
1.2. Con trỏ băm và cấu trúc dữ liệu
Trong phần này, chúng ta thảo luận về con trỏ băm và các ứng dụng của chúng. Con trỏ băm là một cấu trúc dữ liệu hóa ra lại hữu ích trong nhiều hệ thống mà chúng ta xem xét. Một con trỏ băm chỉ đơn giản là một con trỏ tới nơi một số thông tin được lưu trữ cùng với một hàm băm mật mã của thông tin. Trong khi con trỏ thông thường cung cấp cho bạn một cách để truy xuất thông tin, con trỏ băm cũng cho phép bạn xác minh rằng thông tin không bị thay đổi (Hình 1.4).
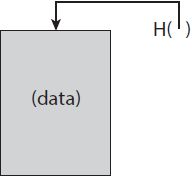
HÌNH 1.4. Con trỏ băm. Con trỏ băm là một con trỏ tới nơi dữ liệu được lưu trữ cùng với một băm mật mã về giá trị của dữ liệu này tại một số thời điểm cố định.
Chúng ta có thể sử dụng con trỏ băm để xây dựng tất cả các loại cấu trúc dữ liệu. Theo trực giác, chúng ta có thể lấy một cấu trúc dữ liệu quen thuộc sử dụng con trỏ, chẳng hạn như danh sách được liên kết hoặc cây tìm kiếm nhị phân và triển khai nó bằng con trỏ băm thay vì con trỏ thông thường, như chúng ta thường làm.
Chuỗi khối
Hình 1.5 cho thấy một danh sách được liên kết bằng cách sử dụng con trỏ băm. Chúng ta gọi cấu trúc dữ liệu này là một chuỗi khối. Trong danh sách được liên kết thông thường, nơi bạn có một loạt các khối, mỗi khối có dữ liệu cũng như một con trỏ đến khối trước đó trong danh sách. Nhưng trong chuỗi khối, con trỏ khối trước đó sẽ được thay thế bằng con trỏ băm. Vì vậy, mỗi khối không chỉ cho chúng ta biết giá trị của khối trước đó ở đâu, mà còn chứa một thông báo về giá trị đó, cho phép chúng ta xác minh rằng giá trị không bị thay đổi. Chúng ta lưu trữ phần đầu của danh sách, chỉ là một con trỏ băm thông thường trỏ đến khối dữ liệu gần đây nhất.
Một trường hợp sử dụng cho chuỗi khối là một bản ghi có bằng chứng giả mạo. Đó là, chúng ta muốn xây dựng một cấu trúc dữ liệu nhật ký để lưu trữ dữ liệu và cho phép chúng ta nối dữ liệu vào cuối nhật ký. Nhưng nếu ai đó thay đổi dữ liệu xuất hiện trước đó trong nhật ký, chúng ta sẽ phát hiện ra sự thay đổi.
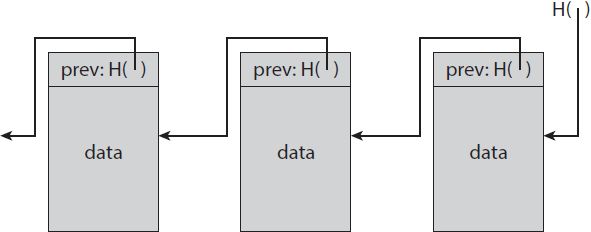
HÌNH 1.5. Chuỗi khối. Chuỗi khối là một danh sách được liên kết được tạo bằng con trỏ băm thay vì con trỏ.
