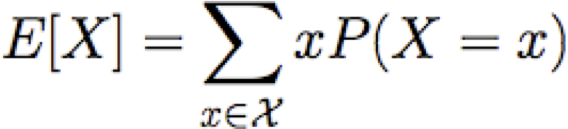Hôm nay:
- Bayes Classifiers
- Conditional Independence
- Naïve Bayes
Readings:
Mitchell: “Naïve Bayes and Logistic Regression” (có sẵn trên trang web của lớp)
Hai nguyên tắc ước lượng tham số
Maximum Likelihood Estimate (MLE): chọn θ để tối đa hóa xác suất của dữ liệu được quan sát D
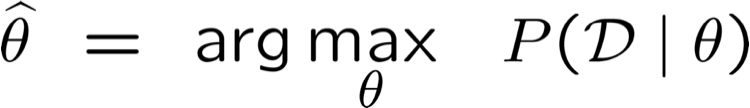
Ước tính tối đa của Posteriori (MAP): chọn θ có khả năng xảy ra nhất với xác suất trước và dữ liệu
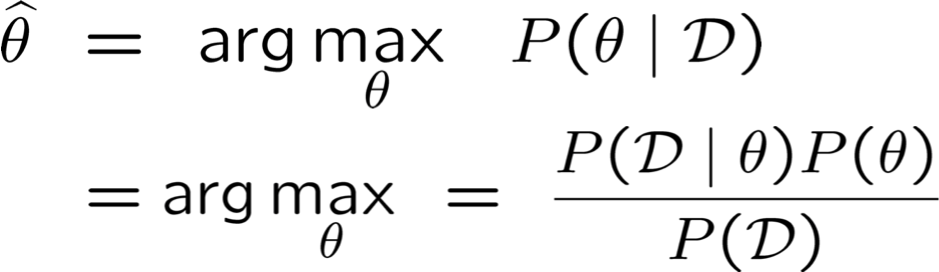
Ước tính khả năng xảy ra tối đa

X=1 X=0
P(X=1) = θ
P(X=0) = 1-θ
(Bernoulli)
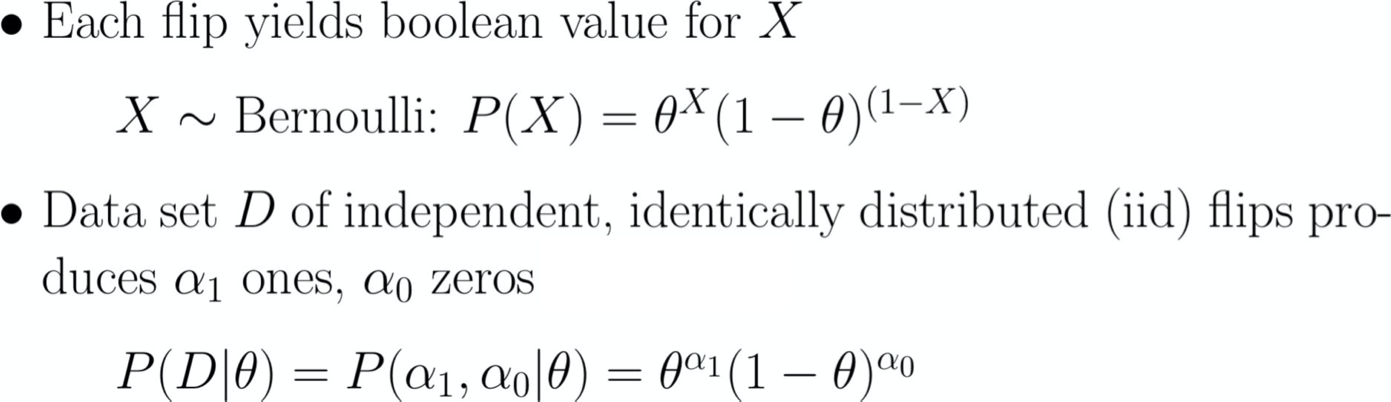
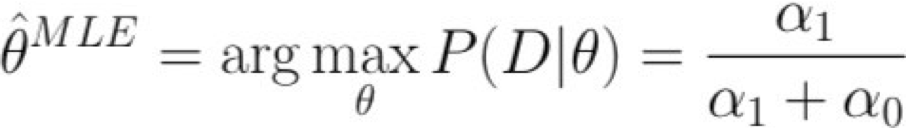
Ước tính tối đa của Posteriori (MAP)

X=1 X=0
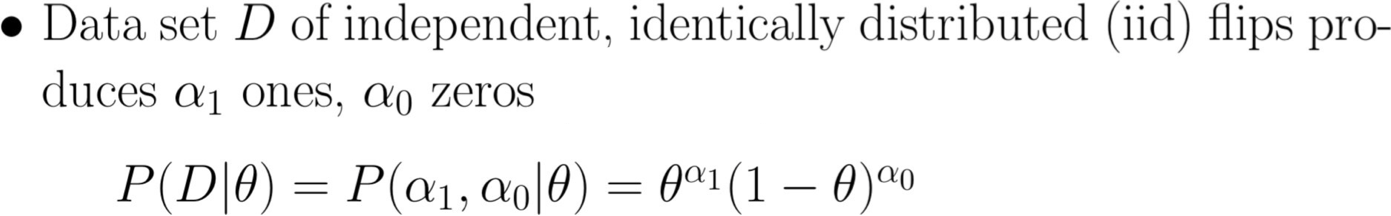

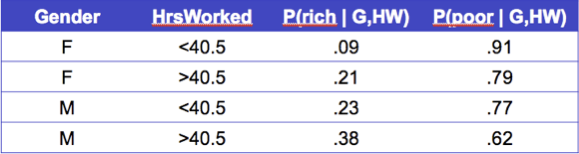
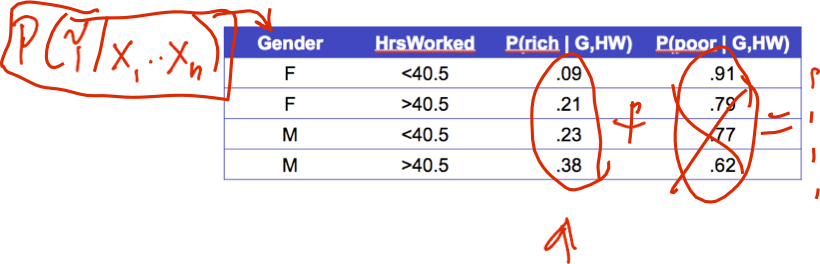
Hãy tìm hiểu các bộ phân loại bằng cách học P(Y|X)
Xem xét Y=Wealth, X=<Gender, HoursWorked>
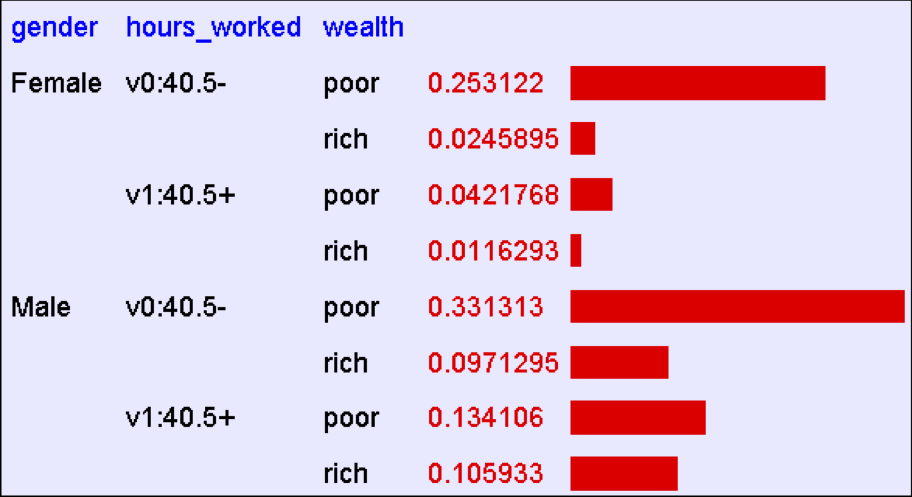
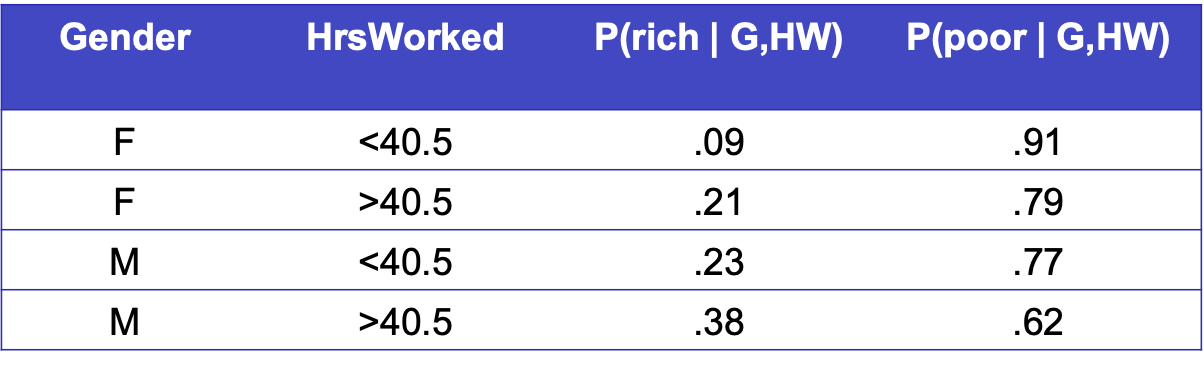
Phải có bao nhiêu tham số Chúng ta ước tính?
