝑑⁄𝑚)
Làm thế nào chúng ta có thể giải thích các thí nghiệm?
R. Schapire, Y. Freund, P. Bartlett, WS Lee. trình bày trong “Boosting lề: Một lời giải thích mới về tính hiệu quả của các phương pháp bỏ phiếu”, một lời giải thích lý thuyết hay.
Ý tưởng chính:
Lỗi đào tạo không nói lên toàn bộ câu chuyện.
Chúng ta cũng cần xem xét độ tin cậy phân loại!!
Việc Boosting dường như không quá khớp với…(!)
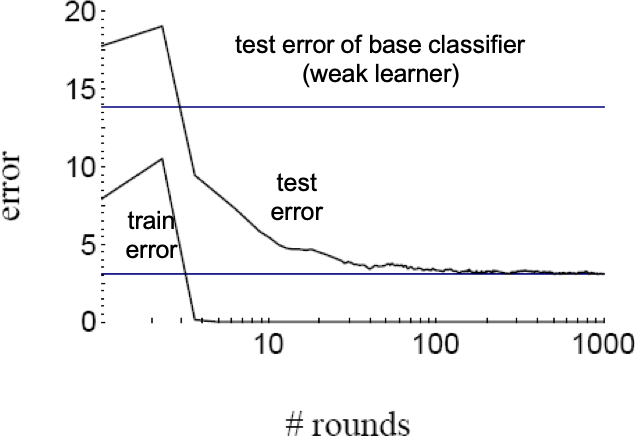
lỗi kiểm tra
lỗi đào tạo
lỗi kiểm tra của bộ phân loại cơ sở (thuật toán học yếu)
…bởi vì hóa ra nó đang tăng lề của bộ phân loại
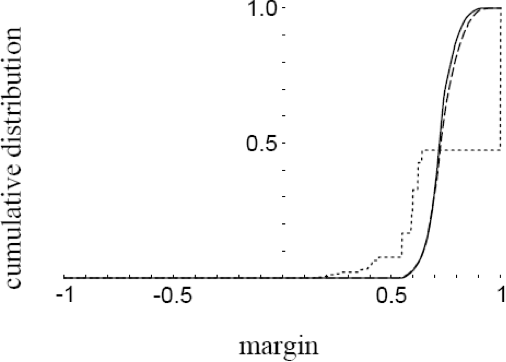
Đường cong lỗi, Đồ thị Phân bổ lề – Đồ thị từ [SFBL98]
Lề phân loại
- H không gian của các giả thuyết yếu. Bao lồi của H:
𝑐𝑜(𝐻) = {𝑓 = ∑𝑇𝑡=1 𝛼𝑡ℎ𝑡 , 𝛼𝑡 ≥ 0, ∑𝑇𝑡=1 𝛼𝑡 = 1, ℎ𝑡 ∈ 𝐻}
- Cho 𝑓 ∈ 𝑐𝑜(𝐻) , 𝑓 = ∑𝑇𝑡=1 𝛼𝑡ℎ𝑡, 𝛼𝑡 ≥ 0, ∑𝑇𝑡=1 𝛼𝑡 = 1.
Quy tắc bỏ phiếu đa số 𝐻𝑓 được đưa ra bởi 𝑓 (được đưa ra bởi 𝐻𝑓 = 𝑠𝑖𝑔𝑛(𝑓(𝑥))) dự đoán sai trên mẫu (𝑥, 𝑦) iff 𝑦𝑓(𝑥) ≤ 0.
Định nghĩa: lề của 𝐻𝑓 (hoặc của 𝑓) trong mẫu (𝑥, 𝑦) là 𝑦𝑓(𝑥).
𝑦𝑓(𝑥) = 𝑦∑𝑇𝑡=1 [𝛼𝑡ℎ𝑡(𝑥)] = ∑𝑇𝑡=1 [𝑦𝛼𝑡ℎ𝑡(𝑥)] = ∑𝑡:𝑦=ℎ𝑡(𝑥) 𝛼𝑡 − ∑𝑡:𝑦≠ℎ𝑡(𝑥) 𝛼𝑡
Lề dương nếu 𝑦 = 𝐻𝑓(𝑥).