Để hiểu tại sao một chuỗi khối đạt được đặc tính rõ ràng là giả mạo này, hãy hỏi điều gì sẽ xảy ra nếu đối thủ muốn giả mạo dữ liệu ở giữa chuỗi. Cụ thể, mục tiêu của đối thủ là làm theo cách sao cho ai đó chỉ nhớ con trỏ băm ở đầu chuỗi khối sẽ không thể phát hiện ra sự giả mạo. Để đạt được mục tiêu này, đối thủ thay đổi dữ liệu của khối k nào đó. Vì dữ liệu đã được thay đổi nên hàm băm trong khối k + 1, là một hàm băm của toàn bộ khối k, sẽ không khớp với nhau. Hãy nhớ rằng chúng ta được đảm bảo về mặt thống kê rằng hàm băm mới sẽ không khớp với nội dung đã thay đổi, vì hàm băm có khả năng chống va chạm. Và do đó, chúng ta sẽ phát hiện sự mâu thuẫn giữa dữ liệu mới trong khối k và con trỏ băm trong khối k + 1. Tất nhiên, đối thủ có thể tiếp tục cố gắng che đậy sự thay đổi này bằng cách thay đổi hàm băm của khối tiếp theo. Đối thủ có thể tiếp tục làm điều này, nhưng chiến lược này sẽ thất bại khi cô ấy đạt đến phần đầu của danh sách. Cụ thể, miễn là chúng ta lưu trữ con trỏ băm ở đầu danh sách ở một nơi mà đối thủ không thể thay đổi nó, thì cô ta sẽ không thể thay đổi bất kỳ khối nào mà không bị phát hiện (Hình 1.6).
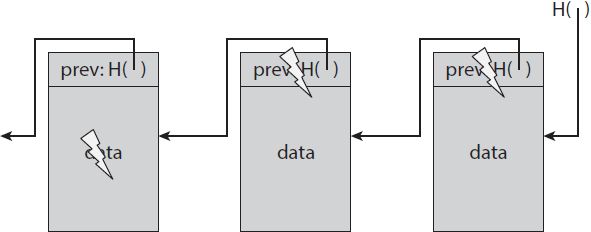
HÌNH 1.6. Nhật ký giả mạo. Nếu đối thủ sửa đổi dữ liệu ở bất kỳ vị trí nào trong chuỗi khối, nó sẽ dẫn đến con trỏ băm trong khối sau không chính xác. Nếu chúng ta lưu trữ phần đầu của danh sách, thì ngay cả khi đối thủ sửa đổi tất cả các con trỏ để phù hợp với dữ liệu đã sửa đổi, con trỏ đầu sẽ không chính xác và chúng ta có thể phát hiện ra sự giả mạo.
Kết quả là nếu đối thủ muốn xáo trộn dữ liệu ở bất kỳ đâu trong toàn bộ chuỗi này, để giữ cho câu chuyện nhất quán, cô ấy sẽ phải xáo trộn các con trỏ băm từ đầu đến cuối. Và cuối cùng cô ấy sẽ gặp phải rào cản, bởi vì cô ấy sẽ không thể giả mạo phần đầu của danh sách. Do đó, chỉ bằng cách ghi nhớ con trỏ băm duy nhất này, về cơ bản chúng ta đã xác định được giá trị băm hiển nhiên giả mạo của toàn bộ danh sách. Vì vậy, chúng ta có thể xây dựng một chuỗi khối như thế này chứa bao nhiêu khối tùy thích, quay trở lại một khối đặc biệt nào đó ở đầu danh sách, mà chúng ta sẽ gọi là khối gốc.
Bạn có thể nhận thấy rằng cấu trúc chuỗi khối tương tự như cấu trúc Merkle-Damgård được thảo luận trong Phần 1.1. Thật vậy, chúng khá giống nhau và đối số bảo mật giống nhau áp dụng cho cả hai.