Giả sử X =<X1,… Xn> trong đó Xi và Y là RV boolean
Để ước lượng P(Y| X1, X2, … Xn)
Nếu chúng ta có 30 boolean Xi‘s: P(Y | X1, X2, … X30)
Chúng ta phải ước lượng bao nhiêu thông số?
Giả sử X =<X1,… Xn> trong đó Xi và Y là RV boolean
Để ước lượng P(Y| X1, X2, … Xn)

Nếu chúng ta có 30 Xi thay vì 2?
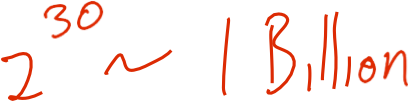
Quy tắc Bayes
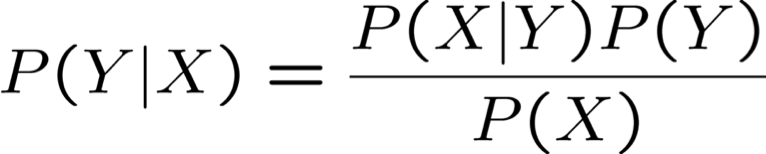
Đó là cách viết tắt của:
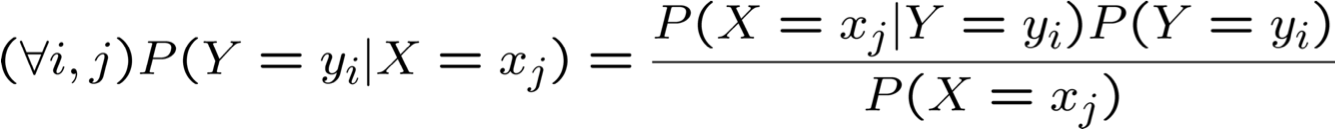
Tương đương:
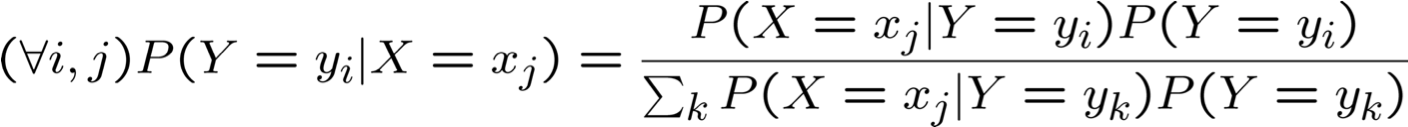
Chúng ta có thể giảm tham số bằng Quy tắc Bayes không?
Giả sử X =<X1,… Xn> trong đó Xi và Y là RV boolean
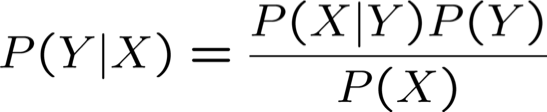
Có bao nhiêu tham số để xác định P(X1,…Xn | Y)?
Có bao nhiêu tham số để xác định P(Y)?
Chúng ta có thể giảm tham số bằng Quy tắc Bayes không?
Giả sử X =<X1,… Xn> trong đó Xi và Y là RV boolean
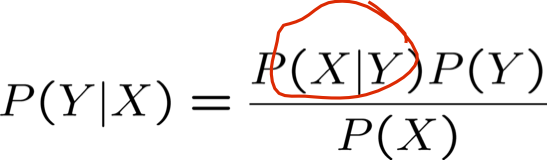
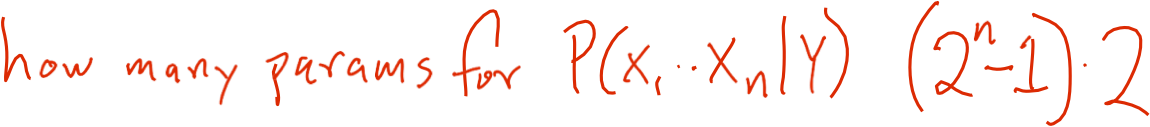
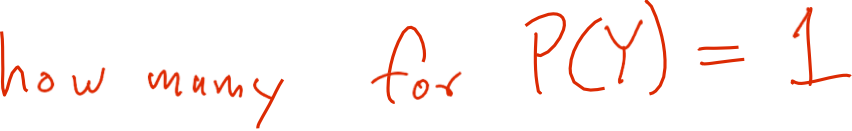
Naïve Bayes
Giả định Naïve Bayes
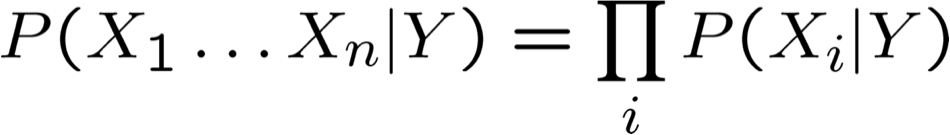
tức là Xi và Xj độc lập có điều kiện với Y, với mọi i≠j
Độc lập có điều kiện
Định nghĩa: X độc lập có điều kiện với Y với Z, nếu phân phối xác suất chi phối X độc lập với giá trị của Y, cho trước giá trị của Z
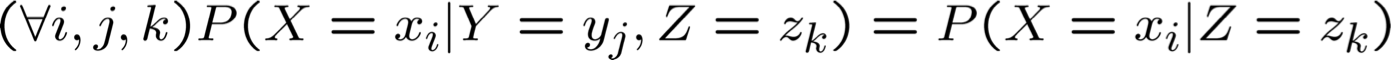
mà chúng ta thường viết
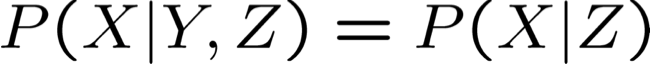
Ví dụ,
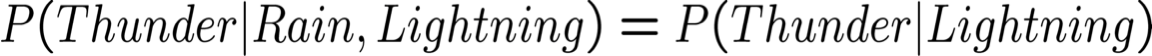
Naïve Bayes sử dụng giả định rằng Xi độc lập có điều kiện, với Y. Ví dụ,
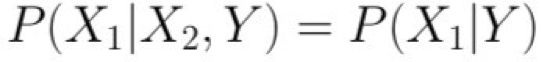
Với giả định này, thì:
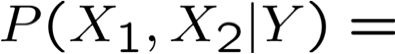
Naïve Bayes sử dụng giả định rằng Xi độc lập có điều kiện, với Y. Ví dụ,
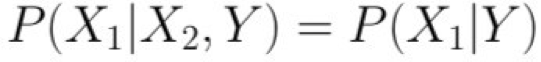
Với giả định này, thì:
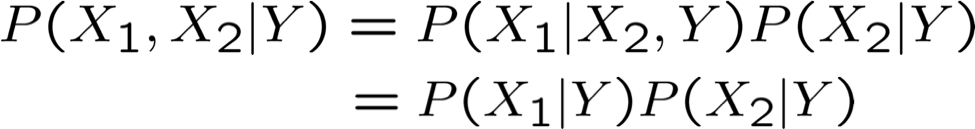
nói chung:
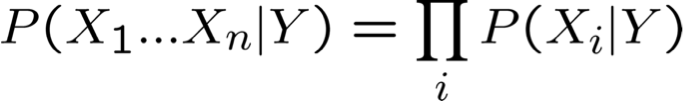
Naïve Bayes sử dụng giả định rằng Xi độc lập có điều kiện, với Y. Ví dụ,
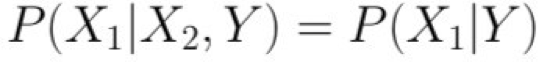
Với giả định này, thì:
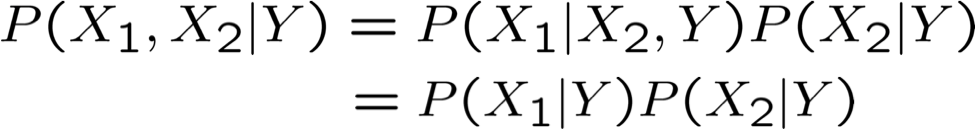
nói chung:
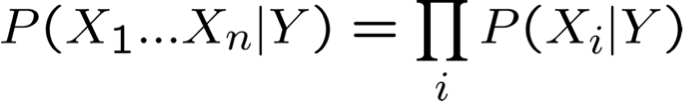
Có bao nhiêu tham số để mô tả P(X1…Xn|Y)? P(Y)?
