Hôm nay:
- Học máy là gì?
- Học cây quyết định
- Hậu cần khóa học
Đọc:
- “The Discipline of ML”
- Mitchell, Chương 3
- Bishop, Chương 14.4
Học máy:
Nghiên cứu các thuật toán
- cải thiện hiệu suất của chúng P
- tại một số nhiệm vụ T
- với kinh nghiệm E
được xác định rõ nhiệm vụ học tập: <P,T,E>
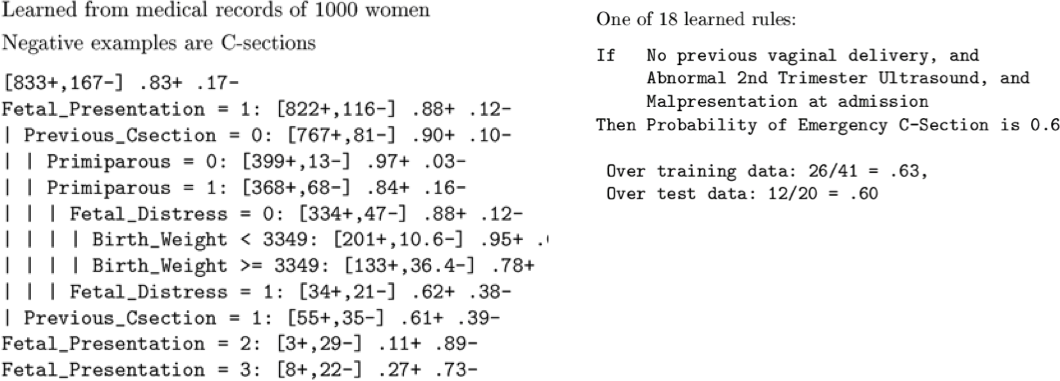
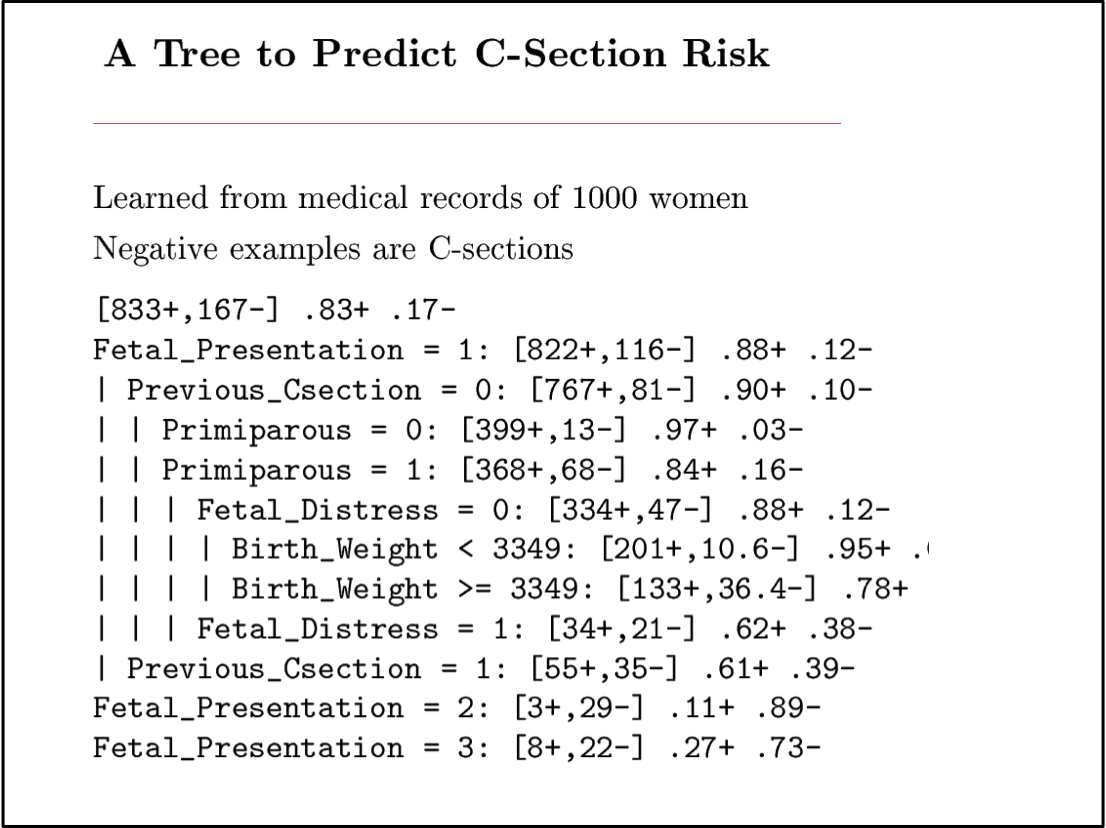
Học cách dự đoán các mổ đẻ khẩn cấp

9714 hồ sơ bệnh nhân, mỗi hồ sơ có 215 tính năng
[Sims et al., 2000]
Học cách phân loại tài liệu văn bản

spam so với không spam
Học cách phát hiện các đối tượng trong hình ảnh
(GS. H. Schneiderman)

Ví dụ đào tạo hình ảnh cho từng định hướng

Học cách phân loại từ
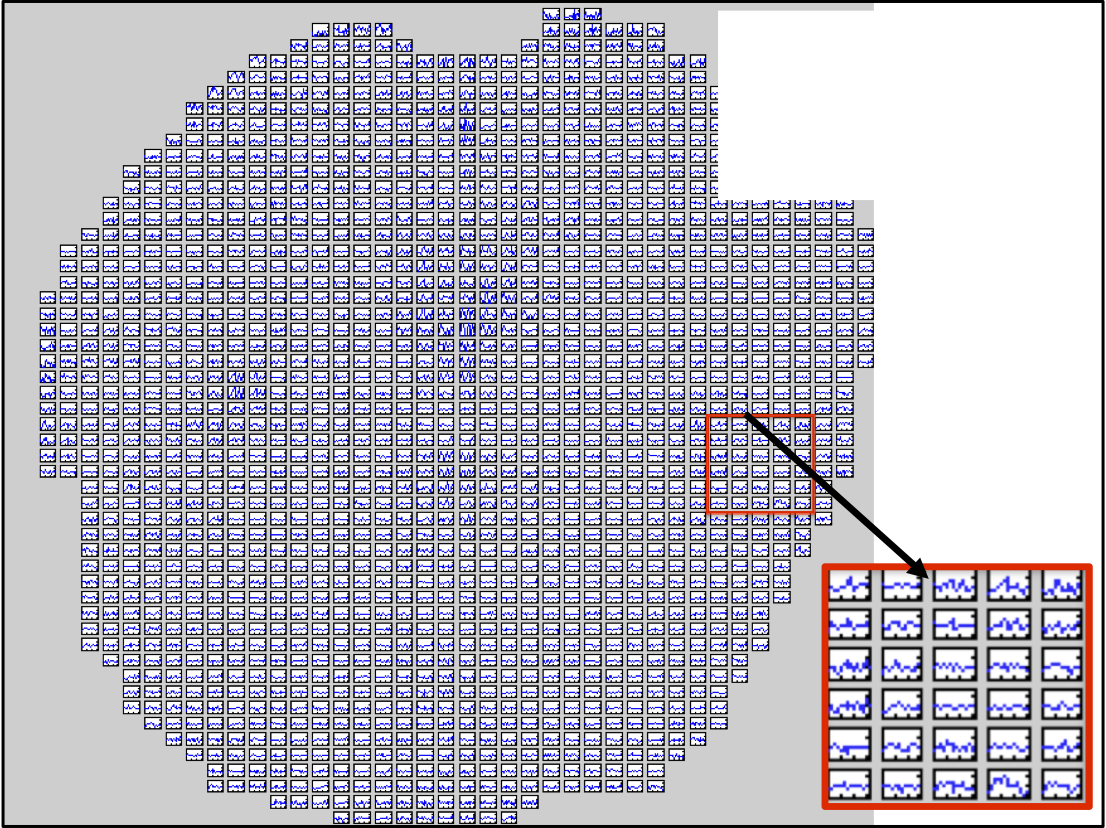
Học cách phân loại từ mà một người đang nghĩ đến, dựa trên hoạt động của não fMRI
Học điều khiển bộ phận giả từ cấy ghép thần kinh
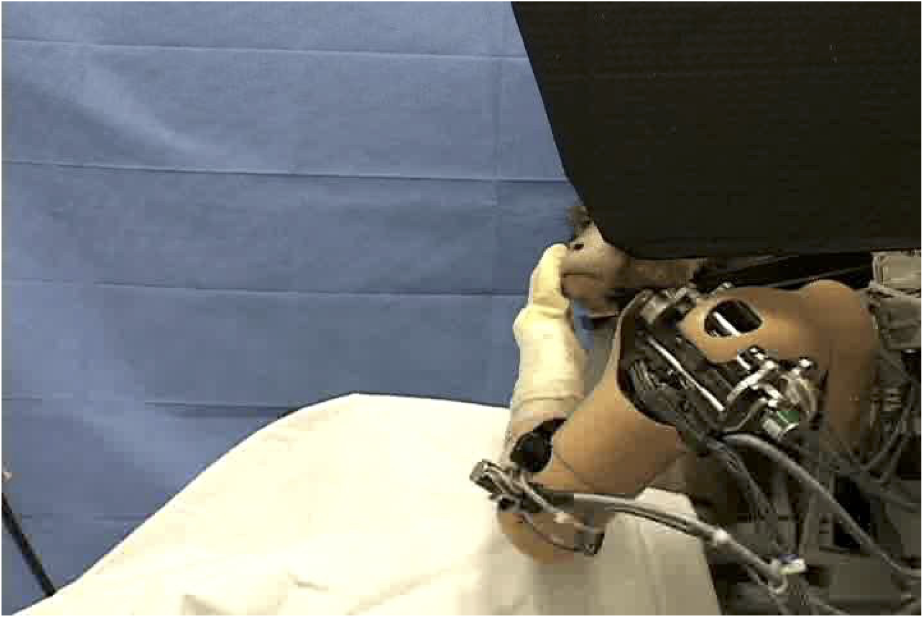
[R. Kass, L. Castellanos, A. Schwartz]
Học máy – Thực hành