Merkle Trees
Một cấu trúc dữ liệu hữu ích khác mà chúng ta có thể xây dựng bằng cách sử dụng con trỏ băm là cây nhị phân. Cây nhị phân với con trỏ băm được gọi là cây Merkle (Hình 1.7), theo tên người phát minh ra nó, Ralph Merkle. Giả sử chúng ta có một số khối chứa dữ liệu. Những khối này tạo nên lá của cây của chúng ta. Chúng ta nhóm các khối dữ liệu này thành cặp đôi, sau đó đối với mỗi cặp, chúng ta xây dựng một cấu trúc dữ liệu có hai con trỏ băm, một cho mỗi khối. Các cấu trúc dữ liệu này tạo nên cấp độ tiếp theo của cây. Lần lượt chúng ta nhóm chúng thành các nhóm hai và đối với mỗi cặp, tạo một cấu trúc dữ liệu mới chứa hàm băm của mỗi cặp. Chúng ta tiếp tục làm điều này cho đến khi chúng ta đạt được một khối duy nhất, phần gốc của cây.
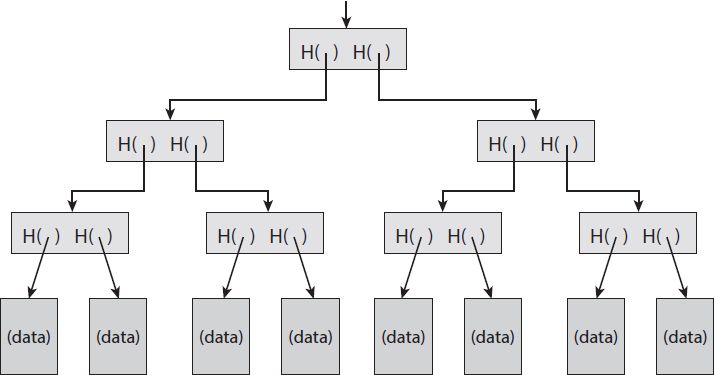
HÌNH 1.7. Cây Merkle. Trong cây Merkle, các khối dữ liệu được nhóm thành từng cặp và hàm băm của mỗi khối này được lưu trữ trong một nút cha. Các nút cha lần lượt được nhóm thành từng cặp và các hàm băm của chúng được lưu trữ nút cao hơn của cây. Mô hình này tiếp tục đi lên cây cho đến khi chúng ta đến nút gốc.
Như trước đây, chúng ta chỉ nhớ một con trỏ băm: trong trường hợp này, con trỏ ở gốc cây. Bây giờ chúng ta có khả năng đi qua các con trỏ băm đến bất kỳ điểm nào trong danh sách. Điều này cho phép chúng ta đảm bảo rằng dữ liệu không bị giả mạo bởi vì, giống như chúng ta đã thấy đối với chuỗi khối, nếu đối thủ giả mạo khối dữ liệu nào đó ở dưới cùng của cây, sự thay đổi của anh ta sẽ khiến con trỏ băm cấp cao hơn không khớp và ngay cả khi anh ta tiếp tục xáo trộn các khối khác ở phía trên cây, cuối cùng thay đổi sẽ lan truyền đến phần trên cùng, nơi anh ta sẽ không thể giả mạo con trỏ băm mà chúng ta đã lưu trữ. Vì vậy, một lần nữa, mọi nỗ lực giả mạo bất kỳ phần dữ liệu nào sẽ bị phát hiện chỉ bằng cách ghi nhớ con trỏ băm ở trên cùng.
Bằng chứng về tư cách thành viên
Một tính năng thú vị khác của Merkle tree là, không giống như chuỗi khối mà chúng ta đã xây dựng trước đây, chúng cho phép một bằng chứng ngắn gọn về tư cách thành viên. Giả sử rằng ai đó muốn chứng minh rằng một khối dữ liệu nào đó là thành viên của cây Merkle. Như thường lệ, chúng ta chỉ nhớ phần gốc. Sau đó, họ cần cho chúng ta thấy khối dữ liệu này, và các khối trên đường dẫn từ khối dữ liệu đến nút gốc. Chúng ta có thể bỏ qua phần còn lại của cây, vì các khối trên đường dẫn này đủ để cho phép chúng ta xác minh các hàm băm cho đến tận gốc của cây. Xem Hình 1.8 để mô tả bằng đồ họa về cách hoạt động của nó.