- Không có giả định độc lập có điều kiện?
- Với giả định độc lập có điều kiện?
Độc lập có điều kiện
Naïve Bayes sử dụng giả định rằng Xi độc lập có điều kiện, với Y
Với giả định này, thì:
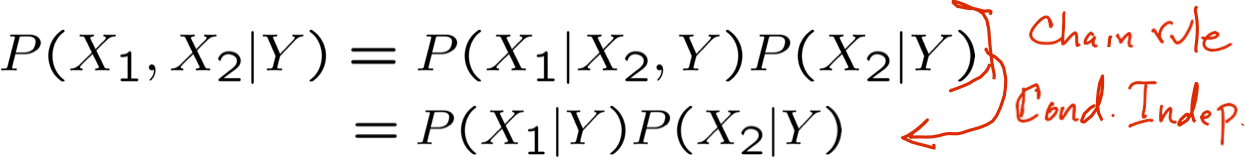
nói chung:
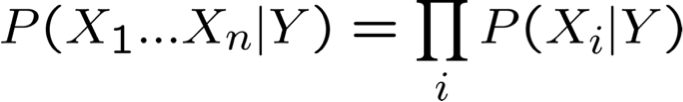
Có bao nhiêu tham số để mô tả P(X1…Xn|Y)? P(Y)?

Sơ lược về Naïve Bayes
Quy tắc Bayes:
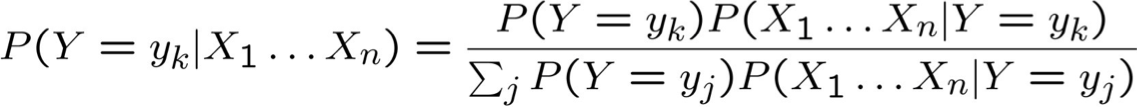
Giả định sự độc lập có điều kiện giữa Xi‘s:
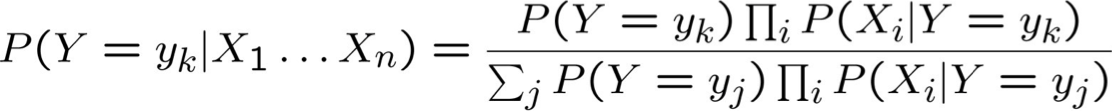
Vì vậy, để chọn Y có thể xảy ra nhất cho Xnew = < X1, …, Xn >
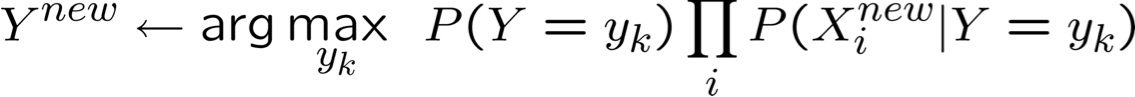
Thuật toán Naïve Bayes – Xi rời rạc
- Huấn luyện Naïve Bayes (mẫu)
- cho mỗi* giá trị yk
- Phân loại (Xnew)
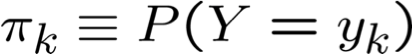
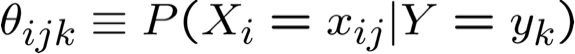
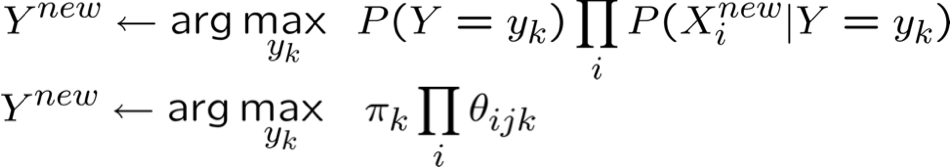
* xác suất phải có tổng bằng 1, vì vậy chỉ cần ước tính n-1 trong số này…
Ước tính Tham số: Y, Xi có giá trị rời rạc
Ước tính khả năng tối đa (MLE’s):
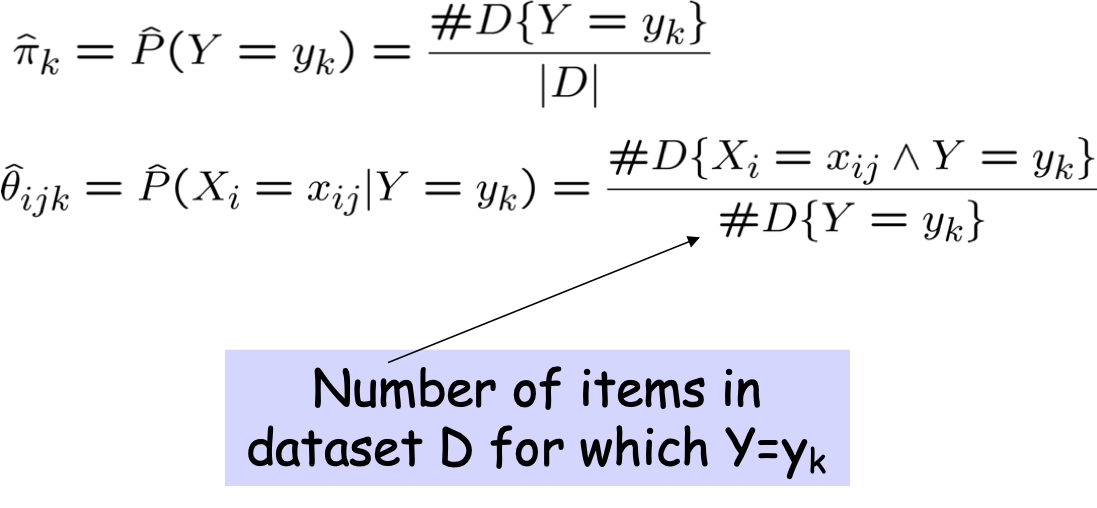
Ví dụ: Sống ở Sq Hill? P(S|G,D,M)
- S=1 nếu sống ở Squirrel Hill
- G=1 nếu mua sắm tại SH Giant Eagle
- D=1 nếu Lái xe đến CMU
- M=1 nếu là người hâm mộ Rachel Maddow
Chúng ta phải ước tính các tham số xác suất nào?