Xem |𝑦𝑓(𝑥)| = |𝑓(𝑥)| như sức mạnh hay sự tự tin của lá phiếu.
Boosting và Lề
Định lý: VCdim(𝐻) = 𝑑, khi đó với xác suất. ≥ 1 − 𝛿, ∀𝑓 ∈ 𝑐𝑜(𝐻), ∀𝜃 > 0, Pr 𝐷 [𝑦𝑓(𝑥) ≤ 0] ≤ Pr 𝑆 [𝑦𝑓(𝑥) ≤ 𝜃] + 𝑂( 1⁄ √𝑚 √d ln2𝑚⁄ 𝑑⁄ 𝜃2 + ln 1⁄ 𝛿)
Lưu ý: ràng buộc không phụ thuộc vào T (số vòng Boosting), chỉ phụ thuộc vào phức hợp. của không gian hyp yếu và lề!

Boosting và Margins
Định lý: VCdim(𝐻) = 𝑑, khi đó với xác suất. ≥ 1 − 𝛿, ∀𝑓 ∈ 𝑐𝑜(𝐻), ∀𝜃 > 0, Pr 𝐷 [𝑦𝑓(𝑥) ≤ 0] ≤ Pr 𝑆 [𝑦𝑓(𝑥) ≤ 𝜃] + 𝑂( 1⁄ √𝑚 √d ln2𝑚⁄ 𝑑⁄ 𝜃2 + ln 1⁄ 𝛿)
- Nếu tất cả các mẫu huấn luyện có lề lớn, thì chúng ta có thể ước lượng bộ phân loại cuối cùng bằng một bộ phân loại nhỏ hơn nhiều.
- Có thể sử dụng điều này để chứng minh rằng lề tốt hơn → lỗi kiểm tra nhỏ hơn, bất kể số lượng bộ phân loại yếu.
- Cũng có thể chứng minh rằng việc Boosting có xu hướng làm tăng lề của các mẫu huấn luyện bằng cách tập trung vào những mẫu có lề nhỏ nhất.
- Mặc dù bộ phân loại cuối cùng ngày càng lớn hơn, nhưng lề có thể sẽ tăng lên, do đó, bộ phân loại cuối cùng đang tiến gần hơn đến một bộ phân loại đơn giản hơn, giúp giảm lỗi kiểm tra.
Boosting và lề
Định lý: VCdim(𝐻) = 𝑑, khi đó với xác suất. ≥ 1 − 𝛿, ∀𝑓 ∈ 𝑐𝑜(𝐻), ∀𝜃 > 0, Pr 𝐷 [𝑦𝑓(𝑥) ≤ 0] ≤ Pr 𝑆 [𝑦𝑓(𝑥) ≤ 𝜃] + 𝑂( 1⁄ √𝑚 √d ln2𝑚⁄ 𝑑⁄ 𝜃2 + ln 1⁄ 𝛿)
Lưu ý: ràng buộc không phụ thuộc vào T (số vòng Boosting), chỉ phụ thuộc vào phức hợp. của không gian hyp yếu và lề!

Tóm tắt Boosting, Adaboost
- Thay đổi tư duy: mục tiêu bây giờ chỉ là tìm ra các bộ phân loại tốt hơn một chút so với đoán ngẫu nhiên.
- Được hỗ trợ bởi nền móng vững chắc.
- Adaboost hoạt động tốt và các biến thể của nó trong thực tế với nhiều loại dữ liệu (một trong 10 thuật toán ML hàng đầu).
- Thông tin thêm về các ứng dụng cổ điển trong Niệm.