Khai thác cơ sở dữ liệu
Nhận dạng giọng nói

Nhận dạng đối tượng

Phân tích văn bản

Học điều khiển
- Máy Vector hỗ trợ
- Mạng Bayesian
- Mô hình Markov ẩn
- Mạng thần kinh sâu
- Học tăng cường
- ….
Học máy – Lý thuyết
Lý thuyết học tập PAC
(học khái niệm có giám sát)
- # mẫu (m)
- độ phức tạp biểu diễn (H)
- tỷ lệ lỗi (ε)
- xác suất thất bại (δ)
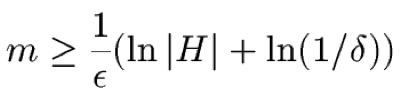
Các lý thuyết khác về
- Học kỹ năng tăng cường
- Học bán giám sát
- Truy vấn tích cực của sinh viên
- …
… cũng liên quan:
- # lỗi trong quá trình học
- chiến lược truy vấn của người học
- tỷ lệ hội tụ
- hiệu suất tiệm cận
- sai lệch, phương sai
Học máy trong Khoa học Máy tính
- Học máy đã là phương pháp ưa thích để
- Nhận dạng giọng nói, Xử lý ngôn ngữ tự nhiên
- Thị giác máy tính
- Phân tích kết quả y tế
- Điều khiển robot
- …
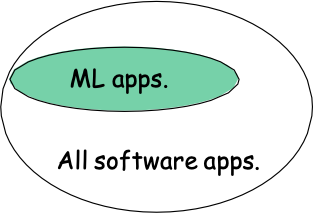
- Phân khúc ML này đang phát triển (tại sao?)
Học máy trong Khoa học máy tính
- Học máy đã là phương pháp ưa thích để
- Nhận dạng giọng nói, Xử lý ngôn ngữ tự nhiên
- Thị giác máy tính
- Phân tích kết quả y tế
- Điều khiển rô bốt
- …
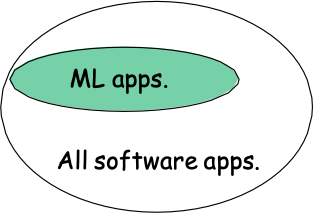
- Phân khúc ML này đang phát triển
- Cải thiện thuật toán học máy
- Tăng khối lượng dữ liệu trực tuyến
- Tăng nhu cầu về bản thân -tùy chỉnh phần mềm
Dự đoán của Tom: ML sẽ là một phần phát triển nhanh nhất của CS trong thế kỷ này
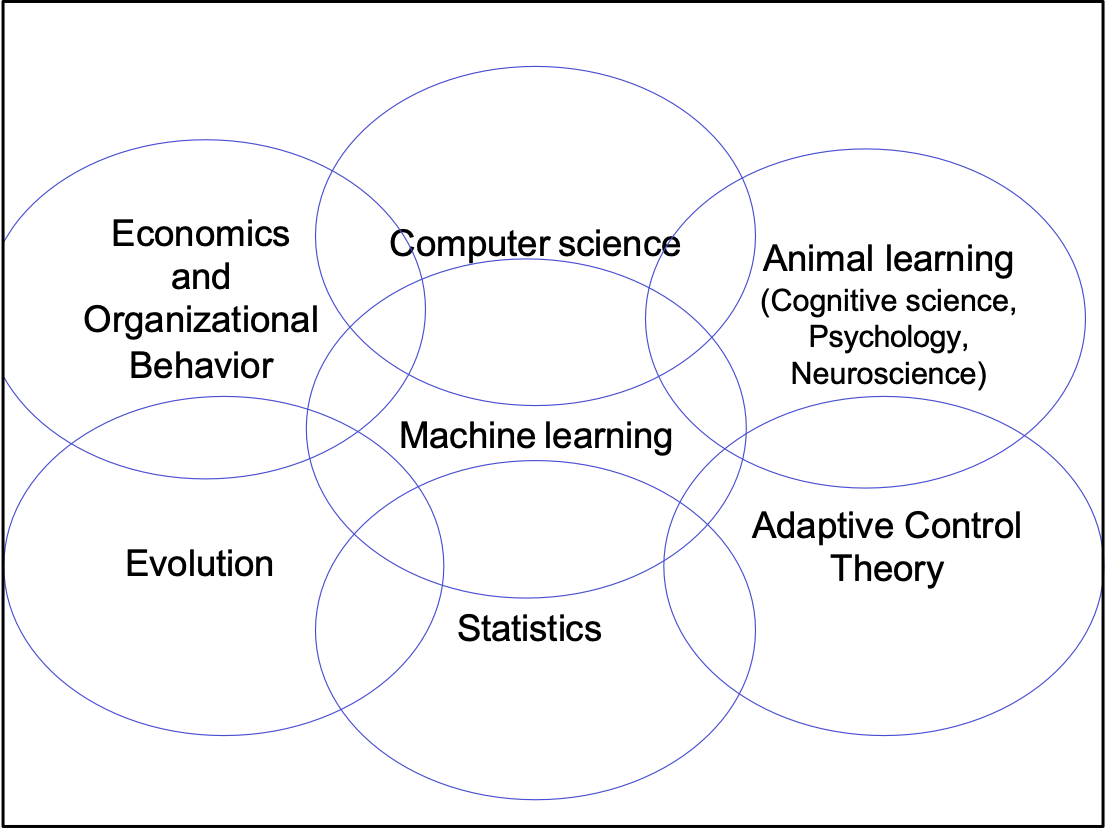
- Động vật học (Khoa học nhận thức, Tâm lý học, Khoa học thần kinh)
- Học máy
- Thống kê
- Khoa học máy tính
- Lý thuyết điều khiển thích ứng
- Tiến hóa
- Kinh tế học và Hành vi tổ chức
Bạn sẽ học gì trong khóa học này
- Các thuật toán Học máy cơ bản
- Hồi quy logistic, phương pháp Bayes, HMM, SVM, học tăng cường, học cây quyết định, tăng cường, phân cụm không giám sát, …
- Cách sử dụng chúng trên dữ liệu thực
- văn bản, hình ảnh, dữ liệu có cấu trúc
- dự án của riêng bạn
- Cơ sở lý thuyết tính toán và thống kê
- Đủ để đọc và hiểu các tài liệu nghiên cứu ML
Hậu cần Khóa học
Machine Learning 10-601
trang web: www.cs.cmu.edu/~ninamf/courses/601sp15
Khoa
- Maria Balcan
- Tom Mitchell
Trợ giảng
- Travis Dick
- Kirsten Early
- Ahmed Hefny
- Micol Marchetti-Bowick
- Willie Neiswanger
- Abu Saparov
Trợ lý khóa học
- Sharon Cavlovich
Xem trang web để biết
- Giờ làm việc
- Chi tiết giáo trình
- Các buổi ôn tập
- Chính sách chấm điểm
- Chính sách trung thực
- Chính sách làm bài tập muộn
- Trang web Piazza
- …
Điểm nổi bật của Hậu cần Khóa học
Trong thời gian chờ đợi danh sách?
- Kiên trì trong vài tuần đầu tiên
Bài tập về nhà 1
- Có sẵn ngay bây giờ, hạn chót là thứ Sáu
Chấm điểm:
- 30% bài tập về nhà (~5-6)
- 20% bài tập môn học
- 25% giữa kỳ đầu tiên (2 tháng 3)
- 25% giữa kỳ cuối (29 tháng 4)
Liêm chính trong học tập:
- Gian lận → Rớt lớp, bị trục xuất khỏi CMU
Bài tập về nhà muộn:
- đủ tín chỉ khi đến hạn
- nửa tín chỉ trong 48 giờ tiếp theo
- 0 tín chỉ sau đó
- chúng tôi sẽ xóa điểm HW thấp nhất của bạn
- phải nộp ít nhất n- 1 trong số n bài tập về nhà, ngay cả khi muộn
Có mặt tại các kỳ thi:
- Bạn phải có mặt – lập kế hoạch ngay bây giờ.
- Hai bài kiểm tra trên lớp, không có bài kiểm tra cuối kỳ nào khác
Maria-Florina Balcan: Nina