Ví dụ: Sống ở Sq Hill? P(S|G,D,M)
- S=1 nếu sống ở Squirrel Hill
- G=1 nếu mua sắm tại SH Giant Eagle
- D=1 nếu Lái xe đến CMU
- M=1 nếu là người hâm mộ Rachel Maddow
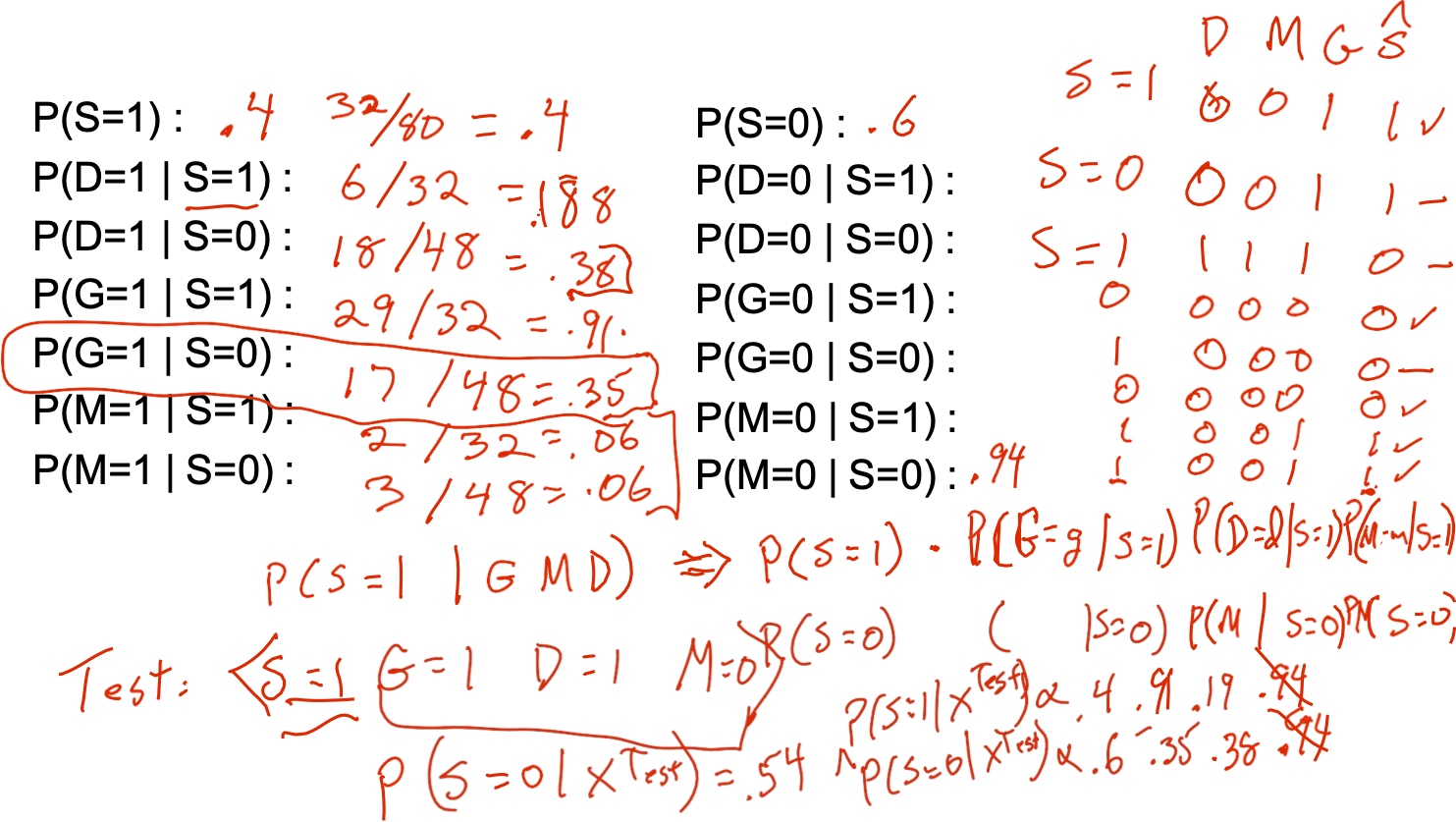
Ví dụ: Sống ở Đồi Sq? P(S|G,D,B)
- S=1 nếu sống ở Squirrel Hill
- G=1 nếu mua sắm tại SH Giant Eagle
- D=1 nếu Lái xe hoặc đi chung xe đến CMU
- B=1 nếu Sinh nhật trước ngày 1 tháng 7
Chúng ta phải ước tính các tham số xác suất nào?
Ví dụ: Sống ở Sq Hill? P(S|G,D,E)
- S=1 nếu sống ở Squirrel Hill
- G=1 nếu mua sắm tại SH Giant Eagle
- D=1 nếu lái xe hoặc đi chung xe đến CMU
- B=1 nếu sinh nhật trước ngày 1 tháng 7

Naïve Bayes: Tinh tế #1
Thường thì Xi không thực sự độc lập có điều kiện
- Dù sao thì chúng ta cũng sử dụng Naïve Bayes trong nhiều trường hợp và nó thường hoạt động khá tốt
- thường là phân loại đúng, ngay cả khi xác suất không đúng (xem [Domingos&Pazzani, 1996])
- Điều gì ảnh hưởng đến ước tính P(Y|X)?
- Trường hợp cực đoan: điều gì sẽ xảy ra nếu chúng ta cộng hai bản sao: Xi = Xk
Trường hợp cực đoan: điều gì xảy ra nếu chúng ta cộng hai bản sao: Xi = Xk
Trường hợp cực đoan: điều gì xảy ra nếu chúng ta cộng hai bản sao: Xi = Xk
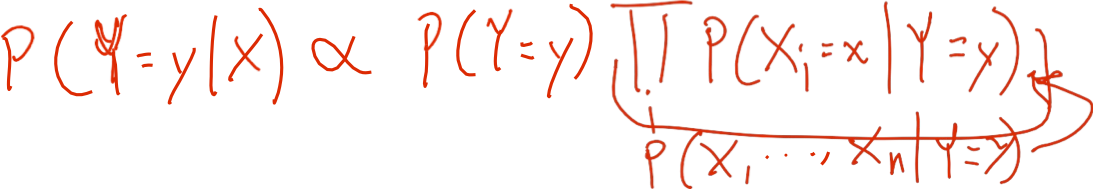
Naïve Bayes: Subtlety #2
Nếu không may mắn, Ước tính MLE của chúng ta cho P(Xi | Y) có thể bằng không. (ví dụ: Xi = ngày sinh. Xi = Jan_25_1992)
- Tại sao phải lo lắng về chỉ một tham số trong số nhiều tham số?
- Có thể làm gì để giải quyết vấn đề này?
Naïve Bayes: Tinh tế #2
Nếu không may mắn, ước tính MLE của chúng ta cho P(Xi | Y) có thể bằng không. (ví dụ: Xi = Birthday_Is_Jan_30_1992)
- Tại sao phải lo lắng về chỉ một tham số trong số nhiều tham số?
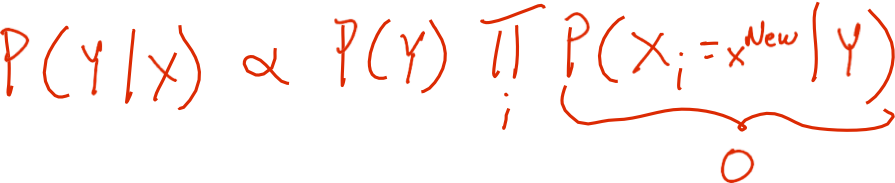
- Có thể làm gì để giải quyết vấn đề này?