- Phù hợp với thời đại dữ liệu lớn: nhanh chóng tập trung vào “những khó khăn cốt lõi”, rất phù hợp với các cài đặt phân tán, nơi dữ liệu phải được truyền đạt hiệu quả [Balcan-Blum-Fine-Mansour COLT’12].
Điều thú vị là tính hữu ích của lề được công nhận trong Machine Learning từ cuối những năm 50.
Perceptron [Rosenblatt’57] được phân tích thông qua lề hình học (còn gọi là 𝐿2, 𝐿2).
Đảm bảo bản gốc trong kịch bản học trực tuyến.
Thuật toán Perceptron
- Mô hình học tập trực tuyến
- Phân tích lề
- Hàm nhân
Mô hình Học tập Trực tuyến
- Mẫu đến tuần tự.
- Chúng ta cần đưa ra dự đoán.
Sau đó quan sát kết quả.
For i=1, 2, …, :

Mô hình ràng buộc sai lầm
- Phân tích khôn ngoan, không đưa ra giả định phân phối.
- Mục tiêu: Giảm thiểu số lần mắc lỗi.
Mô hình học tập trực tuyến. Động lực
- Phân loại email (phân phối cả thư rác và thư thông thường thay đổi theo thời gian, nhưng hàm mục tiêu vẫn cố định – thư rác năm ngoái vẫn giống như thư rác).
- Các hệ thống khuyến nghị. Đề xuất phim, v.v.
- Dự đoán liệu người dùng có quan tâm đến một bài báo mới hay không.
- Thêm vị trí trong một thị trường mới.
Bộ tách tuyến tính
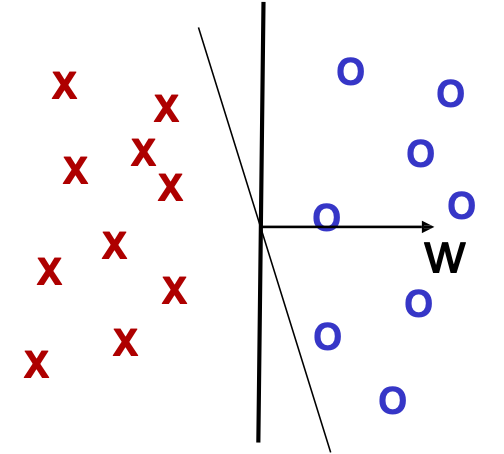
- Không gian thực thể X = Rd
- Lớp giả thuyết của các mặt quyết định tuyến tính trong Rd.
- h(x) = w ⋅ x + w0, nếu ℎ(𝑥) ≥ 0, thì gắn nhãn x là +, nếu không thì gắn nhãn là –
Yêu cầu: WLOG w0 = 0.
Bằng chứng: Có thể mô phỏng ngưỡng khác 0 bằng tính năng nhập giả 𝑥0 tức là luôn bằng 1.
- 𝑥 = (𝑥1, … , 𝑥𝑑) → 𝑥~ = (𝑥1, … , 𝑥𝑑 , 1)
- w ⋅ x + w0 ≥ 0 iff (𝑤1, … , 𝑤𝑑 , w0) ⋅ 𝑥~ ≥ 0 trong đó w = (𝑤1, … , 𝑤𝑑)
Bộ phân tách tuyến tính: Thuật toán Perceptron
- Đặt t=1, bắt đầu với vectơ 0 𝑤1.
- Cho mẫu 𝑥, dự đoán dương iff 𝑤𝑡 ⋅ 𝑥 ≥ 0
- Có lỗi, cập nhật như sau:
- Lỗi dương, khi đó cập nhật 𝑤𝑡+1 ← 𝑤𝑡 + 𝑥
- Sai về âm, khi đó cập nhật 𝑤𝑡+1 ← 𝑤𝑡 − 𝑥
Lưu ý: 𝑤𝑡 tổng trọng số của các mẫu được phân loại không chính xác
𝑤𝑡 = 𝑎𝑖1𝑥𝑖1 + ⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘
𝑤𝑡 ⋅ 𝑥 = 𝑎𝑖1𝑥𝑖1 ⋅ 𝑥 + ⋯+ 𝑎𝑖𝑘𝑥𝑖𝑘 ⋅ 𝑥
Quan trọng khi chúng ta nói về hàm nhân.