- Nền tảng cho Học máy Hiện đại
- Ví dụ: học tập tương tác, phân tán, suốt đời
- Khoa học Máy tính Lý thuyết, đặc biệt là mối liên hệ giữa lý thuyết học tập & các lĩnh vực khác
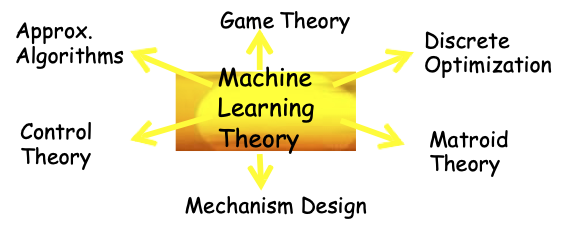
- Lý thuyết Trò chơi
- Thuật toán Xấp xỉ
- Lý thuyết Matroid
- Lý thuyết học máy
- Tối ưu hóa rời rạc
- Thiết kế cơ chế
- Lý thuyết điều khiển
Travis Dick

- Khi nào chúng ta có thể học nhiều khái niệm từ dữ liệu hầu hết không được gắn nhãn bằng cách khai thác mối quan hệ giữa các khái niệm.
- Hiện tại: Mối quan hệ hình học
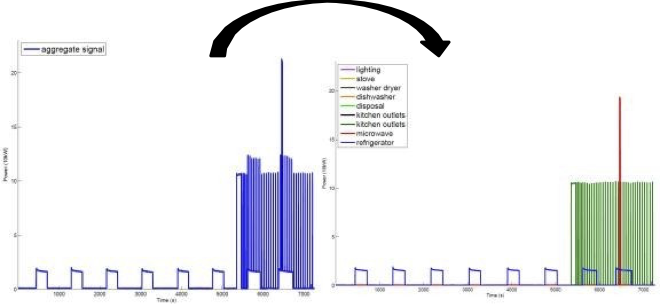
Kirstin Early

- Phân tích và dự đoán mức tiêu thụ năng lượng
- Giảm chi phí/mức sử dụng và giúp mọi người đưa ra quyết định sáng suốt
Dự đoán chi phí năng lượng từ các tính năng của ngôi nhà và hành vi của người cư ngụ

Phân chia năng lượng: phân tách tổng tín hiệu điện thành các thiết bị riêng lẻ
Ahmed Hefny

- Làm thế nào chúng ta có thể học cách theo dõi và dự đoán trạng thái của một hệ động lực chỉ từ những quan sát nhiễu?
- Chúng ta có thể khai thác các phương pháp học có giám sát để tạo ra một cách tiếp cận linh hoạt, không có điểm cực tiểu cục bộ không?

quan sát (con lắc dao động)
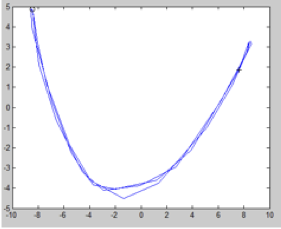
Quỹ đạo trạng thái 2D được trích xuất
Micol Marchetti-Bowick

Làm thế nào chúng ta có thể sử dụng học máy cho nghiên cứu sinh học và y tế?
- Sử dụng dữ liệu kiểu gen để xây dựng các mô hình cá nhân hóa có thể dự đoán kết quả lâm sàng
- Tích hợp dữ liệu từ nhiều nguồn để thực hiện phân tích phân nhóm ung thư
- Mô hình hồi quy thưa thớt có cấu trúc cho các nghiên cứu kết hợp trên toàn bộ gen
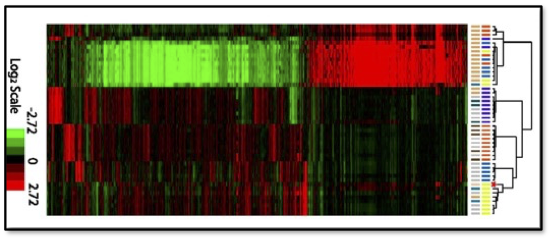
Dữ liệu biểu hiện gen w/ dendrogram (hoặc có một ảnh cho mỗi tác vụ)
Willie Neiswanger

- Nếu chúng ta muốn áp dụng thuật toán học máy cho bộ dữ liệu LỚN…
- Làm thế nào chúng ta có thể phát triển các thuật toán học máy song song, giao tiếp thấp không?
- Chẳng hạn như các thuật toán song song đáng xấu hổ, nơi các máy hoạt động độc lập, không có giao tiếp.
Abu Saparov

- Kiến thức về thế giới có thể giúp máy tính hiểu ngôn ngữ tự nhiên như thế nào?
- Những loại công cụ học máy nào là cần thiết để hiểu câu?
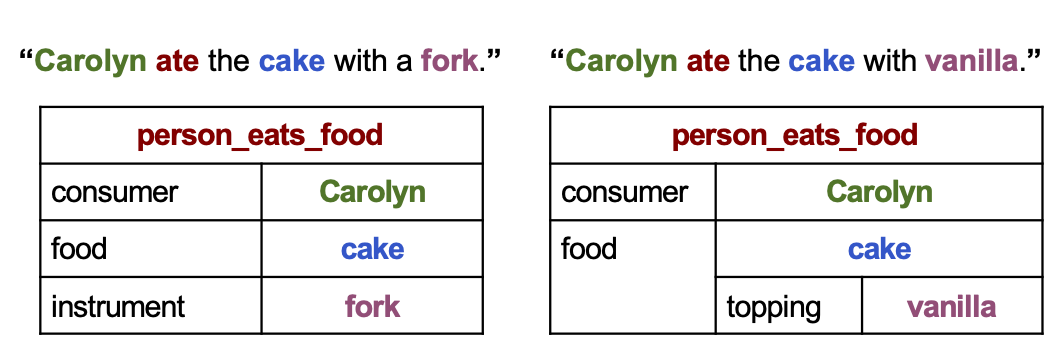
Tom Mitchell