Các tham số ước tính
- Ước tính khả năng tối đa (MLE): chọn θ tối đa hóa xác suất của dữ liệu được quan sát D
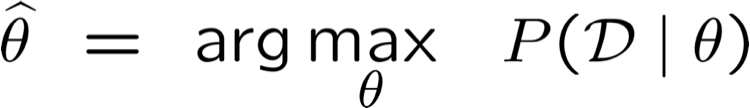
- Ước tính tối đa của Posteriori (MAP): chọn θ có khả năng xảy ra nhất với xác suất trước đó và dữ liệu
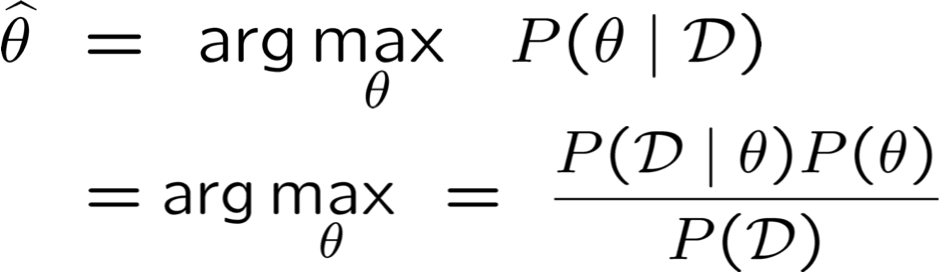
Tham số ước tính: Y, Xi có giá trị rời rạc
Ước tính khả năng tối đa:
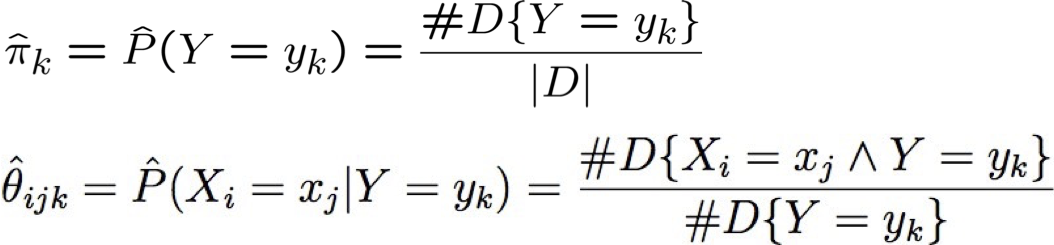
Ước tính MAP (Beta, Dirichlet Priors):
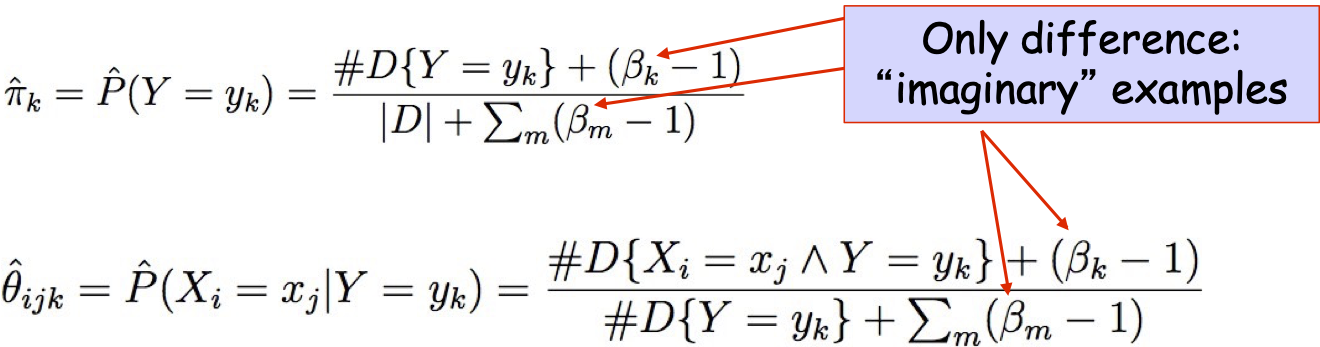
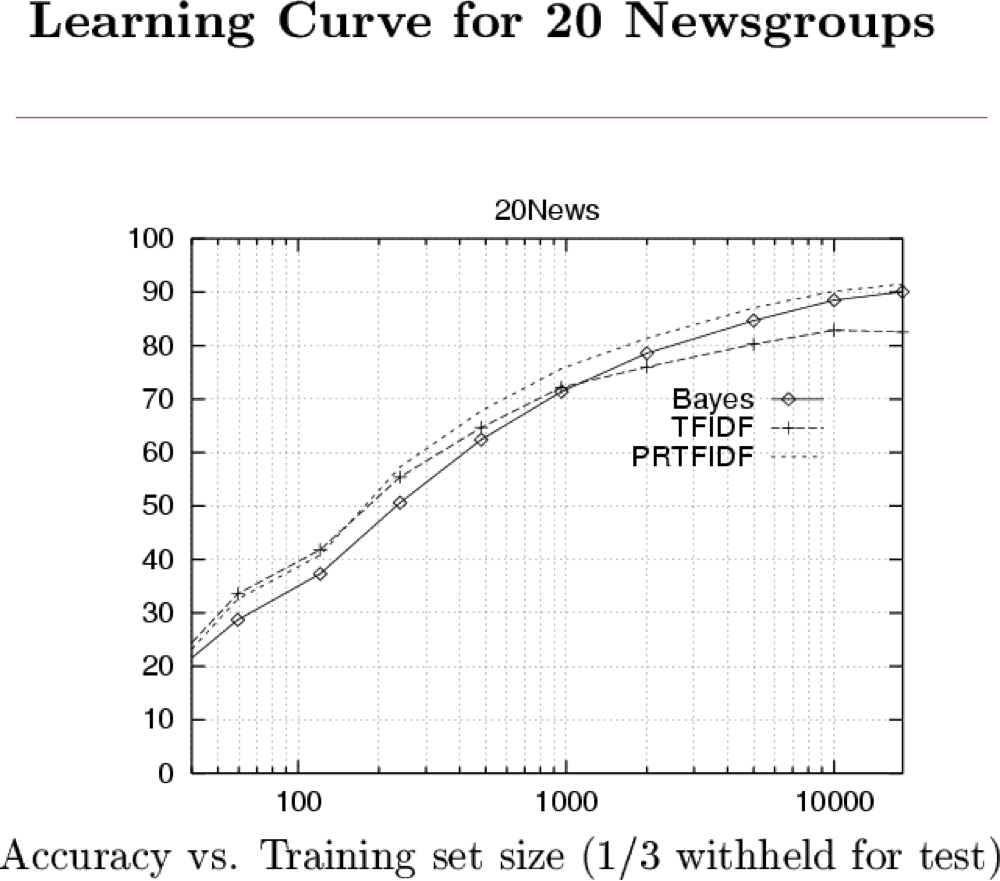
Học cách phân loại tài liệu văn bản
- Phân loại email nào là thư rác?
- Phân loại những email hứa hẹn một tập tin đính kèm?
- Phân loại trang web nào là trang chủ của sinh viên?
Làm thế nào chúng ta sẽ trình bày các tài liệu văn bản cho Naïve Bayes?