Thuật toán Perceptron: Ví dụ
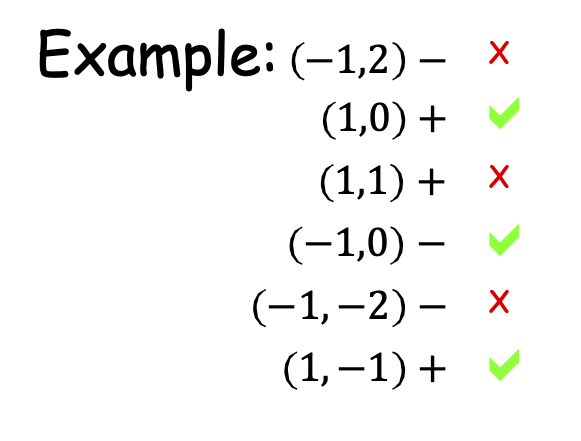
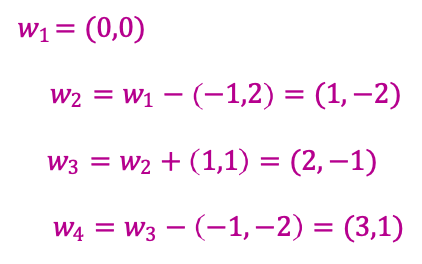
Thuật toán:
- Đặt t=1, bắt đầu với vectơ trọng số bằng 0 𝑤1.
- Cho mẫu 𝑥, dự đoán dương iff 𝑤𝑡 ⋅ 𝑥 ≥ 0.
- Khi có lỗi, cập nhật như sau:
- Sai về dương, cập nhật 𝑤𝑡+1 ← 𝑤𝑡 + 𝑥
- Sai về âm, cập nhật 𝑤𝑡+1 ← 𝑤𝑡 − 𝑥
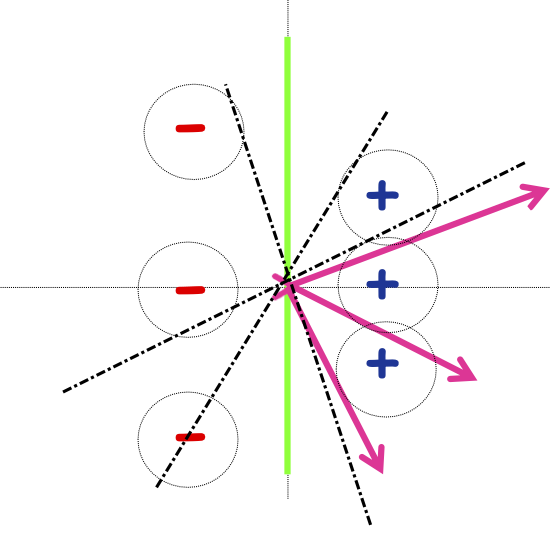
Lề hình học
Định nghĩa: Lề của mẫu 𝑥 wrt a linear sep . 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0 (hoặc âm nếu sai vế)
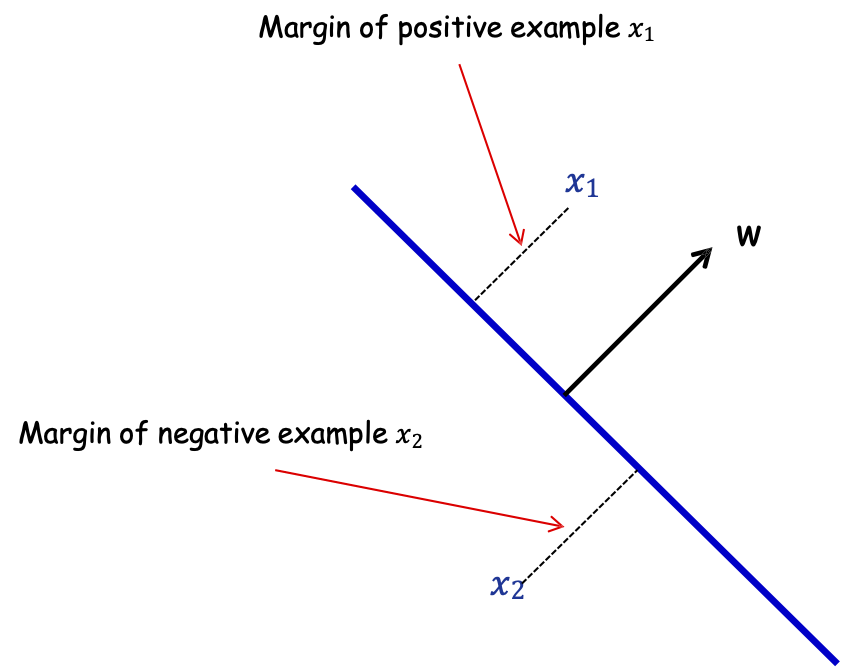
Lề của mẫu dương 𝑥1
Lề của mẫu âm 𝑥2
Lề hình học
Định nghĩa: Lề của mẫu 𝑥 wrt một sep tuyến tính. 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0 (hoặc âm nếu sai vế)
Định nghĩa: Lề 𝛾𝑤 của một tập mẫu 𝑆 wrt một dấu phân cách tuyến tính 𝑤 là lề nhỏ nhất trên các điểm 𝑥 ∈ 𝑆.