Làm thế nào chúng ta có thể xây dựng những người học không bao giờ kết thúc?
Nghiên cứu điển hình: người học ngôn ngữ không bao giờ kết thúc (NELL) chạy 24×7 để học đọc web

xem http://rtw.ml.cmu.edu
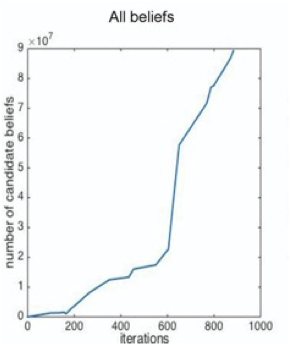
số niềm tin so với thời gian (5 năm)
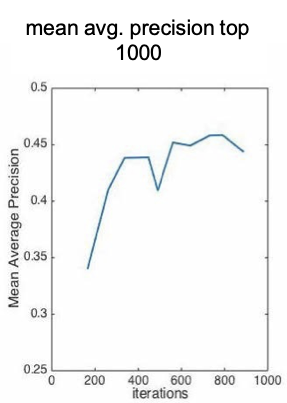
đọc độ chính xác so với thời gian (5 năm)
Xấp xỉ hàm và học cây quyết định
Xấp xỉ hàm
Đặt vấn đề:
- Tập hợp các trường hợp khả dĩ X
- Hàm mục tiêu chưa biết f : X→Y
- Tập hợp các giả thuyết hàm H={ h | h : X→Y }
Đầu vào:
- Các ví dụ huấn luyện {<x(i),y(i)>} của hàm mục tiêu chưa biết f
chỉ số trên: ví dụ huấn luyện thứ i
Đầu ra:
- Giả thuyết h ∈ H gần đúng nhất với hàm mục tiêu f
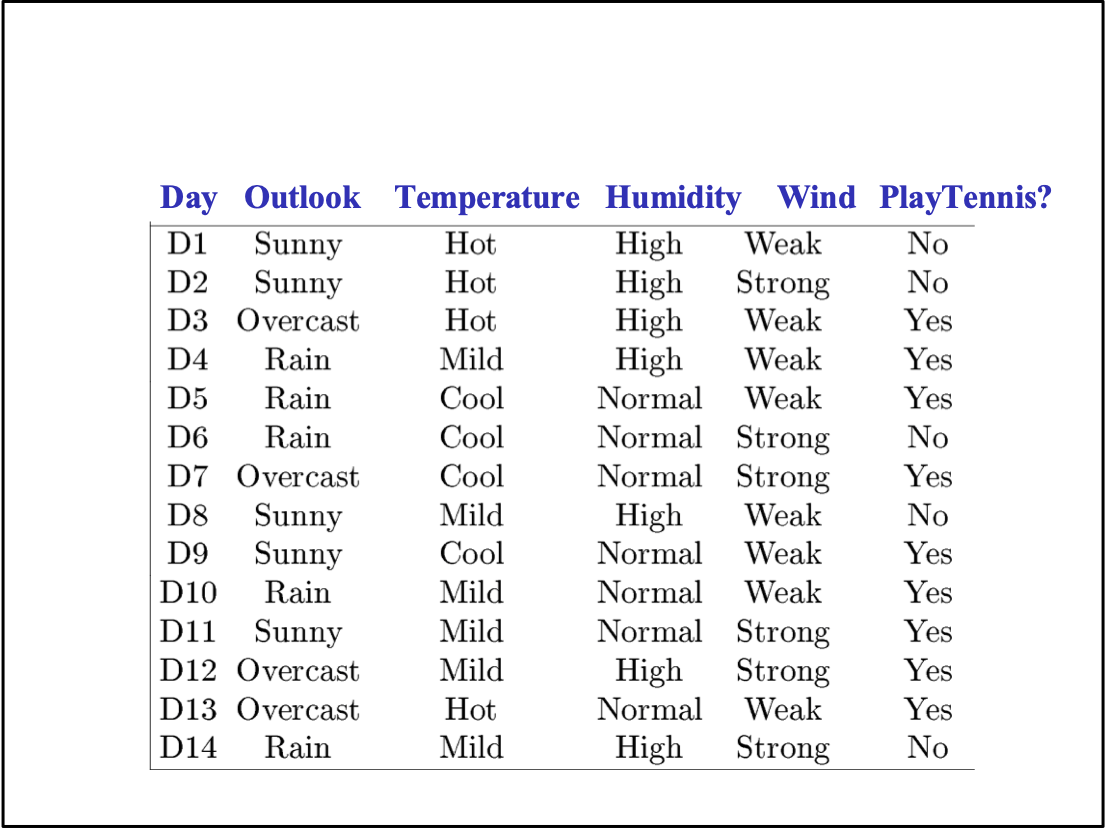
Tập dữ liệu huấn luyện đơn giản
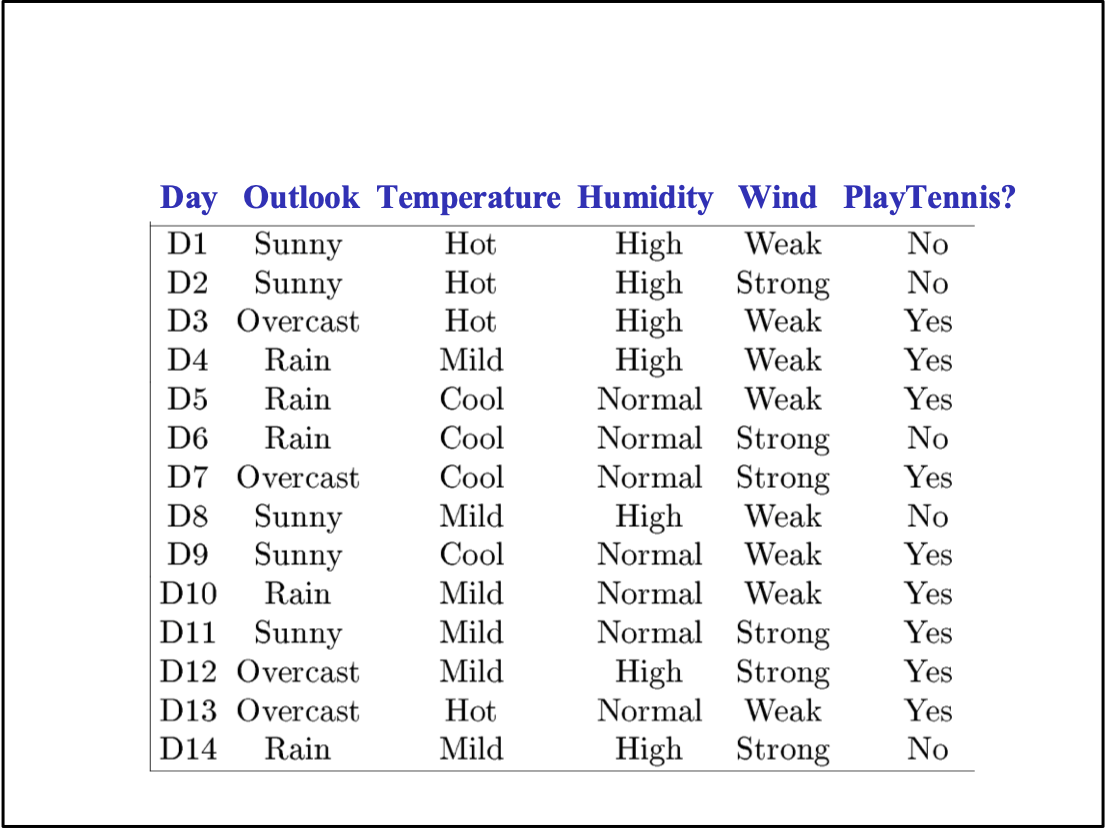
Cây quyết định cho
f: <Outlook, Temperature, Humidity, Wind> → PlayTennis?
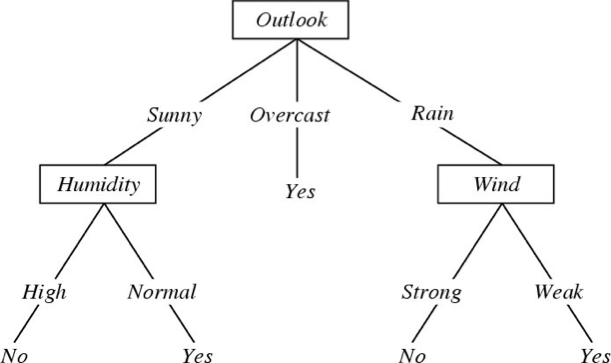
Mỗi nút bên trong: kiểm tra một thuộc tính có giá trị rời rạc Xi
Mỗi nhánh từ một nút: chọn một giá trị cho Xi
Mỗi nút lá: dự đoán Y (hoặc P(Y|X ∈ lá))
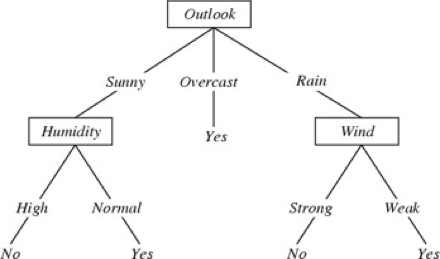
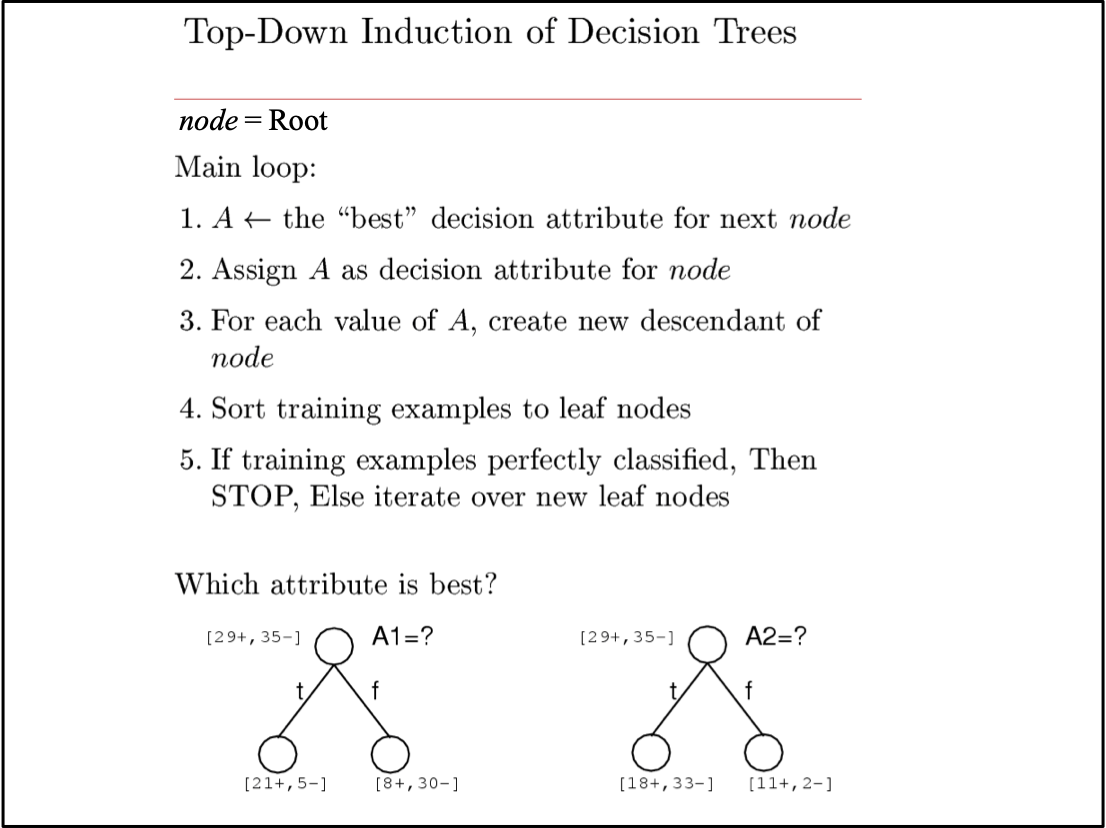
Học Cây Quyết Định
Đặt vấn đề:
- Tập hợp các trường hợp có thể xảy ra X
- mỗi trường hợp x trong X là một vectơ đặc trưng
- ví dụ: <Humidity=low, Wind=weak, Outlook=rain, Temp=hot>
- Hàm mục tiêu chưa xác định f : X→Y
- Y=1 nếu chúng ta chơi quần vợt vào ngày này, ngược lại 0
- Tập hợp của hàm giả thuyết H={ h | h : X→Y }
- mỗi giả thuyết h là một cây quyết định
- cây sắp xếp x thành lá, gán y
Học Cây Quyết Định
Đặt vấn đề:
- Tập hợp các trường hợp có thể xảy ra X