Baseline: Phương pháp tiếp cận Bag of Words

Học cách phân loại tài liệu: P(Y|X) mô hình “Túi từ”
- Y có giá trị rời rạc. ví dụ: Spam hay không
- X = <X1, X2, … Xn> = tài liệu
- Xi là một biến ngẫu nhiên mô tả từ ở vị trí i trong tài liệu
- các giá trị có thể có của Xi : bất kỳ từ wk nào trong tiếng Anh
- Tài liệu = túi từ: vectơ đếm cho tất cả các wk’s
- như #heads, #tails, nhưng chúng ta có nhiều hơn 2 giá trị
- giả sử xác suất từ không phụ thuộc vào vị trí (iid cuộn của một con súc sắc 50.000 mặt)
Thuật toán Naïve Bayes – Xi rời rạc
- Huấn luyện Naïve Bayes (mẫu)
- cho từng giá trị yk
- Phân loại (Xnew)
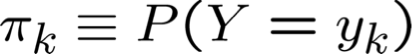
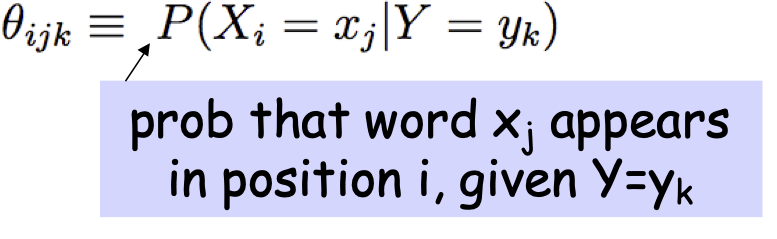
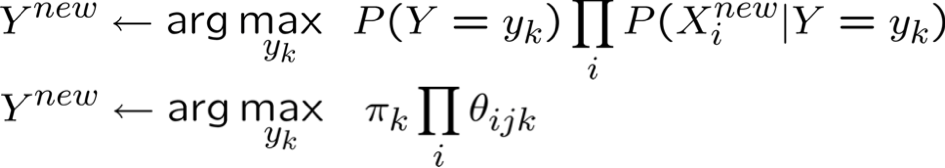
* Giả định bổ sung: xác suất từ không phụ thuộc vào vị trí
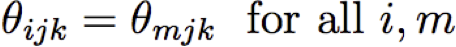
Ước tính MAP cho túi từ
Ước tính Map cho đa thức
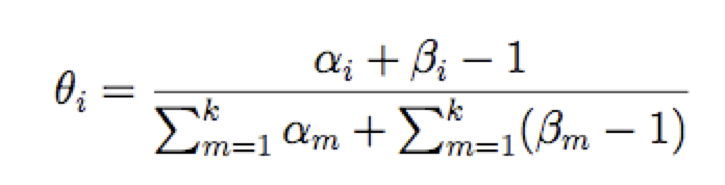
Chúng ta nên chọn những β gì?

Để biết mã và dữ liệu, hãy xem www.cs.cmu.edu/~tom/mlbook.html nhấp vào “Phần mềm và dữ liệu”
Những điều bạn nên biết:
- Đào tạo và sử dụng bộ phân loại dựa trên quy tắc Bayes
- Độc lập có điều kiện
- Nó là gì
- Tại sao nó quan trọng
- Naïve Bayes
- Nó là gì
- Tại sao chúng ta sử dụng nó nhiều như vậy
- Đào tạo sử dụng MLE, ước tính MAP
- Biến rời rạc và liên tục (Gaussian)
Câu hỏi:
- Làm thế nào chúng ta có thể mở rộng Naïve Bayes nếu chỉ có 2 Xi là phụ thuộc?
- Bề mặt quyết định của bộ phân loại Naïve Bayes trông như thế nào?
- Trình phân loại sẽ mắc lỗi gì nếu giả định Naïve Bayes được thỏa mãn và chúng ta có dữ liệu huấn luyện vô hạn?
- Bạn có thể sử dụng Naïve Bayes để kết hợp Xi rời rạc và giá trị thực không?
Nếu chúng ta có Xi liên tục thì sao?
Ví dụ: phân loại ảnh: Xi là pixel thứ i
Nếu chúng ta có Xi liên tục thì sao?
phân loại hình ảnh: Xi là pixel thứ i, Y = trạng thái tinh thần
Vẫn còn có:
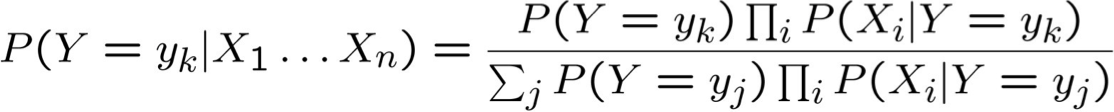
Chỉ cần quyết định cách biểu diễn P(Xi | Y)
Nếu chúng ta có Xi liên tục thì sao?
Ví dụ: phân loại ảnh: Xi là pixel thứ i
Gaussian Naïve Bayes (GNB): giả sử
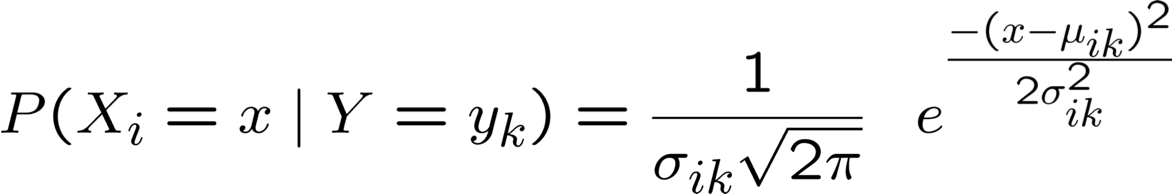
Đôi khi giả sử σik
- độc lập với Y (tức là σi),
- hoặc độc lập với Xi (tức là σk)
- hoặc cả hai (tức là σ)
Thuật toán Gaussian Naïve Bayes – Xi liên tục
(nhưng Y vẫn rời rạc)
- Huấn luyện Naïve Bayes (mẫu)
- cho mỗi giá trị yk
- Phân loại (Xnew)
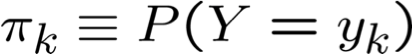
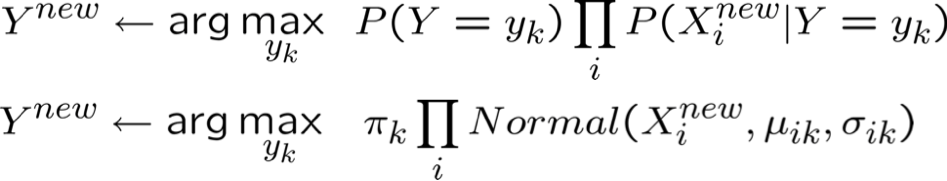
* xác suất phải có tổng bằng 1, vì vậy chỉ cần ước tính n-1 tham số…
Ước tính Tham số: Y rời rạc, Xi liên tục
Ước tính khả năng lớn nhất:
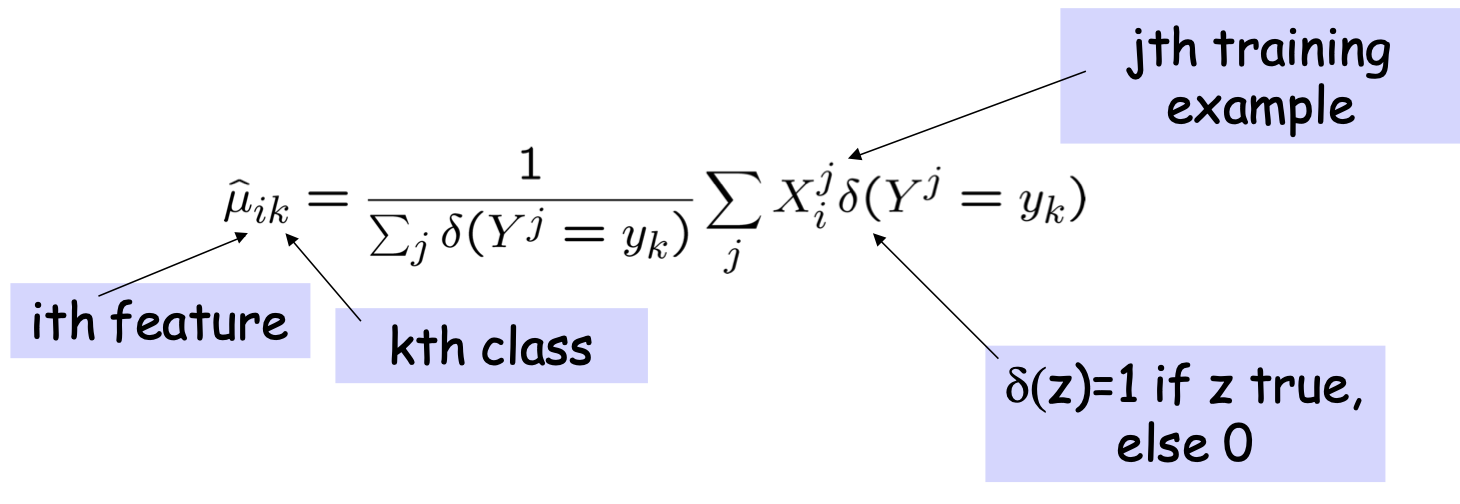
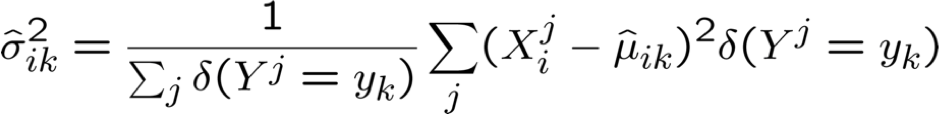
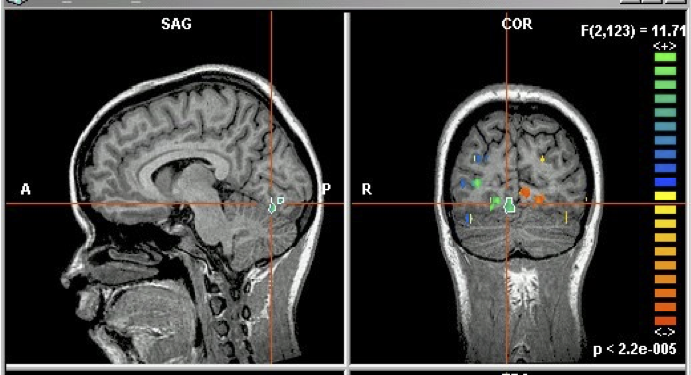
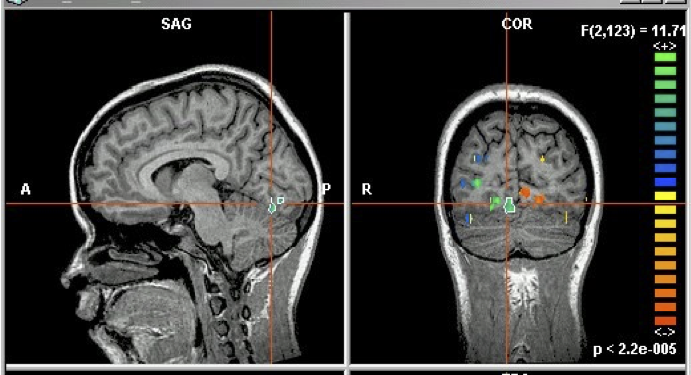
Ví dụ GNB: Phân loại hoạt động nhận thức của một người , dựa trên hình ảnh não bộ
- họ đang đọc một câu hay đang xem một bức tranh?