Lề hình học
Định nghĩa: Lề của mẫu 𝑥 wrt một sep tuyến tính. 𝑤 là khoảng cách từ 𝑥 đến mặt phẳng 𝑤 ⋅ 𝑥 = 0 (hoặc âm nếu sai vế)
Định nghĩa: Lề 𝛾𝑤 của một tập mẫu 𝑆 wrt một dấu phân cách tuyến tính 𝑤 là lề nhỏ nhất trên các điểm 𝑥 ∈ 𝑆.
Định nghĩa: Lề 𝛾 của một tập hợp các mẫu 𝑆 là 𝛾𝑤 lớn nhất trên tất cả các dấu phân cách tuyến tính 𝑤.

Perceptron: Giới hạn sai lầm
Định lý: Nếu dữ liệu có lề 𝛾 và tất cả các điểm bên trong quả cầu có bán kính 𝑅, thì Perceptron tạo ≤ (𝑅/𝛾)2 sai lầm.
(Lề chuẩn hóa: nhân tất cả các điểm với 100 hoặc chia tất cả các điểm cho 100, không làm thay đổi số lượng lỗi; thuật toán là bất biến đối với tỷ lệ.)
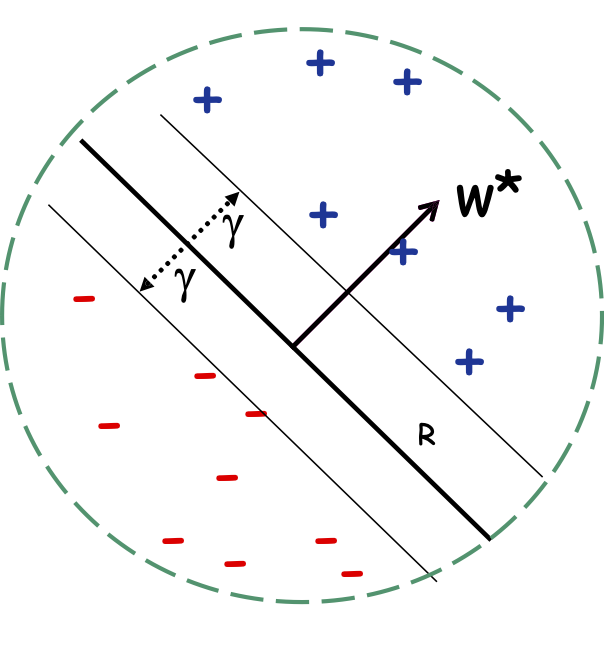
Thuật toán Perceptron: Phân tích
Định lý: Nếu dữ liệu có lề 𝛾 và tất cả các điểm bên trong quả cầu có bán kính 𝑅, thì Perceptron mắc ≤ (𝑅/𝛾)2 lỗi.