- mỗi trường hợp x trong X là một vectơ đặc trưng x = < x1, x2 … xn>
- Hàm mục tiêu chưa xác định f : X→Y
- Y có giá trị rời rạc
- Tập các giả thuyết hàm H={ h | h : X→Y }
- mỗi giả thuyết h là một cây quyết định
Đầu vào:
- Các ví dụ huấn luyện {<x(i),y(i)>} của hàm mục tiêu chưa biết f
Đầu ra:
- Giả thuyết h ∈ H xấp xỉ tốt nhất với hàm mục tiêu f
Cây quyết định
Giả sử X = <X1,… Xn>
trong đó Xi là các biến có giá trị boolean
Bạn sẽ biểu diễn cho Y = X2 X5 như thế nào? Y = X2 ∨ X5
Bạn biểu diễn X2 X5 ∨ X3X4(¬X1) như thế nào
[ID3, C4.5, Quinlan]
Sample Entropy
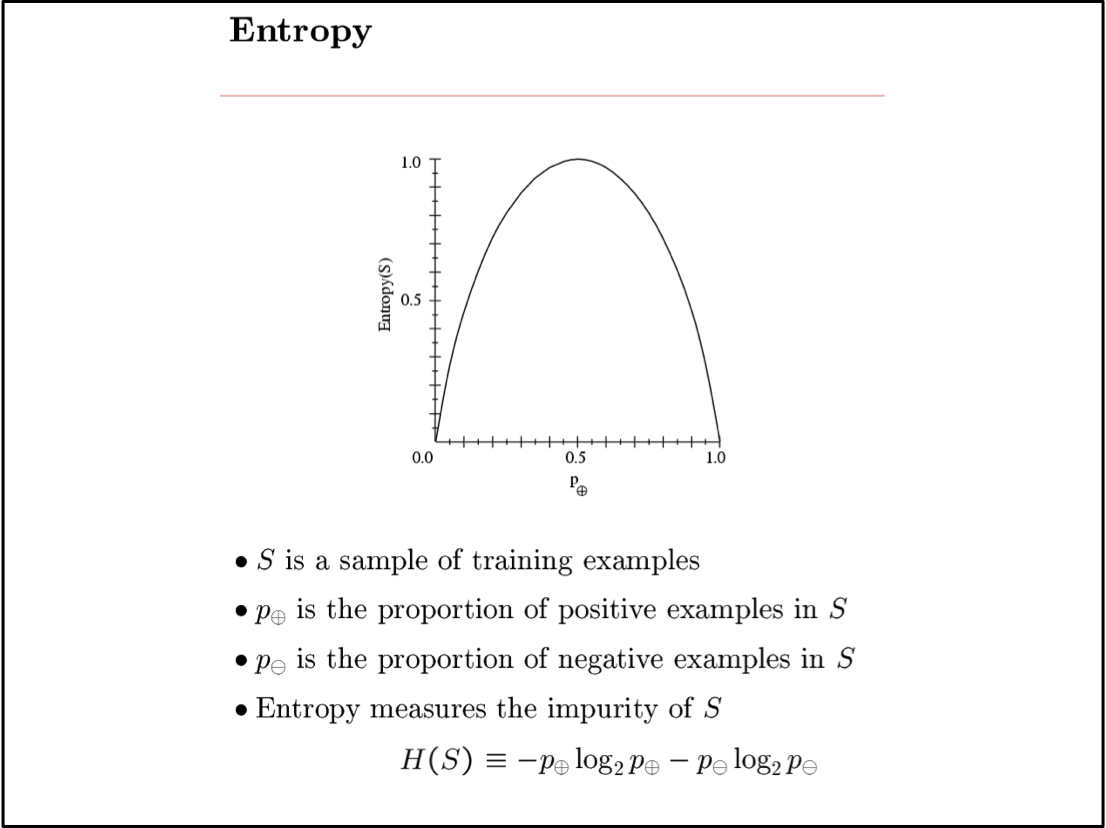
Entropy
Entropy H(X) của biến ngẫu nhiên X
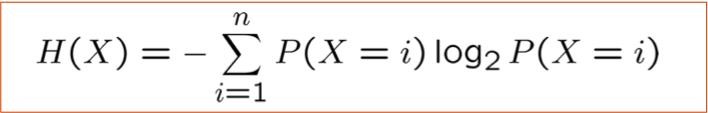
H(X) là số bit dự kiến cần để mã hóa một giá trị X được rút ngẫu nhiên (theo mã hiệu quả nhất)
n: số lượng có thể các giá trị cho X
Tại sao? Lý thuyết thông tin:
- Mã hiệu quả nhất có thể gán các bit -log2 P(X=i) để mã hóa thông báo X=i
- Vì vậy, số lượng bit dự kiến để mã hóa một X ngẫu nhiên là:
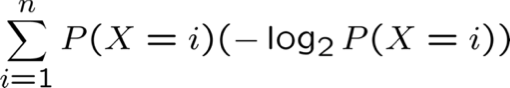
Entropy
Entropy H(X) của biến ngẫu nhiên X
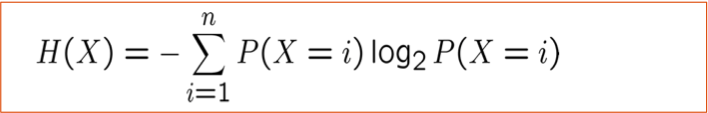
Entropy có điều kiện cụ thể H(X|Y=v) của X cho trước Y=v :
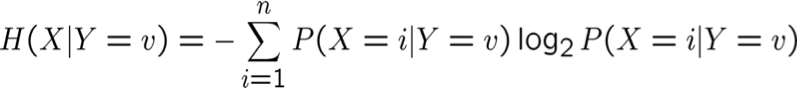
Entropy có điều kiện H(X|Y) của X cho trước Y:
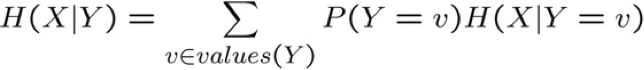
Thông tin tương hỗ (còn gọi là Độ lợi thông tin) của X và Y :
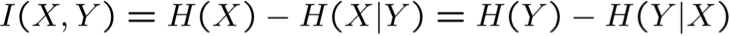
Độ lợi thông tin
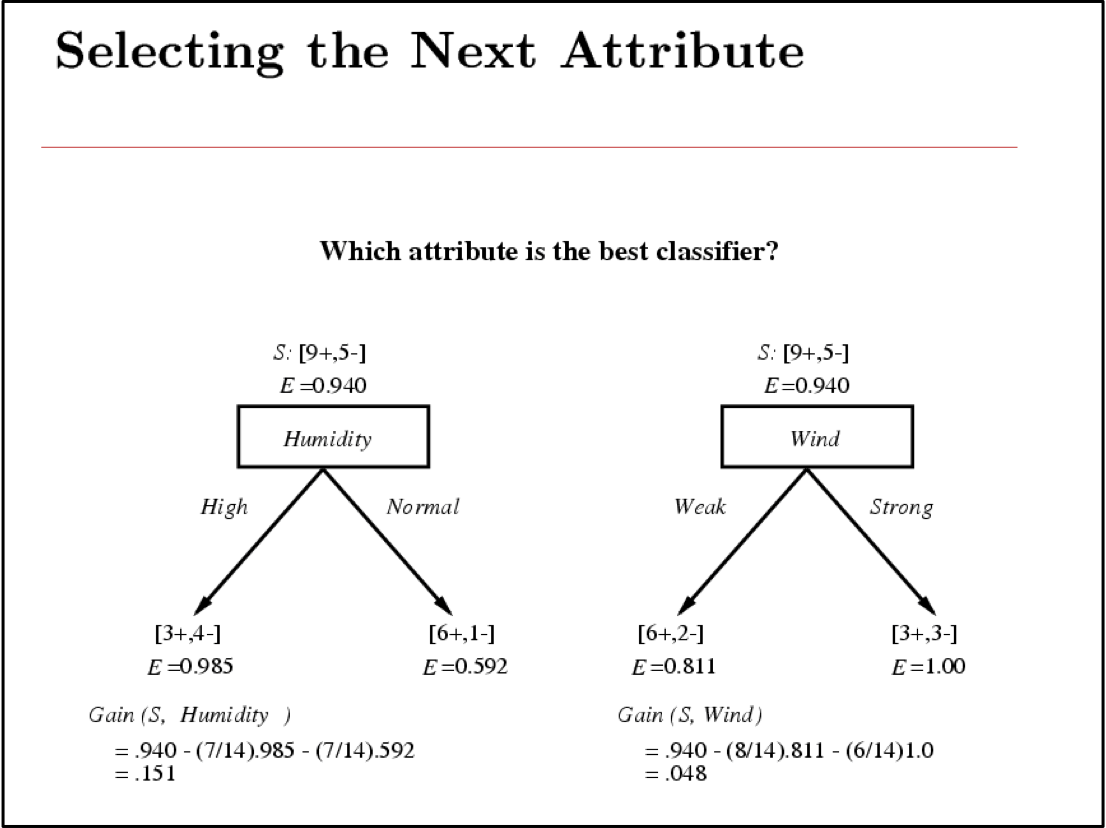
Độ lợi thông tin là thông tin tương hỗ giữa thuộc tính đầu vào A và biến mục tiêu Y
Mức tăng thông tin là mức giảm entropy dự kiến của biến mục tiêu Y đối với mẫu dữ liệu S, do sắp xếp trên biến A