Nếu có n nút trong cây, chỉ có khoảng log(n) mục cần được hiển thị. Và vì mỗi bước chỉ yêu cầu tính toán băm của khối con, nên mất khoảng log(n) thời gian để chúng ta xác minh nó. Và do đó, ngay cả khi cây Merkle chứa một số lượng lớn các khối, chúng ta vẫn có thể chứng minh tư cách thành viên trong một thời gian tương đối ngắn. Do đó, xác minh chạy trong thời gian và không gian, theo lôgarit của số lượng nút trong cây.
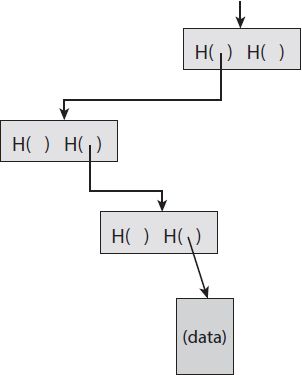
HÌNH 1.8. Bằng chứng về tư cách thành viên. Để chứng minh rằng một khối dữ liệu được bao gồm trong cây, chỉ yêu cầu hiển thị các khối trong đường dẫn từ khối dữ liệu đó đến gốc.
Cây Merkle được sắp xếp chỉ là một cây Merkle nơi chúng ta lấy các khối ở dưới cùng và sắp xếp chúng bằng cách sử dụng một số hàm thứ tự. Đây có thể là thứ tự bảng chữ cái, thứ tự từ vựng, thứ tự số hoặc một số thứ tự được thỏa thuận khác.
Bằng chứng về tư cách không thành viên
Sử dụng cây Merkle đã được sắp xếp, có thể xác minh tư cách không phải là thành viên theo thời gian và không gian lôgarit. Đó là, chúng ta có thể chứng minh rằng một khối cụ thể không có trong cây Merkle. Và cách chúng ta làm điều đó chỉ đơn giản là hiển thị một đường dẫn đến mục ngay trước vị trí của mục được đề cập và hiển thị đường dẫn đến mục ngay sau vị trí của nó. Nếu hai mục này liên tiếp nhau trong cây, thì điều này coi như bằng chứng rằng mục được đề cập không được bao gồm — bởi vì nếu nó được bao gồm, nó sẽ cần phải nằm giữa hai mục được hiển thị, nhưng không có khoảng cách giữa chúng, bởi vì chúng liên tiếp nhau.
Chúng ta đã thảo luận về việc sử dụng con trỏ băm trong danh sách được liên kết và cây nhị phân, nhưng nhìn chung, hóa ra chúng ta có thể sử dụng con trỏ băm trong bất kỳ cấu trúc dữ liệu dựa trên con trỏ nào miễn là cấu trúc dữ liệu không có chu kỳ. Nếu có chu kỳ trong cấu trúc dữ liệu, thì chúng ta sẽ không thể làm cho tất cả các băm khớp với nhau. Nếu bạn nghĩ về nó, trong một cấu trúc dữ liệu không xoay vòng, chúng ta có thể bắt đầu gần những nút lá, hoặc gần những nút không có bất kỳ con trỏ nào xuất hiện từ chúng, tính toán hàm băm của chúng, và sau đó quay trở lại từ đầu. Nhưng trong một cấu trúc với các chu kỳ, không có kết thúc nào mà chúng ta có thể bắt đầu và tính toán lại từ đó.
Để xem xét một ví dụ khác, chúng ta có thể xây dựng một đồ thị có hướng không chu trình từ các con trỏ băm và chúng ta sẽ có thể xác minh tư cách thành viên trong đồ thị đó một cách rất hiệu quả. Nó cũng sẽ dễ dàng để tính toán. Sử dụng con trỏ băm theo cách này là một thủ thuật chung mà bạn sẽ thấy thường xuyên trong bối cảnh cấu trúc dữ liệu phân tán và trong các thuật toán mà chúng ta thảo luận sau trong chương này (Phần 1.5) và trong suốt cuốn sách.