- đọc từ “Hammer” hoặc “Apartment”
- xem đường thẳng đứng hay nằm ngang?
- trả lời câu hỏi, hoặc bối rối?
Kích thích cho nghiên cứu của chúng ta:
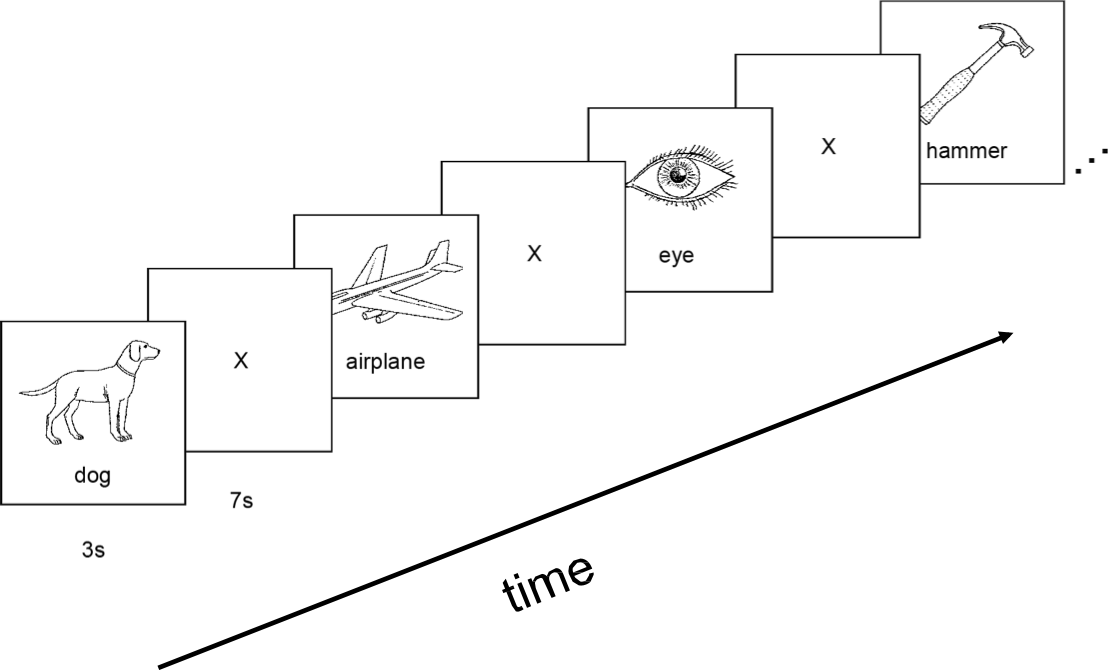
60 mẫu riêng biệt, được trình bày 6 lần mỗi mẫu
điểm ảnh ba chiều fMRI có nghĩa là cho “chai”: có nghĩa là xác định P(Xi | Y=“chai)
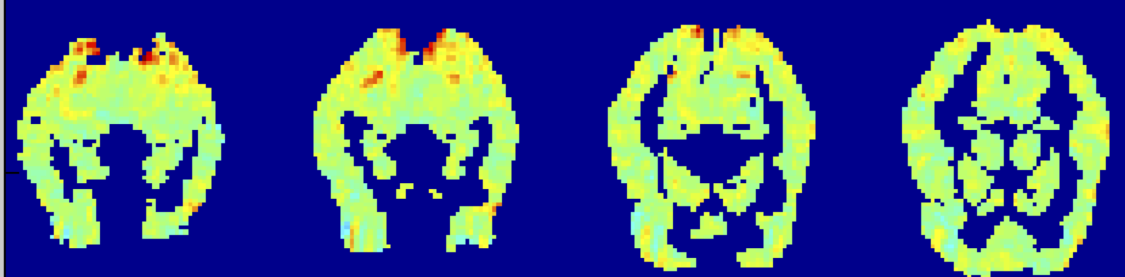
Kích hoạt fMRI trung bình trên tất cả các tác nhân kích thích:
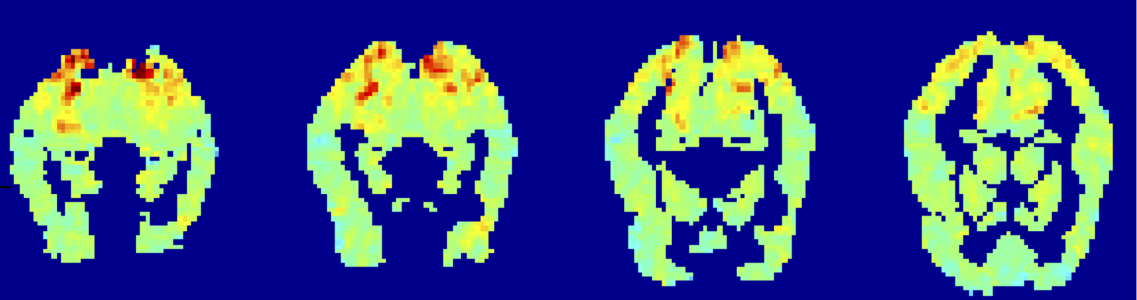
“chai” trừ đi kích hoạt trung bình:
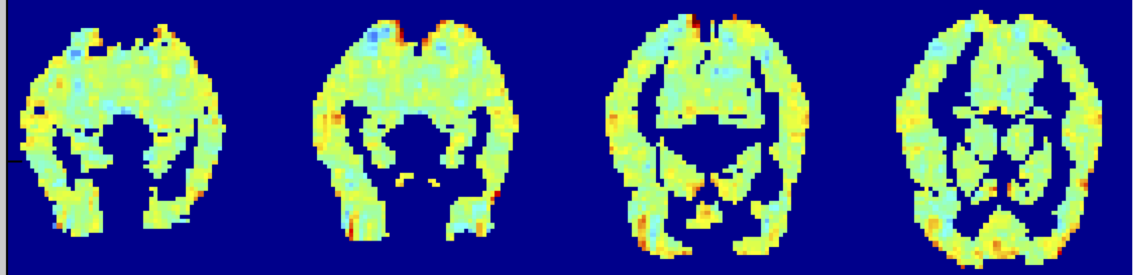
kích hoạt fMRI
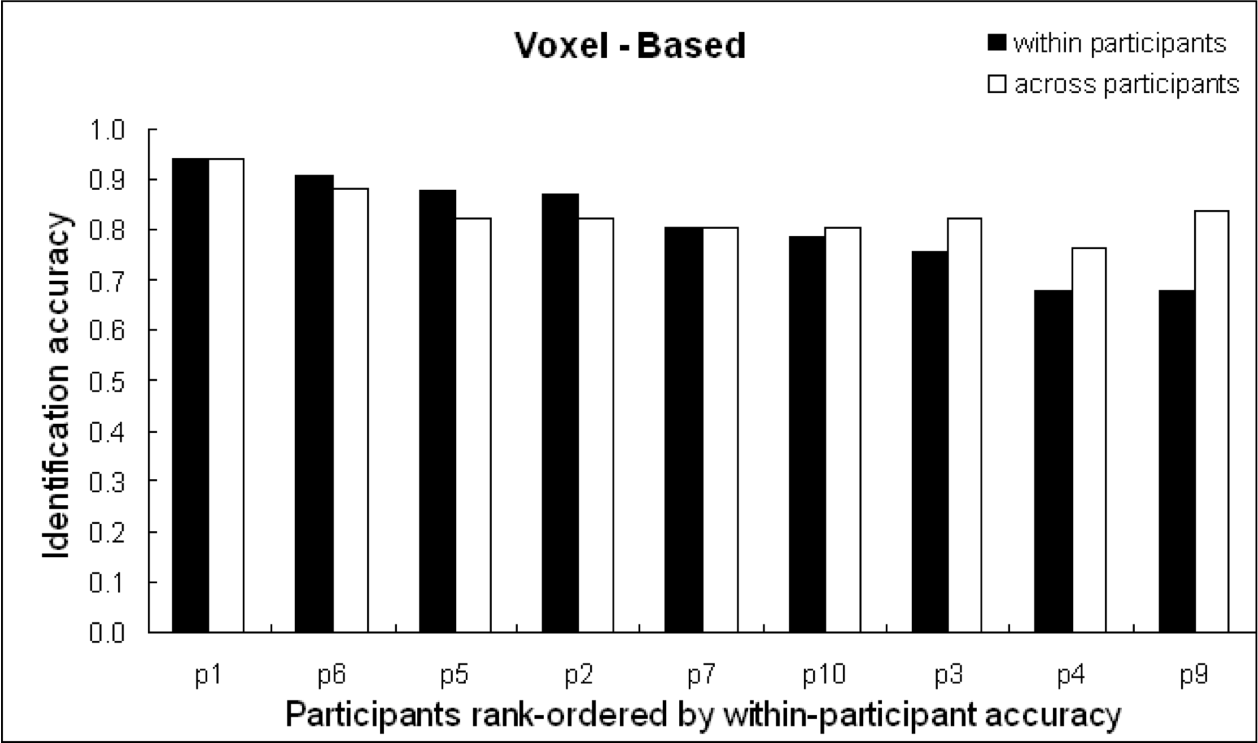
Xếp hạng Độ chính xác Phân biệt giữa 60 từ