Cập nhật quy tắc:
- Sai về dương: 𝑤𝑡+1 ← 𝑤𝑡 + 𝑥
- Sai về âm: 𝑤𝑡+1 ← 𝑤𝑡 − 𝑥
Chứng minh:
Ý tưởng: phân tích 𝑤𝑡 ⋅ 𝑤∗ và ‖𝑤𝑡‖, trong đó 𝑤∗ là lề tối đa , ‖𝑤∗‖ = 1.
Khẳng định 1: 𝑤𝑡+1 ⋅ 𝑤∗ ≥ 𝑤𝑡 ⋅ 𝑤∗ + 𝛾. (vì 𝑙(𝑥)𝑥 ⋅ 𝑤∗ ≥ 𝛾)
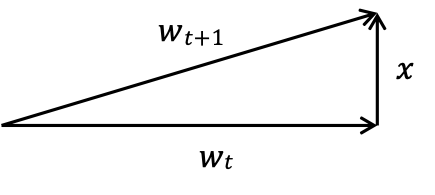
Khẳng định 2: ‖𝑤𝑡+1‖2 ≤ ‖𝑤𝑡‖2 + 𝑅2. (theo Định lý Pitago)
Sau 𝑀 sai lầm:
𝑤𝑀+1 ⋅ 𝑤∗ ≥ 𝛾𝑀 (theo Khẳng định 1)
‖𝑤𝑀+1‖ ≤ 𝑅√𝑀 (theo Khẳng định 2)
𝑤𝑀+1 ⋅ 𝑤∗ ≤ ‖𝑤𝑀+1‖ (vì 𝑤∗ là đơn vị độ dài)
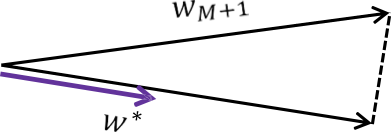
Vậy 𝛾𝑀 ≤ 𝑅√𝑀, nên 𝑀 ≤ (𝑅⁄𝛾)2.
Phần mở rộng của Perceptron
- Có thể sử dụng nó để tìm dấu tách nhất quán (bằng cách quay vòng qua dữ liệu).
- Người ta cũng có thể chuyển đổi bảo đảm ràng buộc sai lầm thành bảo đảm phân phối (đối với trường hợp các 𝑥𝑖 đến từ một phân phối cố định).
- Có thể thích ứng với trường hợp không có dải phân cách hoàn hảo miễn là cái gọi là suy hao bản lề (nghĩa là tổng khoảng cách cần thiết để di chuyển các điểm để phân loại chúng theo lề lớn một cách chính xác) là nhỏ.
- Có thể được nhân hóa để xử lý các ranh giới quyết định phi tuyến tính!
Thảo luận Perceptron
- Thuật toán trực tuyến đơn giản để học các dấu phân cách tuyến tính với sự đảm bảo tốt đẹp chỉ phụ thuộc vào lề hình học (còn gọi là 𝐿2, 𝐿2).
- Nó có thể được hàm nhân hóa để xử lý các ranh giới quyết định phi tuyến tính — xem lớp tiếp theo!
- Đơn giản, nhưng rất hữu ích trong các ứng dụng như Dự đoán rẽ nhánh ; nó cũng có các phần mở rộng thú vị để dự đoán có cấu trúc.