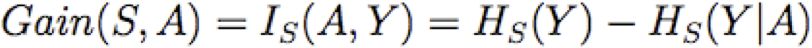
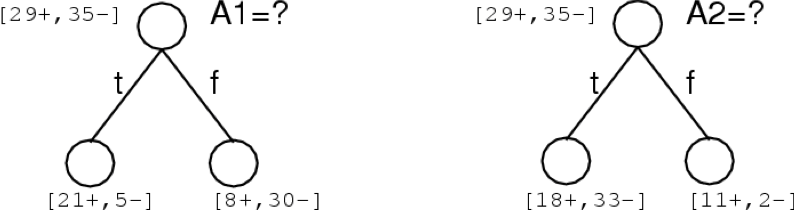
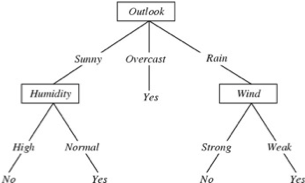
Tập dữ liệu huấn luyện đơn giản
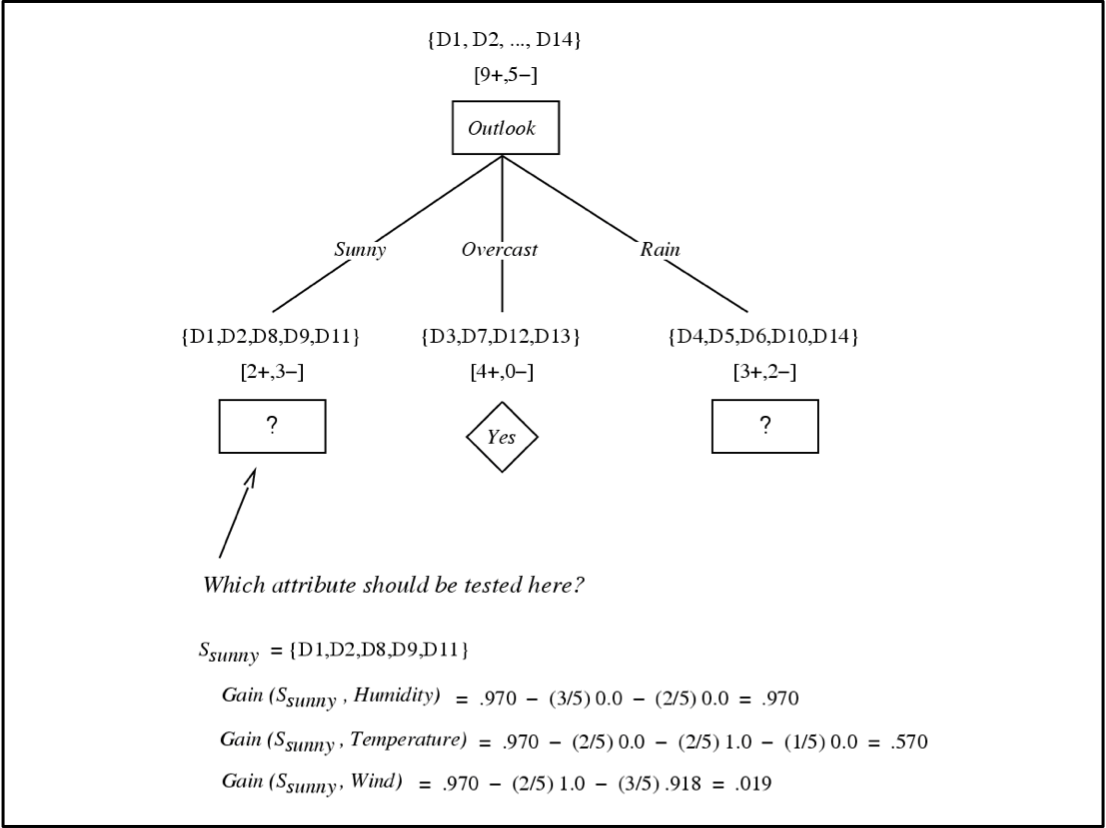
Cây quyết định cuối cùng cho
f: <Outlook, Temperature, Humidity, Wind> → PlayTennis?
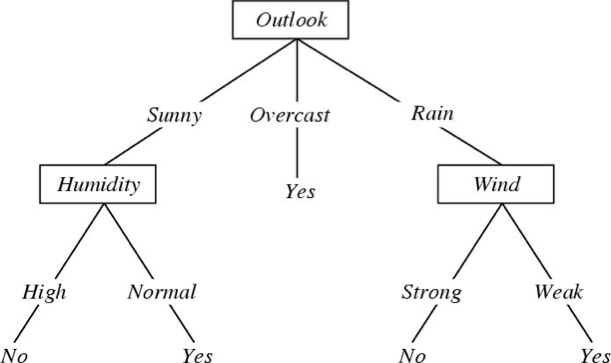
Mỗi nút bên trong: kiểm tra một thuộc tính có giá trị rời rạc Xi
Mỗi nhánh từ một nút: chọn một giá trị cho Xi
Mỗi nút lá: dự đoán Y
Chúng ta nên xuất cây nào?
- ID3 thực hiện tìm kiếm heuristic trong không gian cây quyết định
- Nó dừng ở cây nhỏ nhất chấp nhận được. Tại sao?
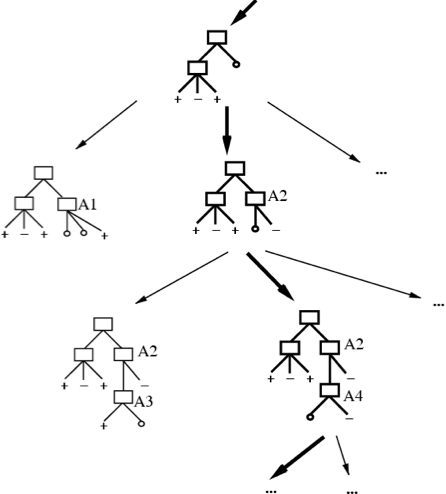
Dao cạo của Occam: thích giả thuyết đơn giản nhất phù hợp với dữ liệu
Tại sao thích giả thuyết ngắn? (Occam’s Razor)
Lập luận ủng hộ:
Lập luận phản đối:
Tại sao ưa thích giả thuyết ngắn? (Occam’s Razor)
Lập luận ủng hộ:
- Ít giả thuyết ngắn hơn giả thuyết dài
- một giả thuyết ngắn phù hợp với dữ liệu ít có khả năng là một sự trùng hợp thống kê
- có khả năng cao là một giả thuyết đủ phức tạp sẽ phù hợp với dữ liệu
Lập luận phản đối:
- Cũng có ít giả thuyết hơn với số nút nguyên tố và thuộc tính bắt đầu bằng “Z”
- Giả thuyết “ngắn” có gì đặc biệt?
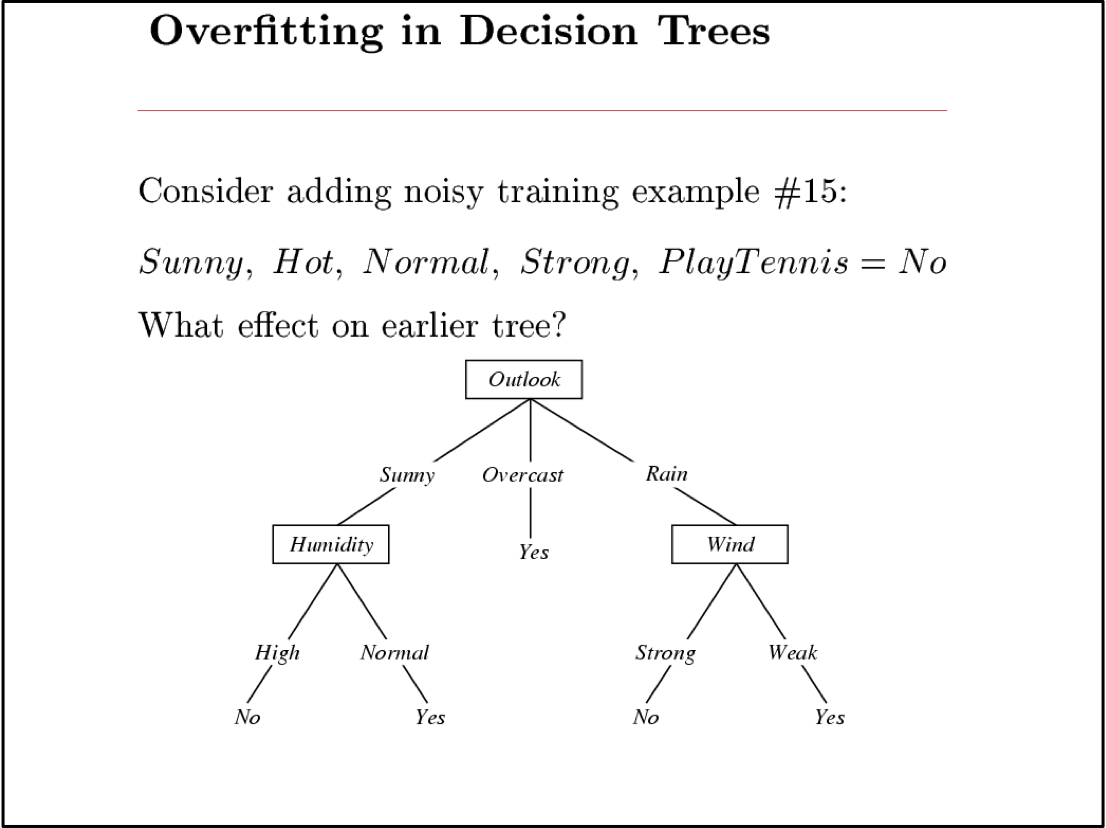
Khớp quá mức
Xem xét một giả thuyết h và giả thuyết của nó
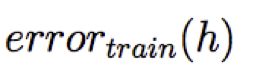
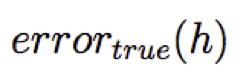
Ta nói h quá khớp với dữ liệu huấn luyện nếu
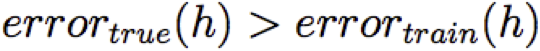
Lượng khớp quá mức =
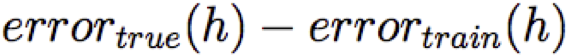
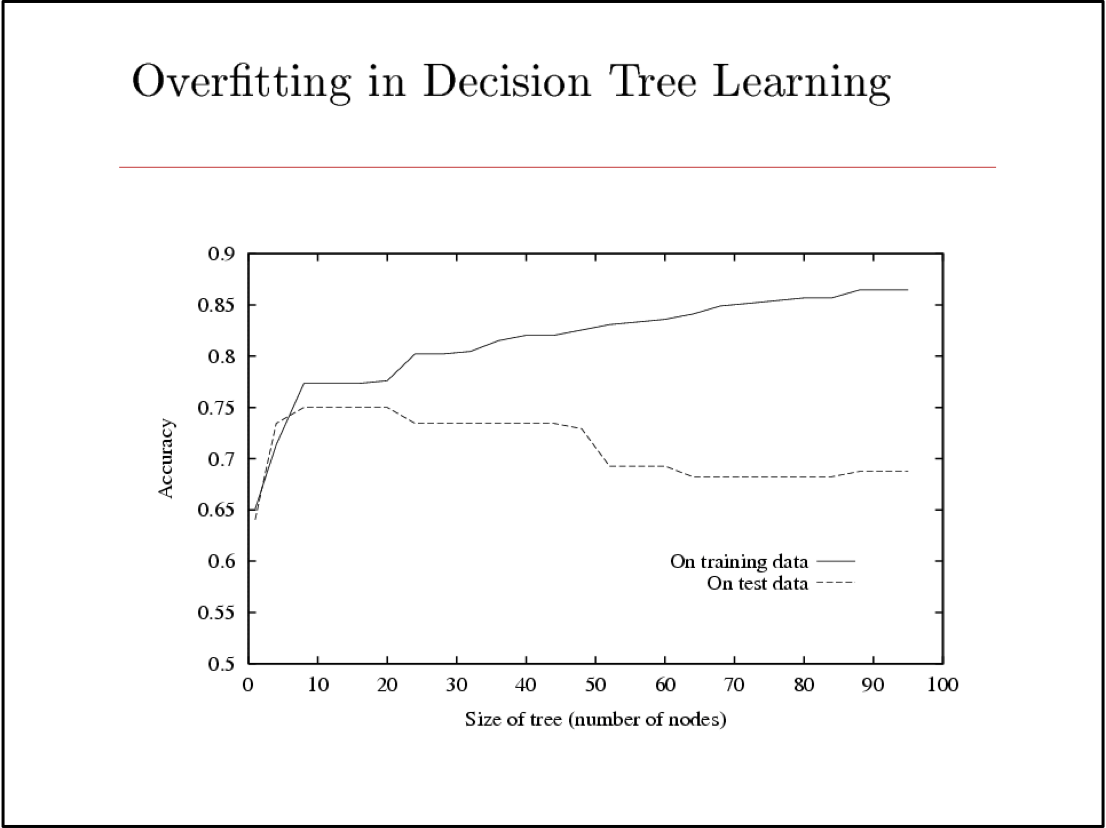


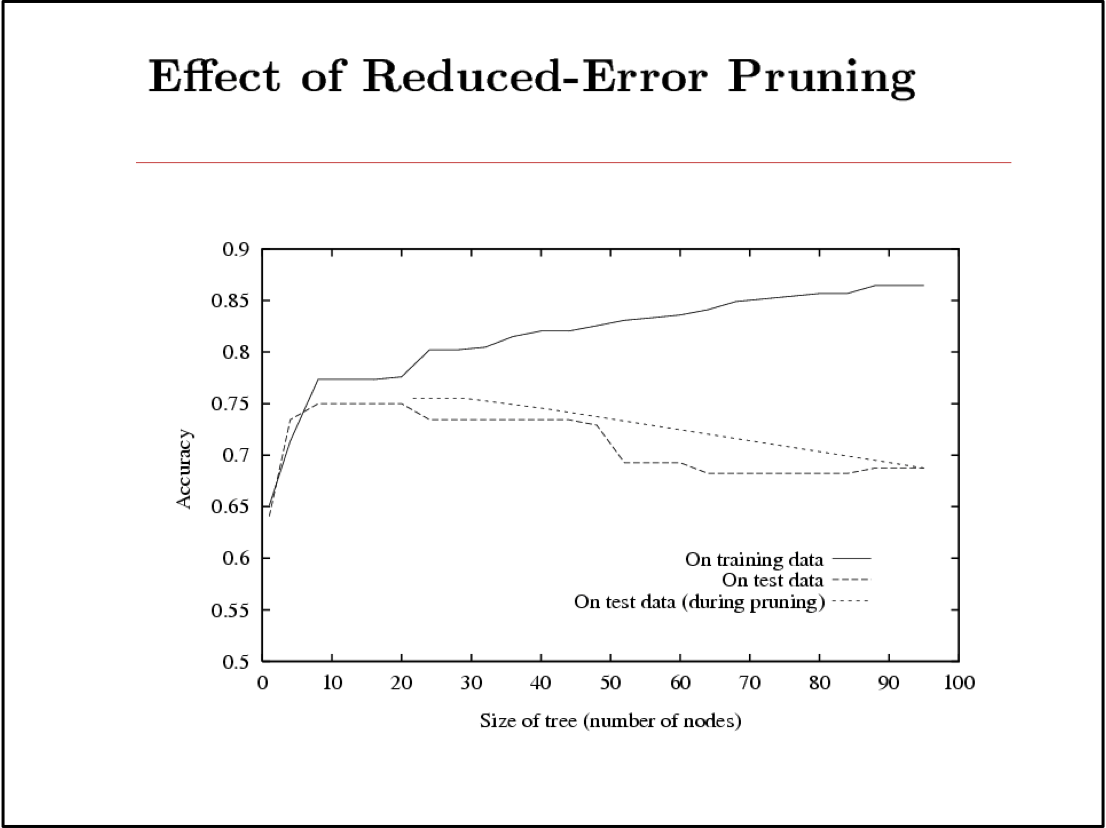
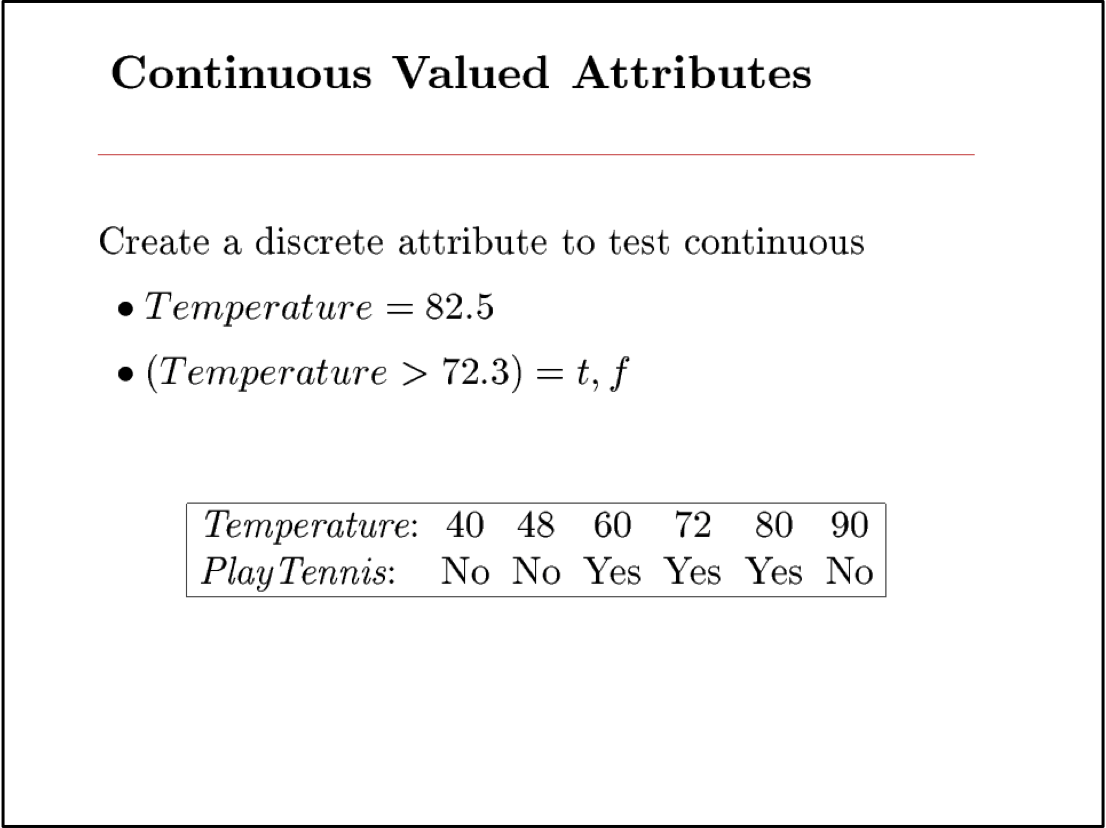

Bạn nên biết:
- Các bài toán xấp xỉ hàm được đặt ra:
- Không gian thể hiện, X
- Mẫu dữ liệu huấn luyện có nhãn { <x(i), y(i)>}
- Không gian giả thuyết, H = { f: X→Y }
- Học là bài toán tìm kiếm/tối ưu hóa trên H
- Các hàm mục tiêu khác nhau
- giảm thiểu lỗi đào tạo (mất mát 0-1)
- trong số các giả thuyết giảm thiểu lỗi đào tạo, chọn nhỏ nhất (?)
- Các hàm mục tiêu khác nhau
- Học cây quyết định
- Greedy top-down learning của cây quyết định (ID3, C4.5,…)
- Overfitting và post-pruning cây/quy tắc
- Phần mở rộng…
Câu hỏi suy nghĩ (1)
- ID3 và C4.5 là các thuật toán heuristic tìm kiếm trong không gian của cây quyết định. Tại sao không chỉ làm một tìm kiếm toàn diện?
Câu hỏi suy nghĩ (2)
- Xét hàm mục tiêu f: <x1,x2> → y, trong đó x1 và x2 có giá trị thực, y là boolean. Tập hợp các bề mặt quyết định có thể mô tả bằng cây quyết định sử dụng mỗi thuộc tính nhiều nhất một lần là gì?
Câu hỏi suy nghĩ (3)
- Tại sao sử dụng Information Gain để chọn thuộc tính trong cây quyết định? Những tiêu chí nào khác có vẻ hợp lý và sự đánh đổi khi đưa ra lựa chọn này là gì?
Câu hỏi suy nghĩ (4)
- Đâu là mối quan hệ giữa việc học cây quyết định và việc học các quy tắc IF-THEN