Công cụ so với Tòa nhà: não mã hóa nghĩa từ của chúng ở đâu?
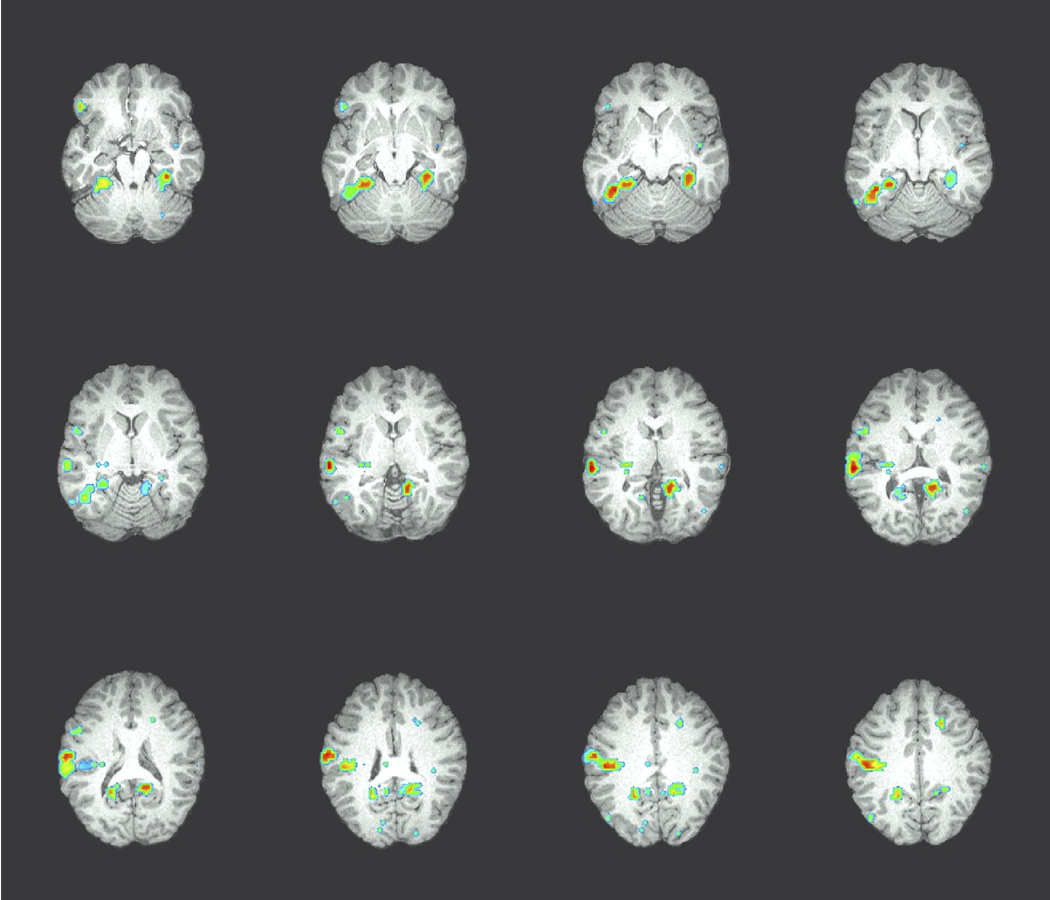
Độ chính xác của các bộ phân loại Naïve Bayes khối 27 điểm ảnh ba chiều tập trung vào mỗi điểm ảnh ba chiều [0,7–0,8]

Giá trị kỳ vọng
Cho biến ngẫu nhiên rời rạc X, giá trị kỳ vọng của X, được viết E[X] là
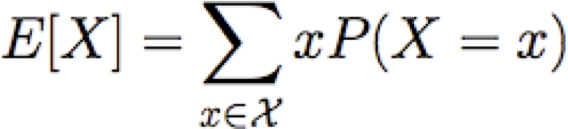
Chúng ta cũng có thể nói về giá trị kỳ vọng của các hàm X
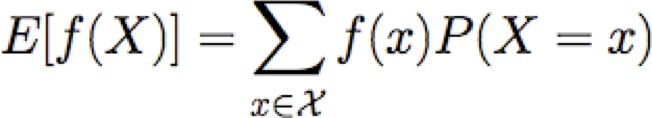
Hiệp phương sai
Cho hai vars ngẫu nhiên X và Y, chúng ta định nghĩa hiệp phương sai của X và Y là

ví dụ: X=giới tính, Y=lượt chơiBóng đá
hoặc X=giới tính, Y=thuận tay trái
Nhớ lại: